
Опубликована большая электронная коллекция романов
#news #philology
Проект «Дальнее чтение для европейской литературной истории» представил обновленную базу текстов. В каждом собрании или коллекции от 20 до 100 романов. Всего в базе 884 текста на 18 языках.
Коллекция доступна в виде архива Github. В нём есть информация о состоянии сборников, авторах и источниках.
Главная задача проекта — собрать коллекцию из 2500 полных романов и дополнить историю европейской литературы 19–20 веков. Сейчас разработчики оцифровывают и разграничивают неканонические книги, написанные женщинами в 1840–1920-х годах.
https://sysblok.ru/philology/opublikovan-otkrytyj-korpus-evropejskih-romanov/
Варвара Гузий
#news #philology
Проект «Дальнее чтение для европейской литературной истории» представил обновленную базу текстов. В каждом собрании или коллекции от 20 до 100 романов. Всего в базе 884 текста на 18 языках.
Коллекция доступна в виде архива Github. В нём есть информация о состоянии сборников, авторах и источниках.
Главная задача проекта — собрать коллекцию из 2500 полных романов и дополнить историю европейской литературы 19–20 веков. Сейчас разработчики оцифровывают и разграничивают неканонические книги, написанные женщинами в 1840–1920-х годах.
https://sysblok.ru/philology/opublikovan-otkrytyj-korpus-evropejskih-romanov/
Варвара Гузий
{kind=link}
История стилометрии: как в разное время люди искали авторов текстов
#nlp
В 1440 году итальянский гуманист Лоренцо Валла написал трактат «О подложности Константинова дара», в котором доказал, что текст этой грамоты — подделка, написанная средневековой латынью VIII века, а не IV века, как предполагалось. До этого «Константинов дар» использовался римскими папами для получения светской власти над Неаполитанским королевством в XV веке.
Эта работа — первый пример определения авторства текста с опорой на сам текст. К сожалению, в ситуациях, когда временного разрыва между текстом и событием нет, такой метод не применим.
Появление стилометрии
В конце XIX веке ученые предположили, что для определения авторства и датировки текстов можно использовать количественные методы, то есть искать в текстах частотные атомарные факты.
Эти идеи развивали Томас Менденхолл, Винцетий Лютославский и Николай Морозов. После появления ЭВМ Фредерик Мостеллер и Дэвид Уоллес, наконец, успешно применили этот метод. Они выяснили, что автором 12 спорных памфлетов из «Записок федералиста» — сборника статей в поддержку утверждения Конституции США — был Джеймс Мэдисон (4-й президент США).
Современная стилометрия
Большинство современных стилометрических исследований опираются на метод Дельты, придуманный Джоном Барроузом (John Burrows) в конце 1990-х — начале 2000-х годов. В его основе лежит подсчет разницы в частотностях между наиболее частотными словами в спорном тексте и тех трудах, чье авторство не вызывает сомнения. Чем меньше дельта, тем выше вероятность, что текст принадлежит ближайшему автору.
Так Джон Барроуз изобрел первый универсальный инструмент для атрибуции текста. Его главный плюс в том, что результаты легко верифицировать экспериментально, а недостаток — что достоверно он работает только на больших текстах, не менее 5–10 тыс. слов.
Некоторые результаты стилометрических исследований
Например, подтвердилось мнение о том, что часть пьесы «Генрих VI» Шекспир писал в соавторстве с Кристофером Марло — одним из тех людей, кому иногда приписывают авторство Шекспира. Некоторые издательства уже указывают, что «Генрих VI» был написан в соавторстве.
Также мы уже писали о других исследованиях и их результатах:
• об определении автора «Сна в красном тереме»;
• об авторстве пьес Мольера;
• об авторстве анонимных статей революционной эпохи;
• о подлинности «Слова о полку Игореве».
https://sysblok.ru/knowhow/stilometrija-kak-v-raznoe-vremja-ljudi-iskali-avtorov-tekstov/
Алина Затонская, Даниил Скоринкин
#nlp
В 1440 году итальянский гуманист Лоренцо Валла написал трактат «О подложности Константинова дара», в котором доказал, что текст этой грамоты — подделка, написанная средневековой латынью VIII века, а не IV века, как предполагалось. До этого «Константинов дар» использовался римскими папами для получения светской власти над Неаполитанским королевством в XV веке.
Эта работа — первый пример определения авторства текста с опорой на сам текст. К сожалению, в ситуациях, когда временного разрыва между текстом и событием нет, такой метод не применим.
Появление стилометрии
В конце XIX веке ученые предположили, что для определения авторства и датировки текстов можно использовать количественные методы, то есть искать в текстах частотные атомарные факты.
Эти идеи развивали Томас Менденхолл, Винцетий Лютославский и Николай Морозов. После появления ЭВМ Фредерик Мостеллер и Дэвид Уоллес, наконец, успешно применили этот метод. Они выяснили, что автором 12 спорных памфлетов из «Записок федералиста» — сборника статей в поддержку утверждения Конституции США — был Джеймс Мэдисон (4-й президент США).
Современная стилометрия
Большинство современных стилометрических исследований опираются на метод Дельты, придуманный Джоном Барроузом (John Burrows) в конце 1990-х — начале 2000-х годов. В его основе лежит подсчет разницы в частотностях между наиболее частотными словами в спорном тексте и тех трудах, чье авторство не вызывает сомнения. Чем меньше дельта, тем выше вероятность, что текст принадлежит ближайшему автору.
Так Джон Барроуз изобрел первый универсальный инструмент для атрибуции текста. Его главный плюс в том, что результаты легко верифицировать экспериментально, а недостаток — что достоверно он работает только на больших текстах, не менее 5–10 тыс. слов.
Некоторые результаты стилометрических исследований
Например, подтвердилось мнение о том, что часть пьесы «Генрих VI» Шекспир писал в соавторстве с Кристофером Марло — одним из тех людей, кому иногда приписывают авторство Шекспира. Некоторые издательства уже указывают, что «Генрих VI» был написан в соавторстве.
Также мы уже писали о других исследованиях и их результатах:
• об определении автора «Сна в красном тереме»;
• об авторстве пьес Мольера;
• об авторстве анонимных статей революционной эпохи;
• о подлинности «Слова о полку Игореве».
https://sysblok.ru/knowhow/stilometrija-kak-v-raznoe-vremja-ljudi-iskali-avtorov-tekstov/
Алина Затонская, Даниил Скоринкин
{kind=link}
Будущее интернета: децентрализация и новый цифровой завет
#society
Интернет — один из сложнейших технологических проектов человечества. И у этого проекта много проблем. Создатель веба Тим Бернерс-Ли даже заявил, что интернет «сломан» и его надо «починить».
Сеть, состоящая из миллиардов устройств, все еще очень централизована. Например, 34% всего интернета хранится на серверах Amazon — то есть зависит от одной конкретной компании из одной конкретной страны. Распределением IP-адресов занимается одна организация (ICANN) на глобальном уровне и еще пять — на региональном. Государства тоже стремятся централизовать доступ в сеть и контролировать его. Достаточно вспомнить «великий китайский фаерволл» или «суверенный Рунет» (пока, к счастью, не очень работающий).
Журнал «Дискурс» @discoursio рассказывает о проектах по децентрализации интернета и освобождении его от государственного и корпоративного контроля. Это не только криптовалюты, блокчейн и deep web. Здесь и системы с распределенным хранением сайтов прямо на компьютерах пользователей, и свободные децентрализованные файлообменники, и mesh-сети вообще без провайдеров.
https://discours.io/articles/social/buduschee-interneta-detsentralizatsiya-i-novyy-tsifrovoy-zavet
#society
Интернет — один из сложнейших технологических проектов человечества. И у этого проекта много проблем. Создатель веба Тим Бернерс-Ли даже заявил, что интернет «сломан» и его надо «починить».
Сеть, состоящая из миллиардов устройств, все еще очень централизована. Например, 34% всего интернета хранится на серверах Amazon — то есть зависит от одной конкретной компании из одной конкретной страны. Распределением IP-адресов занимается одна организация (ICANN) на глобальном уровне и еще пять — на региональном. Государства тоже стремятся централизовать доступ в сеть и контролировать его. Достаточно вспомнить «великий китайский фаерволл» или «суверенный Рунет» (пока, к счастью, не очень работающий).
Журнал «Дискурс» @discoursio рассказывает о проектах по децентрализации интернета и освобождении его от государственного и корпоративного контроля. Это не только криптовалюты, блокчейн и deep web. Здесь и системы с распределенным хранением сайтов прямо на компьютерах пользователей, и свободные децентрализованные файлообменники, и mesh-сети вообще без провайдеров.
https://discours.io/articles/social/buduschee-interneta-detsentralizatsiya-i-novyy-tsifrovoy-zavet
Discours
Открытый журнал о культуре, науке, искусстве и обществе с горизонтальной редакцией.
Как нейросеть реставрирует старые советские мультфильмы
#arts #knowhow
Главная проблема старых мультфильмов — низкое разрешение видеозаписи. Нейросеть DeepHD увеличивает изображение и делает его четким. Программа работает не только со старыми пленками, но и с прямыми трансляциями. Задача алгоритма — убрать шумы и искажения, которые возникают в процессе передачи или сжатия картинки.
Работа нейросети
Технология состоит из двух этапов:
• устранение помех — восстановление деталей.
• увеличение изображения — преобразование картинки в карты признаков и уменьшение расстояния между ними.
Программу обучали на картинках высокого качества, которые уменьшали для приближения к действительности. После обработки «дискриминатор» проверял достоверность исходного и улучшенного изображений. Если «подделку» было трудно отличить от «подлинника», результат работы нейросети считался положительным. С помощью новых датасетов, программа научилась различать объекты различных размеров и качеств.
DeepHD в кино
В мае 2018 года нейросеть испытали на нескольких советских фильмах: «Летят журавли», «Судьба человека», «Иваново детство» и др. У героев фильмов улучшились мимика и фактура одежды, исчезли пересветы.
С помощью технологии также улучшили 10 анимационных лент «Союзмультфильма»: «Котенок по имени Гав», «Дюймовочка», «Аленький цветочек» и др. Персонажи стали четче, повысилось качество фонов, вернулись детали, пропавшие при оцифровке. Все картины можно посмотреть на «КиноПоиске».
