
У нас хорошие новости для тех, кому становится плохо уже от одного упоминания IELTS, TOEFL, DELF, GZ и им подобных: уровень владения языком можно автоматически оценивать по движениям глаз!
При чтении зрачок движется не плавно, а скачками, останавливаясь на незнакомых словах. С помощью технологии айтрекинга эти скачки можно измерить в миллисекундах — и сравнить показатели для людей с разным уровнем языка. Исследователи утверждают, что это работает даже лучше международных тестов.
https://telegra.ph/Po-glazam-vizhu-09-06
При чтении зрачок движется не плавно, а скачками, останавливаясь на незнакомых словах. С помощью технологии айтрекинга эти скачки можно измерить в миллисекундах — и сравнить показатели для людей с разным уровнем языка. Исследователи утверждают, что это работает даже лучше международных тестов.
https://telegra.ph/Po-glazam-vizhu-09-06
Telegraph
«По глазам вижу»: как оценить знание английского с помощью айтрекинга
Работа исследователей из Массачусетского технологического института (MIT) показала, что владение английским как иностранным можно «считать по глазам» в буквальном смысле — при помощи технологии айтрекинга. Чтение не то, чем кажется Помните этот небольшой…
Никого уже не удивишь тем, что машины рано или поздно вытеснят многие профессии. Они уже научились не только выполнять механическую работу, но и решать задачи, которые, казалось бы, требуют развитых социальных навыков. Например, проводить собеседования при приеме на работу.
Если вы думаете, что робот-HR будет оценивать лишь ваши профессиональные качества, то вас ждет разочарование: в интервью с бездушной машиной все еще важна внешность!
https://telegra.ph/Kak-vpechatlit-robota-09-09
Если вы думаете, что робот-HR будет оценивать лишь ваши профессиональные качества, то вас ждет разочарование: в интервью с бездушной машиной все еще важна внешность!
https://telegra.ph/Kak-vpechatlit-robota-09-09
Telegraph
Как впечатлить робота: собеседование с искусственным интеллектом
Байки про «тупых эйчаров» скоро могут стать историей: подбор персонала переходит от людей к алгоритмам машинного обучения. Хотите устроиться в Tesla, Unilever или LinkedIn? Возможно, вам придется не отвечать на вопросы HR-специалиста с листочка, а играть…
Откуда поисковики знают, что «пожрать», «поесть» и «кафе» — это близкие вещи? Как можно научить алгоритм различать слова по смысловой близости? Где можно испытать такие алгоритмы самому? Тыц по ссылке — и узнаете!
https://telegra.ph/Lampochka-i-lapochka-09-09
https://telegra.ph/Lampochka-i-lapochka-09-09
Telegraph
Лампочка светит, а лапочка — нет: как компьютеры «вычисляют» значения слов
Если вбить в поисковике запрос типа «пожрать в Москве», вы получите много результатов, в которых вообще нет слова «пожрать» — вместо этого там будут «поесть» , «есть», «еда», «кафе» и т.п. Как поисковик понимает, что нужно показать все это? Хитростей тут…
Думаете, складывать и вычитать можно только числа? А вот и нет! В цифровую эпоху можно запросто решать примеры со словами.
Что получится, если вычесть из птицы крыло и прибавить плавник? Чему равно "жизнь минус любовь"? Системный Блокъ расскажет!
https://telegra.ph/Vo-chto-prevrashchaetsya-zhizn-bez-lyubvi-09-09
Что получится, если вычесть из птицы крыло и прибавить плавник? Чему равно "жизнь минус любовь"? Системный Блокъ расскажет!
https://telegra.ph/Vo-chto-prevrashchaetsya-zhizn-bez-lyubvi-09-09
Telegraph
Во что превращается жизнь без любви
Недавно мы писали о том, как компьютеры «понимают» значения слов благодаря дистрибутивным моделям (их еще называют векторными). Таким моделям не нужно толковых словарей, энциклопедий и справочников. Просто дайте им Очень. Много. Текстов — и вуаля, они могут…
Как вам идея связать все выложенные в интернете отсканированные ноты в единую машиночитаемую базу данных? Участникам проекта Music Encoding Initiative это кажется вполне реальным!
