
Проект OneSoil Map: как нейросеть помогает сельскому хозяйству
#visualisation
Про Никиту Хрущева шутили, что он запустил не только спутник, но и сельское хозяйство… Но с появлением искусственного интеллекта эти две сферы подружились: теперь спутниковые технологии работают на успех аграрного производства. Разбираемся, как искусственный интеллект и снимки из космоса помогают выбрать плодородное поле для посадки картошки.
Многие наверняка слышали о роли технологий в сельском хозяйстве. Это и альтернативные источники энергии, и генно-модифицированные организмы, и беспилотные машины для уборки урожая. С каждым десятилетием хозяйство вести все легче. У использования новых технологий в сельском хозяйстве есть название: точное (или «прецизионное», от англ. precision) земледелие.
Точное земледелие позволят эффективнее расходовать семена и удобрения, чтобы получать богатый урожай. Среди ресурсов, относящихся к точному земледелию, — проект OneSoil Map. Это карта всех полей Европы и США за три года, на которой видно, кто где что сажает и как и где развивается сельское хозяйство.
Карта — интерактивная, и работает на алгоритмах искусственного интеллекта и спутниковых снимках. Она располагает информацией о 60 миллионах полей и 27 культурах в 44 странах мира. Этот инструмент помогает фермерам, инвесторам и правительству в оптимизации отрасли сельского хозяйства.
Функционал OneSoil Map
При разработке сервиса OneSoil Map использовались снимки спутника Sentinel-2. Данные со спутника представляют собой около 250 терабайт информации о полях США и Европы. Спутниковые фотографии обработали следующим образом:
1. Сделали препроцессинг снимков: почистили облака, тени и снег. После этого этапа объем данных сократился до 50 терабайт.
2. Нашли границы полей, создали классификаторы для разных полей. Итог этого этапа — 250 гигабайт данных, содержащих векторные карты полей с сельскохозяйственными культурами.
3. Вычислили статистику, рейтинг и популярность разных культур в странах мира.
4. Для улучшения алгоритмов предоставили пользователям возможность уведомлять разработчиков о различных ошибках на картах.
При создании карт применялись два подхода. Во-первых, создали растровую карту: поделили карту на квадраты и выполнили последующий рендер в картинки. Браузер подгружает несколько картинок, а когда пользователь перемещается по карте — двигает их. Из плюсов — все поля отображаются без фильтрации, из минусов — растровые изображения довольно долго загружаются из-за большого объема файлов.
Во-вторых, создали векторную карту: анимировали векторные данные в браузере, как в картах Google и Yandeх. Из плюсов — можно использовать файлы меньшего объема, а также кастомизировать способ отображения данных.
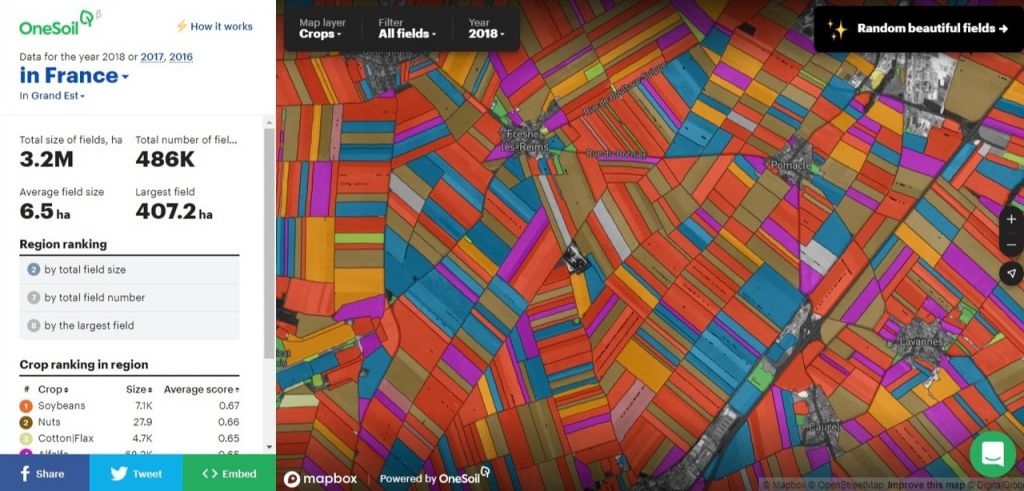
Визуальная часть проекта также тщательно продумана. Для визуализации использовался сервис Mapbox. Для популярных культур выбрали контрастные цвета, для остальных — наименее контрастные. А чтобы привлечь к сервису внимание не только узких специалистов, разработали кнопку «рандомные красивые поля». Например, ниже прикреплена карта полей одного из регионов Франции.
В итоге разработчики стали первыми людьми, кто нанес на карту все поля США и Европы за три года, что не могло не привлечь внимание инвесторов, научных исследователей и фондов. Проект планируют развивать и дальше: цель на ближайшее будущее — автоматически распознавать поля и в остальных странах. Разработчики карты ведут блог, в котором пишут о мониторинге полей, экспериментах, больших данных и историях фермеров.
Колобов Денис
https://sysblok.ru/visual/kak-nejroset-sazhaet-kartoshku-iz-kosmosa/
#visualisation
Про Никиту Хрущева шутили, что он запустил не только спутник, но и сельское хозяйство… Но с появлением искусственного интеллекта эти две сферы подружились: теперь спутниковые технологии работают на успех аграрного производства. Разбираемся, как искусственный интеллект и снимки из космоса помогают выбрать плодородное поле для посадки картошки.
Многие наверняка слышали о роли технологий в сельском хозяйстве. Это и альтернативные источники энергии, и генно-модифицированные организмы, и беспилотные машины для уборки урожая. С каждым десятилетием хозяйство вести все легче. У использования новых технологий в сельском хозяйстве есть название: точное (или «прецизионное», от англ. precision) земледелие.
Точное земледелие позволят эффективнее расходовать семена и удобрения, чтобы получать богатый урожай. Среди ресурсов, относящихся к точному земледелию, — проект OneSoil Map. Это карта всех полей Европы и США за три года, на которой видно, кто где что сажает и как и где развивается сельское хозяйство.
Карта — интерактивная, и работает на алгоритмах искусственного интеллекта и спутниковых снимках. Она располагает информацией о 60 миллионах полей и 27 культурах в 44 странах мира. Этот инструмент помогает фермерам, инвесторам и правительству в оптимизации отрасли сельского хозяйства.
Функционал OneSoil Map
При разработке сервиса OneSoil Map использовались снимки спутника Sentinel-2. Данные со спутника представляют собой около 250 терабайт информации о полях США и Европы. Спутниковые фотографии обработали следующим образом:
1. Сделали препроцессинг снимков: почистили облака, тени и снег. После этого этапа объем данных сократился до 50 терабайт.
2. Нашли границы полей, создали классификаторы для разных полей. Итог этого этапа — 250 гигабайт данных, содержащих векторные карты полей с сельскохозяйственными культурами.
3. Вычислили статистику, рейтинг и популярность разных культур в странах мира.
4. Для улучшения алгоритмов предоставили пользователям возможность уведомлять разработчиков о различных ошибках на картах.
При создании карт применялись два подхода. Во-первых, создали растровую карту: поделили карту на квадраты и выполнили последующий рендер в картинки. Браузер подгружает несколько картинок, а когда пользователь перемещается по карте — двигает их. Из плюсов — все поля отображаются без фильтрации, из минусов — растровые изображения довольно долго загружаются из-за большого объема файлов.
Во-вторых, создали векторную карту: анимировали векторные данные в браузере, как в картах Google и Yandeх. Из плюсов — можно использовать файлы меньшего объема, а также кастомизировать способ отображения данных.
Визуальная часть проекта также тщательно продумана. Для визуализации использовался сервис Mapbox. Для популярных культур выбрали контрастные цвета, для остальных — наименее контрастные. А чтобы привлечь к сервису внимание не только узких специалистов, разработали кнопку «рандомные красивые поля». Например, ниже прикреплена карта полей одного из регионов Франции.
В итоге разработчики стали первыми людьми, кто нанес на карту все поля США и Европы за три года, что не могло не привлечь внимание инвесторов, научных исследователей и фондов. Проект планируют развивать и дальше: цель на ближайшее будущее — автоматически распознавать поля и в остальных странах. Разработчики карты ведут блог, в котором пишут о мониторинге полей, экспериментах, больших данных и историях фермеров.
Колобов Денис
https://sysblok.ru/visual/kak-nejroset-sazhaet-kartoshku-iz-kosmosa/
{kind=link}
Как вычислить эмоции компьютерными методами
Рассказываем на примере анализа песен группы Битлз.
#philology
В 1996 году психолог Синтия Уиссел опубликовала статью, в которой сравнила между собой песни Пола МакКартни и Джона Леннона при помощи методов традиционной и эмоциональной стилометрии. В статье Уиссел пытается ответить на два вопроса:
1. Действительно ли песни Джона грустнее песен Пола?
2. Как менялась эмоциональная составляющая песен Битлз на протяжении четырех стадий их творчества (1962–1964, 1965–1966, 1967–1968, 1969–1970)?
Методы стилометрического анализа
Стилометрия часто использует измерения слова в качестве минимальной единицы. Из слова можно получить множество качеств для изучения текста: длину, частотность и др. Нас интересует коннотация. Коннотации каждого слова вычисляются разными способами опрашивания информантов. Затем результаты документируются в словарях эмоций (Dictionary of Affect). Один из таких словарей Уиссел сама и составила.
Измеряют коннотацию по трем шкалам: оценка, сила и активность. Вместе эти факторы описывают эмоцию человека по отношению к тому, что это слово обозначает, и их достаточно для дифференцирования значений большинства слов. У каждой шкалы две крайности: у оценки это «плохой» и «хороший», у силы — «сильный» и «слабый», а у активности — «активный» и «неактивный».
Для стилометрического исследования не обязательно рассматривать все три шкалы. В статье Уиссел рассматривает только оценку и активность, используя значения из своего словаря. Каждому слову в словаре даны значения на двух семибалльных шкалах: оценки и активности. К примеру, слово delighted ‘восхищенный’ имеет значения 6.4 (оценка) и 4.2 (активность), а gloomy ‘угрюмый’ — 3.2 (оценка) и 2.4 (активность).
Анализ текстов песен группы Битлз
Уиссел посчитала, какой процент наиболее «приятных» и наиболее «активных» слов (в топ 25% по оценке и активности соответственно) присутствует в их песнях на протяжении четырех периодов их творчества. Кроме того, она сконструировала из этих двух шкал еще четыре и тоже их подсчитала:
1. «Радостность» (Cheerfulness) — наиболее приятные и наиболее активные
2. «Гадкость» (Nastiness) — наименее приятные и наиболее активные
3. «Мягкость» (Softness) — наиболее приятные и наименее активные
4. «Грустность» (Sadness) — наименее приятные и наименее активные
Оказалось, что МакКартни использовал на 2% больше «приятных» слов, чем Леннон, который использовал больше «гадких», «мягких» и «грустных» слов.