Альтернативные способы реставрации
Реставраторы-любители считают, что можно обойтись и без DeepHD. Вначале исходник, оцифрованный в Adobe Premier, разбивают на куски. После поправляют цвет, повышают резкость и убирают шумы. Это можно сделать с помощью программ Conbustion или VirtualDubMod. Восстановление займет много времени, но результат будет похож на DeepHD.
https://sysblok.ru/arts/vozvrashhenie-chetkogo-popugaja-kak-nejroset-restavriruet-starye-sovetskie-multfilmy/
Варвара Гузий
#arts #knowhow
Главная проблема старых мультфильмов — низкое разрешение видеозаписи. Нейросеть DeepHD увеличивает изображение и делает его четким. Программа работает не только со старыми пленками, но и с прямыми трансляциями. Задача алгоритма — убрать шумы и искажения, которые возникают в процессе передачи или сжатия картинки.
Работа нейросети
Технология состоит из двух этапов:
• устранение помех — восстановление деталей.
• увеличение изображения — преобразование картинки в карты признаков и уменьшение расстояния между ними.
Программу обучали на картинках высокого качества, которые уменьшали для приближения к действительности. После обработки «дискриминатор» проверял достоверность исходного и улучшенного изображений. Если «подделку» было трудно отличить от «подлинника», результат работы нейросети считался положительным. С помощью новых датасетов, программа научилась различать объекты различных размеров и качеств.
DeepHD в кино
В мае 2018 года нейросеть испытали на нескольких советских фильмах: «Летят журавли», «Судьба человека», «Иваново детство» и др. У героев фильмов улучшились мимика и фактура одежды, исчезли пересветы.
С помощью технологии также улучшили 10 анимационных лент «Союзмультфильма»: «Котенок по имени Гав», «Дюймовочка», «Аленький цветочек» и др. Персонажи стали четче, повысилось качество фонов, вернулись детали, пропавшие при оцифровке. Все картины можно посмотреть на «КиноПоиске».
Альтернативные способы реставрации
Реставраторы-любители считают, что можно обойтись и без DeepHD. Вначале исходник, оцифрованный в Adobe Premier, разбивают на куски. После поправляют цвет, повышают резкость и убирают шумы. Это можно сделать с помощью программ Conbustion или VirtualDubMod. Восстановление займет много времени, но результат будет похож на DeepHD.
https://sysblok.ru/arts/vozvrashhenie-chetkogo-popugaja-kak-nejroset-restavriruet-starye-sovetskie-multfilmy/
Варвара Гузий
YouTube
Хиты «Союзмультфильма» в DeepHD
Вам всегда хотелось рассмотреть наряд Снежной Королевы и живность в «Путешествии муравья» во всех подробностях? Теперь это возможно: в Яндексе появилась собственная технология DeepHD, улучшающая изображения и видео при помощи искусственного интеллекта.
Смотрите…
Смотрите…
Посчитать Средневековье: что показывает сетевой анализ византийских писем
#history
В 2012 году австрийские ученые собрали и оцифровали средневековые письменные источники, чтобы провести их количественный анализ. Исследователи проанализировали переписки многих общественных деятелей: учитывали адресатов их писем и авторов писем к ним, а также измеряли частоту и оживленность переписки.
На основе из этих данных были построены графы, в которых отражались разные социальные связи: политические, клановые, матримониальные и даже экономические.
Какие можно сделать выводы
Выяснилось, что в период правления императора Андроника II Палеолога (1282–1328) родственные связи в среде знати в поздневизантийском обществе далеко не всегда означали тесное взаимодействие на политическом поприще. Также оказалось, что чем теснее человек взаимодействовал с императором, тем более «отчужденным» от своих современников он становился. Эта «отчужденность» сохранялась до 1321 г., когда в Византийской империи началась гражданская война.
После воцарения Андроника III (1328–1341) взаимодействий между представителями знати снова стало больше. Однако в конце его царствования снова наблюдалось «разобщение» элиты. Вероятно, это стало одной из причин коллапса империи и нового круга гражданской войны.
Сколько правили монархи в различных государствах
Ученые также сравнили историю Византийской империи с тем, что в то же время происходило в других странах — Китае, Египте, Англии и Венгрии. Выяснилось, что зависимость между быстрой сменой правителя (на следующий год) и факторами неблагоприятных внешних условий (природных катаклизмов, эпидемий и т. д.) — линейная. Чем хуже внешние условия, тем вероятнее, что правитель не удержится на престоле.
https://sysblok.ru/history/ot-razobshhennosti-k-vojne-chto-pokazyvaet-setevoj-analiz-vizantijskih-pisem/
Анна Ясинская
#history
В 2012 году австрийские ученые собрали и оцифровали средневековые письменные источники, чтобы провести их количественный анализ. Исследователи проанализировали переписки многих общественных деятелей: учитывали адресатов их писем и авторов писем к ним, а также измеряли частоту и оживленность переписки.
На основе из этих данных были построены графы, в которых отражались разные социальные связи: политические, клановые, матримониальные и даже экономические.
Какие можно сделать выводы
Выяснилось, что в период правления императора Андроника II Палеолога (1282–1328) родственные связи в среде знати в поздневизантийском обществе далеко не всегда означали тесное взаимодействие на политическом поприще. Также оказалось, что чем теснее человек взаимодействовал с императором, тем более «отчужденным» от своих современников он становился. Эта «отчужденность» сохранялась до 1321 г., когда в Византийской империи началась гражданская война.
После воцарения Андроника III (1328–1341) взаимодействий между представителями знати снова стало больше. Однако в конце его царствования снова наблюдалось «разобщение» элиты. Вероятно, это стало одной из причин коллапса империи и нового круга гражданской войны.
Сколько правили монархи в различных государствах
Ученые также сравнили историю Византийской империи с тем, что в то же время происходило в других странах — Китае, Египте, Англии и Венгрии. Выяснилось, что зависимость между быстрой сменой правителя (на следующий год) и факторами неблагоприятных внешних условий (природных катаклизмов, эпидемий и т. д.) — линейная. Чем хуже внешние условия, тем вероятнее, что правитель не удержится на престоле.
https://sysblok.ru/history/ot-razobshhennosti-k-vojne-chto-pokazyvaet-setevoj-analiz-vizantijskih-pisem/
Анна Ясинская
{kind=link}
Как работают нейросети: подборка постов с пошаговыми разборами
#survey
Разбираем сложные технологии глубокого обучения, чтобы они становились понятны каждому.
Как работает нейросеть
Рассказываем, как нейросеть учится на своих ошибках и как она в случае неудачи платит по счетам. Если ранее вы пытались изучить вопрос самостоятельно, скорее всего, натыкались на сложные статьи с кучей терминов и оборотов. Мы объясняем базовые принципы работы нейросети простым языком.
https://sysblok.ru/knowhow/kak-rabotaet-neuroset/
Как работает градиентный спуск
Самое главное в обучении нейросетей — процесс уменьшения ошибки. Он в современных нейросетях основан на градиентном спуске. Градиентный спуск — это способ поиска точек минимума или максимума в сложных функциях. В конечном счете все упирается в производные — но посложнее, чем в школе.
https://sysblok.ru/knowhow/razbiraem-nejroseti-po-chastjam-kak-rabotaet-gradientnyj-spusk/
Как работает свертка в нейросетях
Мы привыкли, что в ВК, в Фейсбуке или Инстаграме можно за пару секунд наложить фильтр на изображение: размыть его, подправить цвет, яркость, контрастность, добавить какие-то пятна. В основе этих фильтров лежат те же принципы, что и в основе сверточных нейросетей — главного алгоритма для задач распознавания картинок, символов и прочего «компьютерного зрения». Рассказываем, как работает свертка.
https://sysblok.ru/knowhow/kak-rabotajut-filtry-v-instagrame/
Как посмотреть на мир глазами нейросетей
Еще один материал про компьютерное зрение. Здесь мы рассказываем, как свертки из картинок проходят через нейросеть — и алгоритм находит в них уши котиков, контуры машин и очертания лиц.
https://sysblok.ru/knowhow/kak-posmotret-na-mir-glazami-nejrosetej/
Как устроены рекуррентные нейросети с долгой краткосрочной памятью
Этот текст — про то, что такое языковая модель и зачем она нужна. Еще рассказываем, почему рекуррентная нейросеть (RNN), хорошо подходит под машинную обработку языка и как работает LSTM — усложненная модель RNN, которая умеет запоминать не все подряд, а только важное.
https://sysblok.ru/knowhow/mama-myla-lstm-kak-ustroeny-rekurrentnye-nejroseti-s-dolgoj-kratkosrochnoj-pamjatju/
Как работает «внимание» в нейросетях
Рассказываем о механизме «внимания» (attention), на котором работают в 2020 году все действительно крутые нейросети. Почему внимание стало killer-фичей диплернинга, что под капотом у attention mechanism, как нейросеть понимает, какие признаки текста или картинки важнее других.
https://sysblok.ru/knowhow/vnimanie-vse-chto-vam-nuzhno-kak-rabotaet-attention-v-nejrosetjah/
Как работают нейросети-трансформеры
Все лучшие современные нейросети — это сочетание механизма внимания и трансформерной архитектуры. Трансформеры — это нашумевшие GPT-2, GPT-3, а также BERT — главная рабочая лошадка компьютерной лингвистики. И еще тысячи менее известных нейростевых архитектур. Осенью 2020 года Яндекс вкрутил свой трансформер YATI в. поиск. Рассказываем, как устроены трансформеры и чем они лучше предыдущих архитектур.
https://sysblok.ru/knowhow/kak-rabotajut-transformery-krutejshie-nejroseti-nashih-dnej/
#survey
Разбираем сложные технологии глубокого обучения, чтобы они становились понятны каждому.