https://telegra.ph/Music-Encoding-Initiative-09-01
https://telegra.ph/Music-Encoding-Initiative-09-01
Telegraph
Music Encoding Initiative. Настоящее и будущее цифрового музыковедения
Music Encoding Initiative (MEI) — международная инициатива по созданию единого стандарта машиночитаемого кодирования нот. MEI — это название и проекта, и группы ученых, работающих над ним, и — в более узком смысле — сам язык разметки. Язык MEI основан на…
Как черкал ноты Бетховен: перевод с человеческого на компьютерный
https://telegra.ph/Cifrovoe-muzykovedenie-v-odin-klik-09-20
https://telegra.ph/Cifrovoe-muzykovedenie-v-odin-klik-09-20
Telegraph
Цифровое музыковедение в один клик
Мы уже писали о Music Encoding Initiative (MEI) — международной инициативе по созданию единого стандарта машиночитаемого кодирования нот. Сегодня хотим рассказать подробнее о конкретных проектах с использованием MEI. — Beethovens Werkstatt. Genetische Textkritik…
В Приморье сфальсифицировали данные на участках — и спалились. Но скоро выборами будут манипулировать прямо через мозг. Запасаемся шапочками из фольги.
https://telegra.ph/Polittehnologi-nauchilis-pronikat-v-mozg-09-23
https://telegra.ph/Polittehnologi-nauchilis-pronikat-v-mozg-09-23
Telegraph
Политтехнологи научились проникать в мозг
Чтобы победить в выборах, политики используют все доступные средства, в том числе и новые технологии. Социологическими опросами или анализом постов в соцсетях сейчас никого не удивишь. Могут ли политехнологи пойти дальше и «заглянуть» в мозг, чтобы понять…
Мы уже ранее затрагивали тему переноса стиля с одного изображения на другое. Но что если попытаться развернуть этот процесс вспять и заглянуть в черный ящик? Что скрывают скрытые слои нейросети? Вам и не снилось...
https://telegra.ph/Koshmarnye-sny-nejrosetej-09-30
https://telegra.ph/Koshmarnye-sny-nejrosetej-09-30
Telegraph
Кошмарные сны нейросетей
Нейросети ворвались в искусство в 2015 году. Начало положили две прорывные статьи. В одной инженеры представили нейросеть, которая воспроизводит свои «воспоминания», возникшие на этапе обучения, на новых изображениях. Получается что-то вроде сна — и порой…
Наверное, всем знакома ситуация, когда при попытке сделать групповое фото из миллиона дублей не получается ни один -- кто-нибудь обязательно закроет глаза! Или когда вы просите вас сфотографировать, а потом обнаруживаете, что моргнули -- и все, кадр потерян! Но, кажется, скоро искусственный интеллект избавит нас от расстройств из-за неудавшихся фотографий.
https://telegra.ph/Podnimite-mne-veki-09-23
https://telegra.ph/Podnimite-mne-veki-09-23
Telegraph
Поднимите мне веки
Сделать хорошую фотографию непросто. Множество неприятных мелочей может испортить снимок: от плохого освещения до неудачного ракурса. Если человек не вовремя моргнул, фото можно считать неудавшимся. Facebook Research работает над алгоритмом для замены неудачно…
В "Толковом словаре живого великорусского языка" В.И. Даля 200 тысяч слов. В "Большом академическом словаре" -- 150 тысяч. В "Малом академическом словаре" -- 90 тысяч. В "Словаре языка Пушкина" -- 21 тысяча. А сколько слов в вашем арсенале?
Чтобы проверить это, вовсе не нужно открывать Даля или БАС и отмечать все знакомые слова: хитрому алгоритму нужно всего лишь 15-20 вопросов, чтобы оценить ваш словарный запас. А заодно то, насколько честно вы отвечали. 😏
https://telegra.ph/Defenestraciya-Ne-ne-slyshal-09-23
Чтобы проверить это, вовсе не нужно открывать Даля или БАС и отмечать все знакомые слова: хитрому алгоритму нужно всего лишь 15-20 вопросов, чтобы оценить ваш словарный запас. А заодно то, насколько честно вы отвечали. 😏
https://telegra.ph/Defenestraciya-Ne-ne-slyshal-09-23
Telegraph
Дефенестрация? Не, не слышал!