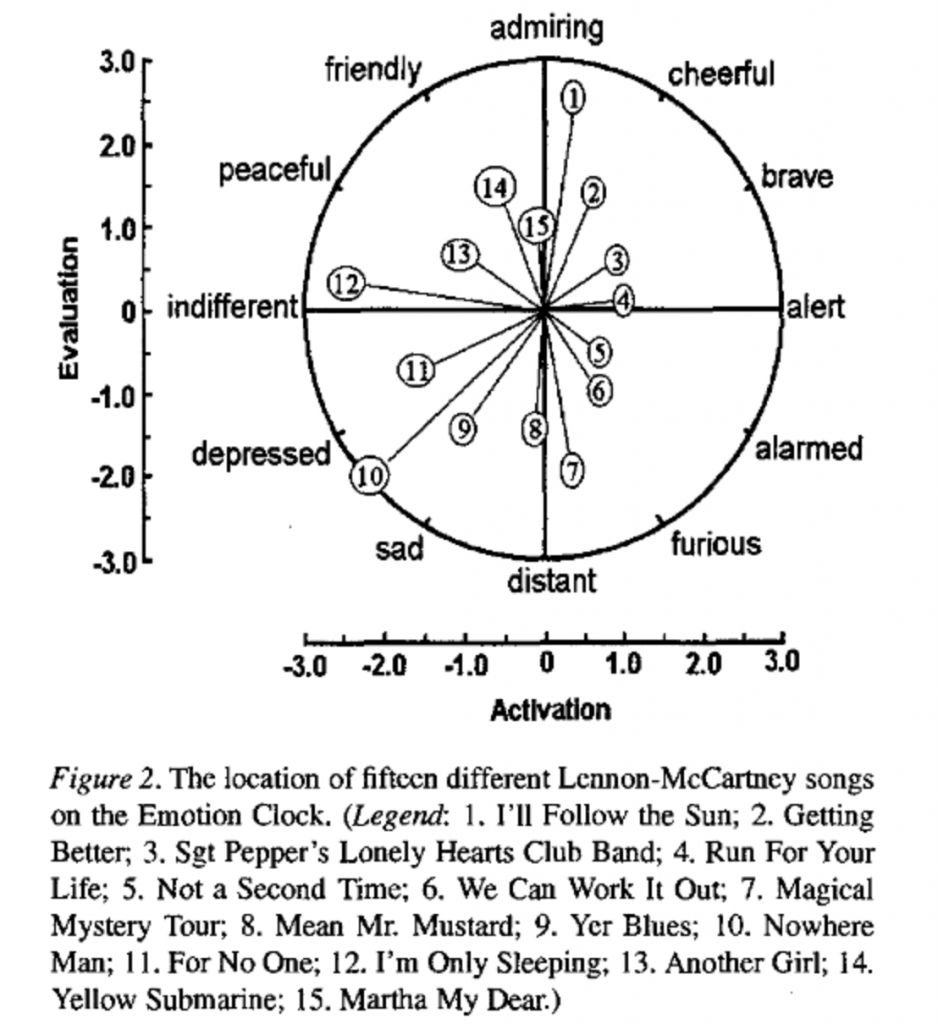
Часы эмоций
Для наглядной демонстрации результатов своих исследований Уиссел использовала т.н. часы эмоций. Схема прикреплена ниже.
Это пространство с двумя осями — оценки и активности. Значения, которые проставляются в этой системе координат, не абсолютные: они нормализованы относительно корпуса из около 50 текстов, включающих в себя художественную литературу, эссе студентов, описания людьми собственных эмоций.
Чем интенсивнее эмоции в тексте, тем вектор (т. е. расстояние от центра до точки, обозначающей текст) будет длиннее, а в зависимости от угла, который образует этот вектор, меняется и общее настроение текста. Для этого и нужна окружность, на которой обозначены различные эмоции.
В среднем все песни Битлз оказываются более «радостными», чем подобранный корпус. А по отдельности песни по-разному располагаются на часах: самой «депрессивной» оказывается песня Джона Леннона «Nowhere Man», самой «приятной» — песня Пола Маккартни «I’ll Follow the Sun».
Сложно понять, насколько эти данные достоверны. Однако интересно, что субъективное мнение критиков, что песни Джона более грустные, как будто подтверждается методами эмоциональной стилометрии. Если два разных подхода к анализу текстов приходят к одному выводу, оба подхода становятся легитимнее, и поэтому, возможно, у эмоциональной стилометрии есть право на существование.
Миша Сонькин
https://sysblok.ru/philology/kak-menjalis-pesni-bitlov-i-mozhno-li-vychislit-jemocii-kompjuternymi-metodami/
Рассказываем на примере анализа песен группы Битлз.
#philology
В 1996 году психолог Синтия Уиссел опубликовала статью, в которой сравнила между собой песни Пола МакКартни и Джона Леннона при помощи методов традиционной и эмоциональной стилометрии. В статье Уиссел пытается ответить на два вопроса:
1. Действительно ли песни Джона грустнее песен Пола?
2. Как менялась эмоциональная составляющая песен Битлз на протяжении четырех стадий их творчества (1962–1964, 1965–1966, 1967–1968, 1969–1970)?
Методы стилометрического анализа
Стилометрия часто использует измерения слова в качестве минимальной единицы. Из слова можно получить множество качеств для изучения текста: длину, частотность и др. Нас интересует коннотация. Коннотации каждого слова вычисляются разными способами опрашивания информантов. Затем результаты документируются в словарях эмоций (Dictionary of Affect). Один из таких словарей Уиссел сама и составила.
Измеряют коннотацию по трем шкалам: оценка, сила и активность. Вместе эти факторы описывают эмоцию человека по отношению к тому, что это слово обозначает, и их достаточно для дифференцирования значений большинства слов. У каждой шкалы две крайности: у оценки это «плохой» и «хороший», у силы — «сильный» и «слабый», а у активности — «активный» и «неактивный».
Для стилометрического исследования не обязательно рассматривать все три шкалы. В статье Уиссел рассматривает только оценку и активность, используя значения из своего словаря. Каждому слову в словаре даны значения на двух семибалльных шкалах: оценки и активности. К примеру, слово delighted ‘восхищенный’ имеет значения 6.4 (оценка) и 4.2 (активность), а gloomy ‘угрюмый’ — 3.2 (оценка) и 2.4 (активность).
Анализ текстов песен группы Битлз
Уиссел посчитала, какой процент наиболее «приятных» и наиболее «активных» слов (в топ 25% по оценке и активности соответственно) присутствует в их песнях на протяжении четырех периодов их творчества. Кроме того, она сконструировала из этих двух шкал еще четыре и тоже их подсчитала:
1. «Радостность» (Cheerfulness) — наиболее приятные и наиболее активные
2. «Гадкость» (Nastiness) — наименее приятные и наиболее активные
3. «Мягкость» (Softness) — наиболее приятные и наименее активные
4. «Грустность» (Sadness) — наименее приятные и наименее активные
Оказалось, что МакКартни использовал на 2% больше «приятных» слов, чем Леннон, который использовал больше «гадких», «мягких» и «грустных» слов.
Часы эмоций
Для наглядной демонстрации результатов своих исследований Уиссел использовала т.н. часы эмоций. Схема прикреплена ниже.
Это пространство с двумя осями — оценки и активности. Значения, которые проставляются в этой системе координат, не абсолютные: они нормализованы относительно корпуса из около 50 текстов, включающих в себя художественную литературу, эссе студентов, описания людьми собственных эмоций.
Чем интенсивнее эмоции в тексте, тем вектор (т. е. расстояние от центра до точки, обозначающей текст) будет длиннее, а в зависимости от угла, который образует этот вектор, меняется и общее настроение текста. Для этого и нужна окружность, на которой обозначены различные эмоции.
В среднем все песни Битлз оказываются более «радостными», чем подобранный корпус. А по отдельности песни по-разному располагаются на часах: самой «депрессивной» оказывается песня Джона Леннона «Nowhere Man», самой «приятной» — песня Пола Маккартни «I’ll Follow the Sun».
Сложно понять, насколько эти данные достоверны. Однако интересно, что субъективное мнение критиков, что песни Джона более грустные, как будто подтверждается методами эмоциональной стилометрии. Если два разных подхода к анализу текстов приходят к одному выводу, оба подхода становятся легитимнее, и поэтому, возможно, у эмоциональной стилометрии есть право на существование.
Миша Сонькин
https://sysblok.ru/philology/kak-menjalis-pesni-bitlov-i-mozhno-li-vychislit-jemocii-kompjuternymi-metodami/
{kind=link}
Как вам может помочь музыкальный поисковик Musipedia
#musicology
Тун, тун, ту-тун, тун-тутун, тун-тутууун… Угадали?
Musipedia — Википедия от мира музыки — способна определить мелодию, навязчивый мотив которой не отпускает вас уже несколько дней. Это постоянно обновляемая коллекция музыки со всего мира. В библиотеке проекта более 30 тысяч треков: от сонат Бетховена до Rolling Stones.
«Musipedia» была создана в 2002 году Райнэром Типке, выпускником старейшего в Германии Технологического института Карлсруэ. Сами авторы отмечают, что «Musipedia» была вдохновлена Википедией, однако не является ее частью.
Поисковик позволяет найти и идентифицировать музыку, даже если вы знаете только её приблизительное звучание. Ввести мелодию в поисковик можно разными способами:
1. Наиграть на подключенной MIDI-клавиатуре.
Она похожа на синтезатор, но для извлечения звука в большинстве случаев ей требуется подключение к компьютеру, так как у нее нет встроенных колонок. Обычно она используется преимущественно для звукозаписи.
2. Ввести с клавиатуры компьютера.
Можно отбить только ритм песни на клавише «space», а можно — наиграть мелодию на клавишах (каждая клавиша будет отвечать за определенную ноту).
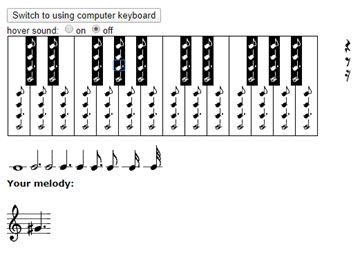
3. Ввести при помощи компьютерной мыши и виртуальных клавиш.
Ниже прикреплен скрин электронной клавиатуры сайта.
4. Насвистеть или напеть в микрофон.
5. Использовать код Парсонса.
Это код для мелодических контуров, в которых происходит так называемое «melodic motion» — движение мелодии вверх или вниз относительно тона предыдущей ноты. Если нота выше предыдущей, она отмечается латинской U (Up), ниже — D (Down), повторяет звучание — R (Repeat). Первая нота отмечается звездочкой ().
На основе такой записи знаменитая колыбельная «Twinkle Twinkle Little Star» будет звучать следующим образом: RURURDDRDRDRDURDRDRDURDRDRDDRURURDDRDRDRD. В русском языке на ту же мелодию играется детская песенка «Как под горкой — под горой».
Когда пользователь набрал мелодию, алгоритм начинает подбор наиболее похожих на нее песен из коллекции «Musipedia». Эту коллекцию можно и пополнить, загрузив трек на сайт. Далее алгоритм программы самостоятельно переведет ноты на понятный ему язык и добавит предложенную мелодию в общую коллекцию. Сайт использует язык нотной записи LilyPond, где каждой ноте соответствует своя буква. Таким образом, привычный нотный стан больше напоминает текстовый документ (‘до’= ‘c’, ‘ре’ = ‘d’ и т. д.).
Мария Черных
https://sysblok.ru/musicology/muzykalnyj-poiskovik-musipedia-ot-mocarta-do-jeltona-dzhona/
#musicology
Тун, тун, ту-тун, тун-тутун, тун-тутууун… Угадали?
Musipedia — Википедия от мира музыки — способна определить мелодию, навязчивый мотив которой не отпускает вас уже несколько дней. Это постоянно обновляемая коллекция музыки со всего мира. В библиотеке проекта более 30 тысяч треков: от сонат Бетховена до Rolling Stones.
«Musipedia» была создана в 2002 году Райнэром Типке, выпускником старейшего в Германии Технологического института Карлсруэ. Сами авторы отмечают, что «Musipedia» была вдохновлена Википедией, однако не является ее частью.
Поисковик позволяет найти и идентифицировать музыку, даже если вы знаете только её приблизительное звучание. Ввести мелодию в поисковик можно разными способами:
1. Наиграть на подключенной MIDI-клавиатуре.
Она похожа на синтезатор, но для извлечения звука в большинстве случаев ей требуется подключение к компьютеру, так как у нее нет встроенных колонок. Обычно она используется преимущественно для звукозаписи.
2. Ввести с клавиатуры компьютера.
Можно отбить только ритм песни на клавише «space», а можно — наиграть мелодию на клавишах (каждая клавиша будет отвечать за определенную ноту).
3. Ввести при помощи компьютерной мыши и виртуальных клавиш.
Ниже прикреплен скрин электронной клавиатуры сайта.
4. Насвистеть или напеть в микрофон.
5. Использовать код Парсонса.
Это код для мелодических контуров, в которых происходит так называемое «melodic motion» — движение мелодии вверх или вниз относительно тона предыдущей ноты. Если нота выше предыдущей, она отмечается латинской U (Up), ниже — D (Down), повторяет звучание — R (Repeat). Первая нота отмечается звездочкой ().
На основе такой записи знаменитая колыбельная «Twinkle Twinkle Little Star» будет звучать следующим образом: RURURDDRDRDRDURDRDRDURDRDRDDRURURDDRDRDRD. В русском языке на ту же мелодию играется детская песенка «Как под горкой — под горой».