Как работает нейросеть
Рассказываем, как нейросеть учится на своих ошибках и как она в случае неудачи платит по счетам. Если ранее вы пытались изучить вопрос самостоятельно, скорее всего, натыкались на сложные статьи с кучей терминов и оборотов. Мы объясняем базовые принципы работы нейросети простым языком.
https://sysblok.ru/knowhow/kak-rabotaet-neuroset/
Как работает градиентный спуск
Самое главное в обучении нейросетей — процесс уменьшения ошибки. Он в современных нейросетях основан на градиентном спуске. Градиентный спуск — это способ поиска точек минимума или максимума в сложных функциях. В конечном счете все упирается в производные — но посложнее, чем в школе.
https://sysblok.ru/knowhow/razbiraem-nejroseti-po-chastjam-kak-rabotaet-gradientnyj-spusk/
Как работает свертка в нейросетях
Мы привыкли, что в ВК, в Фейсбуке или Инстаграме можно за пару секунд наложить фильтр на изображение: размыть его, подправить цвет, яркость, контрастность, добавить какие-то пятна. В основе этих фильтров лежат те же принципы, что и в основе сверточных нейросетей — главного алгоритма для задач распознавания картинок, символов и прочего «компьютерного зрения». Рассказываем, как работает свертка.
https://sysblok.ru/knowhow/kak-rabotajut-filtry-v-instagrame/
Как посмотреть на мир глазами нейросетей
Еще один материал про компьютерное зрение. Здесь мы рассказываем, как свертки из картинок проходят через нейросеть — и алгоритм находит в них уши котиков, контуры машин и очертания лиц.
https://sysblok.ru/knowhow/kak-posmotret-na-mir-glazami-nejrosetej/
Как устроены рекуррентные нейросети с долгой краткосрочной памятью
Этот текст — про то, что такое языковая модель и зачем она нужна. Еще рассказываем, почему рекуррентная нейросеть (RNN), хорошо подходит под машинную обработку языка и как работает LSTM — усложненная модель RNN, которая умеет запоминать не все подряд, а только важное.
https://sysblok.ru/knowhow/mama-myla-lstm-kak-ustroeny-rekurrentnye-nejroseti-s-dolgoj-kratkosrochnoj-pamjatju/
Как работает «внимание» в нейросетях
Рассказываем о механизме «внимания» (attention), на котором работают в 2020 году все действительно крутые нейросети. Почему внимание стало killer-фичей диплернинга, что под капотом у attention mechanism, как нейросеть понимает, какие признаки текста или картинки важнее других.
https://sysblok.ru/knowhow/vnimanie-vse-chto-vam-nuzhno-kak-rabotaet-attention-v-nejrosetjah/
Как работают нейросети-трансформеры
Все лучшие современные нейросети — это сочетание механизма внимания и трансформерной архитектуры. Трансформеры — это нашумевшие GPT-2, GPT-3, а также BERT — главная рабочая лошадка компьютерной лингвистики. И еще тысячи менее известных нейростевых архитектур. Осенью 2020 года Яндекс вкрутил свой трансформер YATI в. поиск. Рассказываем, как устроены трансформеры и чем они лучше предыдущих архитектур.
https://sysblok.ru/knowhow/kak-rabotajut-transformery-krutejshie-nejroseti-nashih-dnej/
{kind=link}
Как построить карту возрастов зданий на открытых данных: проект How old is this house?
#urban
Проект how-old-is-this.house занимается визуализацией возраста зданий на карте. В отличие от других интерактивных карт, проект показывает всю картину, а не только жилые дома.
Создание карты
• Ядро проекта — геометрия зданий из Росреестра 2016 года. Там большинству домов присвоен год постройки.
• Актуализация — датасет OpenStreetMap, благодаря которому на месте старых заводских цехов на карте появились новые ЖК, лофты и концертные залы.
• Смысловое наполнение — данные Министерства культуры, Викимапии и Wikidata. Сюда входит информация о названиях, стилях, архитекторах, фотографиях и т.д.
В итоге получилось 259 тысяч построек, из которых возраст известен у 129 тысяч. Пик пришелся на 1917 год, так как после революции к нему отнесли все дома с неизвестным годом строительства. А с началом советского периода все становится логично: провал Великой Отечественной, массовое строительство хрущевок в 1960-х и спад до 1990-х.
Визуализация
Ассоциативный контекст связывает дома либо с советскими лидерами, либо — в наши дни — с градоначальниками. Авторы проекта не нашли способ разграничить исторические эпохи и периоды строительства.
Легенда карты выделяет девять периодов:
• Допетровская Россия;
• Российская Империя;
• Ленин;
• Сталин;
• Хрущев;
• Брежнев;
• Андропов,
• Черненко,
• Горбачев;
• Лужков;
• Собянин.
У каждого периода свой цвет: дореволюционные дома окрашены в красно-кирпичный цвет, сталинские высотки — в ярко-желтый, семидесятые тускловато-зелёные, а современные здания — холодного синего цвета.
Результаты и дальнейшие планы
К сожалению, результат нельзя назвать безупречным. Каждый этап геопроцессинга несет не только новые данные, но и возможные ошибки: велик шанс, что на дом в базовом слое наложилась точка, обозначающая здание или событие по соседству. Но карту можно редактировать: пользователи могут зайти в карточку объекта и внести или изменить информацию о доме, где была замечена ошибка.
Сейчас команда проекта работает над новыми городами: скоро на сайте появятся карты Екатеринбурга и Воронежа, на очереди Пенза и Нижний Новгород.
https://sysblok.ru/urban/kak-postroit-kartu-vozrastov-zdanij-na-otkrytyh-dannyh-proekt-how-old-is-this-house/
Милана Глебова
#urban
Проект how-old-is-this.house занимается визуализацией возраста зданий на карте. В отличие от других интерактивных карт, проект показывает всю картину, а не только жилые дома.
Создание карты
• Ядро проекта — геометрия зданий из Росреестра 2016 года. Там большинству домов присвоен год постройки.
• Актуализация — датасет OpenStreetMap, благодаря которому на месте старых заводских цехов на карте появились новые ЖК, лофты и концертные залы.
• Смысловое наполнение — данные Министерства культуры, Викимапии и Wikidata. Сюда входит информация о названиях, стилях, архитекторах, фотографиях и т.д.
В итоге получилось 259 тысяч построек, из которых возраст известен у 129 тысяч. Пик пришелся на 1917 год, так как после революции к нему отнесли все дома с неизвестным годом строительства. А с началом советского периода все становится логично: провал Великой Отечественной, массовое строительство хрущевок в 1960-х и спад до 1990-х.
Визуализация
Ассоциативный контекст связывает дома либо с советскими лидерами, либо — в наши дни — с градоначальниками. Авторы проекта не нашли способ разграничить исторические эпохи и периоды строительства.
Легенда карты выделяет девять периодов:
• Допетровская Россия;
• Российская Империя;
• Ленин;
• Сталин;
• Хрущев;
• Брежнев;
• Андропов,
• Черненко,
• Горбачев;
• Лужков;
• Собянин.
У каждого периода свой цвет: дореволюционные дома окрашены в красно-кирпичный цвет, сталинские высотки — в ярко-желтый, семидесятые тускловато-зелёные, а современные здания — холодного синего цвета.
Результаты и дальнейшие планы
К сожалению, результат нельзя назвать безупречным. Каждый этап геопроцессинга несет не только новые данные, но и возможные ошибки: велик шанс, что на дом в базовом слое наложилась точка, обозначающая здание или событие по соседству. Но карту можно редактировать: пользователи могут зайти в карточку объекта и внести или изменить информацию о доме, где была замечена ошибка.
Сейчас команда проекта работает над новыми городами: скоро на сайте появятся карты Екатеринбурга и Воронежа, на очереди Пенза и Нижний Новгород.
https://sysblok.ru/urban/kak-postroit-kartu-vozrastov-zdanij-na-otkrytyh-dannyh-proekt-how-old-is-this-house/
Милана Глебова
{kind=link}
Что такое Legal Tech: можно ли автоматизировать юриста
#society
Legal Tech — отраслевой способ цифровой трансформации для упрощения профессиональной деятельности юристов. В юриспруденции сложно полностью заменить человека роботами, так как в судопроизводстве есть нюансы, связанные со сложными этическими вопросами, трактовкой законов или глубоким анализом документов.
Legal Tech в США
Наиболее развит рынок Legal Tech в США. Одна из самых быстрорастущих компаний — Rocket Lawyer, услугами которой уже воспользовались 20 млн клиентов. Компания проводит онлайн-консультации с юристами, а также имеет «дежурных» адвокатов, которые мгновенно отвечают на вопросы клиентов. Еще есть сервис для составления различных договоров: человек добавляет на сайте необходимую информацию и получает готовые документы. Часовая консультация обычного адвоката составляет 500–1000 долларов, а в Rocket Lawyer — 120 долларов.
Legal Tech в Китае
В Китае Legal Tech завязан на государство и его правоохранительные функции. В августе 2017 года Верховный народный суд Китая учредил первый интернет-суд в Ханчжо, а в 2018 году интернет-суды были учреждены в Пекине и Гуанчжоу. Функции интернет-суда — онлайн-регистрация дел, запрос информации по делам, регистрация электронных доказательств и др.
Legal Tech в Евросоюзе
В Европе в области Legal Tech выступает компания Mynotary, специализирующаяся на риэлторских услугах. Это первая платформа, которая цифровизировала сам процесс создания договора: документ можно изменять и дополнять онлайн, а не отправлять друг другу внесенные изменения на согласование по нескольку раз. Договор можно подписать электронной подписью из любой точки мира. Как только договор купли-продажи подписан продавцом, он отправляется покупателю в один клик.
Legal Tech в России
В России к Legal Tech можно отнести сервисы «Консультант плюс» и «Гарант». Это справочные правовые системы, которые содержат в себе обширную судебную практику и формы документов, а также версии кодексов, законов и иных нормативных правовых актов с комментариями экспертов в актуальной редакции. Еще существуют автоматические конструкторы юридических документов, платформы управления интеллектуальной собственностью и инструменты для интеграции LegalTech-решений в сторонние IT-системы — например, у Гаранта для этого разработан специальный API.
Что станет с юристами в будущем
В ближайшие 20 лет в юридической области вряд ли произойдут кардинальные изменений в трудоустройстве. Почти все юридические технологии-либо вспомогательные, либо слишком сырые: они решают простые небольшие задачи, но не заменяют юриста целиком.
https://sysblok.ru/permhse/chto-takoe-legal-tech-i-mozhno-li-avtomatizirovat-jurista/
Ксения Филиппенко
#society
Legal Tech — отраслевой способ цифровой трансформации для упрощения профессиональной деятельности юристов. В юриспруденции сложно полностью заменить человека роботами, так как в судопроизводстве есть нюансы, связанные со сложными этическими вопросами, трактовкой законов или глубоким анализом документов.
Legal Tech в США
Наиболее развит рынок Legal Tech в США. Одна из самых быстрорастущих компаний — Rocket Lawyer, услугами которой уже воспользовались 20 млн клиентов. Компания проводит онлайн-консультации с юристами, а также имеет «дежурных» адвокатов, которые мгновенно отвечают на вопросы клиентов. Еще есть сервис для составления различных договоров: человек добавляет на сайте необходимую информацию и получает готовые документы. Часовая консультация обычного адвоката составляет 500–1000 долларов, а в Rocket Lawyer — 120 долларов.