Уже несколько лет люди охотно делятся в соцсетях результатами теста своего словарного запаса. Выглядит это так: Ваш пассивный словарный запас — 88000 слов. Ваш индекс честности — 90%. Предлагаем заглянуть под капот этого теста и посмотреть какие технологии…
Задумывались ли вы о том, какие города и страны чаще всего упоминаются в стихах русских поэтов? А вот исследователи Борис Орехов и Елизавета Кузьменко задумались — и проанализировали поэтический корпус размером в 11 миллионов слов. Где жили лирические герои на протяжении трех веков? Как путешествовали? Куда устремлялись в мечтах? Оказывается, наиболее значимые места на поэтической карте можно определить с помощью нехитрых подсчетов.
https://telegra.ph/ZHit-i-umeret-v-Parizhe-300-let-russkoj-poehzii-na-karte-09-01
https://telegra.ph/ZHit-i-umeret-v-Parizhe-300-let-russkoj-poehzii-na-karte-09-01
Telegraph
«Жить и умереть в Париже»: 300 лет русской поэзии на карте
Исследование проводилось на поэтическом подкорпусе Национального корпуса русского языка. Он содержит тексты русских поэтов, написанные в XVIII — XXI веках. Авторы исследования выделили в текстах упоминания стран и городов, вычислили те, что встречаются чаще…
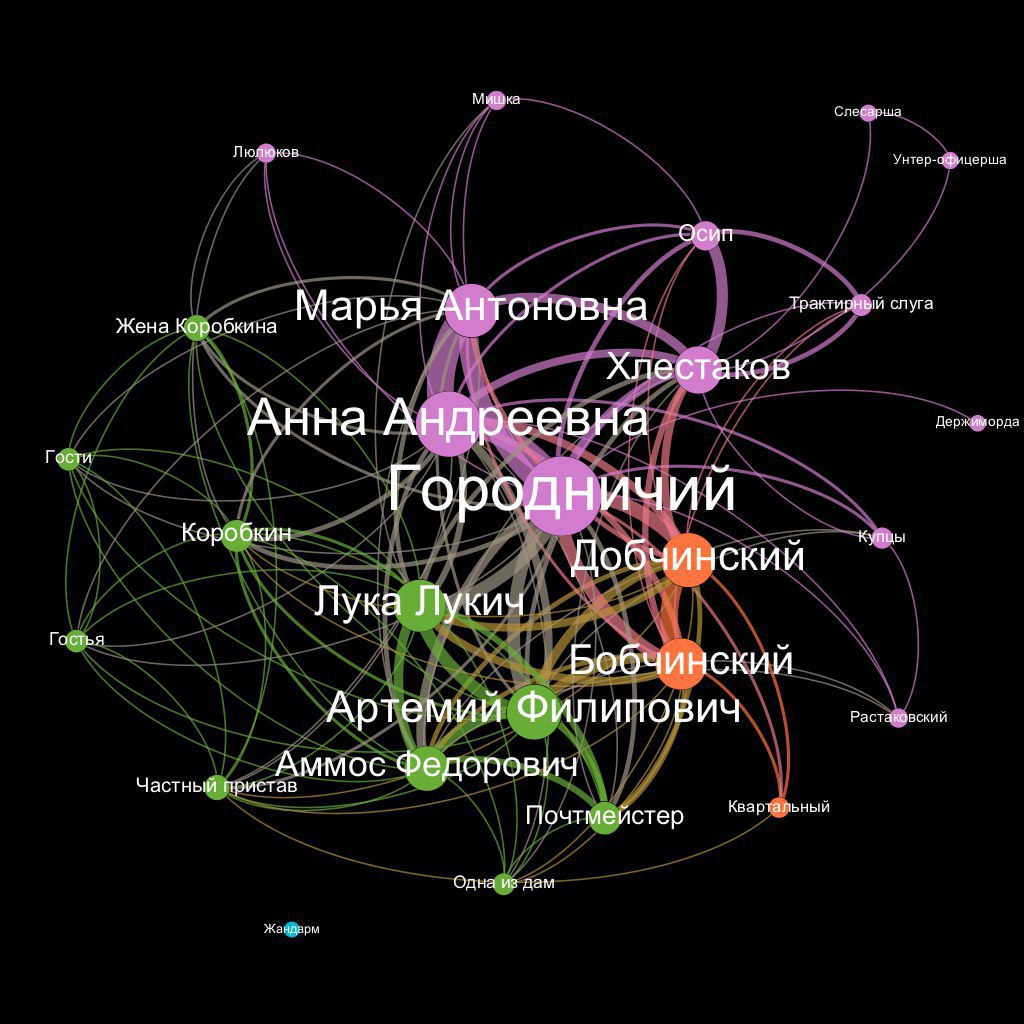
Сегодня мы продолжим разговор о цифровом литературоведении и обратимся к сетевому анализу, или анализу социальных графов. Но граф — это что-то страшное из математики, а социальные сети — это Вконтакте и Facebook! При чем здесь литературоведение?
