
Джеймс против Джойса: можно ли измерить сложность художественной литературы
#philology
Художественный текст сложный по определению, так как авторы используют средства художественной выразительности — метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и др. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии.
В этой статье рассказываем, как исследователи из Кембриджского университета измеряли сложность разнообразных по жанру и стилю произведений английской литературы XIX–XX веков.
Индекс Флеша
Чтобы найти индекс Флеша, вычисляют среднюю длину предложений в тексте, а также количество слогов в словах. Подробнее об индексе Флеша мы уже рассказывали в другой нашей статье.
Выяснилось, что многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют по этому критерию показатели выше, чем у авангардных романов Джойса «Улисс» и «Поминки по Финнегану».
Поэтому меры удобочитаемости (readability) не дают объективной картины для художественной литературы.
Абстрактность используемых слов
Существует словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности: испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст из выборки был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте.
Вестерн Кормака Маккарни «Кровавый меридиан» предсказуемо оказался в самом верху шкалы конкретности. Однако авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану».
Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Измерение культурного контекста
Исследователи Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность текста в сравнении с окружающим его контекстом — большим текстовым корпусом. Для своей задачи исследователи использовали Google Books Fiction — раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Ключевой параметр — относительная частота употребления слов: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Наименьшее значение получил роман «Поминки по Финнегану» (Finnegan’s Wake) Джойса, а наибольшее — «Крылья голубки» (Wings of the dove) Джеймса.
Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т. к. сравнивается относительная сложность произведений.
Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса: именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как простотой, так и сложностью.
https://sysblok.ru/philology/dzhejms-protiv-dzhojsa-o-slozhnosti-v-hudozhestvennoj-literature/
Мария Захарова
#philology
Художественный текст сложный по определению, так как авторы используют средства художественной выразительности — метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и др. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии.
В этой статье рассказываем, как исследователи из Кембриджского университета измеряли сложность разнообразных по жанру и стилю произведений английской литературы XIX–XX веков.
Индекс Флеша
Чтобы найти индекс Флеша, вычисляют среднюю длину предложений в тексте, а также количество слогов в словах. Подробнее об индексе Флеша мы уже рассказывали в другой нашей статье.
Выяснилось, что многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют по этому критерию показатели выше, чем у авангардных романов Джойса «Улисс» и «Поминки по Финнегану».
Поэтому меры удобочитаемости (readability) не дают объективной картины для художественной литературы.
Абстрактность используемых слов
Существует словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности: испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст из выборки был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте.
Вестерн Кормака Маккарни «Кровавый меридиан» предсказуемо оказался в самом верху шкалы конкретности. Однако авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану».
Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Измерение культурного контекста
Исследователи Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность текста в сравнении с окружающим его контекстом — большим текстовым корпусом. Для своей задачи исследователи использовали Google Books Fiction — раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Ключевой параметр — относительная частота употребления слов: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Наименьшее значение получил роман «Поминки по Финнегану» (Finnegan’s Wake) Джойса, а наибольшее — «Крылья голубки» (Wings of the dove) Джеймса.
Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т. к. сравнивается относительная сложность произведений.
Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса: именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как простотой, так и сложностью.
https://sysblok.ru/philology/dzhejms-protiv-dzhojsa-o-slozhnosti-v-hudozhestvennoj-literature/
Мария Захарова
{kind=link}
Виртуальный театр: VR-спектакли в России, Европе и Америке
VR — это способ погрузиться в другой мир, оставаясь в нашей реальности. Все дело в специальных очках и наушниках, которые проецируют цифровую картинку и звуки на то пространство, в котором находится пользователь.
В театре VR помогает сломать так называемую «четвертую стену», традиционно отделяющую зрителя от актеров, а также дает возможности для экспериментов.
Первый проект
Использование VR-технологий в искусстве началось в Америке в конце XX века. Все началось с эксперимента дизайнера и исследователя видеоигр Бренды Лорел, которая в 1994 году совместно с режиссером документального кино Рейчел Стриклэнд создала проект Placeholder.
Основой истории внутри постановки были взаимоотношения древних людей с местами, в которых они обитали. Каждый участник мог выбрать себе локацию и тотемное животное. На протяжении всего действия, участники могли оставлять голосовые сообщения, которые оставались в истории. Так зрители впервые попробовали себя в роли актеров, а создатели смогли воплотить новую форму повествования — многоуровневую, сложную концепцию.
Что VR дает театру
Для теоретиков театра внедрение VR-технологий — поле для рассуждений о новых концепциях взаимодействия актера и зрителя, новых формах сценографии и выстраивания мизансцен. VR-технологии меняют форму повествования в спектакле: нарратив становится не линейным, как это принято в классическом театре, а многомерным.
Здесь может возникнуть вопрос: если зритель сам выбирает, как разворачивается действие, то неужели история и действия героев от этого не меняются? Тупак Мартир, режиссер одного из британских VR-спектаклей, ответил на этот вопрос так: «История никогда не меняется, зритель выбирает то, на что ему смотреть. Мы лишь следуем тому пути, по которому они идут, понимая историю».
VR- спектакли на русской сцене
В нашей первой статье о VR-спектаклях рассказываем об отечественных постановках:
• «Клетка с попугаями» (реж. М. Диденко)
• «В поисках автора» (реж. Д. Чащин)
• «Я убил царя» (реж. М.Патласов)
https://sysblok.ru/arts/virtualnyj-teatr-vr-spektakli-v-rossii/
VR-спектакли в Европе
Во второй части трилогии рассказываем о Британских постановках:
• «Водолаз» (ориг. «Frogman»)
• «Нарисуй меня рядом» (ориг. «Draw Me Close»)
• «Космос внутри нас» (ориг. «Cosmos Within Us»)
• «Все виды Лимбо» (ориг. «All Kinds of Limbo»)
https://sysblok.ru/arts/virtualnyj-teatr-obzor-vr-spektaklej-v-evrope/
VR-спектакли в США
Несмотря на первенство американского театра в использовании VR, сегодня на американской сцене можно найти лишь два действительно крупных проекта:
• «Гамлет 360: дух отца» (ориг. «Hamlet 360: The Father’s Spirit»)
• «Под подарками» (ориг. «The Under Presents»)
https://sysblok.ru/arts/virtualnyj-teatr-vr-spektakli-v-ssha-pozvoljajut-pobyt-otcom-gamleta/
Даша Масленко
VR — это способ погрузиться в другой мир, оставаясь в нашей реальности. Все дело в специальных очках и наушниках, которые проецируют цифровую картинку и звуки на то пространство, в котором находится пользователь.
В театре VR помогает сломать так называемую «четвертую стену», традиционно отделяющую зрителя от актеров, а также дает возможности для экспериментов.
Первый проект
Использование VR-технологий в искусстве началось в Америке в конце XX века. Все началось с эксперимента дизайнера и исследователя видеоигр Бренды Лорел, которая в 1994 году совместно с режиссером документального кино Рейчел Стриклэнд создала проект Placeholder.
Основой истории внутри постановки были взаимоотношения древних людей с местами, в которых они обитали. Каждый участник мог выбрать себе локацию и тотемное животное. На протяжении всего действия, участники могли оставлять голосовые сообщения, которые оставались в истории. Так зрители впервые попробовали себя в роли актеров, а создатели смогли воплотить новую форму повествования — многоуровневую, сложную концепцию.
Что VR дает театру
Для теоретиков театра внедрение VR-технологий — поле для рассуждений о новых концепциях взаимодействия актера и зрителя, новых формах сценографии и выстраивания мизансцен. VR-технологии меняют форму повествования в спектакле: нарратив становится не линейным, как это принято в классическом театре, а многомерным.
Здесь может возникнуть вопрос: если зритель сам выбирает, как разворачивается действие, то неужели история и действия героев от этого не меняются? Тупак Мартир, режиссер одного из британских VR-спектаклей, ответил на этот вопрос так: «История никогда не меняется, зритель выбирает то, на что ему смотреть. Мы лишь следуем тому пути, по которому они идут, понимая историю».
VR- спектакли на русской сцене
В нашей первой статье о VR-спектаклях рассказываем об отечественных постановках:
• «Клетка с попугаями» (реж. М. Диденко)
• «В поисках автора» (реж. Д. Чащин)
• «Я убил царя» (реж. М.Патласов)
https://sysblok.ru/arts/virtualnyj-teatr-vr-spektakli-v-rossii/
VR-спектакли в Европе
Во второй части трилогии рассказываем о Британских постановках:
• «Водолаз» (ориг. «Frogman»)
• «Нарисуй меня рядом» (ориг. «Draw Me Close»)
• «Космос внутри нас» (ориг. «Cosmos Within Us»)
• «Все виды Лимбо» (ориг. «All Kinds of Limbo»)
https://sysblok.ru/arts/virtualnyj-teatr-obzor-vr-spektaklej-v-evrope/
VR-спектакли в США
Несмотря на первенство американского театра в использовании VR, сегодня на американской сцене можно найти лишь два действительно крупных проекта:
• «Гамлет 360: дух отца» (ориг. «Hamlet 360: The Father’s Spirit»)
• «Под подарками» (ориг. «The Under Presents»)
https://sysblok.ru/arts/virtualnyj-teatr-vr-spektakli-v-ssha-pozvoljajut-pobyt-otcom-gamleta/
Даша Масленко
{kind=link}
История адресной системы: как появились номера на домах
#history
Разбираемся, когда на домах появились адреса, кому они понадобились, как связаны с Просвещением, призывом в армию и дискриминацией евреев в Европе.
Античность. В античные времена дома носили имена своих владельцев, так как большинство общественных отношений того времени основывалось на личных знакомствах. Все друг друга знали, и найти дом Гая Ливия в столице древней Римской империи не составило бы труда.
Средневековье. В Средневековье находить нужные дома становилось труднее, так как города росли, и в одной Вене XVIII века домов с именем «Золотой орел» в центре было 6, а на окраинах — 23. Приходит пора менять адресную систему.
Эпоха Просвещения. Государство начинает присваивать зданиям номера, и люди начинают воспринимать дома отдельно от своих хозяев. В первую очередь нумерация домов, похожая на современную, начинает появляться в Лондоне, Париже, Праге и Ливерпуле.
Дома в Европе нумеровали, чтобы упростить работу пожарных служб, полиции и муниципалитета, а также процедуру военного призыва, координацию войск и их снабжение жильем на время стоянки в городе.
Способы нумеровать дома
С появлением номеров возникает вопрос: в каком порядке нумеровать дома? Вариантов множество, и отсюда — ужасная путаница. Для решения этой проблемы были придуманы несколько систем нумерации домов.
Европейская система. Это самая популярная система: по одной стороне улицы располагаются дома с четными номерами, напротив — с нечетными. Впервые она появилась в Филадельфии в 1790 году, и только спустя 15 лет — в Европе.
Возрастная система. Город застраивался от дома под номером один и постепенно разрастался, причем каждому новому дому присваивался номер больше предыдущего. Так, например, в старинной Праге застройка шла от первого дома в историческом районе Градчаны, Пражском Граде.
Районная система. В немецких Аугсбурге и Нюрнберге номера домов состояли из цифр и букв, причем последние соответствовали району города. Вокруг церкви Святого Себальда (район S — St. Sebald) по такой схеме расположились дома с номерами от S1 до S1706, а в районе церкви Святого Лаврентия (район L — St. Lorenz) — от L1 до L1578.
Поквартальная система. Распространена в нынешнем Мадриде. Отдельный номер присваивается каждому кварталу, называемому манзана, а каждому дому, расположенному внутри этого квартала, присваивается еще своя буква или цифра. Таким образом, чтобы найти нужный адрес нужно знать номер квартала, номер (или букву) дома и улицу, на которой он расположен.
Последовательная система. Нумерация идет сначала по одной стороне, а дойдя до конца улицы, разворачивается. В итоге первый дом расположен напротив последнего.
Метрическая система. Номер дома равен расстоянию от этого дома до нулевой отметки, то есть начала улицы. Подобные улицы часто можно встретить в странах Латинской Америки.
Декаметрическая система. Сочетание метрической и европейской систем: номер дома свидетельствует о расстоянии от него до нулевой отметки, при этом четные и нечетные номера расположены на разных сторонах улицы.
Как с помощью нумерации выражали антисемитизм
Во времена правления династии Габсбургов в Европе на одной улице можно было встретить дома с арабскими и римскими номерами. Арабскими цифрами помечались дома европейцев, римскими — евреев. Такое выражение антисемитизма часто встречалось в центральной Европе вплоть до XIX века.
Больше подробностей — в нашей статье: https://sysblok.ru/history/kak-na-domah-pojavilis-nomera-adresa-segodnja-i-300-let-nazad/
Мария Черных
#history
Разбираемся, когда на домах появились адреса, кому они понадобились, как связаны с Просвещением, призывом в армию и дискриминацией евреев в Европе.
Античность. В античные времена дома носили имена своих владельцев, так как большинство общественных отношений того времени основывалось на личных знакомствах. Все друг друга знали, и найти дом Гая Ливия в столице древней Римской империи не составило бы труда.
Средневековье. В Средневековье находить нужные дома становилось труднее, так как города росли, и в одной Вене XVIII века домов с именем «Золотой орел» в центре было 6, а на окраинах — 23. Приходит пора менять адресную систему.
Эпоха Просвещения. Государство начинает присваивать зданиям номера, и люди начинают воспринимать дома отдельно от своих хозяев. В первую очередь нумерация домов, похожая на современную, начинает появляться в Лондоне, Париже, Праге и Ливерпуле.
Дома в Европе нумеровали, чтобы упростить работу пожарных служб, полиции и муниципалитета, а также процедуру военного призыва, координацию войск и их снабжение жильем на время стоянки в городе.
Способы нумеровать дома
С появлением номеров возникает вопрос: в каком порядке нумеровать дома? Вариантов множество, и отсюда — ужасная путаница. Для решения этой проблемы были придуманы несколько систем нумерации домов.
Европейская система. Это самая популярная система: по одной стороне улицы располагаются дома с четными номерами, напротив — с нечетными. Впервые она появилась в Филадельфии в 1790 году, и только спустя 15 лет — в Европе.
Возрастная система. Город застраивался от дома под номером один и постепенно разрастался, причем каждому новому дому присваивался номер больше предыдущего. Так, например, в старинной Праге застройка шла от первого дома в историческом районе Градчаны, Пражском Граде.
Районная система. В немецких Аугсбурге и Нюрнберге номера домов состояли из цифр и букв, причем последние соответствовали району города. Вокруг церкви Святого Себальда (район S — St. Sebald) по такой схеме расположились дома с номерами от S1 до S1706, а в районе церкви Святого Лаврентия (район L — St. Lorenz) — от L1 до L1578.
Поквартальная система. Распространена в нынешнем Мадриде. Отдельный номер присваивается каждому кварталу, называемому манзана, а каждому дому, расположенному внутри этого квартала, присваивается еще своя буква или цифра. Таким образом, чтобы найти нужный адрес нужно знать номер квартала, номер (или букву) дома и улицу, на которой он расположен.
Последовательная система. Нумерация идет сначала по одной стороне, а дойдя до конца улицы, разворачивается. В итоге первый дом расположен напротив последнего.