Legal Tech в Китае
В Китае Legal Tech завязан на государство и его правоохранительные функции. В августе 2017 года Верховный народный суд Китая учредил первый интернет-суд в Ханчжо, а в 2018 году интернет-суды были учреждены в Пекине и Гуанчжоу. Функции интернет-суда — онлайн-регистрация дел, запрос информации по делам, регистрация электронных доказательств и др.
Legal Tech в Евросоюзе
В Европе в области Legal Tech выступает компания Mynotary, специализирующаяся на риэлторских услугах. Это первая платформа, которая цифровизировала сам процесс создания договора: документ можно изменять и дополнять онлайн, а не отправлять друг другу внесенные изменения на согласование по нескольку раз. Договор можно подписать электронной подписью из любой точки мира. Как только договор купли-продажи подписан продавцом, он отправляется покупателю в один клик.
Legal Tech в России
В России к Legal Tech можно отнести сервисы «Консультант плюс» и «Гарант». Это справочные правовые системы, которые содержат в себе обширную судебную практику и формы документов, а также версии кодексов, законов и иных нормативных правовых актов с комментариями экспертов в актуальной редакции. Еще существуют автоматические конструкторы юридических документов, платформы управления интеллектуальной собственностью и инструменты для интеграции LegalTech-решений в сторонние IT-системы — например, у Гаранта для этого разработан специальный API.
Что станет с юристами в будущем
В ближайшие 20 лет в юридической области вряд ли произойдут кардинальные изменений в трудоустройстве. Почти все юридические технологии-либо вспомогательные, либо слишком сырые: они решают простые небольшие задачи, но не заменяют юриста целиком.
https://sysblok.ru/permhse/chto-takoe-legal-tech-i-mozhno-li-avtomatizirovat-jurista/
Ксения Филиппенко
{kind=link}
Алгоритм против копирайта: как запатентовать все мелодии мира
#news #arts
Ноа Рубин и Дэмиен Риль заявили права собственности на каждую когда-либо написанную мелодию песни. Для этого они создали алгоритм, который сгенерировал все возможные 8-тактовые мелодии из 12 звуков одной октавы — то есть все комбинации нот в заданном диапазоне.
Таким способом авторы проекта All the Music LLC хотят покончить с судебными разбирательствами в музыкальной индустрии. Они считают, что если все мелодии могут быть выражены в виде комбинаций, которые существовали с начала времен, то копирайт на них действовать не должен. Иными словами, они ставят знак равенства между сочинением музыки и выбором из конечного числа уже сгенерированных мелодий.
Архив со всеми мелодиями выложили в открытый доступ и сделали их общественным достоянием. А код алгоритма опубликовали на GitHub под лицензией Creative Commons Zero, что также предполагает отказ от авторских прав.
https://sysblok.ru/news/algoritm-protiv-kopirajta-kak-zapatentovat-vse-melodii-mira/
Михаил Совин
#news #arts
Ноа Рубин и Дэмиен Риль заявили права собственности на каждую когда-либо написанную мелодию песни. Для этого они создали алгоритм, который сгенерировал все возможные 8-тактовые мелодии из 12 звуков одной октавы — то есть все комбинации нот в заданном диапазоне.
Таким способом авторы проекта All the Music LLC хотят покончить с судебными разбирательствами в музыкальной индустрии. Они считают, что если все мелодии могут быть выражены в виде комбинаций, которые существовали с начала времен, то копирайт на них действовать не должен. Иными словами, они ставят знак равенства между сочинением музыки и выбором из конечного числа уже сгенерированных мелодий.
Архив со всеми мелодиями выложили в открытый доступ и сделали их общественным достоянием. А код алгоритма опубликовали на GitHub под лицензией Creative Commons Zero, что также предполагает отказ от авторских прав.
https://sysblok.ru/news/algoritm-protiv-kopirajta-kak-zapatentovat-vse-melodii-mira/
Михаил Совин
YouTube
Copyrighting all the melodies to avoid accidental infringement | Damien Riehl | TEDxMinneapolis
In the litany of copyright infringement lawsuits, technology lawyer and musician Damien Riehl demonstrates that music is merely math, and has a finite number of possible melodies. If you’ve ever thought a song you like sounded similar to another, the culprit…
Создали корпус русских переводов общественно-политических сочинений XVIII века
#history
Русский политический язык начал формироваться в XVIII веке. Это время во многом стало переломным для русского общества. Оно стало больше ориентироваться на Запад, и идеи Просвещения затронули все сферы жизни. Тогда же стали активно переводиться различные издания о политике: от памфлетов до словарей и учебных пособий.
Осенью 2020 года Высшая школа экономики в сотрудничестве с Германским историческим институтом в Москве представили корпус переводов общественно-политических текстов XVIII века. Он помогает проследить формирование русского политического языка. В корпусе есть философские трактаты, художественные произведения политического характера, учебники и словари.
Как работать с корпусом
На сайте доступны два вида поиска — простой и расширенный. Результат запроса содержит количество совпадений, которые классифицируются на переводы, образцы, оригиналы и т. п. Также показывается место хранения перевода и год публикации.
Каждый перевод представлен в виде ссылки на отсканированное печатное издание. Его описание содержит краткие сведения о сочинении, его переводчике, основной теме текста, его издании и месте хранения оригинала.
Еще на сайте созданы страницы переводчиков, где собраны все переводы, выполненные одним человеком. Это дает представление о личности переводчика, его общественно-политических интересах и стиле переводов. Также есть справочный материал — словарь основных понятий.
https://sysblok.ru/history/carskie-svitki-i-biografija-konfucija-chto-est-v-korpuse-russkih-perevodov-obshhestvenno-politicheskih-sochinenij-xviii-veka/
Виолетта Арстанова
#history
Русский политический язык начал формироваться в XVIII веке. Это время во многом стало переломным для русского общества. Оно стало больше ориентироваться на Запад, и идеи Просвещения затронули все сферы жизни. Тогда же стали активно переводиться различные издания о политике: от памфлетов до словарей и учебных пособий.
Осенью 2020 года Высшая школа экономики в сотрудничестве с Германским историческим институтом в Москве представили корпус переводов общественно-политических текстов XVIII века. Он помогает проследить формирование русского политического языка. В корпусе есть философские трактаты, художественные произведения политического характера, учебники и словари.
Как работать с корпусом
На сайте доступны два вида поиска — простой и расширенный. Результат запроса содержит количество совпадений, которые классифицируются на переводы, образцы, оригиналы и т. п. Также показывается место хранения перевода и год публикации.
Каждый перевод представлен в виде ссылки на отсканированное печатное издание. Его описание содержит краткие сведения о сочинении, его переводчике, основной теме текста, его издании и месте хранения оригинала.
Еще на сайте созданы страницы переводчиков, где собраны все переводы, выполненные одним человеком. Это дает представление о личности переводчика, его общественно-политических интересах и стиле переводов. Также есть справочный материал — словарь основных понятий.
https://sysblok.ru/history/carskie-svitki-i-biografija-konfucija-chto-est-v-korpuse-russkih-perevodov-obshhestvenno-politicheskih-sochinenij-xviii-veka/
Виолетта Арстанова
{kind=link}
Старое новое: почти 300 лет истории дистанта
#history
Несмотря на то, что дистанционный формат кажется относительно новым явлением, он появился гораздо раньше: в 2028 г. ему исполнится 300 лет.
XVIII век
Дистанционный формат появился в XVIII веке. Профессор Калеб Филипс организовал дистанционные курсы стенографического письма: желающие могли откликнуться на объявление, размещенное в Boston Gazette. Курс не предусматривал обратной связи.
XIX век
Появляются дистанционные курсы с обратной связью. Этот формат назывался корреспондентским обучением: студентам по почте отправляли учебные материалы и задания, после они отправляли их на проверку.
• В 1840 г. британский учёный Айзек Питман организовал курс стенографии.
• В 1856 г. француз Шарль Туссан и немец Густав Лангеншайдт организовали разговорные курсы по иностранным языкам.
• В 1873 г. писательница Анна Эллиот Тикнор организовала «Общество поощрения обучения на дому». Это была настоящая заочная школа, где женщины получали полноценное высшее образование. В школе Тикнор учились не только состоятельные дамы, но и представительницы рабочего класса.
XX век
В 1969 г. в Лондоне появился первый радио- и телевизионный университет — Открытый университет. Он располагался в бывших студиях телеканала BBC. Оттуда транслировались 30-минутные лекции, которые студенты смотрели и слушали в прямом эфире. Преподаватели также общались со студентами по почте и во время летних очных школ.
Университет практиковал принцип open broadcasting: лекции доступны всем желающим, но вот зачесть их могут только поступившие студенты.
Вскоре похожие университеты появились и в других странах:
• 1972 г. — Национальный университет Дистанционного Образования (Испания) и Корейский Национальный Открытый Университет.
• 1985 г. — Национальный Открытый Университет имени Индиры Ганди (Индия).
• 1986 г. — Центральный Радио- и Телевизионный Университет (Китай). Ему подчинялось 28 районных дистанционных университетов и 300 школ.
XXI век
С появлением компьютеров дистанционное образование становится более мобильным. В 1989 г. коммерческий Университет Феникса запустил первые онлайн–программы для студентов. Уже в 2005 г. почти половина студентов Университета Феникса занималась дистанционно.
А первым в истории аккредитованным онлайн–университетом стал Международный Университет Джонса в штате Колорадо.
В 2020 г. дистанционное обучение начали применять повсеместно из-за пандемии коронавируса.
https://sysblok.ru/history/staroe-novoe-pochti-300-let-istorii-distanta/
Мария Черных
#history
Несмотря на то, что дистанционный формат кажется относительно новым явлением, он появился гораздо раньше: в 2028 г. ему исполнится 300 лет.
XVIII век
Дистанционный формат появился в XVIII веке. Профессор Калеб Филипс организовал дистанционные курсы стенографического письма: желающие могли откликнуться на объявление, размещенное в Boston Gazette. Курс не предусматривал обратной связи.
XIX век
Появляются дистанционные курсы с обратной связью. Этот формат назывался корреспондентским обучением: студентам по почте отправляли учебные материалы и задания, после они отправляли их на проверку.
• В 1840 г. британский учёный Айзек Питман организовал курс стенографии.
• В 1856 г. француз Шарль Туссан и немец Густав Лангеншайдт организовали разговорные курсы по иностранным языкам.