Социальные сети бывают не только реальные, но и вымышленные. Например, не так уж сложно себе представить фейсбук Евгения Онегина: как он сначала френдит весь петербургский «свет», потом всех удаляет, потом ставит лайки Ольге Лариной, а сам тем временем разглядывает фото в профиле Татьяны. Тут Ленский ставит «Возмутительно», пишет злой коммент — и заверте...
Изучать соцсети художественных персонажей можно теми же способами, что и реальные. Социологи давно применяют теорию графов и методы анализа сетей, чтобы выделять сообщества, находить в них «центры влияния» и лидеров мнений, анализировать пути распространения информации и власти. С недавних пор тем же занялись и литературоведы — и это уже дало много интересных результатов. Например, известный «цифровой литературовед» Франко Моретти нашел зону смерти в социальной сети «Гамлета»: там умирают только те, кто одновременно тесно связан с самим Гамлетом и с его злодеем-дядей, королем Клавдием. Этот факт можно было вывести и без сетевого анализа, но он не приходил в голову никому до тех пор, пока сеть диалогов персонажей «Гамлета» не была построена и визуализирована.
На русском материале интересные результаты дал анализ произведений А. С. Пушкина и Л. Н. Толстого. Например, в «Войне и мире» структура сетей совпадает с сюжетной динамикой: они плотные в мирное время, разрозненные в военное; Ростовы образуют плотное сообщество, а Курагины (о которых литературоведы давно пишут, что они «лишены семейной поэзии»), никакого сообщества не образуют. А в пушкинском «Борисе Годунове» удалось выявить особого персонажа-посланника, который — и это явно не совпадение — носит фамилию автора. Гаврилу Пушкина никто не назовет главным героем, но сетевые метрики показывают, что он самый главный «промежуточный» персонаж, через которого проходит коммуникация. И это правда так. Сейчас та же команда «цифровых филологов» из НИУ ВШЭ ведет уже автоматический поиск похожих персонажей (агентов, посланников, шпионов) в других пьесах при помощи сетевого анализа — и кое-что уже нашла. Об этом в следующих выпусках.
Социальные сети бывают не только реальные, но и вымышленные. Например, не так уж сложно себе представить фейсбук Евгения Онегина: как он сначала френдит весь петербургский «свет», потом всех удаляет, потом ставит лайки Ольге Лариной, а сам тем временем разглядывает фото в профиле Татьяны. Тут Ленский ставит «Возмутительно», пишет злой коммент — и заверте...
Изучать соцсети художественных персонажей можно теми же способами, что и реальные. Социологи давно применяют теорию графов и методы анализа сетей, чтобы выделять сообщества, находить в них «центры влияния» и лидеров мнений, анализировать пути распространения информации и власти. С недавних пор тем же занялись и литературоведы — и это уже дало много интересных результатов. Например, известный «цифровой литературовед» Франко Моретти нашел зону смерти в социальной сети «Гамлета»: там умирают только те, кто одновременно тесно связан с самим Гамлетом и с его злодеем-дядей, королем Клавдием. Этот факт можно было вывести и без сетевого анализа, но он не приходил в голову никому до тех пор, пока сеть диалогов персонажей «Гамлета» не была построена и визуализирована.