Когда пользователь набрал мелодию, алгоритм начинает подбор наиболее похожих на нее песен из коллекции «Musipedia». Эту коллекцию можно и пополнить, загрузив трек на сайт. Далее алгоритм программы самостоятельно переведет ноты на понятный ему язык и добавит предложенную мелодию в общую коллекцию. Сайт использует язык нотной записи LilyPond, где каждой ноте соответствует своя буква. Таким образом, привычный нотный стан больше напоминает текстовый документ (‘до’= ‘c’, ‘ре’ = ‘d’ и т. д.).
Мария Черных
https://sysblok.ru/musicology/muzykalnyj-poiskovik-musipedia-ot-mocarta-do-jeltona-dzhona/
{kind=link}
Музеи — передовики цифровизации: кто вносит больше объектов в Госкаталог музейного фонда
#opendata #открытыеданные
Госкаталог РФ — инициатива Министерства культуры по оцифровке всего российского музейного фонда. Государственные музеи в России обязаны оцифровывать свои фонды и вносить их в Госкаталог. Но размеры музеев не равны, как не равны и их возможности по оцифровке. Нам стало интересно исследовать это неравенство и посчитать, чьих объектов в Госкаталоге больше всего.
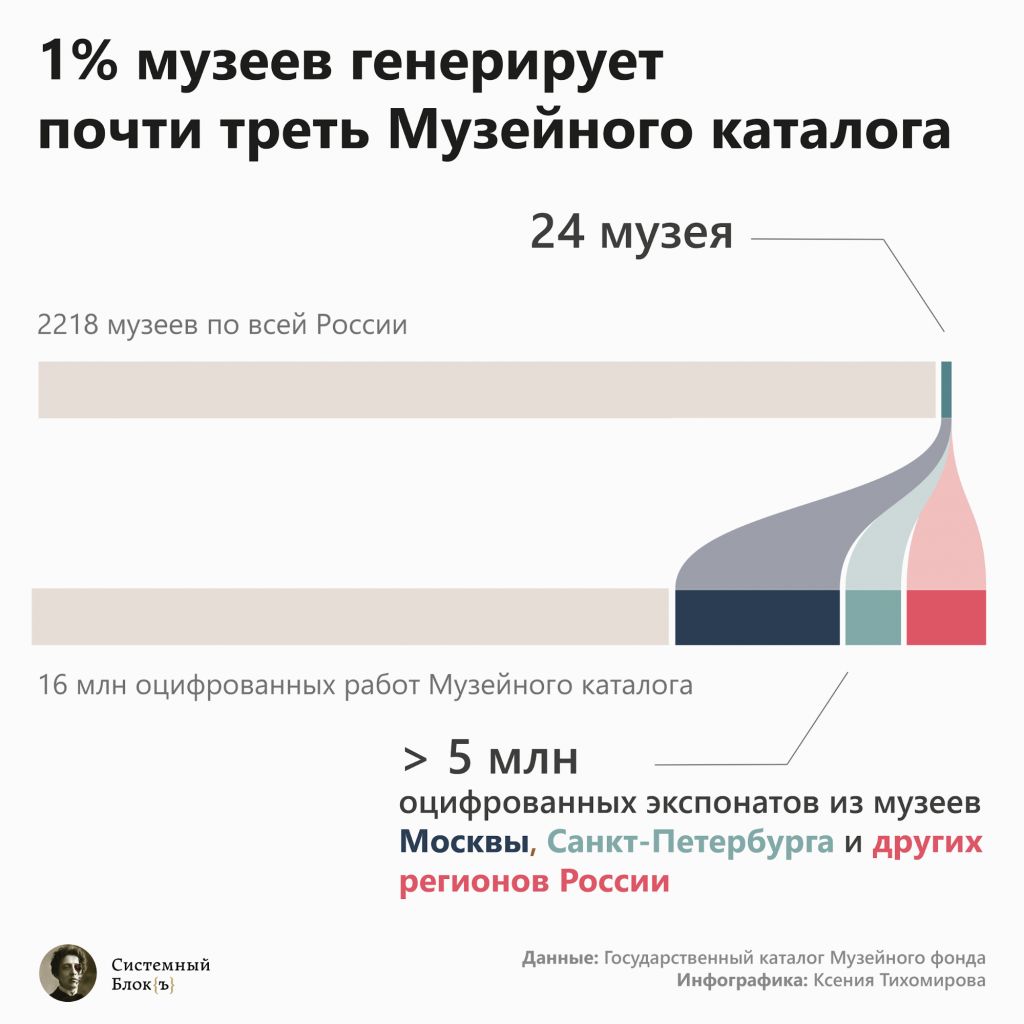
Как выяснилось, 1% музеев внес почти треть работ каталога (32%). По количеству это как полторы коллекции Эрмитажа. В среднем каждый из этих музеев оцифровал почти половину своей коллекции (45%) и выложил 225 тыс. экспонатов. Сам Эрмитаж тоже входит в топ 1% и выложил 15% своих экспонатов.
В этот 1% входит 24 учреждения федерального уровня или из крупных городов. В основном это музеи с большими коллекциями, суммарный объем которых больше четверти всего музейного фонда (28%).
10 музеев из топа находятся в Москве. Лидер по числу оцифрованных объектов — театральный музей имени Бахрушина: оцифровано более 622 тыс. работ (46% коллекции). Помимо декораций и афиш, около 500 тыс. из них посвящены грампластинкам и жизни генерального директора. Например, это фотографии приглашений на мероприятия и благодарностей.
Лидер по доле оцифрованной коллекции находится уже в регионе. Это Владимиро-Суздальский музей-заповедник. Его сотрудники внесли в Госкаталог 96% экспонатов — более 314 тыс. работ. Основные активы заповедника — древние соборы из списка ЮНЕСКО. В электронном виде музей предоставляет фотографии предметов быта: книг, грампластинок, сувениров из стекла и материалов раскопок.
Помимо Владимиро-Суздальского в топе оказались еще 6 музеев-заповедников: Новгородский (361 тыс. оцифрованных объектов), Ставропольский (128 тыс.), Смоленский (117 тыс.), Ростово-Ярославский (88 тыс.), Тобольский (87 тыс.) и Петергоф (99 тыс.).
В начале 2020 каталог Музейного фонда включает более 16 млн оцифрованных и описанных экспонатов, что больше четверти от общей коллекции музеев России (61,6 млн объектов в конце 2018). 2218 музеев внесли свои экспонаты в каталог. В среднем каждый выложил 7 тыс. объектов.
Данные: Минкульт
Ксения Тихомирова
#opendata #открытыеданные
Госкаталог РФ — инициатива Министерства культуры по оцифровке всего российского музейного фонда. Государственные музеи в России обязаны оцифровывать свои фонды и вносить их в Госкаталог. Но размеры музеев не равны, как не равны и их возможности по оцифровке. Нам стало интересно исследовать это неравенство и посчитать, чьих объектов в Госкаталоге больше всего.
Как выяснилось, 1% музеев внес почти треть работ каталога (32%). По количеству это как полторы коллекции Эрмитажа. В среднем каждый из этих музеев оцифровал почти половину своей коллекции (45%) и выложил 225 тыс. экспонатов. Сам Эрмитаж тоже входит в топ 1% и выложил 15% своих экспонатов.
В этот 1% входит 24 учреждения федерального уровня или из крупных городов. В основном это музеи с большими коллекциями, суммарный объем которых больше четверти всего музейного фонда (28%).
10 музеев из топа находятся в Москве. Лидер по числу оцифрованных объектов — театральный музей имени Бахрушина: оцифровано более 622 тыс. работ (46% коллекции). Помимо декораций и афиш, около 500 тыс. из них посвящены грампластинкам и жизни генерального директора. Например, это фотографии приглашений на мероприятия и благодарностей.
Лидер по доле оцифрованной коллекции находится уже в регионе. Это Владимиро-Суздальский музей-заповедник. Его сотрудники внесли в Госкаталог 96% экспонатов — более 314 тыс. работ. Основные активы заповедника — древние соборы из списка ЮНЕСКО. В электронном виде музей предоставляет фотографии предметов быта: книг, грампластинок, сувениров из стекла и материалов раскопок.
Помимо Владимиро-Суздальского в топе оказались еще 6 музеев-заповедников: Новгородский (361 тыс. оцифрованных объектов), Ставропольский (128 тыс.), Смоленский (117 тыс.), Ростово-Ярославский (88 тыс.), Тобольский (87 тыс.) и Петергоф (99 тыс.).
В начале 2020 каталог Музейного фонда включает более 16 млн оцифрованных и описанных экспонатов, что больше четверти от общей коллекции музеев России (61,6 млн объектов в конце 2018). 2218 музеев внесли свои экспонаты в каталог. В среднем каждый выложил 7 тыс. объектов.
Данные: Минкульт
Ксения Тихомирова
{kind=link}
Поясни за смайлик: смех и слезы в интернете
#philology
Рассказываем, как люди начали пользоваться эмотиконами и как теперь их семантику изучают компьютерными методами. Посвящается тем, кто хотя бы раз не понял, что означает сообщение со смайликом.
В письменной речи смайлики — главный способ выражения эмоций: они заменяют интонацию и жесты; могут выступать в качестве слов или выражать отношение говорящего к ситуации.
Смайлики не всегда легко проинтерпретировать, однако и со словами может возникнуть та же проблема. Чтобы понять значение слова, мы обычно смотрим на контекст. Со смайликами этот метод тоже работает. Если контекст не помогает, можно обратиться к словарю.
Разработчики Unicode создали настоящий словарь с описаниями изображений, но вряд ли люди туда часто заглядывают, потому что у смайликов есть преимущество перед словами — визуальная информация. Глядя на слово, мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству.
Цифровые исследования семантики смайликов
Специалисты в области NLP используют эти идеи для переноса значения смайликов в машиночитаемый формат. Ученые уже давно пользуются моделями, которые переводят слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову.
Впервые анализ эмодзи провели в 2015 году. Томас Димсон, один из разработчиков Инстаграма, обучил word2vec на выборке в 50 млн комментариев и поделился результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании — в нашей статье.
Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы. Для оценки близости смайликов были предложены два критерия:
1. сходство (можно ли заменить один смайлик другим);
2. соотнесенность (можно ли встретить эти смайлики в одном контексте).
Группа респондентов также оценила 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов.
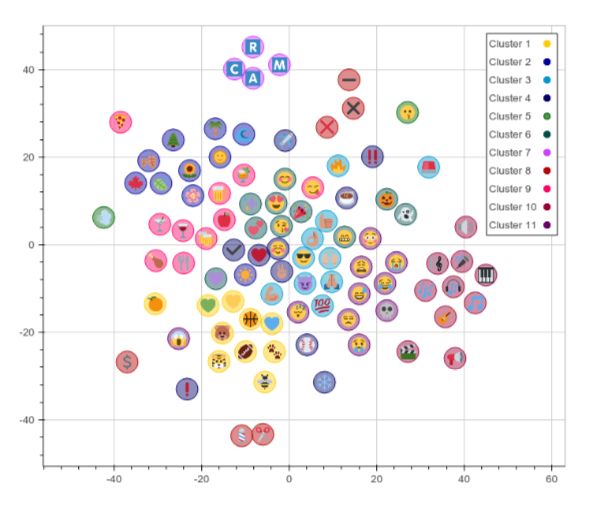
Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Визуализация прикреплена ниже: чем ближе смайлики, тем больше они похожи. На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки, буквенных символов и растений.
Лондонские NLP-специалисты пошли другим путем. В 2016 году они представили своеобразное расширение для традиционной предобученной модели word2vec — emoji2vec. Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений, однако попытки пока не увенчались успехом.
Аня Аксенова
Подробнее читайте по ссылке: https://sysblok.ru/philology/pojasni-za-smajlik-smeh-i-slezy-v-internete/
#philology
Рассказываем, как люди начали пользоваться эмотиконами и как теперь их семантику изучают компьютерными методами. Посвящается тем, кто хотя бы раз не понял, что означает сообщение со смайликом.
В письменной речи смайлики — главный способ выражения эмоций: они заменяют интонацию и жесты; могут выступать в качестве слов или выражать отношение говорящего к ситуации.
Смайлики не всегда легко проинтерпретировать, однако и со словами может возникнуть та же проблема. Чтобы понять значение слова, мы обычно смотрим на контекст. Со смайликами этот метод тоже работает. Если контекст не помогает, можно обратиться к словарю.