• В 1873 г. писательница Анна Эллиот Тикнор организовала «Общество поощрения обучения на дому». Это была настоящая заочная школа, где женщины получали полноценное высшее образование. В школе Тикнор учились не только состоятельные дамы, но и представительницы рабочего класса.
XX век
В 1969 г. в Лондоне появился первый радио- и телевизионный университет — Открытый университет. Он располагался в бывших студиях телеканала BBC. Оттуда транслировались 30-минутные лекции, которые студенты смотрели и слушали в прямом эфире. Преподаватели также общались со студентами по почте и во время летних очных школ.
Университет практиковал принцип open broadcasting: лекции доступны всем желающим, но вот зачесть их могут только поступившие студенты.
Вскоре похожие университеты появились и в других странах:
• 1972 г. — Национальный университет Дистанционного Образования (Испания) и Корейский Национальный Открытый Университет.
• 1985 г. — Национальный Открытый Университет имени Индиры Ганди (Индия).
• 1986 г. — Центральный Радио- и Телевизионный Университет (Китай). Ему подчинялось 28 районных дистанционных университетов и 300 школ.
XXI век
С появлением компьютеров дистанционное образование становится более мобильным. В 1989 г. коммерческий Университет Феникса запустил первые онлайн–программы для студентов. Уже в 2005 г. почти половина студентов Университета Феникса занималась дистанционно.
А первым в истории аккредитованным онлайн–университетом стал Международный Университет Джонса в штате Колорадо.
В 2020 г. дистанционное обучение начали применять повсеместно из-за пандемии коронавируса.
https://sysblok.ru/history/staroe-novoe-pochti-300-let-istorii-distanta/
Мария Черных
{kind=link}
Ткани онлайн: как оцифровать полотно в 6 метров
#arts #history
Многие ткани — важные музейные экспонаты. Иногда это небольшие фартуки, но чаще — массивные платья с многочисленными узорами.
Что происходит с тканями, которым уже более ста лет? Ответ прост: их оцифровывают, как и другие артефакты.
Техники нанесения узора на ткань
Ценность экспоната заключается не только в узорах, но и способах создания:
• Ручная набивка — появилась в 10 веке. По деревянной форме ударяли специальным молотком — киянкой. Тиснение отпечатывалось на заранее окрашенной ткани.
• Механическая печать — на поверхности металлического вала гравировался рисунок, который мастер переносил на носитель. После инструмент окунали в краситель, благодаря чему выгравированный на ролике узор переносился на материал.
• Прямая печать — самая поздняя техника. Для легкой ткани используется обычный алгоритм работы струйного принтера, для плотной необходимо предварительное нанесение специальной грунтовки.
Оцифровка ткани
Чтобы превратить полотна в цифровые файлы, сканируют каждый узор. С помощью сканера формата А3 определяют уникальный фрагмент на ткани, повторяющийся рисунок. Затем происходит склеивание: деталь соединяют, регулируя радиус каждого кусочка. В конце работы формируется готовый файл, который хранится в облаке.
Мультимедийные экспозиции
Лондонский музей Виктории и Альберта создал виртуальную выставку, на которой можно увидеть антикварные и новые ткани из собраний модного дома Александра Маккуина.
А в России в Ивановском краеведческом музее создали онлайн–выставку, посвященную тканям прошлых столетий. В экспозиции представлены 300 тканей русских костюмов XIX–XX веков.
https://sysblok.ru/arts/tkani-onlajn-kak-ocifrovat-polotno-v-6-metrov/
Лиза Снежко
#arts #history
Многие ткани — важные музейные экспонаты. Иногда это небольшие фартуки, но чаще — массивные платья с многочисленными узорами.
Что происходит с тканями, которым уже более ста лет? Ответ прост: их оцифровывают, как и другие артефакты.
Техники нанесения узора на ткань
Ценность экспоната заключается не только в узорах, но и способах создания:
• Ручная набивка — появилась в 10 веке. По деревянной форме ударяли специальным молотком — киянкой. Тиснение отпечатывалось на заранее окрашенной ткани.
• Механическая печать — на поверхности металлического вала гравировался рисунок, который мастер переносил на носитель. После инструмент окунали в краситель, благодаря чему выгравированный на ролике узор переносился на материал.
• Прямая печать — самая поздняя техника. Для легкой ткани используется обычный алгоритм работы струйного принтера, для плотной необходимо предварительное нанесение специальной грунтовки.
Оцифровка ткани
Чтобы превратить полотна в цифровые файлы, сканируют каждый узор. С помощью сканера формата А3 определяют уникальный фрагмент на ткани, повторяющийся рисунок. Затем происходит склеивание: деталь соединяют, регулируя радиус каждого кусочка. В конце работы формируется готовый файл, который хранится в облаке.
Мультимедийные экспозиции
Лондонский музей Виктории и Альберта создал виртуальную выставку, на которой можно увидеть антикварные и новые ткани из собраний модного дома Александра Маккуина.
А в России в Ивановском краеведческом музее создали онлайн–выставку, посвященную тканям прошлых столетий. В экспозиции представлены 300 тканей русских костюмов XIX–XX веков.
https://sysblok.ru/arts/tkani-onlajn-kak-ocifrovat-polotno-v-6-metrov/
Лиза Снежко
{kind=link}
Создание робота-клона и дружба с нейросетью
#society
Компании все чаще представляют новые модели роботов-андроидов. У робототехников большие планы на будущее: андроиды возьмут на себя рутинную и опасную работу. Но есть и другая сторона: роботы-клоны.
Для создания стопроцентной идентичности человека и машины потребуются годы. Даже самого продвинутого на сегодняшний день андроида Софию пока не спутаешь с человеком. Но уже возник вопрос: является ли производство двойников и клонов технологическим будущим или это практика, не вписывающаяся в этические нормы.
Заказы в робототехнике
Нестандартные пожелания — вовсе не редкость в рабочей рутине производителей роботов. В компании Promobot столкнулись со следующим кейсом: после развода с женой бразилец заказал точную копию сына, поскольку жена запретила видеться с ребенком. Компания отказалась брать заказ из-за морально-этических принципов.
Большинство предприятий отказывается от двух направлений: клонирования умерших людей и создания секс-роботов. Тем не менее, в Promobot можно заказать робота-двойника: модель Robo-С создается на основе нескольких фотографий.
Дружба с ИИ
Наши представления об ИИ и роботах сформированы массовой культурой. Тимофей Нестик, заведующий лабораторией социальной и экономической психологии Института психологии РАН, отмечает следующие особенности «дружбы» с роботами:
• чем чаще люди пользуются цифровыми услугами, тем они меньше склонны связывать с ними ИИ;
• доверие к роботам и системам ИИ выше среди тех, кто больше доверяет людям;
• пользователь представляет опасность для ИИ, когда обучает негативному взгляду на мир;
• робот-клон не заменит умершего человека: скорее станет источником дополнительной травматизации.
Право и роботы
Важный вопрос — ответственность за действия системы. Пока наиболее вероятно привлечение к ответственности разработчиков вместе с владельцами систем, но в отношении андроидов даже это сейчас не рассматривается.
Также, в завещании уже можно заявить о желании или нежелании своего продолжения в виде клона или другого цифрового обличия.
https://sysblok.ru/society/chto-ne-tak-s-zhelaniem-sozdat-robota-klona/
Юлия Захарова
#society
Компании все чаще представляют новые модели роботов-андроидов. У робототехников большие планы на будущее: андроиды возьмут на себя рутинную и опасную работу. Но есть и другая сторона: роботы-клоны.
Для создания стопроцентной идентичности человека и машины потребуются годы. Даже самого продвинутого на сегодняшний день андроида Софию пока не спутаешь с человеком. Но уже возник вопрос: является ли производство двойников и клонов технологическим будущим или это практика, не вписывающаяся в этические нормы.
Заказы в робототехнике
Нестандартные пожелания — вовсе не редкость в рабочей рутине производителей роботов. В компании Promobot столкнулись со следующим кейсом: после развода с женой бразилец заказал точную копию сына, поскольку жена запретила видеться с ребенком. Компания отказалась брать заказ из-за морально-этических принципов.
Большинство предприятий отказывается от двух направлений: клонирования умерших людей и создания секс-роботов. Тем не менее, в Promobot можно заказать робота-двойника: модель Robo-С создается на основе нескольких фотографий.
Дружба с ИИ
Наши представления об ИИ и роботах сформированы массовой культурой. Тимофей Нестик, заведующий лабораторией социальной и экономической психологии Института психологии РАН, отмечает следующие особенности «дружбы» с роботами:
• чем чаще люди пользуются цифровыми услугами, тем они меньше склонны связывать с ними ИИ;
• доверие к роботам и системам ИИ выше среди тех, кто больше доверяет людям;
• пользователь представляет опасность для ИИ, когда обучает негативному взгляду на мир;
• робот-клон не заменит умершего человека: скорее станет источником дополнительной травматизации.
Право и роботы
Важный вопрос — ответственность за действия системы. Пока наиболее вероятно привлечение к ответственности разработчиков вместе с владельцами систем, но в отношении андроидов даже это сейчас не рассматривается.
Также, в завещании уже можно заявить о желании или нежелании своего продолжения в виде клона или другого цифрового обличия.
https://sysblok.ru/society/chto-ne-tak-s-zhelaniem-sozdat-robota-klona/
Юлия Захарова
{kind=link}
Разделяй и определяй, или Кто автор «Сна в красном тереме»
#philology
«Сон в красном тереме» — один из «четырех великих романов Китая». В нем повествуется о двух ветвях аристократической семьи Цзя и её постепенном упадке.
Оригинальная версия Цао Сюэциня содержит 80 частей, однако в 1791 году было опубликовано новое издание Гао Э из 120 частей. До сих пор ведутся дискуссии о том, сколько авторов у «Сна в красном тереме».
Поиски истинного автора
Метод Дельты Бёрроуза применяется для установления или уточнения авторства произведений.
Дельта представляет каждый текст в виде списка частотностей скольки-то (N) самых частотных слов — обычно берут от 100 и более слов. Таким образом текст становится вектором в N-мерном пространстве. Затем между этими векторами текстов измеряются расстояния — с помощью обычных геометрических мер близости. На основе этих расстояний и устанавливается наиболее вероятное авторство. Универсальность метода была многократно подтверждена на материале разных жанров, языков и эпох. В том числе на китайских текстах.