На русском материале интересные результаты дал анализ произведений А. С. Пушкина и Л. Н. Толстого. Например, в «Войне и мире» структура сетей совпадает с сюжетной динамикой: они плотные в мирное время, разрозненные в военное; Ростовы образуют плотное сообщество, а Курагины (о которых литературоведы давно пишут, что они «лишены семейной поэзии»), никакого сообщества не образуют. А в пушкинском «Борисе Годунове» удалось выявить особого персонажа-посланника, который — и это явно не совпадение — носит фамилию автора. Гаврилу Пушкина никто не назовет главным героем, но сетевые метрики показывают, что он самый главный «промежуточный» персонаж, через которого проходит коммуникация. И это правда так. Сейчас та же команда «цифровых филологов» из НИУ ВШЭ ведет уже автоматический поиск похожих персонажей (агентов, посланников, шпионов) в других пьесах при помощи сетевого анализа — и кое-что уже нашла. Об этом в следующих выпусках.
{kind=link}
Что читать современному лингвисту/филологу?
Телеграм стал площадкой для нишевых сообществ с уникальным контентом. Мы будем рассказывать о каналах, которые читаем сами. В нашем первом обзоре — четыре канала о лингвистике, четыре канала о литературе и два — о цифровых гуманитарных исследованиях.
— @linguistique_sur_un_genou — Лингвистика на коленке
"Лингвист-дилетант" Ксения пишет, в основном, о компьютерной лингвистике и романских языках. Но здесь не только обзоры лучших курсов по NLP и интересные лингвистические факты, здесь ещё и истории из жизни о собеседованиях на иностранном языке, переводах и французском лингвистическом быте.
— @linguisticmadness — Linguistic Madness
Канал о лингвистике и языках: ссылки, статьи, мнения, факты. Что если переделать "Иронию судьбы" на бандитский манер? Как выглядят граффити для незрячих? Что такое ирландский перфект в английском? Кто говорит на аэрском? И прочие лингвистические безумства.
— @vooiox — уЩербы
Увлекательные рассказы о том, откуда взялось слово "чувак", что такое гражданский брак и можно ли говорить звОнит. В общем, вся правда о русском языке, которую скрывали от нас в школе.
— @word4power — Word4Power
Канал убежденного последователя святого Иеронима о переводах и лингвистике. Будни синхрониста, полезные переводчику книжки и статьи, лингвистические откровения о русском, украинском, английском и французском. Где еще вы узнаете, как делаются субтитры к фильмам и театральным постановкам и в чем разница между Yob's comma и Oxford comma?
— @theodstavec — О литературе и около неё
Команда этого проекта, название которого в переводе с чешского означает "абзац", делает переводы статей, эссе, рецензий и заметок мировых ресурсов о литературе, чтобы они стали доступнее русскоязычному читателю. А ещё там можно опубликовать свою литературоведческую статью.
— @bookngrill — Книги жарь
Канал студента первой магистратуры Creative Writing в России. Новости современной литературы, советы начинающим писателям, литературоведческий ликбез и просто образец хорошего текста.
— @sashaandleo — Саша и Лев
Дайджест литературных новостей со всего мира — о книжных фестивалях, экранизациях, встречах с писателями, литературных премиях.
— @words_and_money — Слова и деньги
Про книги из электронов и из бумаги, деньги из книг, книги без денег и всякое прочее. Издательства, книжные ярмарки, нелитературная сторона мира литературы. По мотивам «Слов и денег» Андре Шиффрина.
— @Sense_catcher — Библиотечная крыса
Авторский канал о книгах и чтении в цифровую эпоху, "чердак цифрового литературоведа". Здесь и рассуждения о судьбах литературы и ее исследователей, и размышления о современном книгоиздании, и личные впечаления от выездных школ и курсов по Digital Humanities, и рассказы об интересных проектах в современной филологии.