Разработчики Unicode создали настоящий словарь с описаниями изображений, но вряд ли люди туда часто заглядывают, потому что у смайликов есть преимущество перед словами — визуальная информация. Глядя на слово, мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству.
Цифровые исследования семантики смайликов
Специалисты в области NLP используют эти идеи для переноса значения смайликов в машиночитаемый формат. Ученые уже давно пользуются моделями, которые переводят слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову.
Впервые анализ эмодзи провели в 2015 году. Томас Димсон, один из разработчиков Инстаграма, обучил word2vec на выборке в 50 млн комментариев и поделился результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании — в нашей статье.
Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы. Для оценки близости смайликов были предложены два критерия:
1. сходство (можно ли заменить один смайлик другим);
2. соотнесенность (можно ли встретить эти смайлики в одном контексте).
Группа респондентов также оценила 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов.
Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Визуализация прикреплена ниже: чем ближе смайлики, тем больше они похожи. На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки, буквенных символов и растений.
Лондонские NLP-специалисты пошли другим путем. В 2016 году они представили своеобразное расширение для традиционной предобученной модели word2vec — emoji2vec. Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений, однако попытки пока не увенчались успехом.
Аня Аксенова
Подробнее читайте по ссылке: https://sysblok.ru/philology/pojasni-za-smajlik-smeh-i-slezy-v-internete/
{kind=link}
Как работают семантические поисковые системы
На примере поисковика по стихам А. С. Пушкина
#nlp
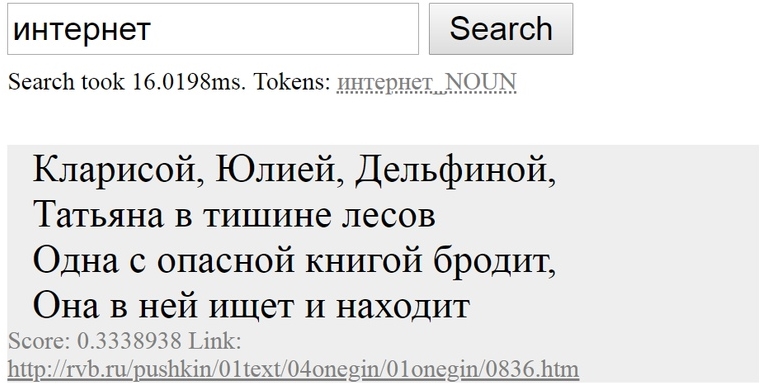
Как найти «то, не знаю что», а если точнее — совершить нечеткий поиск? Вот бы можно было найти в интернете «похожую мысль», «что-нибудь по теме» или «такое же по смыслу». Жаль, что напрямую со смыслом слов Гугл пока что работать не умеет… Зато нечто похожее умеет маленький поисковик по стихам Пушкина.
Посмотрите на скрине ниже, что нашел этот поисковик по запросу «интернет». Как так получилось, что, хотя Пушкин не писал про интернет, поисковик нашел в его стихах строчки про книгу, в которой можно «искать и найти»? Ответ: благодаря семантическим векторам.
Семантический вектор слова
Лингвист Джон Руперт Фёрс однажды сказал: «Слово узнаешь по его окружению». Грубо говоря, на этой гипотезе строится основа дистрибутивной семантики — направления лингвистики, которое вычисляет, насколько близки два слова по смыслу, исходя из частоты их совместной встречаемости в текстовых корпусах.
Так можно найти синонимы и антонимы к слову или классифицировать его в тематический «отдел»; автоматически определить тематику документа, не давая прочесть его человеку; постараться смоделировать перифразы или выяснить правила сочетаемости слов.
Для таких операций каждому новому слову нужно присвоить набор чисел, характеризующий его смысл. Этот набор называется семантическим вектором слова. Его вычисляют на больших корпусах текстов.
В 2013 году Томаш Миколов разработал систему Word2vec, которая строит для слов векторы заданной размерности. Метод Миколова состоит в применении двух нейронных моделей: continuous bag-of-words (CBOW) и skip-gram. Первый предсказывает слово на основе данного контекста, а второй — наоборот, старается угадать контекст данного слова. В результате слова, встречающиеся в тексте в одинаковом окружении (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.
Семантический поисковик по стихам А. С. Пушкина
На сайте RusVectores выложены готовые наборы семантических векторов для огромного числа слов, полученные после обработки различных корпусов текстов алгоритмами word2vec с разными параметрами. Эти «векторные модели» можно скачать и использовать как готовую базу данных семантических векторов. Пользуясь этой возможностью, пользователь GitLab opennota написал семантический поисковик по стихам А. С. Пушкина.
Интерфейс программы — поле запроса, где пользователь может ввести слово или группу слов. Введенный запрос сохраняется в буфер обмена, где морфологический анализатор pymorphy2 распознает формы и леммы слов.
Для каждого слова запроса из предварительно рассчитанной модели word2vec извлекается семантический вектор. В случае, если поисковой запрос содержал несколько слов, их векторы суммируются и нормализуются.
Извлечение векторов отдельных слов, их суммирование и нормализация происходит также для каждого четверостишия из используемой базы данных: эта процедура реализуется при запуске программы. В результате для каждого четверостишия составляется единый семантический вектор.
После получения нормализованного вектора поискового запроса рассчитываются показатели косинусной близости вектора запроса и каждого из векторов четверостиший. Показатели сравниваются и программа выдает строфы, чей семантический вектор ближе всего к вектору слов из поискового запроса.
Поиск дает результаты и тогда, когда очевидно, что слова из поискового запроса не могут встречаться в произведениях Пушкина.
Данный пример демонстрирует, что при помощи инструментов word2vec и проекта RusVectores можно проводить семантический анализ и категоризацию текстов, выполняя поиск по нечетким критериям. Исследователь, работающий с подобной системой, сможет отыскать нестандартные контексты и значения лексических единиц на большом объеме данных.
Владимир Селеверстов
Больше подробностей в статье: https://sysblok.ru/philology/pushkin-terminator-i-zvezdolet/
На примере поисковика по стихам А. С. Пушкина
#nlp
Как найти «то, не знаю что», а если точнее — совершить нечеткий поиск? Вот бы можно было найти в интернете «похожую мысль», «что-нибудь по теме» или «такое же по смыслу». Жаль, что напрямую со смыслом слов Гугл пока что работать не умеет… Зато нечто похожее умеет маленький поисковик по стихам Пушкина.
Посмотрите на скрине ниже, что нашел этот поисковик по запросу «интернет». Как так получилось, что, хотя Пушкин не писал про интернет, поисковик нашел в его стихах строчки про книгу, в которой можно «искать и найти»? Ответ: благодаря семантическим векторам.
Семантический вектор слова
Лингвист Джон Руперт Фёрс однажды сказал: «Слово узнаешь по его окружению». Грубо говоря, на этой гипотезе строится основа дистрибутивной семантики — направления лингвистики, которое вычисляет, насколько близки два слова по смыслу, исходя из частоты их совместной встречаемости в текстовых корпусах.
Так можно найти синонимы и антонимы к слову или классифицировать его в тематический «отдел»; автоматически определить тематику документа, не давая прочесть его человеку; постараться смоделировать перифразы или выяснить правила сочетаемости слов.
Для таких операций каждому новому слову нужно присвоить набор чисел, характеризующий его смысл. Этот набор называется семантическим вектором слова. Его вычисляют на больших корпусах текстов.
В 2013 году Томаш Миколов разработал систему Word2vec, которая строит для слов векторы заданной размерности. Метод Миколова состоит в применении двух нейронных моделей: continuous bag-of-words (CBOW) и skip-gram. Первый предсказывает слово на основе данного контекста, а второй — наоборот, старается угадать контекст данного слова. В результате слова, встречающиеся в тексте в одинаковом окружении (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.
Семантический поисковик по стихам А. С. Пушкина
На сайте RusVectores выложены готовые наборы семантических векторов для огромного числа слов, полученные после обработки различных корпусов текстов алгоритмами word2vec с разными параметрами. Эти «векторные модели» можно скачать и использовать как готовую базу данных семантических векторов. Пользуясь этой возможностью, пользователь GitLab opennota написал семантический поисковик по стихам А. С. Пушкина.
Интерфейс программы — поле запроса, где пользователь может ввести слово или группу слов. Введенный запрос сохраняется в буфер обмена, где морфологический анализатор pymorphy2 распознает формы и леммы слов.
Для каждого слова запроса из предварительно рассчитанной модели word2vec извлекается семантический вектор. В случае, если поисковой запрос содержал несколько слов, их векторы суммируются и нормализуются.
Извлечение векторов отдельных слов, их суммирование и нормализация происходит также для каждого четверостишия из используемой базы данных: эта процедура реализуется при запуске программы. В результате для каждого четверостишия составляется единый семантический вектор.
После получения нормализованного вектора поискового запроса рассчитываются показатели косинусной близости вектора запроса и каждого из векторов четверостиший. Показатели сравниваются и программа выдает строфы, чей семантический вектор ближе всего к вектору слов из поискового запроса.
Поиск дает результаты и тогда, когда очевидно, что слова из поискового запроса не могут встречаться в произведениях Пушкина.
Данный пример демонстрирует, что при помощи инструментов word2vec и проекта RusVectores можно проводить семантический анализ и категоризацию текстов, выполняя поиск по нечетким критериям. Исследователь, работающий с подобной системой, сможет отыскать нестандартные контексты и значения лексических единиц на большом объеме данных.
Владимир Селеверстов
Больше подробностей в статье: https://sysblok.ru/philology/pushkin-terminator-i-zvezdolet/
{kind=link}
У вас стресс, Бэрримор!
#society #history
Сегодня нас раздражают электронная почта, поток каналов в мессенджерах и всяческий киберпанк. Викторианцев же нервировали бесконечные телеграммы, сообщения из газет и… всяческий стимпанк.
В 1869 году американский врач Джордж Миллер Берд выявил новую болезнь. Он дал ей название «неврастения» или «нервное истощение». В ее основе лежало пять элементов — символов XIX века. Ими были паровая энергетика, пресса, телеграфия, развитие науки и рост умственной и профессиональной деятельности женщин. Так появилось понятие «стресс».
Проект «Болезни современной жизни»
Вопрос о возникновении стресса был подробно рассмотрен в исследовательском проекте «Болезни современной жизни». Он финансировался Европейским советом по исследованиям и продолжался с 2014 по 2019 годы. Идея принадлежала Салли Шаттлворт, преподавательнице на факультете английского языка в колледже св. Анны в Оксфорде. В рамках проета изучались явления стресса, перегрузки и другие расстройства в XIX веке. Целью проекта было преодоление разделения психиатрической, экологической и литературной истории и исследование социокультурных явлений в совокупности.
Исследователи предлагали новые способы определения контекста проблем современности в XIX веке. Для этого они опирались на литературу, науку и медицину викторианской эпохи. Это позволило отследить распространение идей тревоги и беспокойства в различных областях. Особое внимание участники уделили роли печати: они рассматривали ее как причину обострения тревог и источник нервозности.
Причины появления стресса
Викторианская эпоха стала временем сильных потрясений и открытий. Ускорился не только технический прогресс, но и само время. Набирала силу урбанизация, строились новые железные дороги и фабрики, появлялись новые социальные классы. Пространства становились все более беспорядочными в социальном отношении. Перемены повлияли на сознание и настроение масс.
В июле 1862 года писатель и литературный критик Эдвард Бульвер-Литтон провел опрос среди британцев. Он обнаружил, что симптомы тревоги стали частью общества. «В состоянии цивилизации, в которой мы пребываем, теперь чаще жалуются из-за переутомления мозга …, нервного истощения и болезни, вызванными чрезмерным раздражением и длительной усталостью …».
По мнению Бульвера-Литтона, «высокоразвитое цивилизованное государство» с помощью прогресса оказывало сильное давление на людей. Этот механизм стал автономной силой, которую стало невозможно контролировать. В результате индустриализация и тревожность британцев создали страх перед современностью. Викторианцы столкнулись с созданной ими реальностью, что и породило стресс. Ниже на рисунке можно увидеть, как, по мнению викторианцев, выглядел этот «безумный новый мир».
О том, чего конкретно боялись британцы и как их лечили от стресса, читайте в нашей статье: https://sysblok.ru/society/u-vas-stress-bjerrimor/
#society #history
Сегодня нас раздражают электронная почта, поток каналов в мессенджерах и всяческий киберпанк. Викторианцев же нервировали бесконечные телеграммы, сообщения из газет и… всяческий стимпанк.