Если разложить главы согласно алгоритму кластеризации, видно что первые 80 глав наименее схожи с позднее опубликованными. Но есть исключение: главы 10 и 11, а так же 6 и 67 (из первой части) объединяются на первом шаге друг с другом, а уже на втором — с главами второй части. Возможные причины: неточный результат Дельты, большое количество имен собственных, редактура второго автора. Последнее проверяется с помощью тематического моделирования.
Тематическое моделирование
Для проверки результатов Дельты использовали версию романа, наиболее близкую к ранним изданиям.
• Предварительная обработка — токенизация и разделение. Это важно для разделения текста на слова, так как границы не обозначены пробелами.
• Формирование списка из стоп-слов — слова, которые нельзя интерпретировать.
• Определение тем — всего 50. Выходные данные свели в соответствии с главами.
• Визуализация — согласно соотношению тем с главами. Ось X – темы, ось Y – главы; красная линия разделяет первые 80 частей и последние 40.
• Распределение слов внутри темы — слова не связаны определенным мотивом.
Метод Дельты Бёллроуза не ошибся: действительно, главы 11 и 67 отличаются от первоначального текста романа. Отличаются не только именами персонажей или сюжетом, присутствуют и стилистические различия. С большей вероятностью, главы 11 и 67 отредактировал Гао Э.
https://sysblok.ru/philology/razdeljaj-i-opredeljaj-ili-kto-avtor-sna-v-krasnom-tereme/
Вероника Ганеева
#philology
«Сон в красном тереме» — один из «четырех великих романов Китая». В нем повествуется о двух ветвях аристократической семьи Цзя и её постепенном упадке.
Оригинальная версия Цао Сюэциня содержит 80 частей, однако в 1791 году было опубликовано новое издание Гао Э из 120 частей. До сих пор ведутся дискуссии о том, сколько авторов у «Сна в красном тереме».
Поиски истинного автора
Метод Дельты Бёрроуза применяется для установления или уточнения авторства произведений.
Дельта представляет каждый текст в виде списка частотностей скольки-то (N) самых частотных слов — обычно берут от 100 и более слов. Таким образом текст становится вектором в N-мерном пространстве. Затем между этими векторами текстов измеряются расстояния — с помощью обычных геометрических мер близости. На основе этих расстояний и устанавливается наиболее вероятное авторство. Универсальность метода была многократно подтверждена на материале разных жанров, языков и эпох. В том числе на китайских текстах.
Если разложить главы согласно алгоритму кластеризации, видно что первые 80 глав наименее схожи с позднее опубликованными. Но есть исключение: главы 10 и 11, а так же 6 и 67 (из первой части) объединяются на первом шаге друг с другом, а уже на втором — с главами второй части. Возможные причины: неточный результат Дельты, большое количество имен собственных, редактура второго автора. Последнее проверяется с помощью тематического моделирования.
Тематическое моделирование
Для проверки результатов Дельты использовали версию романа, наиболее близкую к ранним изданиям.
• Предварительная обработка — токенизация и разделение. Это важно для разделения текста на слова, так как границы не обозначены пробелами.
• Формирование списка из стоп-слов — слова, которые нельзя интерпретировать.
• Определение тем — всего 50. Выходные данные свели в соответствии с главами.
• Визуализация — согласно соотношению тем с главами. Ось X – темы, ось Y – главы; красная линия разделяет первые 80 частей и последние 40.
• Распределение слов внутри темы — слова не связаны определенным мотивом.
Метод Дельты Бёллроуза не ошибся: действительно, главы 11 и 67 отличаются от первоначального текста романа. Отличаются не только именами персонажей или сюжетом, присутствуют и стилистические различия. С большей вероятностью, главы 11 и 67 отредактировал Гао Э.
https://sysblok.ru/philology/razdeljaj-i-opredeljaj-ili-kto-avtor-sna-v-krasnom-tereme/
Вероника Ганеева
{kind=link}
Какой вы цифровой гуманитарий?
#test
В 2020 году стало еще сложнее ориентироваться в мире (и так вечно нестабильном). Мы придумали тест, который может помочь задать точки координат.
Пройдите тест, который покажет, кто вы в мире цифровых гуманитарных исследований. А заодно — познакомьтесь с известными цифровыми гуманитариями.
Дисклеймер: это шутка и только шутка.
https://sysblok.ru/test/kakoj-vy-cifrovoj-gumanitarij/
#test
В 2020 году стало еще сложнее ориентироваться в мире (и так вечно нестабильном). Мы придумали тест, который может помочь задать точки координат.
Пройдите тест, который покажет, кто вы в мире цифровых гуманитарных исследований. А заодно — познакомьтесь с известными цифровыми гуманитариями.
Дисклеймер: это шутка и только шутка.
https://sysblok.ru/test/kakoj-vy-cifrovoj-gumanitarij/
{kind=link}
Исследователи лавин смоделировали гибель группы Дятлова
#news
Некоторые эксперты считают, что смерть девяти туристов из группы Игоря Дятлова в 1959 году — результат схода лавины. Ученые из Швейцарии создали компьютерную модель, которая демонстрирует, как могли развиваться события.
Выяснили, что между размещением группы в лагере и возможным сходом снега прошло 9 часов. Компьютерная программа показала, что длина лавины на склоне горы Холатчахль была около 5 метров. Скользкая поверхность, крутой наклон в 30 градусов, сильные потоковые ветры и большое количество снега перед лагерем, — все это стало причиной гибели туристов.
Создатели проекта разработали модель движения снега, получив данные о силе и давлении на человеческое тело из тестов General Motors. По словам директора Лаборатории снега и лавин, симуляция демонстрирует ночь гибели группы с новой точностью. Однако команда подчеркивает, что представила только вероятную версию событий.
https://sysblok.ru/news/gibel-gruppy-djatlova-smodelirovali-v-laboratorii-lavin/
Варвара Гузий
#news
Некоторые эксперты считают, что смерть девяти туристов из группы Игоря Дятлова в 1959 году — результат схода лавины. Ученые из Швейцарии создали компьютерную модель, которая демонстрирует, как могли развиваться события.
Выяснили, что между размещением группы в лагере и возможным сходом снега прошло 9 часов. Компьютерная программа показала, что длина лавины на склоне горы Холатчахль была около 5 метров. Скользкая поверхность, крутой наклон в 30 градусов, сильные потоковые ветры и большое количество снега перед лагерем, — все это стало причиной гибели туристов.
Создатели проекта разработали модель движения снега, получив данные о силе и давлении на человеческое тело из тестов General Motors. По словам директора Лаборатории снега и лавин, симуляция демонстрирует ночь гибели группы с новой точностью. Однако команда подчеркивает, что представила только вероятную версию событий.
https://sysblok.ru/news/gibel-gruppy-djatlova-smodelirovali-v-laboratorii-lavin/
Варвара Гузий
{kind=link}
Пообедать у Канта: калининградские ученые воссоздают дом философа в 3D
#digitalheritage
Иммануил Кант — основоположник немецкой классической философии, автор знаменитых «Критик» — проживал в Кенигсберге с 1783 по 1804 год. Кант также известен легендарными застольными вечеринками — обедами, на которые он приглашал своих друзей. Однако дом, в котором он жил, не сохранился: его снесли и построили на его месте новое здание.
К 300-летию философа команда Центра социально-гуманитарной информатики Балтийского федерального университета создает «Виртуальный дом Канта». Проект 3D-реконструкции предполагает визуализацию внешнего вида и помещений особняка, объединённых в интерактивную панораму.
На что опирались при реконструкции
Основной источник — работа Вальтера Курке, служащего муниципального строительного управления Кенигсберга. В 1917 году он воссоздал внешний и внутренний облик дома на основе земельных книг и воспоминаний владельца дома профессора Доббелина.
Также использовали гравюры, открытки, картины этого периода, работы зарубежных и отечественных кантоведов и фотографии вещей Канта из музея в Кенигсберге — треуголки, трости, секретера и пуговицы. При воссоздании столовой опирались на картину Эмиля Дерстлинга «Кант и его сотрапезники».
Как ведется реконструкция
Работа началась с составления чертежей и планировок дома. Дом был двухэтажный, с пристройкой и сводчатым подвалом. На нижнем этаже находились лекционный зал и комната повара, на верхнем — столовая, библиотека, спальня, гостиная и кабинет; на маленьком чердаке жил слуга. Для моделирования выбрали программу 3ds MAX.
В процессе работы выявили и исправили неточности в реконструкции внешнего облика дома: изменили количество люкарн, сделали скатные крыши к каждой их них, создали крышу ангарного типа.
Следующий шаг — поэтапная реконструкция столовой и лекционной комнаты, в которых отразили все предметы быта, декор и даже еду. Сначала создали экстерьер, затем наполнили модель предметами интерьера.
Сейчас команда восстанавливает библиотеку Канта — ведет розыск и оцифровку книг. Это наиболее сложная часть проекта, так как на момент смерти владельца библиотека состояла из пятисот книг и брошюр. В планах — реализовать интерактивный функционал, который позволит «брать» книги с полок и листать их в 3D-формате, а также переходить в режим электронного чтения.
https://sysblok.ru/digital-heritage/poobedat-u-kanta-kaliningradskie-uchenye-vossozdajut-dom-filosofa-v-3d/
Е. В. Баранова, В. А. Верещагин, В. Н. Маслов, М. М. Лопатин
#digitalheritage
Иммануил Кант — основоположник немецкой классической философии, автор знаменитых «Критик» — проживал в Кенигсберге с 1783 по 1804 год. Кант также известен легендарными застольными вечеринками — обедами, на которые он приглашал своих друзей. Однако дом, в котором он жил, не сохранился: его снесли и построили на его месте новое здание.
К 300-летию философа команда Центра социально-гуманитарной информатики Балтийского федерального университета создает «Виртуальный дом Канта». Проект 3D-реконструкции предполагает визуализацию внешнего вида и помещений особняка, объединённых в интерактивную панораму.
На что опирались при реконструкции
Основной источник — работа Вальтера Курке, служащего муниципального строительного управления Кенигсберга. В 1917 году он воссоздал внешний и внутренний облик дома на основе земельных книг и воспоминаний владельца дома профессора Доббелина.
Также использовали гравюры, открытки, картины этого периода, работы зарубежных и отечественных кантоведов и фотографии вещей Канта из музея в Кенигсберге — треуголки, трости, секретера и пуговицы. При воссоздании столовой опирались на картину Эмиля Дерстлинга «Кант и его сотрапезники».