— @sysblok — Системный Блокъ
Канал о переходе культуры в цифру и применении технологий в гуманитарных науках и искусстве. Как лингвисты ловят маньяков и какие сны снятся нейросетям? Что скрывают от нас соцсети персонажей? Может ли искусственный интеллект залипнуть у телевизора? Системный Блокъ — это современный Вергилий, который проведет вас через девять кругов Big Data.
Хотите рассказать нам о своем любимом сообществе? Мы уже собираем продолжение. Пишите.
Телеграм стал площадкой для нишевых сообществ с уникальным контентом. Мы будем рассказывать о каналах, которые читаем сами. В нашем первом обзоре — четыре канала о лингвистике, четыре канала о литературе и два — о цифровых гуманитарных исследованиях.
— @linguistique_sur_un_genou — Лингвистика на коленке
"Лингвист-дилетант" Ксения пишет, в основном, о компьютерной лингвистике и романских языках. Но здесь не только обзоры лучших курсов по NLP и интересные лингвистические факты, здесь ещё и истории из жизни о собеседованиях на иностранном языке, переводах и французском лингвистическом быте.
— @linguisticmadness — Linguistic Madness
Канал о лингвистике и языках: ссылки, статьи, мнения, факты. Что если переделать "Иронию судьбы" на бандитский манер? Как выглядят граффити для незрячих? Что такое ирландский перфект в английском? Кто говорит на аэрском? И прочие лингвистические безумства.
— @vooiox — уЩербы
Увлекательные рассказы о том, откуда взялось слово "чувак", что такое гражданский брак и можно ли говорить звОнит. В общем, вся правда о русском языке, которую скрывали от нас в школе.
— @word4power — Word4Power
Канал убежденного последователя святого Иеронима о переводах и лингвистике. Будни синхрониста, полезные переводчику книжки и статьи, лингвистические откровения о русском, украинском, английском и французском. Где еще вы узнаете, как делаются субтитры к фильмам и театральным постановкам и в чем разница между Yob's comma и Oxford comma?
— @theodstavec — О литературе и около неё
Команда этого проекта, название которого в переводе с чешского означает "абзац", делает переводы статей, эссе, рецензий и заметок мировых ресурсов о литературе, чтобы они стали доступнее русскоязычному читателю. А ещё там можно опубликовать свою литературоведческую статью.
— @bookngrill — Книги жарь
Канал студента первой магистратуры Creative Writing в России. Новости современной литературы, советы начинающим писателям, литературоведческий ликбез и просто образец хорошего текста.
— @sashaandleo — Саша и Лев
Дайджест литературных новостей со всего мира — о книжных фестивалях, экранизациях, встречах с писателями, литературных премиях.
— @words_and_money — Слова и деньги
Про книги из электронов и из бумаги, деньги из книг, книги без денег и всякое прочее. Издательства, книжные ярмарки, нелитературная сторона мира литературы. По мотивам «Слов и денег» Андре Шиффрина.
— @Sense_catcher — Библиотечная крыса
Авторский канал о книгах и чтении в цифровую эпоху, "чердак цифрового литературоведа". Здесь и рассуждения о судьбах литературы и ее исследователей, и размышления о современном книгоиздании, и личные впечаления от выездных школ и курсов по Digital Humanities, и рассказы об интересных проектах в современной филологии.
— @sysblok — Системный Блокъ
Канал о переходе культуры в цифру и применении технологий в гуманитарных науках и искусстве. Как лингвисты ловят маньяков и какие сны снятся нейросетям? Что скрывают от нас соцсети персонажей? Может ли искусственный интеллект залипнуть у телевизора? Системный Блокъ — это современный Вергилий, который проведет вас через девять кругов Big Data.
Хотите рассказать нам о своем любимом сообществе? Мы уже собираем продолжение. Пишите.
В одном из прошлых постов мы рассказывали, что такое сетевой анализ литературных произведений. Но как применить это в исследованиях? Цифровые филологи из Германии знают ответ! Оказывается, комедии и трагедии отличаются по структуре социальной сети геров, так что можно определить жанр произведения, просто взглянув на граф.
https://telegra.ph/Drama-v-seti-09-01
https://telegra.ph/Drama-v-seti-09-01
Telegraph
Праздник или смерть? Драма в сети!