Метрическая система. Номер дома равен расстоянию от этого дома до нулевой отметки, то есть начала улицы. Подобные улицы часто можно встретить в странах Латинской Америки.
Декаметрическая система. Сочетание метрической и европейской систем: номер дома свидетельствует о расстоянии от него до нулевой отметки, при этом четные и нечетные номера расположены на разных сторонах улицы.
Как с помощью нумерации выражали антисемитизм
Во времена правления династии Габсбургов в Европе на одной улице можно было встретить дома с арабскими и римскими номерами. Арабскими цифрами помечались дома европейцев, римскими — евреев. Такое выражение антисемитизма часто встречалось в центральной Европе вплоть до XIX века.
Больше подробностей — в нашей статье: https://sysblok.ru/history/kak-na-domah-pojavilis-nomera-adresa-segodnja-i-300-let-nazad/
Мария Черных
{kind=link}
Над пропастью поржи: интервью с техноблогером Вастриком
#interview
Технологический блогер vas3k (в миру программист Василий Зубарев) известен всему просвещенному интернету как автор постов о машинном обучении, VR, машинном переводе, блокчейне и других хайповых технологиях.
Вастрик — пример успешного авторского инди-блога про IT. Его посты переводят на английский, используют как пособие при трудоустройстве и учебный материал для лекций в университете.
Посты Вастрика — это панк-версия журнала «Юный техник» для читателей 18+. Погружение в инженерные детали сочетается с шутками в стиле «сибирский IT-гопник» и картинками в духе XKCD.
Буквально за неделю до COVID-карантина спецгруппа «Системного Блока» съездила в Берлин и записала это интервью.
О чем мы поговорили с Вастриком
• о том, для кого он пишет;
• о внутренней мотивации писать посты;
• о хайпе вокруг IT-образования;
• о пользе гуманитариев в решении проблем;
• о том, надо ли не-айтишнику глубоко разбираться в IT;
• об искусственном интеллекте;
• о тех, кто вдохновляет Вастрика;
• о переходе к закрытому комьюнити с подпиской.
https://sysblok.ru/interviews/nad-propastju-porzhi-intervju-s-tehnoblogerom-vastrikom/
Даниил Скоринкин, Илья Булгаков
#interview
Технологический блогер vas3k (в миру программист Василий Зубарев) известен всему просвещенному интернету как автор постов о машинном обучении, VR, машинном переводе, блокчейне и других хайповых технологиях.
Вастрик — пример успешного авторского инди-блога про IT. Его посты переводят на английский, используют как пособие при трудоустройстве и учебный материал для лекций в университете.
Посты Вастрика — это панк-версия журнала «Юный техник» для читателей 18+. Погружение в инженерные детали сочетается с шутками в стиле «сибирский IT-гопник» и картинками в духе XKCD.
Буквально за неделю до COVID-карантина спецгруппа «Системного Блока» съездила в Берлин и записала это интервью.
О чем мы поговорили с Вастриком
• о том, для кого он пишет;
• о внутренней мотивации писать посты;
• о хайпе вокруг IT-образования;
• о пользе гуманитариев в решении проблем;
• о том, надо ли не-айтишнику глубоко разбираться в IT;
• об искусственном интеллекте;
• о тех, кто вдохновляет Вастрика;
• о переходе к закрытому комьюнити с подпиской.
https://sysblok.ru/interviews/nad-propastju-porzhi-intervju-s-tehnoblogerom-vastrikom/
Даниил Скоринкин, Илья Булгаков
{kind=link}
Как выделяют и классифицируют сущности в художественных текстах
#nlp #philology
Человек схватывает новую информацию на лету: из контекста, из интонации, из невербального общения. А как помочь компьютеру понять, что Гарри — волшебник, Гендальф — майар, а Джон Сноу — одновременно Старк и Таргариен?
В NLP эти задачи называются Named-entity recognition (NER), то есть выделение сущностей, и Entity Typing (ET) — классификация сущностей. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг и собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.
Какие корпуса используют для классифицируют сущности
Обычно для выделения особенностей сущности и их классификации используются тексты Википедии. Этот метод работает, если нужно разобрать текст о реальном мире. Но если мы скормим программе текст «Властелина Колец», она выдаст неполный результат, т. к. в Википедии не хватает информации о вымышленных вселенных.
Эту проблему решили исследователи из Института Макса Планка. Они создали систему ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными.
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы fandom.com (ранее Wikia). Это платформа, которая позволяет создавать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Поэтому ENTYFI смогла определить, что «Фродо Бэггинс» — «хоббит» из племени «мохноног» (harfoot).
Как работает ENTYFI
Сначала статьи Wikia объединяются в группы, в которых все статьи описывают одну и ту же вселенную — Властелин колец, Гарри Поттер, Марвел и др. Затем программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте и с помощью нейросети LSTM выделяются сущности. Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии.
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена. ET при нахождении сущности подразделяет ее на токены (слова в ней), находит их класс (метку) и добавляет к ним префиксы — элементы разметки текста.
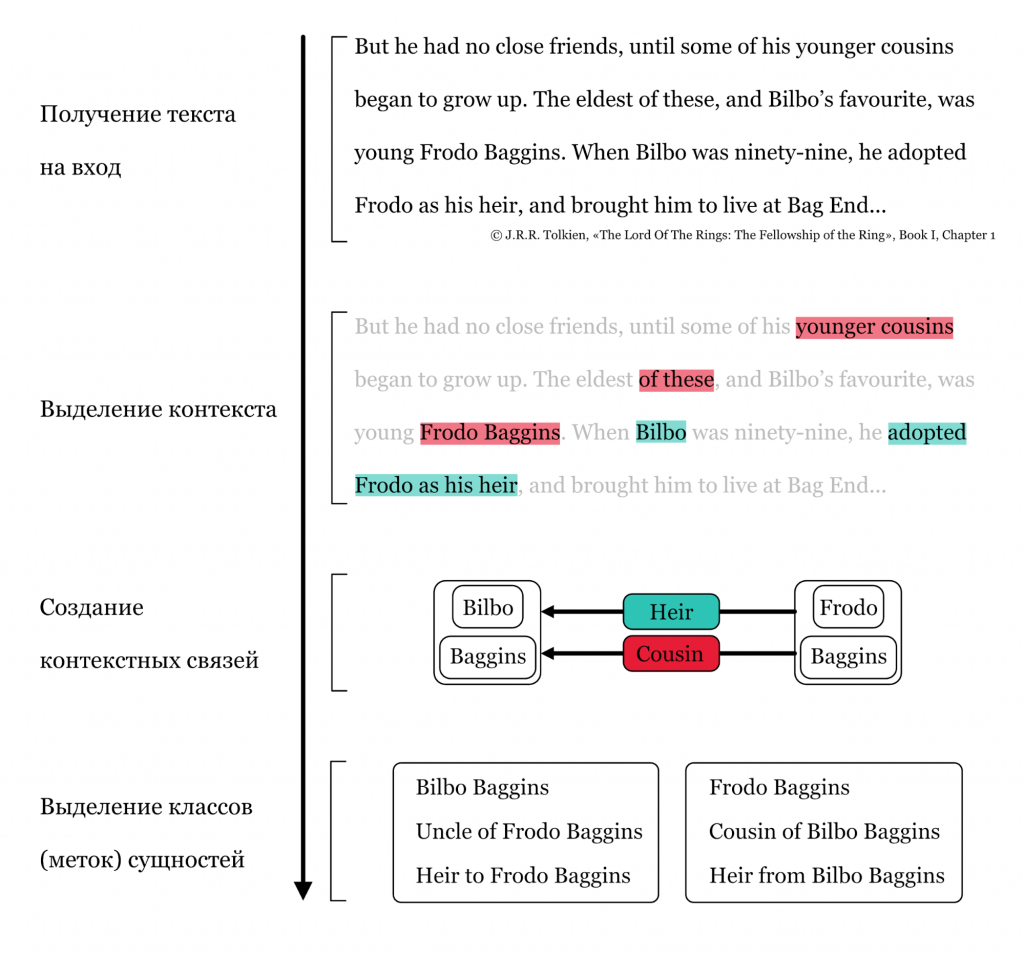
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности. На прикрепленной схеме показано, как программа понимает, что Фродо — «cousin» Бильбо и его наследник.
Информация консолидируется методами Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам.
Сопоставляя факты, ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Авторы ENTYFI выложили исходный код программы на Github.
Также есть демонстратор возможностей библиотеки SpaCy для Python.
https://sysblok.ru/philology/bjegginsy-kolca-i-saurony-kak-nauchit-kompjuter-ponimat-kto-est-kto/
Артур Хисматулин
#nlp #philology
Человек схватывает новую информацию на лету: из контекста, из интонации, из невербального общения. А как помочь компьютеру понять, что Гарри — волшебник, Гендальф — майар, а Джон Сноу — одновременно Старк и Таргариен?
В NLP эти задачи называются Named-entity recognition (NER), то есть выделение сущностей, и Entity Typing (ET) — классификация сущностей. С помощью NER и ET филологи подсчитывают, сколько раз появляется персонаж в тексте, строят сеть связей между героями книг и собирают все прозвища героя, а историки работают с оцифрованными текстами древних рукописей.
Какие корпуса используют для классифицируют сущности
Обычно для выделения особенностей сущности и их классификации используются тексты Википедии. Этот метод работает, если нужно разобрать текст о реальном мире. Но если мы скормим программе текст «Властелина Колец», она выдаст неполный результат, т. к. в Википедии не хватает информации о вымышленных вселенных.
Эту проблему решили исследователи из Института Макса Планка. Они создали систему ENTIFY (ENtity TYping on FIctional texts), которая может работать с художественными текстами, в том числе и фэнтези и science-fiction вселенными.
В основе ENTYFI лежит тот же принцип, что и в базовых инструментах NLP — поиск и классификация сущностей, но к корпусу текстов из Википедии добавляются размеченные тексты с платформы fandom.com (ранее Wikia). Это платформа, которая позволяет создавать отдельные тематические википедии о вселенных из книг, кино, игр и т. д. Поэтому ENTYFI смогла определить, что «Фродо Бэггинс» — «хоббит» из племени «мохноног» (harfoot).
Как работает ENTYFI
Сначала статьи Wikia объединяются в группы, в которых все статьи описывают одну и ту же вселенную — Властелин колец, Гарри Поттер, Марвел и др. Затем программа ранжирует массив «каноничных вселенных» по количеству совпадений в статьях Wikia об одной вселенной и анализируемом тексте и с помощью нейросети LSTM выделяются сущности. Дальше программа ищет найденные в тексте сущности в корпусах Wikia и Википедии.
Одновременно с этими процессами проходят еще два: авторы ENTYFI называют их Unsupervised typing и KB lookup. Unsupervised typing — это поиск класса сущности внутри того предложения, в котором сущность найдена. ET при нахождении сущности подразделяет ее на токены (слова в ней), находит их класс (метку) и добавляет к ним префиксы — элементы разметки текста.
KB lookup — метод, позволяющий вычислить класс (метку) сущности через контекст, который есть в анализируемом тексте. Сначала программа анализирует то, что вокруг сущности (не обязательно близко по тексту), выделяет контекст, формирует связи и из этих связей выделяет классы (метки) сущности. На прикрепленной схеме показано, как программа понимает, что Фродо — «cousin» Бильбо и его наследник.
Информация консолидируется методами Inductive logic programming — Индуктивного логического программирования. Система перепроверяет метки (классы), которые она присвоила персонажам.
Сопоставляя факты, ENTYFI узнает, что Дрого Бэггинс, отец Фродо Бэггинса, ещё и троюродный брат Бильбо Бэггинса по мужской линии; а Примула Брендибак, мать Фродо Бэггинса — двоюродная сестра Бильбо Бэггинса по женской линии. Следовательно, Фродо Бэггинс — дважды племянник Бильбо Бэггинса: двоюродный по матери и троюродный по отцу. Поэтому в «борьбе» меток cousin и nephew победит последняя — потому что Фродо действительно племянник, а не кузен Бильбо.
Авторы ENTYFI выложили исходный код программы на Github.
Также есть демонстратор возможностей библиотеки SpaCy для Python.
https://sysblok.ru/philology/bjegginsy-kolca-i-saurony-kak-nauchit-kompjuter-ponimat-kto-est-kto/
Артур Хисматулин
{kind=link}
Распределение субсидий: кому помогает государство
#opendata
С конца 2019 года российские власти публикуют список топ-20 крупнейших государственных субсидий. Их получатели — РЖД, Сбербанк, Федеральная кадастровая палата, телеканал Russia Today и другие организации и госструктуры. «Системный Блокъ» изучил этот список и визуализировал для вас, кто, откуда и сколько миллиардов получил.
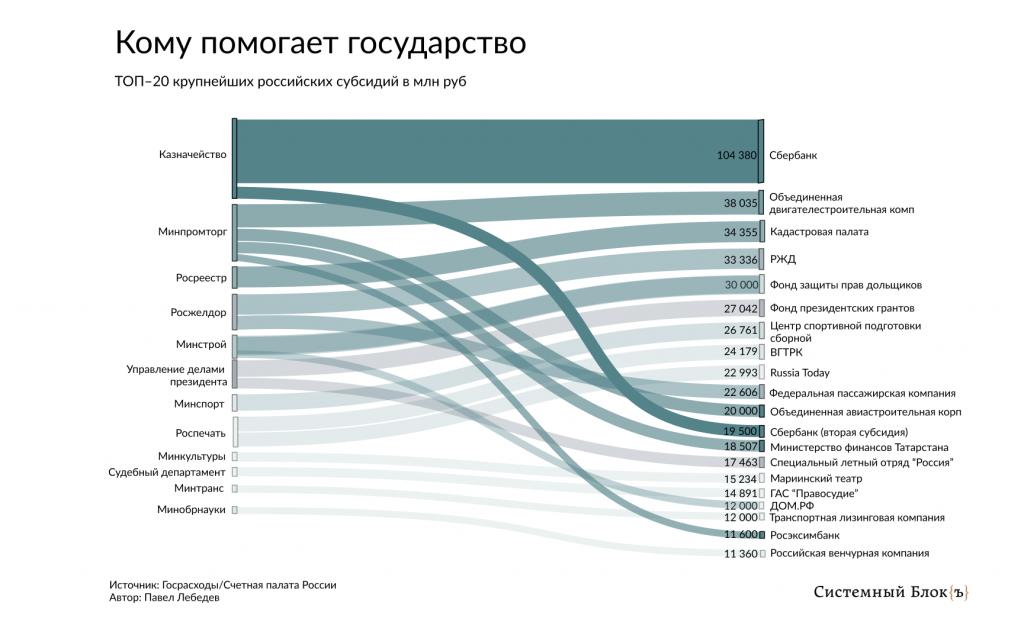
Самая крупная субсидия в 2020 году досталась Сбербанку. Ее размер 104,38 млрд рублей. В постановлении правительства сообщается, что эти деньги призваны помочь средним и малым предприятиям, которые сильнее всего пострадали от коронавируса.
Некоторые субсидии рассчитываются сразу на несколько лет. Так, в течение трех лет фонду Президентских грантов будет выделено более 27 млрд рублей. Назначение субсидии — на проекты, развивающие гражданское общество. А субсидия в 15 млрд рублей будет выдана Государственной автоматизированной системе РФ «Правосудие» на выполнение государственного задания. Субсидия рассчитана на четыре года, в этом году уже выданы более 5 млрд рублей.