Как ведется реконструкция
Работа началась с составления чертежей и планировок дома. Дом был двухэтажный, с пристройкой и сводчатым подвалом. На нижнем этаже находились лекционный зал и комната повара, на верхнем — столовая, библиотека, спальня, гостиная и кабинет; на маленьком чердаке жил слуга. Для моделирования выбрали программу 3ds MAX.
В процессе работы выявили и исправили неточности в реконструкции внешнего облика дома: изменили количество люкарн, сделали скатные крыши к каждой их них, создали крышу ангарного типа.
Следующий шаг — поэтапная реконструкция столовой и лекционной комнаты, в которых отразили все предметы быта, декор и даже еду. Сначала создали экстерьер, затем наполнили модель предметами интерьера.
Сейчас команда восстанавливает библиотеку Канта — ведет розыск и оцифровку книг. Это наиболее сложная часть проекта, так как на момент смерти владельца библиотека состояла из пятисот книг и брошюр. В планах — реализовать интерактивный функционал, который позволит «брать» книги с полок и листать их в 3D-формате, а также переходить в режим электронного чтения.
https://sysblok.ru/digital-heritage/poobedat-u-kanta-kaliningradskie-uchenye-vossozdajut-dom-filosofa-v-3d/
Е. В. Баранова, В. А. Верещагин, В. Н. Маслов, М. М. Лопатин
{kind=link}
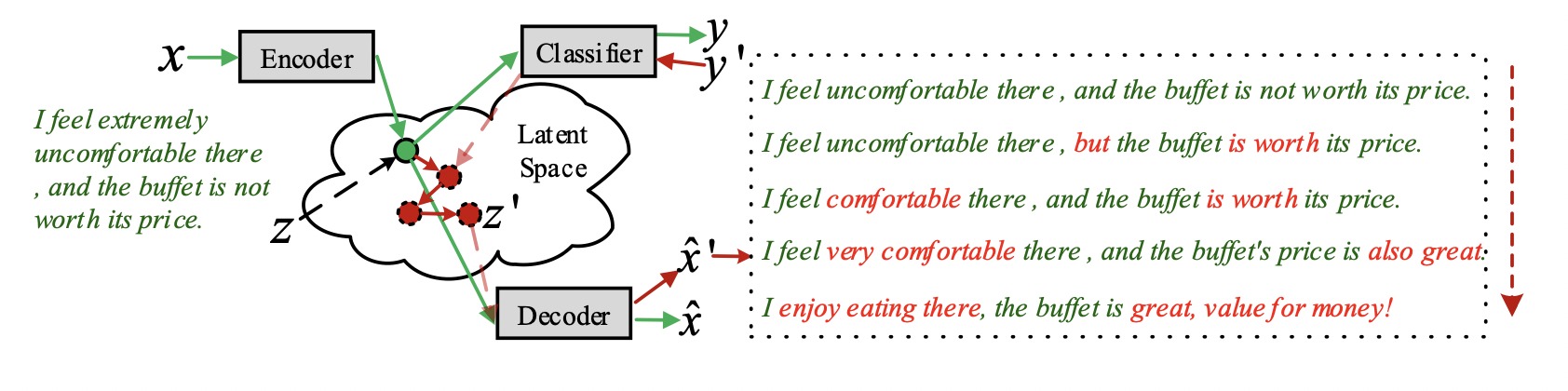
Как нейросеть заменяет нецензурную лексику на эвфемизмы
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
#knowhow #nlp
Машинное обучение разрешает менять стилистику текста без изменения содержания. Например, нейросеть сгенерировала песни в стиле Егора Летова, а также ведет аккаунт Neural Meduza в Twitter`е. Однако методы генерации и стилизации текстов приносят и практическую пользу.
ВКонтакте фильтрует комментарии
ВКонтакте тестирует новые функции: сервис учится фильтровать оскорбительные комментарии в сообществах, а также предупреждать пользователей о неприемлемом тоне высказываний. Так как диаметральная смена окраски комментариев — это нарушение свободы слова, нашли полумеру: нецензурная лексика будет заменяться эвфемизмами, а остальные высказывания — «сглаживаться».
Перенос стиля: как это работает
Перенос стиля основан на изменении векторных представлений текстов. Мы уже рассказывали, как создаются такие вектора.
Чтобы научиться переносить стиль текста, потребуется:
1. два корпуса текстов с противоположными стилями: положительный и отрицательный, токсичный и обычный и т.д.
2. автокодировщик, который нужно обучить тому, как представлять тексты в виде векторов
Алгоритм следующий:
1. обучаем кодировщик на обоих корпусах
2. получаем векторные представления текстов стиля 1
3. изменяем полученные вектора в соответствии с векторами текста стиля 2
4. подаем измененные вектора на вход декодировщику
5. получаем тексты стиля 2
Основная задача — изменить векторы так, чтобы на выходе получился текст нужного стиля. Для этого берем векторные представления текстов для обоих корпусов и обучаем на них новую нейронную сеть определять стиль текста. После обучения пытаемся её обмануть: берём вектор текста стиля 1 и добавляем шум. Шум подбираем таким образом, чтобы нейросеть перепутала стиль и на выходе мы получили текст стиля 2.
Альтернативное решение
Есть более сложный и продвинутый метод, который позволяет менять стиль и содержание текста независимо друг от друга. В этом случае вся информация о стиле содержится в одной части вектора, а информация о содержании — в другой.
https://sysblok.ru/knowhow/v-prostranstve-tekstov-detoksikacija-kommentariev-poddelka-otzyvov-i-nejrocenzura/
Михаил Ким
{kind=link}
Подборка интерактивных карт по истории
#history
Интерактивный палеоглобус — проект, похожий на Google Earth, но показывающий не только современность, но и прошлое. Иллюстрирует, как меняется распределение суши и моря за последние 750 млн лет. Автор — Ian Webster, в основу легли работы геолога Christopher R. Scotese.
Интерактивный атлас поможет разобраться где, когда и какие государства существовали. В легенде карты можно выбрать год — с 3000 лет до н.э. до нашего времени — и увидеть политическую карту того времени. Автор — Luis Muzquiz.
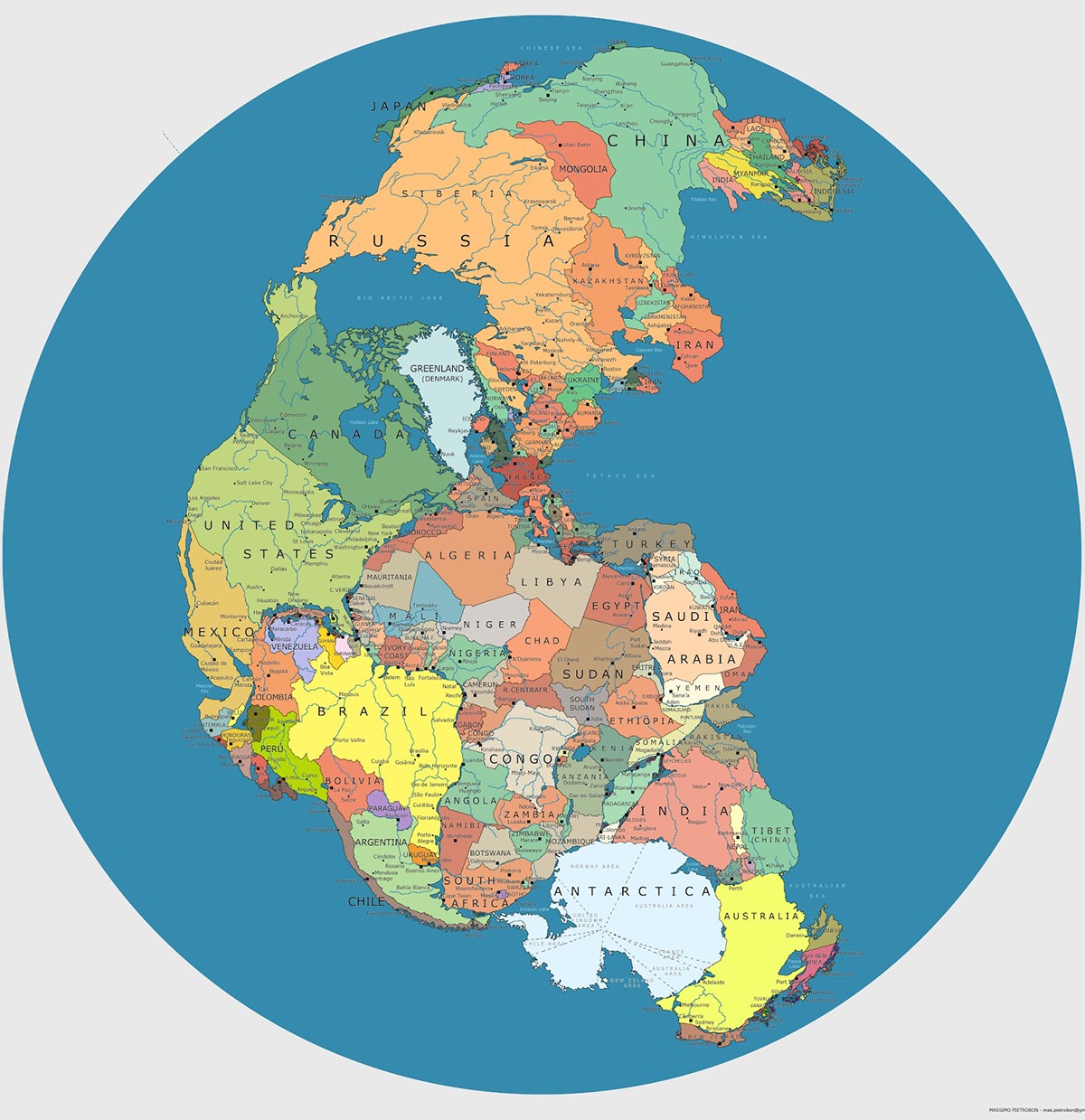
Pangea Politica — карта материка Пангеи, на которой Massimo Pietrobon отметил границы современных государств. Пангея существовала 300 млн лет назад и с течение времени распалась на современные материки.
World Population History — карта, которая показывает, как росло население с 1 г. н.э. до нашего времени, а также прогнозирует дальнейший рост до 2050 года. Один кружок на карте — миллион человек, проживающих в этом регионе. В легенде карты отмечены переломные для развития цивилизации события.
Платформа Orbis рассчитает, сколько времени и денег потребовалось бы вам, чтобы добраться из одного города в другой — во времена, когда не было ни машин, ни поездов, ни самолетов. Можно выставить в приоритет скорость, цену или расстояние, а также указать время года и вид транспорта. Проект создан при Кембриджском университете.