Мы уже писали о том, как анализ социальных сетей (социальных графов) персонажей произведения помогает филологам в исследованиях. Сеть общения героев — своеобразный скелет текста, в котором можно увидеть неявные структурные особенности, героев-«проводников»…
Как вы думаете, что скрывается за загадочным термином "N-граммы"? Программы? Нет, все не так уж страшно. N-граммы — это такие хитрые последовательности звуков, слогов, слов или букв и они очень важны для компьютерной лингвистики. В этой статье мы расскажем, как они устроены и чем помогают при автоматической обработке текста.
https://telegra.ph/N-grammy-09-01
https://telegra.ph/N-grammy-09-01
Telegraph
Что такое N-граммы и с чем их едят?
N-грамма — это просто последовательность из n элементов (звуков, слогов, слов или букв). На практике чаще имеют в виду ряд слов (реже — букв). Последовательность из двух последовательных элементов называют биграмма, из трёх элементов — триграмма. Например…
За несколько тысяч лет нарратив претерпел значительные изменения, эволюционировав от устной истории до ветвящихся сценариев компьютерных игр через стадии классического романа и постмодернистского текста-калейдоскопа.
Впрочем, цифровой нарратив не ограничивается компьютерными играми – это любой интерактивный мультисенсорный текст, который нельзя превратить в печатную версию без существенных потерь. Итак, в сегодняшней статье мы рассказываем об особенностях и формах цифрового нарратива.
https://telegra.ph/Multinarrativ-programmiruemaya-istoriya-10-21
Впрочем, цифровой нарратив не ограничивается компьютерными играми – это любой интерактивный мультисенсорный текст, который нельзя превратить в печатную версию без существенных потерь. Итак, в сегодняшней статье мы рассказываем об особенностях и формах цифрового нарратива.
https://telegra.ph/Multinarrativ-programmiruemaya-istoriya-10-21
Telegraph
Мультинарратив: программируемая история
Долгое время люди рассказывали друг другу истории только устно. Поскольку память имеет ограниченный ресурс, эти истории обычно звучали в разных вариациях. С появлением письменности сюжеты историй оказались «заморожены» — и стали четко определенными последовательностями…
Сегодня у Соловецкого камня в Москве читают имена жертв репрессий. Но можем ли мы действительно назвать всех? Имена жертв — и имена палачей? Ко Дню памяти жертв репрессий — рассказ о базах данных «Международного Мемориала» @toposmemoru.
https://telegra.ph/Bolshie-dannye-Bolshogo-terrora-10-28
https://telegra.ph/Bolshie-dannye-Bolshogo-terrora-10-28
Telegraph
Большие данные Большого террора
Жертвами советского государственного террора стали миллионы людей. От тех, кто погребен в расстрельных рвах Бутовского полигона и «Коммунарки», надорвался на Беломорканале или замерз на рудниках Колымы, не осталось почти ничего. Но репрессивная машина не…
Нейросеть научилась диагностировать депрессию
Исследователи из Массачуссетского технологического института (MIT) разработали алгоритм диагностики депрессии на основе нейросети. Модель ставит диагноз по аудиозаписям и текстовыми расшифровкам интервью с пациентами, обнаруживая в речи специфические «депрессивные паттерны».
Ранее машинное обучение уже применялось для помощи психологам в диагностике. Однако прежде алгоритмы оценивали конкретные ответы на конкретные вопросы, что накладывало сильные ограничения на применимость. Новый алгоритм позволяет анализировать произвольные разговоры пациента.
Исследователи надеются, что в будущем их разработка может быть встроена в мобильные приложения, которые следят за здоровьем. Тогда первые признаки депрессии можно будет отловить задолго до того, как человек соберется ко врачу или в форточку.
Подробнее узнать о нейросети-психологе можно тут.