Каждый год Управление по делам президента выделяет субсидии Специальному летному отряду «Россия», который занимается обслуживанием самолетов первых лиц государства и глав ведомств. Несмотря на вопросы о неэффективном расходовании бюджетных средств, которые освещала Счетная палата России, расходы на деятельность отряда только увеличиваются и в этом году почти достигли 17,5 млрд рублей. Годом ранее отряду было выделено 14,65 млрд рублей.
В ноябре прошлого года Счетная палата России также запустила портал «Госрасходы». На этом портале доступен рейтинг «20 крупнейших субсидий за 2020 год». Кроме обзора субсидий в проекте агрегируются данные о государственных финансах из разных источников и формулируются профили национальных проектов. Наборы данных можно скачать в машиночитаемых форматах для последующего анализа, а также доступен открытый API.
https://sysblok.ru/otkrytye-dannye/kak-raspredeljajutsja-krupnye-gosudarstvennye-subsidii/
Павел Лебедев
#opendata
С конца 2019 года российские власти публикуют список топ-20 крупнейших государственных субсидий. Их получатели — РЖД, Сбербанк, Федеральная кадастровая палата, телеканал Russia Today и другие организации и госструктуры. «Системный Блокъ» изучил этот список и визуализировал для вас, кто, откуда и сколько миллиардов получил.
Самая крупная субсидия в 2020 году досталась Сбербанку. Ее размер 104,38 млрд рублей. В постановлении правительства сообщается, что эти деньги призваны помочь средним и малым предприятиям, которые сильнее всего пострадали от коронавируса.
Некоторые субсидии рассчитываются сразу на несколько лет. Так, в течение трех лет фонду Президентских грантов будет выделено более 27 млрд рублей. Назначение субсидии — на проекты, развивающие гражданское общество. А субсидия в 15 млрд рублей будет выдана Государственной автоматизированной системе РФ «Правосудие» на выполнение государственного задания. Субсидия рассчитана на четыре года, в этом году уже выданы более 5 млрд рублей.
Каждый год Управление по делам президента выделяет субсидии Специальному летному отряду «Россия», который занимается обслуживанием самолетов первых лиц государства и глав ведомств. Несмотря на вопросы о неэффективном расходовании бюджетных средств, которые освещала Счетная палата России, расходы на деятельность отряда только увеличиваются и в этом году почти достигли 17,5 млрд рублей. Годом ранее отряду было выделено 14,65 млрд рублей.
В ноябре прошлого года Счетная палата России также запустила портал «Госрасходы». На этом портале доступен рейтинг «20 крупнейших субсидий за 2020 год». Кроме обзора субсидий в проекте агрегируются данные о государственных финансах из разных источников и формулируются профили национальных проектов. Наборы данных можно скачать в машиночитаемых форматах для последующего анализа, а также доступен открытый API.
https://sysblok.ru/otkrytye-dannye/kak-raspredeljajutsja-krupnye-gosudarstvennye-subsidii/
Павел Лебедев
{kind=link}
Технологии Big Data в индустрии моды
#arts
В модной индустрии большие данные обычно используются в маркетинговых и аналитических целях. А информационный дизайнер Джорджия Лупи на основе больших данных создает принты для одежды. Она считает, что так она придает сырым данным большую человечность.
«Будучи людьми, мы не способны увидеть в сырых данных на листах Excel паттерны человеческого поведения, — рассказала Лупи Vogue. — Только через дизайн и визуализацию данных можно получить доступ к этим знаниям». Также Лупи выступила на TedTalks, посмотреть выступление.
Совместно с брендом & Other Stories в 2019 году Лупи выпустила коллекцию одежды. Данные для принтов она собрала из биографий трех женщин-ученых — Ады Лавлейс, Рэйчел Карсон и Мэй Джемисон.
Ада Лавлейс
Ада Лавлейс знаменита тем, что в середине XIX века она описала первую в истории компьютерную программу. В примечании к своей научной статье об устройстве механической вычислительной машины она рассказала, как ее можно использовать для вычисления последовательности Фибоначчи. Это и была первая попытка запрограммировать машину для вычисления сложных математических задач.
Фрагменты алгоритма Лавлейс представлены в коллекции Лупи серией ярких разноцветных штрихов. Ниже прикрепляем фотографию готовой одежды с этими принтами.
Рэйчел Карсон
Рэйчел Карсон — биолог, защитница окружающей среды и автор нескольких книг. Для серии принтов о Рэйчел Карсон дизайнер использовала данные из ее книги «Безмолвная весна»: количество слов и символов в книге, типы знаков препинания. Также Лупи собрала информацию о различных видах растений, о которых писала Карсон, и ее исследованиях антропогенного изменения климата.
Мэй Джемисон
Мэй Джемисон — первая темнокожая женщина в космосе. В 1992 году она отправилась на орбиту во время миссии STS-47. Лупи визуализировала дни, проведенные Джемисон в космосе, ее восприятие других людей на станции и проведенные научные эксперименты на орбите.
Посмотреть всю коллекцию
https://sysblok.ru/arts/big-data-modnaja-skazka-o-chelovecheskih-zhiznjah/
Даша Джиоева
#arts
В модной индустрии большие данные обычно используются в маркетинговых и аналитических целях. А информационный дизайнер Джорджия Лупи на основе больших данных создает принты для одежды. Она считает, что так она придает сырым данным большую человечность.
«Будучи людьми, мы не способны увидеть в сырых данных на листах Excel паттерны человеческого поведения, — рассказала Лупи Vogue. — Только через дизайн и визуализацию данных можно получить доступ к этим знаниям». Также Лупи выступила на TedTalks, посмотреть выступление.
Совместно с брендом & Other Stories в 2019 году Лупи выпустила коллекцию одежды. Данные для принтов она собрала из биографий трех женщин-ученых — Ады Лавлейс, Рэйчел Карсон и Мэй Джемисон.
Ада Лавлейс
Ада Лавлейс знаменита тем, что в середине XIX века она описала первую в истории компьютерную программу. В примечании к своей научной статье об устройстве механической вычислительной машины она рассказала, как ее можно использовать для вычисления последовательности Фибоначчи. Это и была первая попытка запрограммировать машину для вычисления сложных математических задач.
Фрагменты алгоритма Лавлейс представлены в коллекции Лупи серией ярких разноцветных штрихов. Ниже прикрепляем фотографию готовой одежды с этими принтами.
Рэйчел Карсон
Рэйчел Карсон — биолог, защитница окружающей среды и автор нескольких книг. Для серии принтов о Рэйчел Карсон дизайнер использовала данные из ее книги «Безмолвная весна»: количество слов и символов в книге, типы знаков препинания. Также Лупи собрала информацию о различных видах растений, о которых писала Карсон, и ее исследованиях антропогенного изменения климата.
Мэй Джемисон
Мэй Джемисон — первая темнокожая женщина в космосе. В 1992 году она отправилась на орбиту во время миссии STS-47. Лупи визуализировала дни, проведенные Джемисон в космосе, ее восприятие других людей на станции и проведенные научные эксперименты на орбите.
Посмотреть всю коллекцию
https://sysblok.ru/arts/big-data-modnaja-skazka-o-chelovecheskih-zhiznjah/
Даша Джиоева
{kind=link}
Цифровая эпиграфика: удаленный доступ к архивам эпиграфических памятников
#digitalheritage
Эпиграфика изучает содержание и формы надписей на твёрдых носителях: камне, керамике, металлических поверхностях. Классические методы эпиграфики — переписывание текста, зарисовка или эстампирование (создание оттиска) — часто приводят к неточностям и ошибкам.
С изобретением цифровой фотографии и 3D-моделирования документирование эпиграфического памятников изменилось. Рассказываем, как это делают сегодня и какие есть проекты в области цифровой эпиграфики.
Корпус древних надписей Северного Причерноморья
Для этого проекта международная группа эпиграфистов и технических специалистов собрала многочисленный древний эпиграфический материал Северопонтийского региона. Исследователи фотографировали эпиграфические памятники и расшифровывали их.
Корпус включает в себя надписи на камне, керамике, металле и кости. Сами надписи сделаны на латинском и греческом языках с третьей четверти 17-го века до н. э. и до падения Константинополя в 1453 г. н. э.
В корпусе собрано около 5000 текстов разной длины. Можно искать нужный текст по дате, происхождению, типу, критериям датировки, именам, материалу и институтам хранения эпиграфических памятников Северопонтийского региона.
«Свод русских надписей»
Для этого проекта исследователи собрали эпиграфические памятники XV–XVII веков и, в меньшей степени, XI–XIV веков. В «Своде» содержатся надписи, выполненные на территории Руси, не только на русском и древнерусском языках, но и латинском, греческом, итальянском и голландском. Всего в «Своде» задокументировано 1332 памятника.
В настоящее время база данных «Свода русских надписей» находится в разработке, а на сайте проекта демонстрируются лишь отдельные примеры. Но в скором времени исследователи смогут просматривать трехмерные модели и растровые изображения эпиграфических памятников, осуществлять сортировку и фильтрацию надписей по нескольким критериям, а также полнотекстовый поиск.
Исследователи «Свода» пришли к выводу, что самым эффективным методом формирования трехмерной модели памятника является фотограмметрическая обработка фотографий, сделанных с помощью цифрового фотоаппарата с полноразмерной матрицей высокого разрешения. Благодаря цифровым трехмерным моделям стало возможным воспроизведение объектов любого размера, корректное воспроизведение цвета, сложных поверхностей.
Ogham in 3D
Цель проекта Ogham in 3D — документирование и описание всех памятников огамического письма на территории Ирландии. Исследовательская группа задокументировала 131 объект из 400 известных, дала их описания, создала интерактивную карту и объединила все надписи в единую базу данных. Памятники сканировали с использованием «структурированного света».
Камни огама — важное культурное наследие Ирландии. На этих перпендикулярных камнях нанесены надписи на уникальном древнем алфавите кельтов. На камнях содержатся имена выдающихся людей, иногда — племенная принадлежность или географический район. Эти надписи представляют собой самую раннюю зарегистрированную форму ирландского языка.
На сайте проекта «Ogham in 3D» все надписи хранятся в одном разделе, сгруппированы по алфавиту, каждая надпись имеет описание, отмечена на интерактивной карте.
https://sysblok.ru/digital-heritage/steret-nelzja-ocifrovat-jepigrafika-otkryvaet-vtoroe-dyhanie/
Этери Джафарова
#digitalheritage
Эпиграфика изучает содержание и формы надписей на твёрдых носителях: камне, керамике, металлических поверхностях. Классические методы эпиграфики — переписывание текста, зарисовка или эстампирование (создание оттиска) — часто приводят к неточностям и ошибкам.
С изобретением цифровой фотографии и 3D-моделирования документирование эпиграфического памятников изменилось. Рассказываем, как это делают сегодня и какие есть проекты в области цифровой эпиграфики.
Корпус древних надписей Северного Причерноморья
Для этого проекта международная группа эпиграфистов и технических специалистов собрала многочисленный древний эпиграфический материал Северопонтийского региона. Исследователи фотографировали эпиграфические памятники и расшифровывали их.
Корпус включает в себя надписи на камне, керамике, металле и кости. Сами надписи сделаны на латинском и греческом языках с третьей четверти 17-го века до н. э. и до падения Константинополя в 1453 г. н. э.
В корпусе собрано около 5000 текстов разной длины. Можно искать нужный текст по дате, происхождению, типу, критериям датировки, именам, материалу и институтам хранения эпиграфических памятников Северопонтийского региона.
«Свод русских надписей»
Для этого проекта исследователи собрали эпиграфические памятники XV–XVII веков и, в меньшей степени, XI–XIV веков. В «Своде» содержатся надписи, выполненные на территории Руси, не только на русском и древнерусском языках, но и латинском, греческом, итальянском и голландском. Всего в «Своде» задокументировано 1332 памятника.
В настоящее время база данных «Свода русских надписей» находится в разработке, а на сайте проекта демонстрируются лишь отдельные примеры. Но в скором времени исследователи смогут просматривать трехмерные модели и растровые изображения эпиграфических памятников, осуществлять сортировку и фильтрацию надписей по нескольким критериям, а также полнотекстовый поиск.
Исследователи «Свода» пришли к выводу, что самым эффективным методом формирования трехмерной модели памятника является фотограмметрическая обработка фотографий, сделанных с помощью цифрового фотоаппарата с полноразмерной матрицей высокого разрешения. Благодаря цифровым трехмерным моделям стало возможным воспроизведение объектов любого размера, корректное воспроизведение цвета, сложных поверхностей.
Ogham in 3D
Цель проекта Ogham in 3D — документирование и описание всех памятников огамического письма на территории Ирландии. Исследовательская группа задокументировала 131 объект из 400 известных, дала их описания, создала интерактивную карту и объединила все надписи в единую базу данных. Памятники сканировали с использованием «структурированного света».
Камни огама — важное культурное наследие Ирландии. На этих перпендикулярных камнях нанесены надписи на уникальном древнем алфавите кельтов. На камнях содержатся имена выдающихся людей, иногда — племенная принадлежность или географический район. Эти надписи представляют собой самую раннюю зарегистрированную форму ирландского языка.
На сайте проекта «Ogham in 3D» все надписи хранятся в одном разделе, сгруппированы по алфавиту, каждая надпись имеет описание, отмечена на интерактивной карте.
https://sysblok.ru/digital-heritage/steret-nelzja-ocifrovat-jepigrafika-otkryvaet-vtoroe-dyhanie/
Этери Джафарова
{kind=link}
Как нейросети генерируют ложные варианты для тестов
#nlp
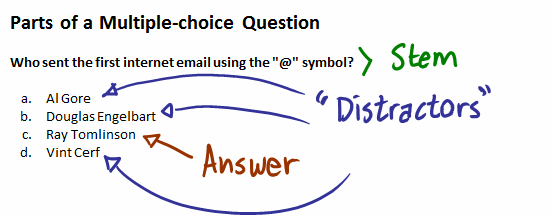
Составлять тесты сложно: кроме правильного ответа надо придумать и неправильные. Причем придумать их с умом: чтобы варианты не были слишком очевидно неверными — но и не оказались бы при этом подходящей альтернативой верному варианту.
В англоязычной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Подбор хороших дистракторов при разработке тестов очень важен. Сейчас ученые пробуют автоматически генерировать дистракторы с помощью нейросетей.
Если у нас есть хорошие примеры дистракторов, сделанных людьми, мы можем включить их в обучающую выборку и решать задачу обучения нейросети с учителем (supervised learning). А если таких примеров нет, мы будем обучать нейросеть без учителя (unsupervised learning).
Когда и как применяют обучение с учителем
Задача порождения дистракторов сводится к подбору списка слов-кандидатов и обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Алгоритм должен присваивать наиболее высокие ранги словам или предложениям, которые являются дистракторами для данного вопроса, то есть помечены как дистракторы в тестовой выборке.
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Когда применяют обучение без учителя
Когда готовый пул вопросов нужного формата отсутствует, применяют unsupervised-подход. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. В таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions. Это вопросы, которые получаются, если заменить какое-либо слова или словосочетание в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.