В 1869 году американский врач Джордж Миллер Берд выявил новую болезнь. Он дал ей название «неврастения» или «нервное истощение». В ее основе лежало пять элементов — символов XIX века. Ими были паровая энергетика, пресса, телеграфия, развитие науки и рост умственной и профессиональной деятельности женщин. Так появилось понятие «стресс».
Проект «Болезни современной жизни»
Вопрос о возникновении стресса был подробно рассмотрен в исследовательском проекте «Болезни современной жизни». Он финансировался Европейским советом по исследованиям и продолжался с 2014 по 2019 годы. Идея принадлежала Салли Шаттлворт, преподавательнице на факультете английского языка в колледже св. Анны в Оксфорде. В рамках проета изучались явления стресса, перегрузки и другие расстройства в XIX веке. Целью проекта было преодоление разделения психиатрической, экологической и литературной истории и исследование социокультурных явлений в совокупности.
Исследователи предлагали новые способы определения контекста проблем современности в XIX веке. Для этого они опирались на литературу, науку и медицину викторианской эпохи. Это позволило отследить распространение идей тревоги и беспокойства в различных областях. Особое внимание участники уделили роли печати: они рассматривали ее как причину обострения тревог и источник нервозности.
Причины появления стресса
Викторианская эпоха стала временем сильных потрясений и открытий. Ускорился не только технический прогресс, но и само время. Набирала силу урбанизация, строились новые железные дороги и фабрики, появлялись новые социальные классы. Пространства становились все более беспорядочными в социальном отношении. Перемены повлияли на сознание и настроение масс.
В июле 1862 года писатель и литературный критик Эдвард Бульвер-Литтон провел опрос среди британцев. Он обнаружил, что симптомы тревоги стали частью общества. «В состоянии цивилизации, в которой мы пребываем, теперь чаще жалуются из-за переутомления мозга …, нервного истощения и болезни, вызванными чрезмерным раздражением и длительной усталостью …».
По мнению Бульвера-Литтона, «высокоразвитое цивилизованное государство» с помощью прогресса оказывало сильное давление на людей. Этот механизм стал автономной силой, которую стало невозможно контролировать. В результате индустриализация и тревожность британцев создали страх перед современностью. Викторианцы столкнулись с созданной ими реальностью, что и породило стресс. Ниже на рисунке можно увидеть, как, по мнению викторианцев, выглядел этот «безумный новый мир».
О том, чего конкретно боялись британцы и как их лечили от стресса, читайте в нашей статье: https://sysblok.ru/society/u-vas-stress-bjerrimor/
{kind=link}
Сигнал в будущее: как сообщить потомкам о ядерной угрозе
#society
Около 70 лет прошло с тех пор, как человечество научилось расщеплять атом. За это время на Земле скопилось около 300 тысяч тонн высококонцентрированных радиоактивных отходов, которые будут представлять опасность в течение 100 тысяч лет. Создание прочного и надежного места для захоронения отходов — одна из важнейших инженерных задач современности. В то же время философы, семиотики и лингвисты должны разработать предупреждающий об опасности знак, который будет понятен в будущем более отдаленном, чем мы можем себе представить.
Сейчас проблема ядерных отходов решается их захоронением в геологически стабильных местах нашей планеты. По всему миру разрабатываются и возводятся такие сооружения с расчетом, что отработанное ядерное топливо и другие радиоактивные отходы смогут храниться там от 10 до 100 тысяч лет без какого-либо обслуживания. Наоборот, после того как объект консервируется, вмешательство человека оказывается куда большей проблемой, чем естественный износ или природные катаклизмы.
Экспертное заключение национальных лабораторий Сандия в США предложило три обобщенных сценария развития технологии в будущем: устойчивое развитие, устойчивый упадок и колебание между резкими научными прорывами и крахом технологий. Именно третий сценарий представляет наибольшие опасения, потому что в моменты взлета технологий люди будут иметь техническую возможность обнаружить место захоронения отходов и нарушить его целостность, в то время как периоды упадка могут прервать культурную преемственность человечества настолько, что знания об опасности ядерных отходов затеряются.
Как сделать так, чтобы наши далекие потомки не отнеслись к предупреждениям о реальной опасности так, как мы относимся к проклятиям на египетских пирамидах? В качестве возможных решений:
— атомное братство;
— меняющие цвет коты;
— искусственная луна;
— «Черная дыра»: огромный монолитный блок из черного материала, который поглощает жар пустыни и отражает его, создавая невыносимо высокую температуру вокруг себя;
— «Поле шипов», на котором в случайном порядке построены 15-метровые шипы, наводящие на мысли об опасности;
— наконец, наиболее вероятный сценарий: создание системы долговечных знаков, избыточно маркирующих местонахождение радиоактивных отходов.
Подробнее о каждом из возможных решений — в нашей статье:
https://sysblok.ru/society/signal-v-budushhee-vash-kot-soobshhaet-o-jadernoj-ugroze/
#society
Около 70 лет прошло с тех пор, как человечество научилось расщеплять атом. За это время на Земле скопилось около 300 тысяч тонн высококонцентрированных радиоактивных отходов, которые будут представлять опасность в течение 100 тысяч лет. Создание прочного и надежного места для захоронения отходов — одна из важнейших инженерных задач современности. В то же время философы, семиотики и лингвисты должны разработать предупреждающий об опасности знак, который будет понятен в будущем более отдаленном, чем мы можем себе представить.
Сейчас проблема ядерных отходов решается их захоронением в геологически стабильных местах нашей планеты. По всему миру разрабатываются и возводятся такие сооружения с расчетом, что отработанное ядерное топливо и другие радиоактивные отходы смогут храниться там от 10 до 100 тысяч лет без какого-либо обслуживания. Наоборот, после того как объект консервируется, вмешательство человека оказывается куда большей проблемой, чем естественный износ или природные катаклизмы.
Экспертное заключение национальных лабораторий Сандия в США предложило три обобщенных сценария развития технологии в будущем: устойчивое развитие, устойчивый упадок и колебание между резкими научными прорывами и крахом технологий. Именно третий сценарий представляет наибольшие опасения, потому что в моменты взлета технологий люди будут иметь техническую возможность обнаружить место захоронения отходов и нарушить его целостность, в то время как периоды упадка могут прервать культурную преемственность человечества настолько, что знания об опасности ядерных отходов затеряются.
Как сделать так, чтобы наши далекие потомки не отнеслись к предупреждениям о реальной опасности так, как мы относимся к проклятиям на египетских пирамидах? В качестве возможных решений:
— атомное братство;
— меняющие цвет коты;
— искусственная луна;
— «Черная дыра»: огромный монолитный блок из черного материала, который поглощает жар пустыни и отражает его, создавая невыносимо высокую температуру вокруг себя;
— «Поле шипов», на котором в случайном порядке построены 15-метровые шипы, наводящие на мысли об опасности;
— наконец, наиболее вероятный сценарий: создание системы долговечных знаков, избыточно маркирующих местонахождение радиоактивных отходов.
Подробнее о каждом из возможных решений — в нашей статье:
https://sysblok.ru/society/signal-v-budushhee-vash-kot-soobshhaet-o-jadernoj-ugroze/
{kind=link}
#best
Вчера отмечали международный день архивов. В честь этого события предлагаем вспомнить лучшие посты Системного Блока о цифровых архивах и сохранении данных.
Оцифровать Французскую революцию:
- Парламентские архивы
Рассказываем об архивах парламента Французской революции — того самого парламента, из которого вырос почти весь современный парламентаризм, а также классическое разделение на левых и правых. Оцифровка парламентских архивов — один из самых крупных проектов по дигитализации исторического наследия. Рассказываем, кто, как и зачем это сделал.
- Коллекция Бодуэна
Еще одна цифровая коллекция из времен Французской революции. Франсуа-Жан Бодуэн стал официальным печатником Национальной ассамблеи в июне 1789 года, когда предыдущая типография отказалась обслуживать взбунтовавшееся третье сословие. Его главной задачей было быстрое и качественное издание всех решений, вынесенных Ассамблеей. Изданные им шестьдесят семь томов Collection générale des décrets оказались наиболее полным и заслуживающим доверия сборником, на основе которого была создана база данных Collection Baudoin.
Краудсорсинг в Digital Humanities: опыт Латвийского фольклорного архива
Фольклорный архив Латвии придумал много разных способов пополнять свои цифровые коллекции с привлечением волонтеров и медиа. Ценный опыт, если у вас нет миллионов долларов на оцифровку. Пользователям предложили создавать аудиоверсии любимых стихов, сканировать рукописи для оцифровки, загружать в архив собственные записи старинных песен.
Европейское культурное наследие онлайн
Подборка европейских цифровых архивов: сотни тысяч произведений искусства, старинных рукописей, музейных экспонатов — and much more.
Биты или манускрипт: кто выживет в борьбе со временем?
Оцифровка культурного наследия — это не просто дорого, но и сложно на технологическом и системно-стратегическом уровне. Как обеспечить сохранность данных не через 10, а через 100 лет? Что будет, если сервер архива сгорит? Какие именно данные сохранять, если гуманитариям и социальным исследователям может быть интересно все что угодно, от порносайтов до форумов любителей аквариумных рыбок, а любой рядовой пользователь твиттера может через 30 лет стать президентом? Большая и немного философская статья о трудностях цифрового сохранения.
Ноты — в цифру: как музыковеды собирают данные
Доступ к источникам всегда был проблемой для музыковедов. Еще несколько лет назад для того, чтобы ознакомиться с каким-нибудь редким документом, нужно было найти его местонахождение, пользуясь печатным каталогом, написать в библиотеку и ждать изготовления микрофильма. Процесс мог длиться месяцами. В цифровую эру ситуация изменилась. Рассказываем, как именно.
Вчера отмечали международный день архивов. В честь этого события предлагаем вспомнить лучшие посты Системного Блока о цифровых архивах и сохранении данных.
Оцифровать Французскую революцию:
- Парламентские архивы
Рассказываем об архивах парламента Французской революции — того самого парламента, из которого вырос почти весь современный парламентаризм, а также классическое разделение на левых и правых. Оцифровка парламентских архивов — один из самых крупных проектов по дигитализации исторического наследия. Рассказываем, кто, как и зачем это сделал.
- Коллекция Бодуэна
Еще одна цифровая коллекция из времен Французской революции. Франсуа-Жан Бодуэн стал официальным печатником Национальной ассамблеи в июне 1789 года, когда предыдущая типография отказалась обслуживать взбунтовавшееся третье сословие. Его главной задачей было быстрое и качественное издание всех решений, вынесенных Ассамблеей. Изданные им шестьдесят семь томов Collection générale des décrets оказались наиболее полным и заслуживающим доверия сборником, на основе которого была создана база данных Collection Baudoin.
Краудсорсинг в Digital Humanities: опыт Латвийского фольклорного архива
Фольклорный архив Латвии придумал много разных способов пополнять свои цифровые коллекции с привлечением волонтеров и медиа. Ценный опыт, если у вас нет миллионов долларов на оцифровку. Пользователям предложили создавать аудиоверсии любимых стихов, сканировать рукописи для оцифровки, загружать в архив собственные записи старинных песен.
Европейское культурное наследие онлайн
Подборка европейских цифровых архивов: сотни тысяч произведений искусства, старинных рукописей, музейных экспонатов — and much more.
Биты или манускрипт: кто выживет в борьбе со временем?
Оцифровка культурного наследия — это не просто дорого, но и сложно на технологическом и системно-стратегическом уровне. Как обеспечить сохранность данных не через 10, а через 100 лет? Что будет, если сервер архива сгорит? Какие именно данные сохранять, если гуманитариям и социальным исследователям может быть интересно все что угодно, от порносайтов до форумов любителей аквариумных рыбок, а любой рядовой пользователь твиттера может через 30 лет стать президентом? Большая и немного философская статья о трудностях цифрового сохранения.
Ноты — в цифру: как музыковеды собирают данные
Доступ к источникам всегда был проблемой для музыковедов. Еще несколько лет назад для того, чтобы ознакомиться с каким-нибудь редким документом, нужно было найти его местонахождение, пользуясь печатным каталогом, написать в библиотеку и ждать изготовления микрофильма. Процесс мог длиться месяцами. В цифровую эру ситуация изменилась. Рассказываем, как именно.