Географический справочник Pleiades — крупнейшая база данных античных мест: это и поселения, и конкретные сооружения, и географические объекты. Каждое памятное место четко привязано к координатам. Всего в базе 37 500 записей. Пользователи могут исправлять неточности и предлагать новые места.
https://sysblok.ru/history/podborka-interaktivnyh-kart-po-istorii/
Светлана Филатова
#history
Интерактивный палеоглобус — проект, похожий на Google Earth, но показывающий не только современность, но и прошлое. Иллюстрирует, как меняется распределение суши и моря за последние 750 млн лет. Автор — Ian Webster, в основу легли работы геолога Christopher R. Scotese.
Интерактивный атлас поможет разобраться где, когда и какие государства существовали. В легенде карты можно выбрать год — с 3000 лет до н.э. до нашего времени — и увидеть политическую карту того времени. Автор — Luis Muzquiz.
Pangea Politica — карта материка Пангеи, на которой Massimo Pietrobon отметил границы современных государств. Пангея существовала 300 млн лет назад и с течение времени распалась на современные материки.
World Population History — карта, которая показывает, как росло население с 1 г. н.э. до нашего времени, а также прогнозирует дальнейший рост до 2050 года. Один кружок на карте — миллион человек, проживающих в этом регионе. В легенде карты отмечены переломные для развития цивилизации события.
Платформа Orbis рассчитает, сколько времени и денег потребовалось бы вам, чтобы добраться из одного города в другой — во времена, когда не было ни машин, ни поездов, ни самолетов. Можно выставить в приоритет скорость, цену или расстояние, а также указать время года и вид транспорта. Проект создан при Кембриджском университете.
Географический справочник Pleiades — крупнейшая база данных античных мест: это и поселения, и конкретные сооружения, и географические объекты. Каждое памятное место четко привязано к координатам. Всего в базе 37 500 записей. Пользователи могут исправлять неточности и предлагать новые места.
https://sysblok.ru/history/podborka-interaktivnyh-kart-po-istorii/
Светлана Филатова
{kind=link}
Виден ли конец «нейронного блицкрига»: компьютерные лингвисты между вычислением и теорией
Восьмой выпуск подкаста Неопознанный искусственный интеллект — с Денисом Кирьяновым
#podcasts
Денис работает в SberDevices, он — один из создателей семейства голосовых помощников «Салют».
В этом выпуске:
01:33 — как делали голосовых помощников «Салют»
03:25 — чем машина все еще хуже человека: проблема целеполагания
06:53 — «писули» от «волшебной машины»: почему GPT-3 генерирует фейковые факты и выдуманные названия рок-групп
10:50 — как сделать персональных помощников более человекоподобными: проактивные ИИ-зануды
14:22 — как машине научиться делать то, чего она никогда не видела
16:55 — конец нейронного блицкрига: «забрасывать железом» компьютерно-лингвистические задачи больше не модно
17:59 — применение лингвистики в разработке голосовых помощников
19:07 — вычислительная лингвистика versus лингвистическая теория
24:30 — лингвисты между двумя стульями: преодолим ли разрыв между теоретиками и компьютерщиками
28:24 — что могут дать компьютерные модели теоретическим лингвистам
31:22 — когда нейросети начнут создавать новые теории
39:31 — ИИ будущего и межкультурные различия
40:54 — как должно быть устроено образование в области автоматической обработки языка
43:42 — Data Science в курятнике и кибер-village
Хайлайты выпуска
1. О «волшебстве» GPT-3
GPT-3 позиционируется как машина, которая может решать много разных задач. Если написать начало стихотворения — модель может продолжить в стихах. Если подать пары фраз на русском и английском — GPT-3 продолжит переводить. А если показать, как превращать длинный текст в короткий, модель научится делать и это.
Поэтому GPT-3 часто называют «универсальным решателем задач». Однако, качество работы GPT-3 пока отстает от человеческого на десятки процентов. Она может иногда сгенерировать хороший и правдивый текст, но в любой момент может породить и фейк. Поэтому GPT-3 сложно считать по-настоящему умной моделью.
2. Об обучении языковых моделей
Исследователи пришли к выводу, что для дальнейшего развития нейросетевых моделей недостаточно только количественных изменений — увеличения мощности серверов или размера корпуса, на котором обучается модель.
Нужно привносить что-то новое в архитектуру — искать способы передать машине больше знаний о реальном мире в каком-либо формальном представлении. Например, с помощью «графов знаний» (knowledge graphs).
3. О взаимосвязи между теоретической и компьютерной лингвистикой
Вопрос о том, как лингвистика поможет NLP, стоит давно, и им занимается много людей. А вот обратный вопрос — как NLP поможет понять что-то фундаментально новое о языке — пока менее популярен.
Сейчас ученые пытаются расшифровать «черные ящики» внтури языковых моделей: появляются статьи о том, что на одном из слоев BERTа находится нечто, похожее на синтаксис, на другом — нечто, похожее на морфологию, и т. д. Вероятно, векторные представления значений, с таким успехом применяемые в NLP, также могли бы обогатить такую область лингвистики, как семантика.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Google Podcasts или в подкастах ВК.
Расшифровка и дополнительные материалы — на странице подкаста на сайте «Системного Блока».
Восьмой выпуск подкаста Неопознанный искусственный интеллект — с Денисом Кирьяновым
#podcasts
Денис работает в SberDevices, он — один из создателей семейства голосовых помощников «Салют».
В этом выпуске:
01:33 — как делали голосовых помощников «Салют»
03:25 — чем машина все еще хуже человека: проблема целеполагания
06:53 — «писули» от «волшебной машины»: почему GPT-3 генерирует фейковые факты и выдуманные названия рок-групп
10:50 — как сделать персональных помощников более человекоподобными: проактивные ИИ-зануды
14:22 — как машине научиться делать то, чего она никогда не видела
16:55 — конец нейронного блицкрига: «забрасывать железом» компьютерно-лингвистические задачи больше не модно
17:59 — применение лингвистики в разработке голосовых помощников
19:07 — вычислительная лингвистика versus лингвистическая теория
24:30 — лингвисты между двумя стульями: преодолим ли разрыв между теоретиками и компьютерщиками
28:24 — что могут дать компьютерные модели теоретическим лингвистам
31:22 — когда нейросети начнут создавать новые теории
39:31 — ИИ будущего и межкультурные различия
40:54 — как должно быть устроено образование в области автоматической обработки языка
43:42 — Data Science в курятнике и кибер-village
Хайлайты выпуска
1. О «волшебстве» GPT-3
GPT-3 позиционируется как машина, которая может решать много разных задач. Если написать начало стихотворения — модель может продолжить в стихах. Если подать пары фраз на русском и английском — GPT-3 продолжит переводить. А если показать, как превращать длинный текст в короткий, модель научится делать и это.
Поэтому GPT-3 часто называют «универсальным решателем задач». Однако, качество работы GPT-3 пока отстает от человеческого на десятки процентов. Она может иногда сгенерировать хороший и правдивый текст, но в любой момент может породить и фейк. Поэтому GPT-3 сложно считать по-настоящему умной моделью.
2. Об обучении языковых моделей
Исследователи пришли к выводу, что для дальнейшего развития нейросетевых моделей недостаточно только количественных изменений — увеличения мощности серверов или размера корпуса, на котором обучается модель.
Нужно привносить что-то новое в архитектуру — искать способы передать машине больше знаний о реальном мире в каком-либо формальном представлении. Например, с помощью «графов знаний» (knowledge graphs).
3. О взаимосвязи между теоретической и компьютерной лингвистикой
Вопрос о том, как лингвистика поможет NLP, стоит давно, и им занимается много людей. А вот обратный вопрос — как NLP поможет понять что-то фундаментально новое о языке — пока менее популярен.
Сейчас ученые пытаются расшифровать «черные ящики» внтури языковых моделей: появляются статьи о том, что на одном из слоев BERTа находится нечто, похожее на синтаксис, на другом — нечто, похожее на морфологию, и т. д. Вероятно, векторные представления значений, с таким успехом применяемые в NLP, также могли бы обогатить такую область лингвистики, как семантика.
Где нас слушать или читать
Слушайте выпуск на Яндекс. Музыке, Apple Podcasts, Google Podcasts или в подкастах ВК.
Расшифровка и дополнительные материалы — на странице подкаста на сайте «Системного Блока».
{kind=link}
История в лицах: как могли бы выглядеть римские императоры
#history #news
Дизайнер виртуальной реальности Даниэль Воршат опубликовал изображения 54 римских императоров. Цель проекта — создать у зрителя ощущение, что перед ним не вселяющий ужас Калигула, а всего лишь человек.
Фотографии создали с помощью нейросети Artbreeder. В начале художник загрузил в ИИ 800 фотографий бюстов римских императоров, снятых под разным углом. Затем все загруженные данные синтезировались в единый портрет.
Если бюстов не было, Воршат опирался на изображения с древних монет или на письменные источники. Сгенерированные картины дизайнер раскрасил вручную: на каждую ушло по 15—16 часов. В процессе он использовал информацию из исторических документов, содержащих описание внешности императоров.
Невозможно узнать, насколько точны изображения Воршата. Однако интерпретации художника пользуются успехом: плакаты с римскими императорами можно купить в интернет-магазине Etsy.
https://sysblok.ru/history/vr-dizajner-ozhivil-54-rimskih-imperatora/
Мария Черных
#history #news
Дизайнер виртуальной реальности Даниэль Воршат опубликовал изображения 54 римских императоров. Цель проекта — создать у зрителя ощущение, что перед ним не вселяющий ужас Калигула, а всего лишь человек.
Фотографии создали с помощью нейросети Artbreeder. В начале художник загрузил в ИИ 800 фотографий бюстов римских императоров, снятых под разным углом. Затем все загруженные данные синтезировались в единый портрет.
Если бюстов не было, Воршат опирался на изображения с древних монет или на письменные источники. Сгенерированные картины дизайнер раскрасил вручную: на каждую ушло по 15—16 часов. В процессе он использовал информацию из исторических документов, содержащих описание внешности императоров.
Невозможно узнать, насколько точны изображения Воршата. Однако интерпретации художника пользуются успехом: плакаты с римскими императорами можно купить в интернет-магазине Etsy.
https://sysblok.ru/history/vr-dizajner-ozhivil-54-rimskih-imperatora/
Мария Черных
{kind=link}