Как проводят обучение без учителя (на примере корпуса ошибок REALEC)
Для языкового тестирования gap-filling questions можно получить, используя специальный корпус ошибок. Так называют корпуса, которые содержат тексты, написанные не-носителями определенного языка. Эти тексты содержат области, размеченные как ошибки, а также их исправления.
Корпус ошибок REALEC содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе. В системе LangExBank каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Задача — получить ещё 2–3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена принципиальная поправка: если модель предсказывала правильный вариант (т. е. слово-исправление), штраф для неё увеличивался в 2 раза.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Результаты пока далеки от совершенства, поэтому платформа поддерживает редактирование полученных из корпуса тестов.
Устройство нейросети и примеры ее работы — в нашей статье: https://sysblok.ru/linguistics/zaputat-nelzja-ugadat-kak-nejroseti-generirujut-lozhnye-primanki-dlja-testov/
Никита Логин
#nlp
Составлять тесты сложно: кроме правильного ответа надо придумать и неправильные. Причем придумать их с умом: чтобы варианты не были слишком очевидно неверными — но и не оказались бы при этом подходящей альтернативой верному варианту.
В англоязычной литературе для неправильных вариантов ответа в тестах существует специальное название — дистракторы (distractors, букв. «отвлекатели»). Подбор хороших дистракторов при разработке тестов очень важен. Сейчас ученые пробуют автоматически генерировать дистракторы с помощью нейросетей.
Если у нас есть хорошие примеры дистракторов, сделанных людьми, мы можем включить их в обучающую выборку и решать задачу обучения нейросети с учителем (supervised learning). А если таких примеров нет, мы будем обучать нейросеть без учителя (unsupervised learning).
Когда и как применяют обучение с учителем
Задача порождения дистракторов сводится к подбору списка слов-кандидатов и обучению ранжированию. Вопросы нужного формата обычно собираются из оцифрованных копий учебников или интернет-ресурсов.
Алгоритм должен присваивать наиболее высокие ранги словам или предложениям, которые являются дистракторами для данного вопроса, то есть помечены как дистракторы в тестовой выборке.
Получив на вход текст вопроса и текст «кандидата в дистракторы», классификатор должен «решить», насколько хорошо данный ответ может сойти за правильный в контексте данного вопроса, выдав определенную вероятность в виде числа. Подтверждением успешного обучения является получение настоящими дистракторами большего, чем у остальных кандидатов, рейтинга.
Когда применяют обучение без учителя
Когда готовый пул вопросов нужного формата отсутствует, применяют unsupervised-подход. Такая ситуация возникает, когда сами вопросы генерируются из определенного корпуса текстов. В таком случае к ним нет готового обучающего набора отвлекающих неправильных ответов.
Пример такого варианта — gap-filling questions. Это вопросы, которые получаются, если заменить какое-либо слова или словосочетание в корпусном предложении на пропуск. Задача проходящего тест — догадаться, какая единица должна быть на месте пропуска.
Как проводят обучение без учителя (на примере корпуса ошибок REALEC)
Для языкового тестирования gap-filling questions можно получить, используя специальный корпус ошибок. Так называют корпуса, которые содержат тексты, написанные не-носителями определенного языка. Эти тексты содержат области, размеченные как ошибки, а также их исправления.
Корпус ошибок REALEC содержит тексты на английском языке, написанные русскоязычными студентами в качестве письменных заданий-эссе. В системе LangExBank каждый тестовый вопрос — предложение корпуса REALEC, в котором область ошибки заменена на пропуск. Таким образом, правильный ответ и один неправильный ответ в исходных данных уже есть — это исправление и оригинальная область ошибки. Задача — получить ещё 2–3 неправильных варианта.
В LangExBank реализована генерация дистракторов из вопросов, полученных на основе лексических ошибок и ошибок на употребление предлогов. Для подбора дистракторов используется классификатор в виде рекуррентной нейронной сети. Нейросеть должна заполнить пропуск, но в обучение модели внесена принципиальная поправка: если модель предсказывала правильный вариант (т. е. слово-исправление), штраф для неё увеличивался в 2 раза.
Так как в датасете изначально не содержатся дистракторы, качество сгенерированных вариантов можно проверить только вручную. Результаты пока далеки от совершенства, поэтому платформа поддерживает редактирование полученных из корпуса тестов.
Устройство нейросети и примеры ее работы — в нашей статье: https://sysblok.ru/linguistics/zaputat-nelzja-ugadat-kak-nejroseti-generirujut-lozhnye-primanki-dlja-testov/
Никита Логин
{kind=link}
Покажи мне свой Spotify, и я покажу тебе, кто ты
#musicology #opendata
«Spotify опоздал» — говорят одни. «Spotify — всего лишь один из многих!», — говорят другие. «Spotify неудобен» — говорят третьи. А мы говорим: «У Spotify есть открытый API — и мы идем исследовать себя!»
Мы уже писали о том, как Spotify угадывает наши предпочтения в музыке. В этой статье мы попытаемся сами проанализировать наши музыкальные предпочтения с помощью WEB API от Spotify и понять, что о нашем вкусе говорит наш плейлист.
На своих серверах Spotify хранит информацию о каждом треке. Есть данные о размерности трека, его энергичности, темпе и прочие музыкальные характеристики. С ними мы и будем работать.
Какие задачи мы будем решать
• зарегистрируемся на Spotify как разработчики,
• создадим свое приложение,
• подключим наше приложение к Spotify API,
• получим информацию о своем плейлисте,
• сформируем из данных таблицу и скачаем ее на компьютер,
• визуализируем данные в IDE — в среде разработки, в которой мы будем писать код.
Подробное решение всех задач — в нашей статье: https://sysblok.ru/musicology/pokazhi-mne-svoj-spotify-i-ja-pokazhu-tebe-kto-ty/
Артур Хисматулин
#musicology #opendata
«Spotify опоздал» — говорят одни. «Spotify — всего лишь один из многих!», — говорят другие. «Spotify неудобен» — говорят третьи. А мы говорим: «У Spotify есть открытый API — и мы идем исследовать себя!»
Мы уже писали о том, как Spotify угадывает наши предпочтения в музыке. В этой статье мы попытаемся сами проанализировать наши музыкальные предпочтения с помощью WEB API от Spotify и понять, что о нашем вкусе говорит наш плейлист.
На своих серверах Spotify хранит информацию о каждом треке. Есть данные о размерности трека, его энергичности, темпе и прочие музыкальные характеристики. С ними мы и будем работать.
Какие задачи мы будем решать
• зарегистрируемся на Spotify как разработчики,
• создадим свое приложение,
• подключим наше приложение к Spotify API,
• получим информацию о своем плейлисте,
• сформируем из данных таблицу и скачаем ее на компьютер,
• визуализируем данные в IDE — в среде разработки, в которой мы будем писать код.
Подробное решение всех задач — в нашей статье: https://sysblok.ru/musicology/pokazhi-mne-svoj-spotify-i-ja-pokazhu-tebe-kto-ty/
Артур Хисматулин
{kind=link}
Тиндер 1917 года и революция в цифре
#digitalmemory #history
Историческое знание нуждается в новых формах представления, особенно онлайн. Публичная история (public history) связывает современного человека и историю в медиапространстве, образуя активный социальный диалог. Public history предлагает digital-проекты для изучения истории в игровой форме. Самый популярный из них — цифровая реинкарнация 1917 года от команд Михаила Зыгаря и Сергея Лунёва.
Михаил Зыгарь — бывший главный редактор телеканала «Дождь», автор бестселлера «Вся кремлевская рать» и основатель креативной студии «История будущего». Три года назад, к столетию октябрьской революции, он запустил мультимедийный проект «1917. Свободная история», в котором репрезентировалась история современников 1917 года в виде странички в Facebook: адаптированные посты, трансляции и фото.
Проект «1917. Свободная история»
В проекте больше 1500 героев. У поэтессы Зинаиды Гиппиус стоит статус «Главное — не ныть. Не размазывать своих „страданий“. Подумаешь! У всякого своя боль. Вот у меня кашель, например», это ее цитата. В разделе «место работы» у архитектора Эля Лисицкого написано, что он занимает должность секретаря оргкомитета и готовит к открытию Выставку художников-евреев в Москве.
Команда провела трансляцию с первого заседания Государственной Думы, прославившуюся выступлением оппозиционера Павла Милюкова, открытие долгожданной выставки общества «Бубновый валет», осветила тайную свадьбу сестры императора Ольги. А еще на сайте можно отправить письмо чат-боту с Распутиным, зайти в Тиндер1917, узнать интимные прозвища звезд времен революции и многое другое.
Проект «1917. День за днем»
Второй проект про «сложное» прошлое — «1917. День за днем» Сергея Лунёва, историка и создателя познавательного журнала о русскоязычной цивилизации «VATNIKSTAN», — менее динамичный. Он разделен на две части — столетние архивы и статьи студентов МГУ. В «Источниках» можно найти вырезки из газеты «Вперед», «Русские Ведомости», тексты декретов, воспоминания. В «Статьях» хранятся публикации с тематикой интервью, историографии, литературоведения, политической и социальной истории и т. д.
Ученые негодуют: почему историки выступили против проекта Зыгаря
Однако многие приверженцы академической истории скептично относятся к проекту «1917. Свободная история», критикуя его за необоснованные сокращения, которые превращают факты в домыслы. По их мнению, так теряются важные причинно-следственные связи: читателя вводят в заблуждение, выдавая художественное за историческое. Например, фразы типа «Я точно зверь травленный: все загрызть хотят… Поперек горла им стою» в игре «Поговори с Распутиным» могли им и не произноситься.
Сами авторы называют «Свободную историю» инновационным сторителлингом и утверждают, что, пытаясь сделать историю общедоступной и понятной, они не подменяли исторические факты. Содержание публикаций основывается на письмах и личных дневниках.
Запустив «1917. Свободную историю» и «1917. День за днем» Зыгарь и Лунёв не воссоздали точную историческую копию России 1917 года, да и не имели такой цели. Создатели проектов посмотрели на события революции сквозь призму особого личного понимания, построенного на достоверных фактах. Теперь историки могут изучать не только минувшие события, но и их современные репрезентации, которые накладываются друг на друга, образуя новые образы прошлого в культуре.
https://sysblok.ru/digitalmemory/tinder-1917-goda-i-revoljucija-v-cifre/
Яна Олейник
#digitalmemory #history
Историческое знание нуждается в новых формах представления, особенно онлайн. Публичная история (public history) связывает современного человека и историю в медиапространстве, образуя активный социальный диалог. Public history предлагает digital-проекты для изучения истории в игровой форме. Самый популярный из них — цифровая реинкарнация 1917 года от команд Михаила Зыгаря и Сергея Лунёва.
Михаил Зыгарь — бывший главный редактор телеканала «Дождь», автор бестселлера «Вся кремлевская рать» и основатель креативной студии «История будущего». Три года назад, к столетию октябрьской революции, он запустил мультимедийный проект «1917. Свободная история», в котором репрезентировалась история современников 1917 года в виде странички в Facebook: адаптированные посты, трансляции и фото.
Проект «1917. Свободная история»
В проекте больше 1500 героев. У поэтессы Зинаиды Гиппиус стоит статус «Главное — не ныть. Не размазывать своих „страданий“. Подумаешь! У всякого своя боль. Вот у меня кашель, например», это ее цитата. В разделе «место работы» у архитектора Эля Лисицкого написано, что он занимает должность секретаря оргкомитета и готовит к открытию Выставку художников-евреев в Москве.
Команда провела трансляцию с первого заседания Государственной Думы, прославившуюся выступлением оппозиционера Павла Милюкова, открытие долгожданной выставки общества «Бубновый валет», осветила тайную свадьбу сестры императора Ольги. А еще на сайте можно отправить письмо чат-боту с Распутиным, зайти в Тиндер1917, узнать интимные прозвища звезд времен революции и многое другое.
Проект «1917. День за днем»
Второй проект про «сложное» прошлое — «1917. День за днем» Сергея Лунёва, историка и создателя познавательного журнала о русскоязычной цивилизации «VATNIKSTAN», — менее динамичный. Он разделен на две части — столетние архивы и статьи студентов МГУ. В «Источниках» можно найти вырезки из газеты «Вперед», «Русские Ведомости», тексты декретов, воспоминания. В «Статьях» хранятся публикации с тематикой интервью, историографии, литературоведения, политической и социальной истории и т. д.
Ученые негодуют: почему историки выступили против проекта Зыгаря
Однако многие приверженцы академической истории скептично относятся к проекту «1917. Свободная история», критикуя его за необоснованные сокращения, которые превращают факты в домыслы. По их мнению, так теряются важные причинно-следственные связи: читателя вводят в заблуждение, выдавая художественное за историческое. Например, фразы типа «Я точно зверь травленный: все загрызть хотят… Поперек горла им стою» в игре «Поговори с Распутиным» могли им и не произноситься.
Сами авторы называют «Свободную историю» инновационным сторителлингом и утверждают, что, пытаясь сделать историю общедоступной и понятной, они не подменяли исторические факты. Содержание публикаций основывается на письмах и личных дневниках.
Запустив «1917. Свободную историю» и «1917. День за днем» Зыгарь и Лунёв не воссоздали точную историческую копию России 1917 года, да и не имели такой цели. Создатели проектов посмотрели на события революции сквозь призму особого личного понимания, построенного на достоверных фактах. Теперь историки могут изучать не только минувшие события, но и их современные репрезентации, которые накладываются друг на друга, образуя новые образы прошлого в культуре.
https://sysblok.ru/digitalmemory/tinder-1917-goda-i-revoljucija-v-cifre/
Яна Олейник
{kind=link}
Тест Тьюринга для переводчиков: вычисли машину
#test
В этом тесте мы предлагаем вам попробовать отличить человеческий перевод — от сделанного компьютером. И заодно покажем, что у всех переводчиков, даже машинных, есть свой стиль. А в качестве примеров возьмем фразы из известных фильмов.
Тяжело выбрать, каким переводчиком лучше воспользоваться — ведь «жизнь как коробка шоколадных конфет: никогда не знаешь, какая начинка тебе попадётся». Узнали цитату? Интересно, как бы она звучала, если бы переводчики Форреста Гампа воспользовались Google. Translate или Яндекс. А главное, смогли бы вы понять, что при переводе использовали машину?
Мы подобрали для вас еще несколько цитат — и предлагаем угадать, какой из переводов сделан человеком.
https://sysblok.ru/test/test-tjuringa-dlja-perevodchikov-vychisli-mashinu/
#test
В этом тесте мы предлагаем вам попробовать отличить человеческий перевод — от сделанного компьютером. И заодно покажем, что у всех переводчиков, даже машинных, есть свой стиль. А в качестве примеров возьмем фразы из известных фильмов.
Тяжело выбрать, каким переводчиком лучше воспользоваться — ведь «жизнь как коробка шоколадных конфет: никогда не знаешь, какая начинка тебе попадётся». Узнали цитату? Интересно, как бы она звучала, если бы переводчики Форреста Гампа воспользовались Google. Translate или Яндекс. А главное, смогли бы вы понять, что при переводе использовали машину?