{kind=link}
«Республика учёных»: создание модели общества Раннего Нового времени
#history
Начиная с 15 века благодаря открытию новых университетов, изобретению печати и развитию почтовой системы, всё больше и больше образованных людей из разных стран могли связываться друг с другом, чтобы обсудить новые публикации, события или частную жизнь.
Таким образом, европейское научное сообщество оказалось неформально, но очень тесно связано. Сами себя члены этого огромного надгосударственного и независимого общества назвали respublica litteraria — республика учёных. Стать её частью можно было вне зависимости от происхождения или дохода, нужно было просто быть образованным и культурным человеком.
Самым важным и обширным свидетельством о существовании «республики» является корреспонденция, связывавшая воедино людей из разных концов мира. По приблизительным оценкам, с того времени до нас дошло более миллиона писем. Кроме того, сохранились различные сведения о путешествиях, религиозных обществах и университетах, а также книги, газеты и журналы.
Долгое время письма хранились в архивах, и ученым нужно было приложить усилия, чтобы получить к ним доступ. В наши дни ситуация улучшилась: много документов оцифровано и находится в открытом доступе. Нехватки источников уже давно нет, напротив, обилие информации делает невозможным всё проанализировать и составить общую картину происходящего. И здесь на помощь приходит Big Data.
С помощью инструментов Big Data можно узнать, как жили люди в эпоху Ренессанса и Просвещения, с кем они общались, где учились и о чём переписывались. Пошаговый анализ писем, а также визуализация результатов исследования — в нашей статье: https://sysblok.ru/history/respublika-uchjonyh-sozdanie-modeli-obshhestva-rannego-novogo-vremeni/
#history
Начиная с 15 века благодаря открытию новых университетов, изобретению печати и развитию почтовой системы, всё больше и больше образованных людей из разных стран могли связываться друг с другом, чтобы обсудить новые публикации, события или частную жизнь.
Таким образом, европейское научное сообщество оказалось неформально, но очень тесно связано. Сами себя члены этого огромного надгосударственного и независимого общества назвали respublica litteraria — республика учёных. Стать её частью можно было вне зависимости от происхождения или дохода, нужно было просто быть образованным и культурным человеком.
Самым важным и обширным свидетельством о существовании «республики» является корреспонденция, связывавшая воедино людей из разных концов мира. По приблизительным оценкам, с того времени до нас дошло более миллиона писем. Кроме того, сохранились различные сведения о путешествиях, религиозных обществах и университетах, а также книги, газеты и журналы.
Долгое время письма хранились в архивах, и ученым нужно было приложить усилия, чтобы получить к ним доступ. В наши дни ситуация улучшилась: много документов оцифровано и находится в открытом доступе. Нехватки источников уже давно нет, напротив, обилие информации делает невозможным всё проанализировать и составить общую картину происходящего. И здесь на помощь приходит Big Data.
С помощью инструментов Big Data можно узнать, как жили люди в эпоху Ренессанса и Просвещения, с кем они общались, где учились и о чём переписывались. Пошаговый анализ писем, а также визуализация результатов исследования — в нашей статье: https://sysblok.ru/history/respublika-uchjonyh-sozdanie-modeli-obshhestva-rannego-novogo-vremeni/
{kind=link}
Мама мыла LSTM: как устроены рекуррентные нейросети с долгой краткосрочной памятью
#knowhow
Системный Блокъ подготовил крафтовый техно-лонгрид, в котором разбирается по винтикам одна из самых ходовых технологий в современной компьютерной лингвистике — рекуррентные нейросети с архитектурой LSTM.
Именно на LSTM-сетях впервые взлетел качественный нейросетевой машинный перевод. Несмотря на бум нейросетей-трансформеров, о которых мы расскажем в наших следующих техно-лонгридах, рекуррентные LSTM-сети остаются одним из популярнейших рабочих инструментов в задачах машинной обработки естественного языка.
Зачем обрабатывать текст на компьютере
Было бы круто научить компьютер генерировать связный текст, выделять логические конструкции, потом делать с ними что-нибудь интересное, как умеет человек. Может получиться чат-бот, поисковая машина, «умная» клавиатура на телефоне, онлайн-переводчик, генератор пересказов.
Эти задачи решает обработка естественного языка. С ней есть сложности: в языке бывают омонимы, бывают многозначные слова. А что делать, если «Трофей не поместился в чемодан, потому что он был слишком большим»? Как тут программе сориентироваться, к чему относится слово «он»?
К счастью, речь людей статистически предсказуема. Есть популярные цепочки слов, которые повторяют почти все. Велика вероятность после слов «чайник уже» найти слово «вскипел». И напротив, есть последовательности, которые никогда не услышишь в речи. Например, «чайник уже… обиделся».
О чем рассказываем в статье:
— Как использовать неслучайность речи
— Как работает языковая модель на цепях Маркова без нейросетей
— Что такое рекуррентность
— Как RNN сохраняет свое состояние и передает его дальше
— Почему неэффективно передавать контекст со слоя на слой
— Что происходит внутри одного слоя нейронов
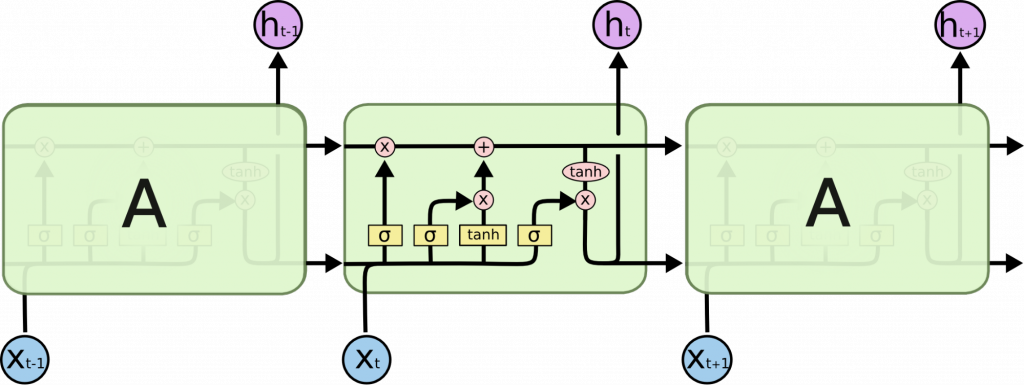
— Как работает LSTM — Long Short Term Memory
— Как реализуется забывание контекста в LSTM
— Как реализуется запоминание контекста в LSTM
— Как реализуется запись новых значений в контекст
— Как получается предсказание LSTM
Обо всем этом — в нашей статье: https://sysblok.ru/knowhow/mama-myla-lstm-kak-ustroeny-rekurrentnye-nejroseti-s-dolgoj-kratkosrochnoj-pamjatju/
#knowhow
Системный Блокъ подготовил крафтовый техно-лонгрид, в котором разбирается по винтикам одна из самых ходовых технологий в современной компьютерной лингвистике — рекуррентные нейросети с архитектурой LSTM.
Именно на LSTM-сетях впервые взлетел качественный нейросетевой машинный перевод. Несмотря на бум нейросетей-трансформеров, о которых мы расскажем в наших следующих техно-лонгридах, рекуррентные LSTM-сети остаются одним из популярнейших рабочих инструментов в задачах машинной обработки естественного языка.
Зачем обрабатывать текст на компьютере
Было бы круто научить компьютер генерировать связный текст, выделять логические конструкции, потом делать с ними что-нибудь интересное, как умеет человек. Может получиться чат-бот, поисковая машина, «умная» клавиатура на телефоне, онлайн-переводчик, генератор пересказов.
Эти задачи решает обработка естественного языка. С ней есть сложности: в языке бывают омонимы, бывают многозначные слова. А что делать, если «Трофей не поместился в чемодан, потому что он был слишком большим»? Как тут программе сориентироваться, к чему относится слово «он»?
К счастью, речь людей статистически предсказуема. Есть популярные цепочки слов, которые повторяют почти все. Велика вероятность после слов «чайник уже» найти слово «вскипел». И напротив, есть последовательности, которые никогда не услышишь в речи. Например, «чайник уже… обиделся».
О чем рассказываем в статье:
— Как использовать неслучайность речи
— Как работает языковая модель на цепях Маркова без нейросетей
— Что такое рекуррентность
— Как RNN сохраняет свое состояние и передает его дальше
— Почему неэффективно передавать контекст со слоя на слой
— Что происходит внутри одного слоя нейронов
— Как работает LSTM — Long Short Term Memory
— Как реализуется забывание контекста в LSTM
— Как реализуется запоминание контекста в LSTM
— Как реализуется запись новых значений в контекст
— Как получается предсказание LSTM
Обо всем этом — в нашей статье: https://sysblok.ru/knowhow/mama-myla-lstm-kak-ustroeny-rekurrentnye-nejroseti-s-dolgoj-kratkosrochnoj-pamjatju/
{kind=link}
Как отслеживают мировую историю через анализ и визуализацию данных
На примере истории международных конгрессов XIX–XX веков
#history
Визуализация используется еще со времен Древнего Египта и майя. Со временем визуализация — способ отображения текстовой информации в более доступной форме на диаграммах, графиках или интерактивных картах — стала неотъемлемой частью любой науки. С недавнего времени она применяется и в качестве одного из ведущих методов изучения истории, ведь мировая история, записанная исключительно в текстовом формате или при помощи обычных карт, может быть трудна для восприятия.
Международные конгрессы
Развитие международного сотрудничества началось с самого начала человеческой истории. Вплоть до 20-го века, однако, это была скорее интернационализация, то есть кросскоммуникация между отдельными государствами. Привычная нам глобализация, когда все государства интегрируются в одну общую систему, не насчитывает в своей истории и ста лет.
Сегодня международные конгрессы — пережиток времен интернационализации — видятся как наследие ушедшей прекрасной эпохи. Они уступают место крупным всемирным организациям: ООН, НАТО, ВТО (а первой в их числе была Лига Наций, созданная после Первой Мировой войны).
Вокруг съездов и конгрессов со временем формируются организации, контролирующие их деятельность. Первой становится Союз Международных Ассоциаций (СМА). С 1907 он как неправительственный научно-исследовательский институт и центр документации ведет учет деятельности всех конгрессов и деятельности глобального гражданского общества.
Проект «Mapping a century of International Congresses»
Целью проекта «Mapping a century of International Congresses» стала визуализация огромного количества информации о более чем 8000 международных конгрессах 1840–1960 годов на основе документов ежегодных конгрессов и документации СМА.
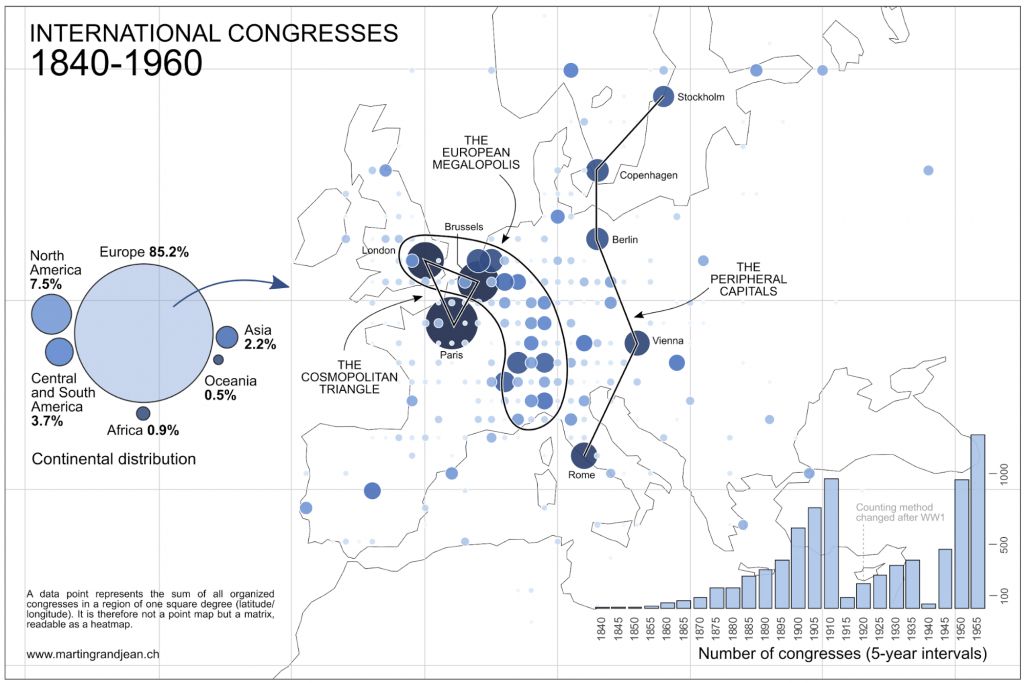
Карты с акцентом на достоверность и точность были бы крайне громоздки и перенасыщены информацией, потому что они охватывают большую площадь и значительные временные рамки. Поэтому был выбран вариант, наиболее близкий к тепловым картам, где значения документации отображаются при помощи цвета или тона. Это позволило более просто визуализировать информацию.