#neuroscience #sysblok
Исследователи из Массачуссетского технологического института (MIT) разработали алгоритм диагностики депрессии на основе нейросети. Модель ставит диагноз по аудиозаписям и текстовыми расшифровкам интервью с пациентами, обнаруживая в речи специфические «депрессивные паттерны».
Ранее машинное обучение уже применялось для помощи психологам в диагностике. Однако прежде алгоритмы оценивали конкретные ответы на конкретные вопросы, что накладывало сильные ограничения на применимость. Новый алгоритм позволяет анализировать произвольные разговоры пациента.
Исследователи надеются, что в будущем их разработка может быть встроена в мобильные приложения, которые следят за здоровьем. Тогда первые признаки депрессии можно будет отловить задолго до того, как человек соберется ко врачу или в форточку.
Подробнее узнать о нейросети-психологе можно тут.
#neuroscience #sysblok
{kind=link}
В последнее время тема искусственного интеллекта стала очень популярной. Сложно поверить, но его история началась почти 100 лет назад! За это время он прошел немало эволюционных этапов, от идеи «Россумских универсальных роботов» Карела Чапека до самообучающихся нейросетей.
Сегодня мы поговорим о юности и двух «зимах» искуственного интеллекта, об изобретении теста Тьюринга и об экспертных системах.
https://telegra.ph/Kratkaya-istoriya-iskusstvennogo-intellekta-chast-I-11-05
Сегодня мы поговорим о юности и двух «зимах» искуственного интеллекта, об изобретении теста Тьюринга и об экспертных системах.
https://telegra.ph/Kratkaya-istoriya-iskusstvennogo-intellekta-chast-I-11-05
Telegraph
Краткая история искусственного интеллекта (часть I)
Предисловие В последнее время тема искусственного интеллекта стала очень популярной. Но что такое ИИ на самом деле? Каких результатов он уже достиг и в каком направлении будет развиваться в будущем? Вокруг этой темы ведется много споров. Сначала неплохо выяснить…
Вчера мы писали о ранних этапах эволюции искусственного интеллекта, а теперь обратимся к современности и посмотрим, что такое Deep Blue и Deep Mind, каких результатов достиг искусственный интеллект в XXI веке и в каком направлении он будет развиваться в будущем.
https://telegra.ph/Kratkaya-istoriya-iskusstvennogo-intellekta-chast-II-11-05
https://telegra.ph/Kratkaya-istoriya-iskusstvennogo-intellekta-chast-II-11-05
Telegraph
Краткая история искусственного интеллекта (часть II)
В предыдущей части мы рассказали, как зарождались идеи ИИ, а теперь обратимся к современности. Deep Blue После долгих лет взлетов и падений произошло значимое событие для ИИ: 11 мая 1997 года шахматный суперкомпьютер Deep Blue, разработанный компанией IBM…
В двух предыдущих статьях мы рассказывали об истории искусственного интеллекта, а теперь перейдём непосредственно к нейронным сетям — первой технологии, которая действительно напоминает интеллект.
Нейросети порождают никогда до этого не существовавшие слова и тексты, пишут картины, успешно управляют беспилотными машинами в незнакомой местности, распознают объекты на снимках гораздо точнее человека, а также видят в данных сложные закономерности.
Как устроены эти алгоритмы? Что такое искусственные нейроны и чем они отличаются от настоящих? И кто же все-таки победит: мозг или компьютер?
#knowhow #sysblok
https://telegra.ph/Mozg-protiv-kompyutera-11-05
Нейросети порождают никогда до этого не существовавшие слова и тексты, пишут картины, успешно управляют беспилотными машинами в незнакомой местности, распознают объекты на снимках гораздо точнее человека, а также видят в данных сложные закономерности.
Как устроены эти алгоритмы? Что такое искусственные нейроны и чем они отличаются от настоящих? И кто же все-таки победит: мозг или компьютер?
#knowhow #sysblok
https://telegra.ph/Mozg-protiv-kompyutera-11-05
Telegraph
Мозг против компьютера
Нейронные сети — первая искусственная технология, которая действительно напоминает интеллект. Нейросети порождают никогда до этого не существовавшие слова и тексты, пишут картины, успешно управляют беспилотными машинами в незнакомой местности, распознают…