Мы подобрали для вас еще несколько цитат — и предлагаем угадать, какой из переводов сделан человеком.
https://sysblok.ru/test/test-tjuringa-dlja-perevodchikov-vychisli-mashinu/
{kind=link}
Цифровой гербарий МГУ: новая жизнь исторической коллекции растений
#biology #opendata
Переход «в цифру» — уже давно не новость для различных коллекций. Множество музеев мира готовы принять посетителей в своих виртуальных стенах, библиотеки предоставляют открытый доступ к нужным книгам через интернет.
Не стали исключением и гербарии — научные коллекции засушенных растений по всему миру. И не зря. Ведь оцифровка коллекций — это не только «получение картинок», но и обработка и получение огромных массивов ботанической информации, большой шаг в эпоху больших данных для коллекций растений. Сегодня ботаника развивается в том числе и за счет обобщений крупных массивов информации, приемов математического моделирования и матстатистики.
Для второго по величине гербария нашей страны — коллекции МГУ имени М. В. Ломоносова — переход на новый уровень начался еще в 2015 году. И к 2020 году мы имеем большой структурированный портал, который помогает ботаникам из любой точки мира.
Что получили ученые после оцифровки
1. Доступность более чем 1 млн. изображений растений из любой точки мира.
2. Базу метаданных, которая также открыта для запросов ученых и представляет собой классический образец больших данных. И если отсканированные картинки — это наиболее видимый результат, то база данных цифрового гербария — это очень важная и ценная часть проекта именно с точки зрения возможностей анализа информации.
3. У каждого образца появился уникальный идентификатор — стало гораздо проще ссылаться на нужные образцы в своих статьях
4. Привязки к карте для более чем 50% образцов. Это очень ценная информация. Вопрос «где растет этот вид» — один из базовых в ботанике и по сей день не теряет актуальности, ведь в изменяющихся под влиянием человека условиях еще важнее знать «где что растет», чтобы потом можно было спрогнозировать «а будет ли расти там и там при таких и таких условиях». И здесь в игру вступает информация с этикеток гербария и ее «привязка» к карте.
Вплоть до 1990-х годов для составления гербариев GPS системы практически не использовались, и места сбора растений отмечали как «5 км к ЮВ от деревни X». Чтобы найти по словесным описаниям точку на современной карте требуется много времени и сил. Один человек за рабочий день может «привязать» от 50 до 300 точек.
В базе гербария МГУ таких точек уже 578063. Для их определения, помимо ручного труда, людям помогал специально настроенный алгоритм. Система группировала образцы, собранные в один день одним и тем же человеком и экстраполировала на эту группу геопривязку, если она имелась хотя бы для одного образца из группы.
Конечно, такая привязка не столь точна, как «ручная», но она тем не менее позволила уточнить расположение мест сбора многих тысяч растений. Такие автоматические привязки помечены в системе отдельным значком.
5. Названия растений на портале синхронизированы с международной базой данных названий «Catalogue of Life». Можно сразу посмотреть не только актуальное название растения, но и его положение в системе растительного мира и возможные синонимы.
6. Распознаны тексты этикеток (в том числе рукописных) для почти половины образцов
7. Гибкая система поиска позволяет найти нужное растение за пару минут, используя самые разные параметры: от названия растения до даты сбора образца.
Конечно же гербарий МГУ существует и в оффлайн формате. Образцы XVIII–XXI веков хранятся в специальных шкафах и ждут заинтересованных специалистов.
Однако перевод в цифровую форму не только открыл гербарий для пользователей со всего мира, но и сделал возможным детальный анализ данных по разнообразию и географии растений. Ну, а в периоды дистанционной работы гербария из-за пандемии его онлайн-портал — это единственная возможность ознакомиться с образцами и получить данные для своей курсовой, диссертации, научной статьи.
https://sysblok.ru/biologija/cifrovoj-gerbarij-mgu-novaja-zhizn-istoricheskoj-kollekcii-rastenij/
Ксения Дудова
#biology #opendata
Переход «в цифру» — уже давно не новость для различных коллекций. Множество музеев мира готовы принять посетителей в своих виртуальных стенах, библиотеки предоставляют открытый доступ к нужным книгам через интернет.
Не стали исключением и гербарии — научные коллекции засушенных растений по всему миру. И не зря. Ведь оцифровка коллекций — это не только «получение картинок», но и обработка и получение огромных массивов ботанической информации, большой шаг в эпоху больших данных для коллекций растений. Сегодня ботаника развивается в том числе и за счет обобщений крупных массивов информации, приемов математического моделирования и матстатистики.
Для второго по величине гербария нашей страны — коллекции МГУ имени М. В. Ломоносова — переход на новый уровень начался еще в 2015 году. И к 2020 году мы имеем большой структурированный портал, который помогает ботаникам из любой точки мира.
Что получили ученые после оцифровки
1. Доступность более чем 1 млн. изображений растений из любой точки мира.
2. Базу метаданных, которая также открыта для запросов ученых и представляет собой классический образец больших данных. И если отсканированные картинки — это наиболее видимый результат, то база данных цифрового гербария — это очень важная и ценная часть проекта именно с точки зрения возможностей анализа информации.
3. У каждого образца появился уникальный идентификатор — стало гораздо проще ссылаться на нужные образцы в своих статьях
4. Привязки к карте для более чем 50% образцов. Это очень ценная информация. Вопрос «где растет этот вид» — один из базовых в ботанике и по сей день не теряет актуальности, ведь в изменяющихся под влиянием человека условиях еще важнее знать «где что растет», чтобы потом можно было спрогнозировать «а будет ли расти там и там при таких и таких условиях». И здесь в игру вступает информация с этикеток гербария и ее «привязка» к карте.
Вплоть до 1990-х годов для составления гербариев GPS системы практически не использовались, и места сбора растений отмечали как «5 км к ЮВ от деревни X». Чтобы найти по словесным описаниям точку на современной карте требуется много времени и сил. Один человек за рабочий день может «привязать» от 50 до 300 точек.
В базе гербария МГУ таких точек уже 578063. Для их определения, помимо ручного труда, людям помогал специально настроенный алгоритм. Система группировала образцы, собранные в один день одним и тем же человеком и экстраполировала на эту группу геопривязку, если она имелась хотя бы для одного образца из группы.
Конечно, такая привязка не столь точна, как «ручная», но она тем не менее позволила уточнить расположение мест сбора многих тысяч растений. Такие автоматические привязки помечены в системе отдельным значком.
5. Названия растений на портале синхронизированы с международной базой данных названий «Catalogue of Life». Можно сразу посмотреть не только актуальное название растения, но и его положение в системе растительного мира и возможные синонимы.
6. Распознаны тексты этикеток (в том числе рукописных) для почти половины образцов
7. Гибкая система поиска позволяет найти нужное растение за пару минут, используя самые разные параметры: от названия растения до даты сбора образца.
Конечно же гербарий МГУ существует и в оффлайн формате. Образцы XVIII–XXI веков хранятся в специальных шкафах и ждут заинтересованных специалистов.
Однако перевод в цифровую форму не только открыл гербарий для пользователей со всего мира, но и сделал возможным детальный анализ данных по разнообразию и географии растений. Ну, а в периоды дистанционной работы гербария из-за пандемии его онлайн-портал — это единственная возможность ознакомиться с образцами и получить данные для своей курсовой, диссертации, научной статьи.
https://sysblok.ru/biologija/cifrovoj-gerbarij-mgu-novaja-zhizn-istoricheskoj-kollekcii-rastenij/
Ксения Дудова
{kind=link}
Осторожно: ретросимулякр! Советское прошлое в медиапроектах про 1968 год и Перестройку
#digitalmemory
Воспоминания о советском прошлом захватывают часть сознания людей, переживших личный опыт пребывания в СССР, и тех, кто хранит чужие ностальгические воспоминания по утраченному прошлому. Но как именно работают механизмы ностальгии? Разбираемся на примере screenlife-сериала «1968: Digital» и интерактивной игры «Карта истории».
Как работают механизмы ностальгии
Ностальгия занимает отдельное место в механизме памяти о советском пространстве. Она предстает в роли эмоционального анестетика, смягчающего фантомные боли по безвозвратно ушедшим временам. Источником теплой грусти может являться как абстрактный дом, воплощающийся в образе Советского Союза, так и собирательный образ молодости, который все равно вклинивается в пространство СССР, а значит невольно затрагивает ностальгические чувства и о нем, пусть даже на самую малость.
В самом обобщенном виде прошлое под воздействием фильтра ностальгической обработки создает комбинацию воображения, грез и эмоций, которые вместе конструируют фикцию — то, чего на самом деле могло никогда и не быть. Ведь человеческий мозг устроен таким образом, что память уводит в расфокус реальные события, романтизируя их даже несмотря на все экономические, социальные и идеологические сложности, которые, в том числе, резко ограничивали свободу советского человека.
Ностальгическую картинку советского пространства можно сравнить с фотокарточкой, прошедшей обработку в Instagram — ретросимулякре, который с помощью набора специальных фильтров придает кадрам повседневной жизни романтизированный образ состаренного фото в стиле Polaroid.
Screenlife-формат: революция сознания
Технологический прием виртуализации удачно использовали журналист Михаил Зыгарь и режиссер Тимур Бекмамбетов в первом документальном сериале для смартфонов «1968: Digital» — о периоде, насыщенном яркими событиями и в СССР, и в мире: космическая гонка Гагарина и Армстронга, Пражская весна, The Beatles и многое другое. Авторы освещают историю с позиции СССР и зарубежья одновременно, что помогает избежать логических ям в осмыслении истории XX века.
Особенность проекта в том, что он выполнен в формате screenlife. Каждая серия ведется от лица реальных героев 1968 года через их смартфоны, которые могли бы у них быть. «Ив Сен-Лоран постит твиты, у группы The Beatles есть чат в WhatsApp, Энди Уорхол выкладывает фотографии со своих выставок в инстаграм…», — рассказывают креаторы на сайте проекта. За два года существования проекта отснято уже 35 эпизодов.
Ментальная карта истории
«Карта истории» — интерактивная игра про главные события в России ХХ века с элементами сторителлинга. Авторы идеи — Михаил Зыгарь и Карен Шаинян — взяли судьбы исторических персонажей и разбили на 10–20 ходов со сложным моральным выбором. Как поступить Высоцкому в ответ на просьбу не петь провокационные песни, зачем Роберт Робинсон меняет США на СССР в поисках лучшей жизни, как Эйзенштейну снять свой главный фильм и сохранить свободу и т. д.
Всего в «Карте истории» 7 сезонов — каждое десятилетие СССР. В начале каждой «эпохи» показан мультфильм, вводящий в дискурс времени. В освещении исторических событий фокус смещен с лидеров государства на общество и культурные явления, то есть на индивидуальные эмоциональные переживания.
Подробности — в нашей статье: https://sysblok.ru/digitalmemory/ostorozhno-retrosimuljakr-sovetskoe-proshloe-v-mediaproektah-pro-1968-god-i-perestrojku/
Яна Олейник
#digitalmemory
Воспоминания о советском прошлом захватывают часть сознания людей, переживших личный опыт пребывания в СССР, и тех, кто хранит чужие ностальгические воспоминания по утраченному прошлому. Но как именно работают механизмы ностальгии? Разбираемся на примере screenlife-сериала «1968: Digital» и интерактивной игры «Карта истории».
Как работают механизмы ностальгии
Ностальгия занимает отдельное место в механизме памяти о советском пространстве. Она предстает в роли эмоционального анестетика, смягчающего фантомные боли по безвозвратно ушедшим временам. Источником теплой грусти может являться как абстрактный дом, воплощающийся в образе Советского Союза, так и собирательный образ молодости, который все равно вклинивается в пространство СССР, а значит невольно затрагивает ностальгические чувства и о нем, пусть даже на самую малость.
В самом обобщенном виде прошлое под воздействием фильтра ностальгической обработки создает комбинацию воображения, грез и эмоций, которые вместе конструируют фикцию — то, чего на самом деле могло никогда и не быть. Ведь человеческий мозг устроен таким образом, что память уводит в расфокус реальные события, романтизируя их даже несмотря на все экономические, социальные и идеологические сложности, которые, в том числе, резко ограничивали свободу советского человека.
Ностальгическую картинку советского пространства можно сравнить с фотокарточкой, прошедшей обработку в Instagram — ретросимулякре, который с помощью набора специальных фильтров придает кадрам повседневной жизни романтизированный образ состаренного фото в стиле Polaroid.
Screenlife-формат: революция сознания
Технологический прием виртуализации удачно использовали журналист Михаил Зыгарь и режиссер Тимур Бекмамбетов в первом документальном сериале для смартфонов «1968: Digital» — о периоде, насыщенном яркими событиями и в СССР, и в мире: космическая гонка Гагарина и Армстронга, Пражская весна, The Beatles и многое другое. Авторы освещают историю с позиции СССР и зарубежья одновременно, что помогает избежать логических ям в осмыслении истории XX века.
Особенность проекта в том, что он выполнен в формате screenlife. Каждая серия ведется от лица реальных героев 1968 года через их смартфоны, которые могли бы у них быть. «Ив Сен-Лоран постит твиты, у группы The Beatles есть чат в WhatsApp, Энди Уорхол выкладывает фотографии со своих выставок в инстаграм…», — рассказывают креаторы на сайте проекта. За два года существования проекта отснято уже 35 эпизодов.
Ментальная карта истории
«Карта истории» — интерактивная игра про главные события в России ХХ века с элементами сторителлинга. Авторы идеи — Михаил Зыгарь и Карен Шаинян — взяли судьбы исторических персонажей и разбили на 10–20 ходов со сложным моральным выбором. Как поступить Высоцкому в ответ на просьбу не петь провокационные песни, зачем Роберт Робинсон меняет США на СССР в поисках лучшей жизни, как Эйзенштейну снять свой главный фильм и сохранить свободу и т. д.
Всего в «Карте истории» 7 сезонов — каждое десятилетие СССР. В начале каждой «эпохи» показан мультфильм, вводящий в дискурс времени. В освещении исторических событий фокус смещен с лидеров государства на общество и культурные явления, то есть на индивидуальные эмоциональные переживания.
Подробности — в нашей статье: https://sysblok.ru/digitalmemory/ostorozhno-retrosimuljakr-sovetskoe-proshloe-v-mediaproektah-pro-1968-god-i-perestrojku/
Яна Олейник
{kind=link}
Почему нейросеть так легко обмануть
#knowhow
С каждым годом искусственный интеллект все больше входит в нашу жизнь: ему уже доверили не только мелочи вроде подбора контекстной рекламы, но и более серьезные задачи — управление беспилотными автомобилями и даже диагностику пациентов. Случаи, когда ошибка ИИ привела бы к серьезным последствиям для человека — редкость, но риск такой ошибки велик.
Исследования показали, что минимальные изменения в любых типах входных данных способны запутать ИИ. Достаточно с расчетом наклеить стикеры на дорожный знак, нанести определенный узор на шляпу или очки или добавить белый шум в аудиозапись, чтобы система распознавания совершила ошибку там, где человек без раздумий ответил бы верно.
Как учится нейронная сеть
В основе любой современной технологии, нуждающейся в распознавании образов, лежит глубокая нейронная сеть. Это искусственная сеть, состоящая из множества цифровых нейронов, упорядоченных в слои так, чтобы приблизительно повторять архитектуру человеческого мозга.