Тепловая карта, прикрепленная ниже, позволяет с первого взгляда оценить распределение международных конгрессов по городам. Выделился «космпополитический треугольник»: три города, где чаще всего собирались конгрессмены, — Париж, Лондон, и Брюссель. Остальные города разделились на «европейский мегаполис» — урбанизированный район, протянувшийся от Манчестера на юг до Милана, и «периферийные столицы», в которых конгрессы проводились реже.
Анализ документации СМА
Для начала проанализировали рост числа конгрессов и их распределение по европейскому континенту. Выяснилось, что за весь период Европа приняла 85% от общего числа международных конгрессов. А до начала Первой Мировой так и все 92%. В то же время на территории Северной Америки проводится за все время чуть более 11% мероприятий.
Также создали гистограммы, которые отражают распределение конгрессов по городам между 1840 и 1960 годами. Из полученных данных были выявлены 12 ведущих стран, в разное время принимавших конгрессы на своей территории: Франция, Бельгия, Великобритания, Германия, Швейцария, США, Италия, Нидерладны, Австрия, Дания, Швеция и Испания.
По заявлениям самих исследователей подобный подход к представлению исторических данных помог понять процессы интернационализации международного сообщества и задокументировать общественно-научная история международных отношений.
Мария Черных
Все диаграммы и гистограммы — по ссылке: https://sysblok.ru/history/i-celogo-mira-malo-kak-otsledit-mirovuju-istoriju-cherez-analiz-i-vizualizaciju-dannyh/
На примере истории международных конгрессов XIX–XX веков
#history
Визуализация используется еще со времен Древнего Египта и майя. Со временем визуализация — способ отображения текстовой информации в более доступной форме на диаграммах, графиках или интерактивных картах — стала неотъемлемой частью любой науки. С недавнего времени она применяется и в качестве одного из ведущих методов изучения истории, ведь мировая история, записанная исключительно в текстовом формате или при помощи обычных карт, может быть трудна для восприятия.
Международные конгрессы
Развитие международного сотрудничества началось с самого начала человеческой истории. Вплоть до 20-го века, однако, это была скорее интернационализация, то есть кросскоммуникация между отдельными государствами. Привычная нам глобализация, когда все государства интегрируются в одну общую систему, не насчитывает в своей истории и ста лет.
Сегодня международные конгрессы — пережиток времен интернационализации — видятся как наследие ушедшей прекрасной эпохи. Они уступают место крупным всемирным организациям: ООН, НАТО, ВТО (а первой в их числе была Лига Наций, созданная после Первой Мировой войны).
Вокруг съездов и конгрессов со временем формируются организации, контролирующие их деятельность. Первой становится Союз Международных Ассоциаций (СМА). С 1907 он как неправительственный научно-исследовательский институт и центр документации ведет учет деятельности всех конгрессов и деятельности глобального гражданского общества.
Проект «Mapping a century of International Congresses»
Целью проекта «Mapping a century of International Congresses» стала визуализация огромного количества информации о более чем 8000 международных конгрессах 1840–1960 годов на основе документов ежегодных конгрессов и документации СМА.
Карты с акцентом на достоверность и точность были бы крайне громоздки и перенасыщены информацией, потому что они охватывают большую площадь и значительные временные рамки. Поэтому был выбран вариант, наиболее близкий к тепловым картам, где значения документации отображаются при помощи цвета или тона. Это позволило более просто визуализировать информацию.
Тепловая карта, прикрепленная ниже, позволяет с первого взгляда оценить распределение международных конгрессов по городам. Выделился «космпополитический треугольник»: три города, где чаще всего собирались конгрессмены, — Париж, Лондон, и Брюссель. Остальные города разделились на «европейский мегаполис» — урбанизированный район, протянувшийся от Манчестера на юг до Милана, и «периферийные столицы», в которых конгрессы проводились реже.
Анализ документации СМА
Для начала проанализировали рост числа конгрессов и их распределение по европейскому континенту. Выяснилось, что за весь период Европа приняла 85% от общего числа международных конгрессов. А до начала Первой Мировой так и все 92%. В то же время на территории Северной Америки проводится за все время чуть более 11% мероприятий.
Также создали гистограммы, которые отражают распределение конгрессов по городам между 1840 и 1960 годами. Из полученных данных были выявлены 12 ведущих стран, в разное время принимавших конгрессы на своей территории: Франция, Бельгия, Великобритания, Германия, Швейцария, США, Италия, Нидерладны, Австрия, Дания, Швеция и Испания.
По заявлениям самих исследователей подобный подход к представлению исторических данных помог понять процессы интернационализации международного сообщества и задокументировать общественно-научная история международных отношений.
Мария Черных
Все диаграммы и гистограммы — по ссылке: https://sysblok.ru/history/i-celogo-mira-malo-kak-otsledit-mirovuju-istoriju-cherez-analiz-i-vizualizaciju-dannyh/
{kind=link}
«Мы вытаскиваем людей из небытия» ― интервью с Виктором Тумаркиным, техническим руководителем ОБД «Мемориал» и «Подвиг народа»
#interview
В Великой Отечественной войне участвовали десятки миллионов людей. Воевали наши бабушки и дедушки, прабабушки и прадедушки, их сестры, братья, жены, мужья. Трудно найти семью, где не было бы родственника-участника ВОВ.
К 22 июня «Системный Блокъ» сделал большое интервью с техническим руководителем ОБД «Мемориал» и «Подвига народа» Виктором Тумаркиным — о поиске родных, работе по оцифровке архивов и о том, что нового мы сможем узнать о войне, когда будет оцифровано все доступное.
В чем могут помочь ресурсы о войне?
1. Установить судьбу человека, который не вернулся с войны. Чтобы понять, что с ним случилось, если человек погиб, то где он похоронен.
2. Узнать что-то новое о своих близких, связанное либо с наградами, либо с боевым путем — где воевали и чем отличились.
3. Генеалогический поиск и расширение генеалогического древа.
Как соотносятся три ресурса — ОБД «Мемориал», «Подвиг народа» и «Память народа»?
Сайт ОБД «Мемориал» строго направлен на поиск человека, установление судьбы. Раньше там можно было найти только не вернувшихся с войны, сейчас появляются другие массивы информации ― документы призыва, списки частей, прохождение через военно-призывные пункты и запасные полки, учетно-послужные карты.
За наградами нужно идти на «Подвиг народа». А «Память народа» — это все перечисленное вместе плюс оперативные документы, карты действий отдельных частей, информация о командующих.
Как поступить человеку, который хочет узнать судьбу своего дедушки или прадедушки?
Если нужна судьба, сначала лучше поискать на ОБД «Мемориал». Если там ничего не нашлось, можно еще попробовать на «Памяти народа». Если есть редкая фамилия, редкое имя, редкое отчество — надо начинать искать с него. Вилка такая: если дашь очень много информации — этого может не оказаться в документе и не будет найдено. Если дашь очень мало, то записей может оказаться очень много, и все их перебирать сил не хватит.
Поэтому нужно искать какой-то разумный компромисс. Начинать с самого простого, просто явно задавая ФИО, и смотреть, сколько мы такого найдем. Можно даже без года, потому что много документов, в которых нет года рождения, или он неправильный. Но, конечно, если это Иванов Иван Сергеевич, то задавать просто ФИО бесполезно.
В полной версии интервью вы узнаете:
— Если человек не находится даже расширенным поиском, о чем это говорит?
— Может ли пользователь ОБД «Мемориал» как-то исправить опечатку в документе?
— Как создавался проект ОБД «Мемориал»?
— Как проводилась оцифровка документов?
— Сколько человек работают над проектом?
— Как описывались подвиги в наградных листах?
https://sysblok.ru/interviews/my-vytaskivaem-ljudej-iz-nebytija/
#interview
В Великой Отечественной войне участвовали десятки миллионов людей. Воевали наши бабушки и дедушки, прабабушки и прадедушки, их сестры, братья, жены, мужья. Трудно найти семью, где не было бы родственника-участника ВОВ.
К 22 июня «Системный Блокъ» сделал большое интервью с техническим руководителем ОБД «Мемориал» и «Подвига народа» Виктором Тумаркиным — о поиске родных, работе по оцифровке архивов и о том, что нового мы сможем узнать о войне, когда будет оцифровано все доступное.
В чем могут помочь ресурсы о войне?
1. Установить судьбу человека, который не вернулся с войны. Чтобы понять, что с ним случилось, если человек погиб, то где он похоронен.
2. Узнать что-то новое о своих близких, связанное либо с наградами, либо с боевым путем — где воевали и чем отличились.
3. Генеалогический поиск и расширение генеалогического древа.
Как соотносятся три ресурса — ОБД «Мемориал», «Подвиг народа» и «Память народа»?
Сайт ОБД «Мемориал» строго направлен на поиск человека, установление судьбы. Раньше там можно было найти только не вернувшихся с войны, сейчас появляются другие массивы информации ― документы призыва, списки частей, прохождение через военно-призывные пункты и запасные полки, учетно-послужные карты.
За наградами нужно идти на «Подвиг народа». А «Память народа» — это все перечисленное вместе плюс оперативные документы, карты действий отдельных частей, информация о командующих.
Как поступить человеку, который хочет узнать судьбу своего дедушки или прадедушки?
Если нужна судьба, сначала лучше поискать на ОБД «Мемориал». Если там ничего не нашлось, можно еще попробовать на «Памяти народа». Если есть редкая фамилия, редкое имя, редкое отчество — надо начинать искать с него. Вилка такая: если дашь очень много информации — этого может не оказаться в документе и не будет найдено. Если дашь очень мало, то записей может оказаться очень много, и все их перебирать сил не хватит.
Поэтому нужно искать какой-то разумный компромисс. Начинать с самого простого, просто явно задавая ФИО, и смотреть, сколько мы такого найдем. Можно даже без года, потому что много документов, в которых нет года рождения, или он неправильный. Но, конечно, если это Иванов Иван Сергеевич, то задавать просто ФИО бесполезно.
В полной версии интервью вы узнаете:
— Если человек не находится даже расширенным поиском, о чем это говорит?
— Может ли пользователь ОБД «Мемориал» как-то исправить опечатку в документе?
— Как создавался проект ОБД «Мемориал»?
— Как проводилась оцифровка документов?
— Сколько человек работают над проектом?
— Как описывались подвиги в наградных листах?
https://sysblok.ru/interviews/my-vytaskivaem-ljudej-iz-nebytija/
{kind=link}
Коллективная память в эпоху её технической воспроизводимости
#digitalmemory
Memory studies — это междисциплинарное направление в гуманитарном знании. Объект его изучения — коллективная память, то есть коллективные представления людей об их истории и культуре и общие воспоминания, консолидирующие социальные группы.
Цифровые средства предоставляют людям новые возможности: публично показывать не только свою личную скорбь, но и скорбь по трагедиям, которые произошли далеко и не коснулись никого из близких.
Самый популярный способ выразить соболезнования и показать свою сопричастность к общему горю — фотография свечи. Её могут выставить в отдельном посте, временно поставить в качестве аватара или обложки на личной странице.
Однако этот способ выражения скорби часто критикуется. Так, президент Украины Владимир Зеленский поставил свечу на обложку своей страницы в Facebook после крушения Boeing-737 «Международных авиалиний Украины» под Тегераном 8 января 2020 года, когда погибло 176 человек. В ответ на это пользователи соцсети высказались о неуместности фотографии с улыбкой в таком контексте, и вскоре Зеленский заменил аватар на другой, где у него более серьёзное выражение лица. Также, при просмотре с телефона, свеча как будто вырастает прямо из головы человека, что не способствует поддержанию скорбного настроения.