Нейросеть обучается на больших дата-сетах — например, множестве изображений котов и собак. Самостоятельно или с учителем нейросеть выявляет из картинок паттерны, которые помогают ей определить, кто на фотографии. Затем использует эти паттерны, чтобы делать прогнозы относительно новых примеров.
Как обмануть нейронную сеть
В 2013 году исследователи Google показали, что достаточно изменить в картинке всего несколько пикселей, и правильно определенное в первый раз изображение после небольшой оптимизации покажется классификатору незнакомым. Поддельные изображения назвали адверсальными примерами.
Годом позже ученые обратили внимание на то, что нейронная сеть видит предметы даже там, где их нет. Можно создать изображения, которые будут неузнаваемы для людей, но с 99,9% вероятностью знакомыми для ИИ. Например, королевский пингвин в узоре из волнистых линий.
В 2018 году стало известно, что объект достаточно повернуть, чтобы ввести в заблуждение самые сильные классификаторы изображений. Скорее всего, это происходит, потому что предметы под другим ракурсом сильно отличаются от примеров, на которых сеть обучалась.
В 2019 обнаружили, что даже неподдельные, сырые изображения могут заставить самые сильные нейронные сети делать непредсказуемые оплошности. Например, ИИ может определить гриб как крендель или стрекозу как крышку люка, потому что нейросеть фокусируется на цвете изображения, текстуре или заднем плане.
Как сделать нейросеть сильнее
Ученые предлагают дать ИИ больше информации об объекте, скармливая ему адверсальные примеры и исправляя его ошибки. Для нейросетей устраивают «адверсальные тренировки», в которых одна сеть учится определять объекты, а другая изменяет их, чтобы запутать ее. Но обучая нейросеть противостоять одному виду атак, можно ослабить ее к другим.
Поскольку большинство адверсальных атак работает, внося крошечные изменения в составные части входных данных — например, незаметно изменяя цвет пикселей в изображении до тех пор, пока это не приведет к ошибочной классификации, — исследователи также предложили включить формулу ошибки в нейросеть. Так она сможет просчитывать изменения самостоятельно и не менять свое решение.
Также есть предложение объединить глубокую нейронную сеть с символическим искусственным интеллектом, который был основным до появления машинного обучения. С помощью символического ИИ машины рассуждали, используя жестко запрограммированные представления о мире: что он состоит из дискретных объектов, которые находятся друг с другом в различных отношениях.
Но ИИ хорош ровно настолько насколько хороши примеры, на которых его обучали. Чтобы приблизить его к идеалу, нужно позволить ему учиться в более богатой среде, которую он сможет самостоятельно исследовать. Также может помочь обучение в трехмерной среде — реальной или смоделированной.
https://sysblok.ru/neuroscience/pochemu-nejroset-tak-legko-obmanut/
Алена Завьялова
#knowhow
С каждым годом искусственный интеллект все больше входит в нашу жизнь: ему уже доверили не только мелочи вроде подбора контекстной рекламы, но и более серьезные задачи — управление беспилотными автомобилями и даже диагностику пациентов. Случаи, когда ошибка ИИ привела бы к серьезным последствиям для человека — редкость, но риск такой ошибки велик.
Исследования показали, что минимальные изменения в любых типах входных данных способны запутать ИИ. Достаточно с расчетом наклеить стикеры на дорожный знак, нанести определенный узор на шляпу или очки или добавить белый шум в аудиозапись, чтобы система распознавания совершила ошибку там, где человек без раздумий ответил бы верно.
Как учится нейронная сеть
В основе любой современной технологии, нуждающейся в распознавании образов, лежит глубокая нейронная сеть. Это искусственная сеть, состоящая из множества цифровых нейронов, упорядоченных в слои так, чтобы приблизительно повторять архитектуру человеческого мозга.
Нейросеть обучается на больших дата-сетах — например, множестве изображений котов и собак. Самостоятельно или с учителем нейросеть выявляет из картинок паттерны, которые помогают ей определить, кто на фотографии. Затем использует эти паттерны, чтобы делать прогнозы относительно новых примеров.
Как обмануть нейронную сеть
В 2013 году исследователи Google показали, что достаточно изменить в картинке всего несколько пикселей, и правильно определенное в первый раз изображение после небольшой оптимизации покажется классификатору незнакомым. Поддельные изображения назвали адверсальными примерами.
Годом позже ученые обратили внимание на то, что нейронная сеть видит предметы даже там, где их нет. Можно создать изображения, которые будут неузнаваемы для людей, но с 99,9% вероятностью знакомыми для ИИ. Например, королевский пингвин в узоре из волнистых линий.
В 2018 году стало известно, что объект достаточно повернуть, чтобы ввести в заблуждение самые сильные классификаторы изображений. Скорее всего, это происходит, потому что предметы под другим ракурсом сильно отличаются от примеров, на которых сеть обучалась.
В 2019 обнаружили, что даже неподдельные, сырые изображения могут заставить самые сильные нейронные сети делать непредсказуемые оплошности. Например, ИИ может определить гриб как крендель или стрекозу как крышку люка, потому что нейросеть фокусируется на цвете изображения, текстуре или заднем плане.
Как сделать нейросеть сильнее
Ученые предлагают дать ИИ больше информации об объекте, скармливая ему адверсальные примеры и исправляя его ошибки. Для нейросетей устраивают «адверсальные тренировки», в которых одна сеть учится определять объекты, а другая изменяет их, чтобы запутать ее. Но обучая нейросеть противостоять одному виду атак, можно ослабить ее к другим.
Поскольку большинство адверсальных атак работает, внося крошечные изменения в составные части входных данных — например, незаметно изменяя цвет пикселей в изображении до тех пор, пока это не приведет к ошибочной классификации, — исследователи также предложили включить формулу ошибки в нейросеть. Так она сможет просчитывать изменения самостоятельно и не менять свое решение.
Также есть предложение объединить глубокую нейронную сеть с символическим искусственным интеллектом, который был основным до появления машинного обучения. С помощью символического ИИ машины рассуждали, используя жестко запрограммированные представления о мире: что он состоит из дискретных объектов, которые находятся друг с другом в различных отношениях.
Но ИИ хорош ровно настолько насколько хороши примеры, на которых его обучали. Чтобы приблизить его к идеалу, нужно позволить ему учиться в более богатой среде, которую он сможет самостоятельно исследовать. Также может помочь обучение в трехмерной среде — реальной или смоделированной.
https://sysblok.ru/neuroscience/pochemu-nejroset-tak-legko-obmanut/
Алена Завьялова
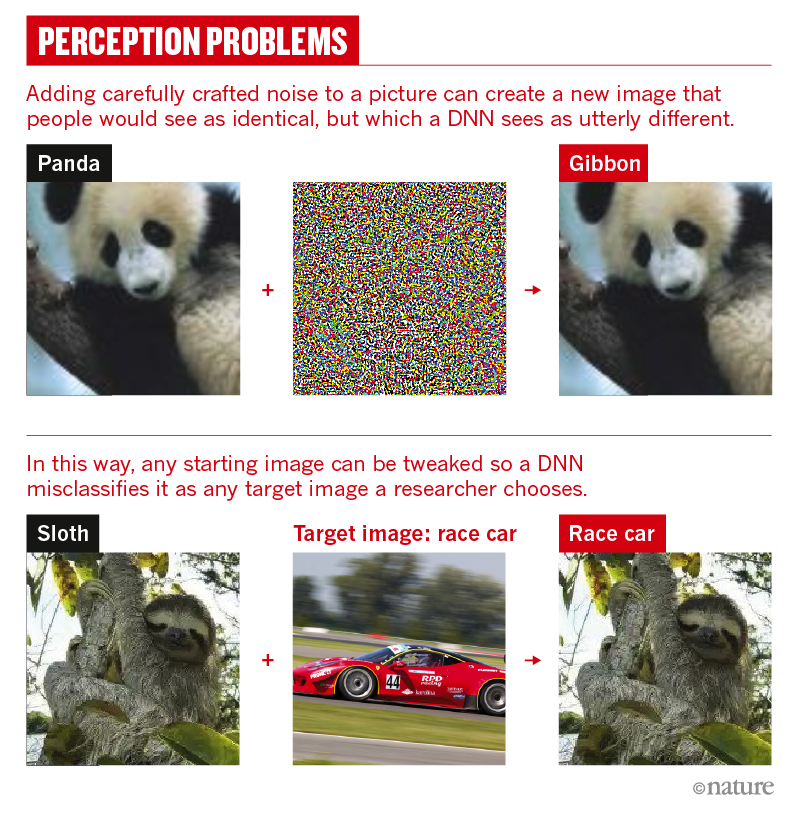{kind=link}
Обучаем Word2vec: практикум по созданию векторных моделей языка
#knowhow
Как использовать в своей повседневной работе векторные семантические модели и библиотеку Word2Vec? Это несложно: понадобится немного кода на Python и готовые векторные модели — например, с сайта RusVectores.
Word2vec — библиотека для получения векторных представлений слов на основе их совместной встречаемости в текстах. Системный Блокъ уже писал ранее о том, как работают эти модели, и вы можете освежить в памяти механизмы работы Word2vec, прочитав нашу статью.
Сейчас мы займемся более практичными и приземленными вещами: научимся использовать Word2vec в своей повседневной работе. Мы будем использовать реализацию Word2vec в библиотеке Gensim для языка программирования Python.
Что мы научимся делать
• В первой части мы научимся предобрабатывать текстовые файлы и самостоятельно тренировать векторную модель на своих данных.
• Во второй части мы разберемся, как загружать уже готовые векторные модели и работать с ними. Например, мы научимся выполнять простые операции над векторами слов, такие как «найти слово с наиболее близким вектором» или «вычислить коэффициент близости между двумя векторами слов».
• Также мы рассмотрим более сложные операции над векторами, например, «найти семантические аналоги» или «найти лишний вектор в группе слов».
Для прохождения тьюториала мы рекомендуем использовать Python3. Работоспособность кода для Python2 не гарантируется. Код из этого тьюториала также доступен в формате jupyter-тетрадки.
https://sysblok.ru/knowhow/obuchaem-word2vec-praktikum-po-sozdaniju-vektornyh-modelej-jazyka/
Елизавета Кузьменко
#knowhow
Как использовать в своей повседневной работе векторные семантические модели и библиотеку Word2Vec? Это несложно: понадобится немного кода на Python и готовые векторные модели — например, с сайта RusVectores.
Word2vec — библиотека для получения векторных представлений слов на основе их совместной встречаемости в текстах. Системный Блокъ уже писал ранее о том, как работают эти модели, и вы можете освежить в памяти механизмы работы Word2vec, прочитав нашу статью.
Сейчас мы займемся более практичными и приземленными вещами: научимся использовать Word2vec в своей повседневной работе. Мы будем использовать реализацию Word2vec в библиотеке Gensim для языка программирования Python.
Что мы научимся делать
• В первой части мы научимся предобрабатывать текстовые файлы и самостоятельно тренировать векторную модель на своих данных.
• Во второй части мы разберемся, как загружать уже готовые векторные модели и работать с ними. Например, мы научимся выполнять простые операции над векторами слов, такие как «найти слово с наиболее близким вектором» или «вычислить коэффициент близости между двумя векторами слов».
• Также мы рассмотрим более сложные операции над векторами, например, «найти семантические аналоги» или «найти лишний вектор в группе слов».
Для прохождения тьюториала мы рекомендуем использовать Python3. Работоспособность кода для Python2 не гарантируется. Код из этого тьюториала также доступен в формате jupyter-тетрадки.
https://sysblok.ru/knowhow/obuchaem-word2vec-praktikum-po-sozdaniju-vektornyh-modelej-jazyka/
Елизавета Кузьменко
{kind=link}
Как нейросеть узнает растения и почему она ошибается
#knowhow #biology
Автоматические определители живых организмов стали привычными приложениями на смартфонах любителей природы: достаточно просто навести камеру на растение или животное, чтобы определить, что это.
Любители природы разделились на два лагеря. Одни восторгаются такой простой возможностью познакомиться с природой поближе, другие утверждают, что правильно определить растение или животное с помощью этой технологии невозможно. Кто прав? Разбираемся, как устроены такие приложения и что у них под капотом.
Мы уже рассказывали о проекте iNaturalist — социальной сети для любителей природы, где каждый пользователь может загружать свои изображения, а эксперты определяют видовую принадлежность объекта. На данный момент на платформу загружено 10 880 718 фотонаблюдений растений, для которых эксперты определили видовую принадлежность.
На этой же платформе работает интерфейс автоматического распознавания видов. Фотографии, на которых растения уже определены, используются для обучения нейросетей, которые распознают виды.
В основе технологии распознавания объектов лежат механизмы компьютерного зрения, которые успешно применяются в разных областях — от машин-беспилотников до диагностики рака. Подробнее об этой технологии можно почитать в другой нашей статье.
Как работает распознавание растений в приложении iNaturalist
Алгоритмы конкретно для iNaturalist разработаны в 2017 году и периодически обновляются. Система по ряду параметров запоминает, какое фото к какой категории — к какому виду — относится. После того как пользователь загрузит фотографию, начинается ее анализ и сравнение полученных параметров с базой уже имеющихся фотографий.
Более 10 миллионов изображений — цифра внушительная и вроде бы достаточная для качественного обучения нейросети. Однако, посмотрев на структуру этих данных поближе, мы увидим, что они крайне неоднородны.
Есть широко распространенные виды с десятками тысяч фотографий со всего мира. Если на загруженном пользователем изображении широко распространенный вид, и в базе уже много его фотографий, то нейросеть с большей вероятностью его верно распознает.
А если вид редкий, да еще сфотографирован с необычного ракурса, то более вероятны ошибки со стороны системы. Есть огромный блок видов, для которых в базе не наберется и пяти фотографий. Причины могут быть разными: произрастание этих видов в труднодоступных местах, малая численность, сложность идентификации даже для специалистов. И по таким видам для обучения алгоритмов материала оказывается очень мало, ведь нейросеть — это не человек-эксперт. Она анализирует заданные параметры и имеет только тот опыт, который мы туда заложили.
Дополнительную сложность для алгоритмов дает фон, на котором сняты растения. Он бывает очень разным: это может быть и небо, и другие травы, и камни, и человеческие руки. Случаи, когда растение на фото почти сливается с другими травами, для распознавания особенно сложны. Многое зависит и от качества изображения: если все смазано и от цветка лишь кусок — такое растение даже опытный профессор не факт, что определит.
https://sysblok.ru/knowhow/kak-nejroset-uznaet-rastenija-i-pochemu-ona-oshibaetsja/
Ксения Дудова
#knowhow #biology
Автоматические определители живых организмов стали привычными приложениями на смартфонах любителей природы: достаточно просто навести камеру на растение или животное, чтобы определить, что это.
Любители природы разделились на два лагеря. Одни восторгаются такой простой возможностью познакомиться с природой поближе, другие утверждают, что правильно определить растение или животное с помощью этой технологии невозможно. Кто прав? Разбираемся, как устроены такие приложения и что у них под капотом.
Мы уже рассказывали о проекте iNaturalist — социальной сети для любителей природы, где каждый пользователь может загружать свои изображения, а эксперты определяют видовую принадлежность объекта. На данный момент на платформу загружено 10 880 718 фотонаблюдений растений, для которых эксперты определили видовую принадлежность.
На этой же платформе работает интерфейс автоматического распознавания видов. Фотографии, на которых растения уже определены, используются для обучения нейросетей, которые распознают виды.
В основе технологии распознавания объектов лежат механизмы компьютерного зрения, которые успешно применяются в разных областях — от машин-беспилотников до диагностики рака. Подробнее об этой технологии можно почитать в другой нашей статье.
Как работает распознавание растений в приложении iNaturalist
Алгоритмы конкретно для iNaturalist разработаны в 2017 году и периодически обновляются. Система по ряду параметров запоминает, какое фото к какой категории — к какому виду — относится. После того как пользователь загрузит фотографию, начинается ее анализ и сравнение полученных параметров с базой уже имеющихся фотографий.
Более 10 миллионов изображений — цифра внушительная и вроде бы достаточная для качественного обучения нейросети. Однако, посмотрев на структуру этих данных поближе, мы увидим, что они крайне неоднородны.
Есть широко распространенные виды с десятками тысяч фотографий со всего мира. Если на загруженном пользователем изображении широко распространенный вид, и в базе уже много его фотографий, то нейросеть с большей вероятностью его верно распознает.
А если вид редкий, да еще сфотографирован с необычного ракурса, то более вероятны ошибки со стороны системы. Есть огромный блок видов, для которых в базе не наберется и пяти фотографий. Причины могут быть разными: произрастание этих видов в труднодоступных местах, малая численность, сложность идентификации даже для специалистов. И по таким видам для обучения алгоритмов материала оказывается очень мало, ведь нейросеть — это не человек-эксперт. Она анализирует заданные параметры и имеет только тот опыт, который мы туда заложили.
Дополнительную сложность для алгоритмов дает фон, на котором сняты растения. Он бывает очень разным: это может быть и небо, и другие травы, и камни, и человеческие руки. Случаи, когда растение на фото почти сливается с другими травами, для распознавания особенно сложны. Многое зависит и от качества изображения: если все смазано и от цветка лишь кусок — такое растение даже опытный профессор не факт, что определит.
https://sysblok.ru/knowhow/kak-nejroset-uznaet-rastenija-i-pochemu-ona-oshibaetsja/
Ксения Дудова
{kind=link}
Русский 360°: виртуальный музей без границ
#arts #digitalheritage
Технологии формируют новое пространство вокруг нас и расширяют сферы применения научно-просветительских и образовательных программ. Пример в области искусства — цифровые проекты Государственного Русского музея. Портал «Виртуальный музей» собрал всю информацию о деятельности Русского музея в сфере информационных технологий воедино.
Оцифрованная коллекция музея
Коллекция Русского музея — крупнейшее собрание русского искусства в мире: тысячи картин, сервизы императорского фарфорового завода, скульптуры, гравюры и т. д. Коллекция была оцифрована и теперь доступна онлайн. Также есть фотогалерея, которая иллюстрирует историю музея с 1898 года.
3D-туры по экспозициям
3D-экскурсии обеспечивают полное погружение в музейную атмосферу. Это достигается благодаря технологиям, похожим на Google Street View. На сайте проекта есть два типа 3D-экскурсий. Тур по основной экспозиции и проект «Шедевры русского музея в „Одноклассниках“» — это фотографии экспонатов, виртуальные панорамы залов, медиатека с аудиогидом, который озвучивают звезды: Боярский рассказывает об истории создания картины Карла Брюллова «Последний день Помпеи», Ургант — о «Шестикрылом серафиме» Врубеля.
Электронная экспозиция Центра мультимедиа
Электронную экспозицию Центра мультимедиа составляют физические выставки в музее, экскурсионный сюжет которых строится при помощи компьютерных фильмов, аудио и видео сопровождения, 3D-моделирования, интерактивного режима для пользователей, технологий микромэппинга и кинекта. Такие интерактивные экспозиции посвящены, например, владельцу Михайловского замка — Павлу I, а в 2020 году работу начинает техно-игровой маршрут «Петр I и Павел I: прадед и правнук». На портале можно оставить заявку на посещение центра мультимедиа и заказать групповую экскурсию по экспозиции.
Онлайн-лекторий Русского музея
Этот проект включает в себя проведение лекций с онлайн-трансляцией на платформах музея в социальных сетях. Публичные лекции читаются по теории и истории изобразительного искусства, проводятся тематические встречи и конференции с сотрудниками и ведущими специалистами Русского музея, кураторами выставок, реставраторами, исследователями и профессионалами в других сферах. На портале доступно расписание ближайших лекций и видеозаписи прошедших.
Виртуальный филиал
«Русский музей: виртуальный филиал» — это межрегиональный и международный проект, воплощающий идею доступности крупнейшей в России коллекции русского искусства самой широкой аудитории за пределами Санкт-Петербурга. Информационно-образовательный центр виртуального филиала состоит из медиатеки, информационно-образовательного класса и мультимедийного кинотеатра и содержит материалы по истории русского искусства в период с X по XXI вв., архивной деятельности, изучению и показу музейных экспонатов.
«Сага о династии»
С 2013 года Русский музей работает над реализацией проекта преобразования Михайловского замка в музей нового типа, который будет посвящен династии Романовых. «Сага о династии» будет представлять собой историческую драму в десяти актах (+ эпилог), каждый из которых посвящен эпохе правления отдельной исторической личности. Основаны они на временных выставках, по итогам которых были подготовлены виртуальные туры.
Русский музей в Google Arts & Culture
Русский музей принял участие в проекте Google Arts & Culture. Это цифровое собрание изображений предметов искусства из известных музеев и художественных галерей всего мира в наивысшем качестве. Каждое такое изображение — это примерно 7 миллиардов пикселей, которые позволяют исследовать мельчайшие детали полотен, манеру письма и особенности стиля художника. Была оцифрована картина «Последний день Помпеи» Карла Брюллова.
https://sysblok.ru/arts/russkij-360-virtualnyj-muzej-bez-granic/
Мария Черных
#arts #digitalheritage
Технологии формируют новое пространство вокруг нас и расширяют сферы применения научно-просветительских и образовательных программ. Пример в области искусства — цифровые проекты Государственного Русского музея. Портал «Виртуальный музей» собрал всю информацию о деятельности Русского музея в сфере информационных технологий воедино.
Оцифрованная коллекция музея
Коллекция Русского музея — крупнейшее собрание русского искусства в мире: тысячи картин, сервизы императорского фарфорового завода, скульптуры, гравюры и т. д. Коллекция была оцифрована и теперь доступна онлайн. Также есть фотогалерея, которая иллюстрирует историю музея с 1898 года.
3D-туры по экспозициям
3D-экскурсии обеспечивают полное погружение в музейную атмосферу. Это достигается благодаря технологиям, похожим на Google Street View. На сайте проекта есть два типа 3D-экскурсий. Тур по основной экспозиции и проект «Шедевры русского музея в „Одноклассниках“» — это фотографии экспонатов, виртуальные панорамы залов, медиатека с аудиогидом, который озвучивают звезды: Боярский рассказывает об истории создания картины Карла Брюллова «Последний день Помпеи», Ургант — о «Шестикрылом серафиме» Врубеля.
Электронная экспозиция Центра мультимедиа
Электронную экспозицию Центра мультимедиа составляют физические выставки в музее, экскурсионный сюжет которых строится при помощи компьютерных фильмов, аудио и видео сопровождения, 3D-моделирования, интерактивного режима для пользователей, технологий микромэппинга и кинекта. Такие интерактивные экспозиции посвящены, например, владельцу Михайловского замка — Павлу I, а в 2020 году работу начинает техно-игровой маршрут «Петр I и Павел I: прадед и правнук». На портале можно оставить заявку на посещение центра мультимедиа и заказать групповую экскурсию по экспозиции.
Онлайн-лекторий Русского музея
Этот проект включает в себя проведение лекций с онлайн-трансляцией на платформах музея в социальных сетях. Публичные лекции читаются по теории и истории изобразительного искусства, проводятся тематические встречи и конференции с сотрудниками и ведущими специалистами Русского музея, кураторами выставок, реставраторами, исследователями и профессионалами в других сферах. На портале доступно расписание ближайших лекций и видеозаписи прошедших.
Виртуальный филиал
«Русский музей: виртуальный филиал» — это межрегиональный и международный проект, воплощающий идею доступности крупнейшей в России коллекции русского искусства самой широкой аудитории за пределами Санкт-Петербурга. Информационно-образовательный центр виртуального филиала состоит из медиатеки, информационно-образовательного класса и мультимедийного кинотеатра и содержит материалы по истории русского искусства в период с X по XXI вв., архивной деятельности, изучению и показу музейных экспонатов.
«Сага о династии»
С 2013 года Русский музей работает над реализацией проекта преобразования Михайловского замка в музей нового типа, который будет посвящен династии Романовых. «Сага о династии» будет представлять собой историческую драму в десяти актах (+ эпилог), каждый из которых посвящен эпохе правления отдельной исторической личности. Основаны они на временных выставках, по итогам которых были подготовлены виртуальные туры.
Русский музей в Google Arts & Culture
Русский музей принял участие в проекте Google Arts & Culture. Это цифровое собрание изображений предметов искусства из известных музеев и художественных галерей всего мира в наивысшем качестве. Каждое такое изображение — это примерно 7 миллиардов пикселей, которые позволяют исследовать мельчайшие детали полотен, манеру письма и особенности стиля художника. Была оцифрована картина «Последний день Помпеи» Карла Брюллова.
https://sysblok.ru/arts/russkij-360-virtualnyj-muzej-bez-granic/
Мария Черных
{kind=link}
Геохронологический трекинг в истории
#history
Каждому, кто в школе заполнял контурные карты, известно, что исторические данные иногда гораздо удобнее представлять в пространстве. Для научного анализа событий прошлого историки используют более продвинутые географические методы. Среди них геохронологический трекинг — специализированный ГИС-инструмент.
Геохронологический трек — это сочетание геопространственных и хронологических данных в виде кривой, которая соединяет точки на карте. Эти точки основаны на биографической информации об исторической личности или объекте и имеют строгую историко-географическую привязку. А дуги, которые их соединяют, носят условно-логический характер.
Технология создания геохронологического трека
Рассмотрим процесс создания геохронологического трека, а также его особенности, на основе послужного списка военнослужащего, в котором отражены изменения мест его службы в первой половине ХХ века.
Сначала в отдельную базу данных вносятся все населенные пункты, в которых когда-либо расквартировывались военные части. В качестве координат населенного пункта указывается широта и долгота почтового отделения. Далее составляется перечень воинских частей. В таблице указывается их наименование и период нахождения в населенном пункте.
Структура обобщенных данных позволяет составить индивидуальные послужные карточки и на их основе выявить геохронологический трек индивида. Указывается его дата рождения с точностью до месяца, а из уже имеющихся таблиц с перечнем воинских частей заполняются поля «Наименование воинской части» и «Дата назначения в часть». Послужной список считается непрерывным: дата завершения службы в одной части — дата начала службы в новой части. По таблице формируется база данных «Геохронологический трек индивида».
Конечный результат геохронологического трекинга — визуальная интерпретация базы данных в виде графа на основе ГИС-подложки (карты-основы). Визуализировать данные можно с помощью специализированных ГИС-приложений (например, ArcMap) или на основе картографического набора данных (например, OpenStreetMap). В данном случае вершинами трека (графа) окажутся места дислокации воинских частей, а дугами — направленные линии, которые условно позволяют проследить перемещение индивида.
Дуги различаются по толщине и цвету в зависимости от данных, внесенных в таблицу. Например, чем больше перемещений индвида из пункта, А в пункт В, тем линия, соединяющая точки, А и В на карте, толще.
Ниже прикрепляем геохронологический трек индивида, который был создан на основе послужного списка Н. П. Ивакина.
Чем геохронологический трекинг полезен историкам
Геохронологический трекинг позволяет наглядно представить исторические факты и осветить не вполне очевидные аспекты деятельности социальных групп и индивидов. То есть пронаблюдать, увидеть историю.
ГИС-технологии значительно упрощают элемент наблюдения за историческими процессами и позволяют гораздо больше времени уделить «историческому следствию», то есть построению исторических гипотез, их подтверждению или опровержению.
Готовый геохронологический трек — визуализация текстовой информации. Её гораздо
проще воспринимать и анализировать, чтобы подтвердить или опровергнуть те или иные предположения.
На основании статистически значимых документов можно, например, проанализировать объективные тенденции большого террора в СССР или углубиться в изучение миграционных процессов в Европе середины V века нашей эры. За какую бы историческую задачу мы ни брались, использование геохронологического трекинга в разы сократит временные затраты на ее выполнение.
Конечно, эта технология далеко не универсальна, и целью дальнейших исследований будет определение ее возможностей и варианты совершенствования.
https://sysblok.ru/history/geohronologicheskij-treking-v-istorii/
Мария Черных
#history
Каждому, кто в школе заполнял контурные карты, известно, что исторические данные иногда гораздо удобнее представлять в пространстве. Для научного анализа событий прошлого историки используют более продвинутые географические методы. Среди них геохронологический трекинг — специализированный ГИС-инструмент.
Геохронологический трек — это сочетание геопространственных и хронологических данных в виде кривой, которая соединяет точки на карте. Эти точки основаны на биографической информации об исторической личности или объекте и имеют строгую историко-географическую привязку. А дуги, которые их соединяют, носят условно-логический характер.
Технология создания геохронологического трека
Рассмотрим процесс создания геохронологического трека, а также его особенности, на основе послужного списка военнослужащего, в котором отражены изменения мест его службы в первой половине ХХ века.
Сначала в отдельную базу данных вносятся все населенные пункты, в которых когда-либо расквартировывались военные части. В качестве координат населенного пункта указывается широта и долгота почтового отделения. Далее составляется перечень воинских частей. В таблице указывается их наименование и период нахождения в населенном пункте.
Структура обобщенных данных позволяет составить индивидуальные послужные карточки и на их основе выявить геохронологический трек индивида. Указывается его дата рождения с точностью до месяца, а из уже имеющихся таблиц с перечнем воинских частей заполняются поля «Наименование воинской части» и «Дата назначения в часть». Послужной список считается непрерывным: дата завершения службы в одной части — дата начала службы в новой части. По таблице формируется база данных «Геохронологический трек индивида».
Конечный результат геохронологического трекинга — визуальная интерпретация базы данных в виде графа на основе ГИС-подложки (карты-основы). Визуализировать данные можно с помощью специализированных ГИС-приложений (например, ArcMap) или на основе картографического набора данных (например, OpenStreetMap). В данном случае вершинами трека (графа) окажутся места дислокации воинских частей, а дугами — направленные линии, которые условно позволяют проследить перемещение индивида.
Дуги различаются по толщине и цвету в зависимости от данных, внесенных в таблицу. Например, чем больше перемещений индвида из пункта, А в пункт В, тем линия, соединяющая точки, А и В на карте, толще.
Ниже прикрепляем геохронологический трек индивида, который был создан на основе послужного списка Н. П. Ивакина.
Чем геохронологический трекинг полезен историкам
Геохронологический трекинг позволяет наглядно представить исторические факты и осветить не вполне очевидные аспекты деятельности социальных групп и индивидов. То есть пронаблюдать, увидеть историю.
ГИС-технологии значительно упрощают элемент наблюдения за историческими процессами и позволяют гораздо больше времени уделить «историческому следствию», то есть построению исторических гипотез, их подтверждению или опровержению.
Готовый геохронологический трек — визуализация текстовой информации. Её гораздо
проще воспринимать и анализировать, чтобы подтвердить или опровергнуть те или иные предположения.
На основании статистически значимых документов можно, например, проанализировать объективные тенденции большого террора в СССР или углубиться в изучение миграционных процессов в Европе середины V века нашей эры. За какую бы историческую задачу мы ни брались, использование геохронологического трекинга в разы сократит временные затраты на ее выполнение.
Конечно, эта технология далеко не универсальна, и целью дальнейших исследований будет определение ее возможностей и варианты совершенствования.
https://sysblok.ru/history/geohronologicheskij-treking-v-istorii/
Мария Черных
{kind=link}
Sketch Engine и Маяковский. Часть I: человек до и после революции
#philology #knowhow
Sketch Engine — инструмент для корпусных исследований, то есть исследований, которые выполняются на материале корпусов, больших электронных коллекций текстов. Sketch Engine может быть полезен не только исследователям-лингвистам и филологам, но и лексикографам, переводчикам и тем, кто изучает и преподает язык.
Почему такое название — «скетч»? Скетч — это быстрый набросок, пробная версия рисунка. Очень простой и незавершенный, скетч, тем не менее, передает общий замысел рисунка: мы уже понимаем, что хочет изобразить художник. Так и Sketch Engine позволяет создать «скетч», набросок, образ отдельного слова, текста или даже целого корпуса. С его помощью мы можем например, понять, в каких контекстах встречается интересующее нас слово, какие у интересующего нас текста или корпуса ключевые слова, а затем уже интерпретировать и использовать полученные результаты.
При помощи Sketch Engine мы попробуем провести «расследование», чтобы выяснить, какой лирический герой чаще появляется в творчестве Маяковского: поэт-агитатор на пароходе современности или отвергнутый и непонятый всеми романтик, каким автор предстает перед нами в своей любовной лирике.
Чтобы создать свой корпус и работать с ним, мы воспользовались бесплатной онлайн-версией проекта, которая действует 30 дней. Тексты Владимира Маяковского мы скачали из поэтического подкорпуса НКРЯ.
Анализ с помощью «Word Sketch»
Мы разбили свой корпус на подкорпусы «до» и «после» Революции. Это позволит нам, например, оценить частоту появления одного и того же слова в разных подкорпусах или сравнить ключевые слова разных подкорпусов.
Мы хотим узнать, как меняется образ человека в стихотворениях Маяковского: в инструменте «Word Sketch» задаем лемму «Человек» и запускаем программу для обоих подкорпусов. Теперь попробуем интерпретировать полученные результаты.
Что делает человек в стихах Маяковского, написанных до революции? Ничего особенного: он рождается, растет, ждет чего-то, дичает и в итоге исчезает. А вот после революции он деятелен и полон энергии: ходит, ездит, прыгает, готов ринуться куда-то… в общем, живет полной жизнью.
Если мы предположим, что главным героем поэзии Маяковского был простой рабочий, представитель пролетариата, то такие перемены могли быть связаны с изменением социального положения героя, установлением новой власти и радужными перспективами социализма.
Анализ с помощью «Concordance»
Образ человека не исчерпывается действиями. С помощью инструмента «Concordance» посмотрим на расширенный контекст слова «Человек», то есть, не просто на сочетания слов, а на целые предложения, в которых встречается указанное слово.
При анализе полученных данных увидим, что до 1917 года в творчестве Маяковского было много восклицаний и побудительных предложений, был призыв к действию («Эй, человек, землю саму зови на вальс!»). А после 1917 года предложения становятся утвердительными, в них прославляется человек, его всесилие и могущество («миром правит сам человек», «Люди двигают горами»).
Почему так мало призыва брать новые высоты в послереволюционном периоде творчества Маяковского? После революции в творчестве Маяковского часто встречается образ «искусственных людей»: «Этими — и добрыми, и кобры лютей, Союз до краев загружен». Они — порождение бюрократической системы, которая рождается вместе с молодым Советским государством, хоть и совершенно противоречит его идее.
Благодаря «Sketch Engine» мы выяснили, что человек у Маяковского, хоть и стал деятельным после Революции, но стал не личностью, а винтиком в системе. Виной всему бюрократия, которая возникла в государстве, которое изначально должно было быть основано на всеобщем равенстве и принципах справедливости.
А все технические подробности со скриншотами — в нашей статье: https://sysblok.ru/philology/sketch-engine-i-majakovskij-chast-i-chelovek-do-i-posle-revoljucii/
Мария Черных, Дарья Балуева
#philology #knowhow
Sketch Engine — инструмент для корпусных исследований, то есть исследований, которые выполняются на материале корпусов, больших электронных коллекций текстов. Sketch Engine может быть полезен не только исследователям-лингвистам и филологам, но и лексикографам, переводчикам и тем, кто изучает и преподает язык.
Почему такое название — «скетч»? Скетч — это быстрый набросок, пробная версия рисунка. Очень простой и незавершенный, скетч, тем не менее, передает общий замысел рисунка: мы уже понимаем, что хочет изобразить художник. Так и Sketch Engine позволяет создать «скетч», набросок, образ отдельного слова, текста или даже целого корпуса. С его помощью мы можем например, понять, в каких контекстах встречается интересующее нас слово, какие у интересующего нас текста или корпуса ключевые слова, а затем уже интерпретировать и использовать полученные результаты.
При помощи Sketch Engine мы попробуем провести «расследование», чтобы выяснить, какой лирический герой чаще появляется в творчестве Маяковского: поэт-агитатор на пароходе современности или отвергнутый и непонятый всеми романтик, каким автор предстает перед нами в своей любовной лирике.
Чтобы создать свой корпус и работать с ним, мы воспользовались бесплатной онлайн-версией проекта, которая действует 30 дней. Тексты Владимира Маяковского мы скачали из поэтического подкорпуса НКРЯ.
Анализ с помощью «Word Sketch»
Мы разбили свой корпус на подкорпусы «до» и «после» Революции. Это позволит нам, например, оценить частоту появления одного и того же слова в разных подкорпусах или сравнить ключевые слова разных подкорпусов.
Мы хотим узнать, как меняется образ человека в стихотворениях Маяковского: в инструменте «Word Sketch» задаем лемму «Человек» и запускаем программу для обоих подкорпусов. Теперь попробуем интерпретировать полученные результаты.
Что делает человек в стихах Маяковского, написанных до революции? Ничего особенного: он рождается, растет, ждет чего-то, дичает и в итоге исчезает. А вот после революции он деятелен и полон энергии: ходит, ездит, прыгает, готов ринуться куда-то… в общем, живет полной жизнью.
Если мы предположим, что главным героем поэзии Маяковского был простой рабочий, представитель пролетариата, то такие перемены могли быть связаны с изменением социального положения героя, установлением новой власти и радужными перспективами социализма.
Анализ с помощью «Concordance»
Образ человека не исчерпывается действиями. С помощью инструмента «Concordance» посмотрим на расширенный контекст слова «Человек», то есть, не просто на сочетания слов, а на целые предложения, в которых встречается указанное слово.
При анализе полученных данных увидим, что до 1917 года в творчестве Маяковского было много восклицаний и побудительных предложений, был призыв к действию («Эй, человек, землю саму зови на вальс!»). А после 1917 года предложения становятся утвердительными, в них прославляется человек, его всесилие и могущество («миром правит сам человек», «Люди двигают горами»).
Почему так мало призыва брать новые высоты в послереволюционном периоде творчества Маяковского? После революции в творчестве Маяковского часто встречается образ «искусственных людей»: «Этими — и добрыми, и кобры лютей, Союз до краев загружен». Они — порождение бюрократической системы, которая рождается вместе с молодым Советским государством, хоть и совершенно противоречит его идее.
Благодаря «Sketch Engine» мы выяснили, что человек у Маяковского, хоть и стал деятельным после Революции, но стал не личностью, а винтиком в системе. Виной всему бюрократия, которая возникла в государстве, которое изначально должно было быть основано на всеобщем равенстве и принципах справедливости.
А все технические подробности со скриншотами — в нашей статье: https://sysblok.ru/philology/sketch-engine-i-majakovskij-chast-i-chelovek-do-i-posle-revoljucii/
Мария Черных, Дарья Балуева
{kind=link}
Реставрация картин: от вакуумных столов до машинного обучения
#arts
Картины Ильи Репина можно назвать «хронически больными», уверяют сотрудники Третьяковской галереи. Исследование его работ показало, что более трех десятков его картин написаны некачественными масляными красками и с применением некачественных грунтов.
Картина «Иван Грозный и сын его Иван» никогда не покидала стен Третьяковской галереи, но и там ее все время подстерегали опасности.
• В 1913 году на картину было совершено покушение: душевнобольной Абрам Балашов изрезал лицо царя. Для восстановления этих повреждений был нанесен дублирующий слой.
• В 1922 году дождливая осень и неотапливаемые залы спровоцировали осыпи краски с картины — влагу со стен хранители музея собирали тряпками.
• В 2018 посетитель Третьяковки в Лаврушинском переулке трижды ударил полотно металлической стойкой ограждения, разбив защитное стекло.
Третьяковская галерея пригласила западных специалистов, которые предложили несколько вариантов для реставрации — методика «холодного дублирования», компьютерное моделирование процессов старения реставрационных материалов, комбинированные методы различных типов визуализаций.
Мы изучили методы эффективных реставрационных работ, которые невозможны без компьютерных технологий и анализа данных, на примере российского опыта.
Рентгенографическое исследование. Рентгенография используется для уточнения состояния сохранности предметов, стадии написания полотна, и позволяет составить предварительное мнение о материалах, из которых состоит работа. Большие полотна, такие как «Иван Грозный и сын его Иван» (2×2,54 м), сканируют фрагментарно и соединяют части воедино.
Физико-химические исследования. Способствуют изучению процессов нейтрализации кислот на поверхности стареющего полотна, определяют уровень деформации станковой живописи при повышенной влажности в разных условиях хранения работ во время экспозиционирования.
Дублирование и укрепление красочного слоя картин. В 70-х годах прошлого столетия появились вакуумные столы с подогревом, которые позволяют точно регулировать и задавать температуру и давление для реставрационных работ картин. Вместо традиционных утюжков в практику вошли обогреваемые шпатели и специальные подрамники, которые регулируют натяжение холста.
Моделирование и сбор данных. Любое исследование требует моделирования и сбора данных, чтобы оценить риски и затраты и предсказать результаты. Для этого используют инструменты машинного обучения — сверточные нейросети. Они решают зрительные задачи: превращают визуальные данные в смысловые единицы. Комбинируя различные методы визуализации, исследователи видят под поверхностью полотна непосредственное изменение химического состава художественных пигментов, которые использовал художник.
Реставрационная съемка. ГМИИ им. Пушкина при реставрации и диджитализации объектов культурного наследия использует технологию реставрационной съемки, которая позволяет рассмотреть объект с разных ракурсов. Цифровая реставрация объекта происходит вручную: такая методика позволяет запечатлеть процесс реставрации в онлайн-пространстве. Реставраторы, используя цифровые методы, удешевляют сам процесс и оценивают целесообразность воссоздания объекта в первоначальном виде. Сбор и восстановление культурных артефактов с помощью реставрационной съемки может стимулировать разработку алгоритма, который на основе максимально точных цифровых образов одной эпохи, художественного направления или выделенной группы, сможет автоматизировать процесс реставрации.
https://sysblok.ru/arts/restavracija-kartin-ot-vakuumnyh-stolov-do-mashinnogo-obuchenija/
Дарья Джиоева
#arts
Картины Ильи Репина можно назвать «хронически больными», уверяют сотрудники Третьяковской галереи. Исследование его работ показало, что более трех десятков его картин написаны некачественными масляными красками и с применением некачественных грунтов.
Картина «Иван Грозный и сын его Иван» никогда не покидала стен Третьяковской галереи, но и там ее все время подстерегали опасности.
• В 1913 году на картину было совершено покушение: душевнобольной Абрам Балашов изрезал лицо царя. Для восстановления этих повреждений был нанесен дублирующий слой.
• В 1922 году дождливая осень и неотапливаемые залы спровоцировали осыпи краски с картины — влагу со стен хранители музея собирали тряпками.
• В 2018 посетитель Третьяковки в Лаврушинском переулке трижды ударил полотно металлической стойкой ограждения, разбив защитное стекло.
Третьяковская галерея пригласила западных специалистов, которые предложили несколько вариантов для реставрации — методика «холодного дублирования», компьютерное моделирование процессов старения реставрационных материалов, комбинированные методы различных типов визуализаций.
Мы изучили методы эффективных реставрационных работ, которые невозможны без компьютерных технологий и анализа данных, на примере российского опыта.
Рентгенографическое исследование. Рентгенография используется для уточнения состояния сохранности предметов, стадии написания полотна, и позволяет составить предварительное мнение о материалах, из которых состоит работа. Большие полотна, такие как «Иван Грозный и сын его Иван» (2×2,54 м), сканируют фрагментарно и соединяют части воедино.
Физико-химические исследования. Способствуют изучению процессов нейтрализации кислот на поверхности стареющего полотна, определяют уровень деформации станковой живописи при повышенной влажности в разных условиях хранения работ во время экспозиционирования.
Дублирование и укрепление красочного слоя картин. В 70-х годах прошлого столетия появились вакуумные столы с подогревом, которые позволяют точно регулировать и задавать температуру и давление для реставрационных работ картин. Вместо традиционных утюжков в практику вошли обогреваемые шпатели и специальные подрамники, которые регулируют натяжение холста.
Моделирование и сбор данных. Любое исследование требует моделирования и сбора данных, чтобы оценить риски и затраты и предсказать результаты. Для этого используют инструменты машинного обучения — сверточные нейросети. Они решают зрительные задачи: превращают визуальные данные в смысловые единицы. Комбинируя различные методы визуализации, исследователи видят под поверхностью полотна непосредственное изменение химического состава художественных пигментов, которые использовал художник.
Реставрационная съемка. ГМИИ им. Пушкина при реставрации и диджитализации объектов культурного наследия использует технологию реставрационной съемки, которая позволяет рассмотреть объект с разных ракурсов. Цифровая реставрация объекта происходит вручную: такая методика позволяет запечатлеть процесс реставрации в онлайн-пространстве. Реставраторы, используя цифровые методы, удешевляют сам процесс и оценивают целесообразность воссоздания объекта в первоначальном виде. Сбор и восстановление культурных артефактов с помощью реставрационной съемки может стимулировать разработку алгоритма, который на основе максимально точных цифровых образов одной эпохи, художественного направления или выделенной группы, сможет автоматизировать процесс реставрации.
https://sysblok.ru/arts/restavracija-kartin-ot-vakuumnyh-stolov-do-mashinnogo-obuchenija/
Дарья Джиоева
{kind=link}