Дизайнера Данилу No Name свечи в Интернете раздражают уже давно. Ещё в ноябре 2018 г. он выпустили лендинг под названием «Траур BUNDLE (4K) SMM pack», где «продаёт» наборы для скорби: изображения свечей различного размера и цвета в хорошем качестве для постов и аватарок. Скриншот прикреплен ниже.
О том, какие еще есть способы публично выразить свою скорбь и почему коммеморация в сети — это не всегда про скорбь и смерть, рассказываем в нашей статье: https://sysblok.ru/society/kollektivnaja-pamjat-v-jepohu-ejo-tehnicheskoj-vosproizvodimosti/
#digitalmemory
Memory studies — это междисциплинарное направление в гуманитарном знании. Объект его изучения — коллективная память, то есть коллективные представления людей об их истории и культуре и общие воспоминания, консолидирующие социальные группы.
Цифровые средства предоставляют людям новые возможности: публично показывать не только свою личную скорбь, но и скорбь по трагедиям, которые произошли далеко и не коснулись никого из близких.
Самый популярный способ выразить соболезнования и показать свою сопричастность к общему горю — фотография свечи. Её могут выставить в отдельном посте, временно поставить в качестве аватара или обложки на личной странице.
Однако этот способ выражения скорби часто критикуется. Так, президент Украины Владимир Зеленский поставил свечу на обложку своей страницы в Facebook после крушения Boeing-737 «Международных авиалиний Украины» под Тегераном 8 января 2020 года, когда погибло 176 человек. В ответ на это пользователи соцсети высказались о неуместности фотографии с улыбкой в таком контексте, и вскоре Зеленский заменил аватар на другой, где у него более серьёзное выражение лица. Также, при просмотре с телефона, свеча как будто вырастает прямо из головы человека, что не способствует поддержанию скорбного настроения.
Дизайнера Данилу No Name свечи в Интернете раздражают уже давно. Ещё в ноябре 2018 г. он выпустили лендинг под названием «Траур BUNDLE (4K) SMM pack», где «продаёт» наборы для скорби: изображения свечей различного размера и цвета в хорошем качестве для постов и аватарок. Скриншот прикреплен ниже.
О том, какие еще есть способы публично выразить свою скорбь и почему коммеморация в сети — это не всегда про скорбь и смерть, рассказываем в нашей статье: https://sysblok.ru/society/kollektivnaja-pamjat-v-jepohu-ejo-tehnicheskoj-vosproizvodimosti/
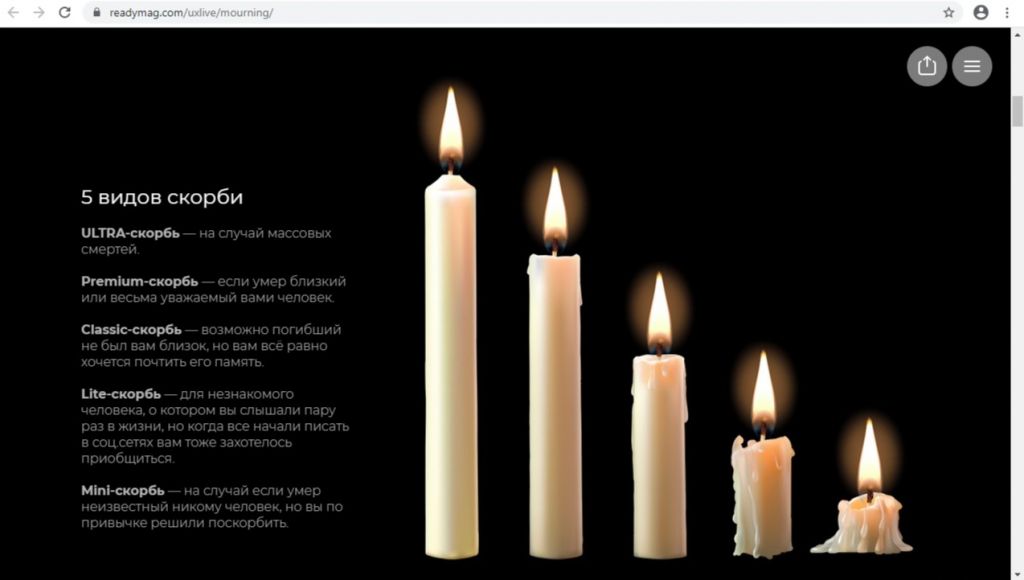{kind=link}
Внимание — все, что вам нужно: как работает attention в нейросетях
#knowhow
Мы продолжаем серию постов об устройстве нейронных сетей. В прошлом материале «Системный Блокъ» рассказывал о том, зачем нужны рекуррентные нейросети (RNN), что такое рекуррентность и как добавить нейросети долгосрочной памяти.
Сегодня рассказываем о механизме внимания, на котором работают в 2020 году все действительно крутые нейросети. Почему внимание стало killer-фичей диплернинга, что под капотом у attention mechanism, как нейросеть понимает, какие признаки текста или картинки важнее других.
У применения RNN в области обработки и понимания естественного языка есть три основные проблемы:
1. RNN работает медленно и недостаточно эффективно;
2. RNN учитывает только прошлый контекст, а не все предложение;
3. в RNN контекст со временем размывается.
Чтобы решить вторую проблему, используют двунаправленную RNN. Она обрабатывает предложение один раз слева направо, другой раз — справа налево, и только потом начинает предсказывать.
А механизм внимания решает третью проблему. Его цель — заставить нейросеть сильнее сосредоточиться на важном слове в дальнем конце предложения. Контекст — это сумма векторов всех слов в предложении. «Подсветить» важное слово в контексте — значит умножить его вектор на большое число («вес внимания»). Чтобы понять, какое слово сейчас важно, потребуется еще одна нейросеть (внутри нейросети).
О чем рассказываем в статье:
— Какие бывают типы рекуррентных архитектур
— Чем хороша архитектура «энкодер — декодер» для машинного перевода
— Как работает двунаправленная RNN
— В чем заключается идея механизма внимания
— Как сделан механизм внимания в энкодере
— Как сделан механизм внимания в декодере
— Как получить вес внимания и понять, что на самом деле важно «запомнить»
— Как работает функция активации Softmax
https://sysblok.ru/knowhow/vnimanie-vse-chto-vam-nuzhno-kak-rabotaet-attention-v-nejrosetjah/
#knowhow
Мы продолжаем серию постов об устройстве нейронных сетей. В прошлом материале «Системный Блокъ» рассказывал о том, зачем нужны рекуррентные нейросети (RNN), что такое рекуррентность и как добавить нейросети долгосрочной памяти.
Сегодня рассказываем о механизме внимания, на котором работают в 2020 году все действительно крутые нейросети. Почему внимание стало killer-фичей диплернинга, что под капотом у attention mechanism, как нейросеть понимает, какие признаки текста или картинки важнее других.
У применения RNN в области обработки и понимания естественного языка есть три основные проблемы:
1. RNN работает медленно и недостаточно эффективно;
2. RNN учитывает только прошлый контекст, а не все предложение;
3. в RNN контекст со временем размывается.
Чтобы решить вторую проблему, используют двунаправленную RNN. Она обрабатывает предложение один раз слева направо, другой раз — справа налево, и только потом начинает предсказывать.
А механизм внимания решает третью проблему. Его цель — заставить нейросеть сильнее сосредоточиться на важном слове в дальнем конце предложения. Контекст — это сумма векторов всех слов в предложении. «Подсветить» важное слово в контексте — значит умножить его вектор на большое число («вес внимания»). Чтобы понять, какое слово сейчас важно, потребуется еще одна нейросеть (внутри нейросети).
О чем рассказываем в статье:
— Какие бывают типы рекуррентных архитектур
— Чем хороша архитектура «энкодер — декодер» для машинного перевода
— Как работает двунаправленная RNN
— В чем заключается идея механизма внимания
— Как сделан механизм внимания в энкодере
— Как сделан механизм внимания в декодере
— Как получить вес внимания и понять, что на самом деле важно «запомнить»
— Как работает функция активации Softmax
https://sysblok.ru/knowhow/vnimanie-vse-chto-vam-nuzhno-kak-rabotaet-attention-v-nejrosetjah/
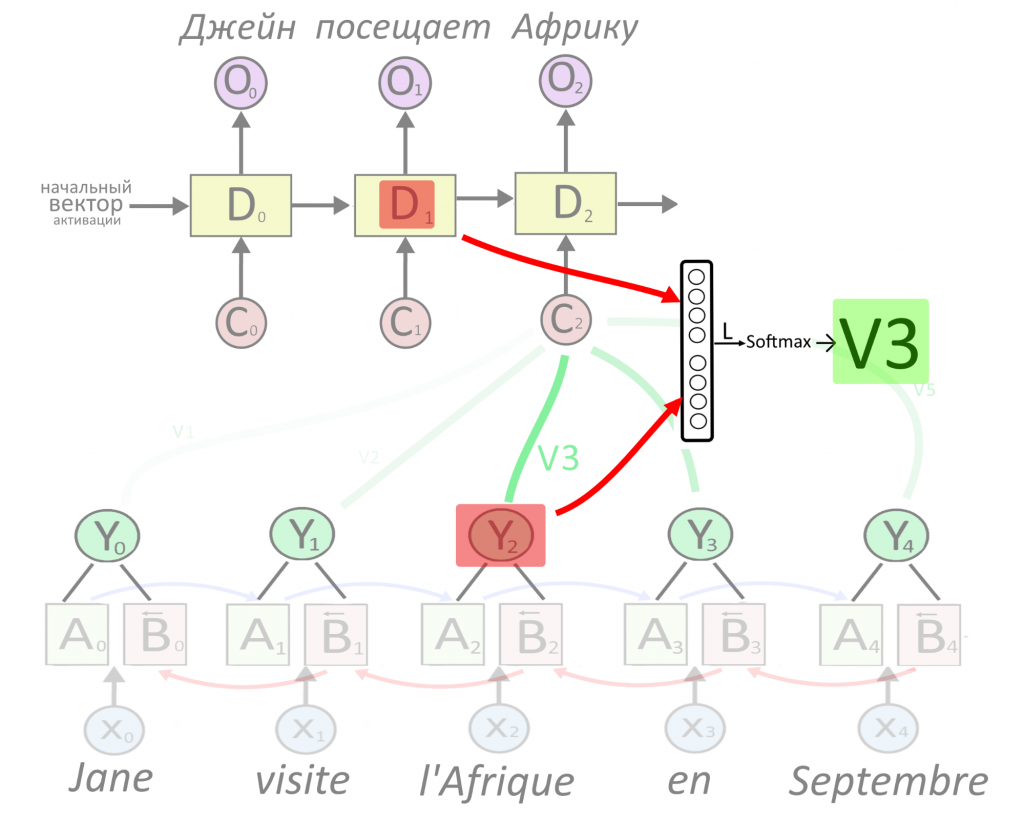{kind=link}
Как измерить городскую культуру
#urban
В 1980-х годах французский социолог Пьер Бурдье предложил теорию, согласно которой успех человека определяется соотношением его экономического и культурного капитала — два измерения социального пространства, схематично изображенного на рисунке ниже.
Исследовательская компания GoodCityLife решила проверить эту теорию на уровне городских районов, то есть выяснить, в какой степени успешность городского развития определяется не только экономическими, но и культурными факторами. Но как можно измерить такую нематериальную вещь как культура?
Мы уже писали об одном из проектов этой компании, суть которого состояла в создании карты запахов города на основе фотографий из социальных сетей. Здесь похожий принцип: берём несколько миллионов фотографий из Flickr с геопривязкой к одному из районов Лондона или Нью-Йорка и анализируем теги.
Культурный капитал
Общее количество фотографий с культурными тегами позволяет определить значение культурного капитала. Исследователи визуализировали районы Лондона и Нью-Йорка на графиках, аналогичных социальному пространству Бурдье, а также на интерактивных картах, и решили выяснить, какая из девяти основных категорий культурного капитала преобладает в данном конкретном районе.
Оказалось, что в обоих городах категория «перформанс» преобладает в центральных районах, тогда как многие периферийные районы выделяются категорией «архитектура», видимо, потому что другие виды культурной специализации развиты слабо.
Любопытно, как четко разграничиваются западная и восточная части Внутреннего Лондона: богатый и респектабельный Вест-энд со своими торгово-развлекательными кварталами и туристическими достопримечательностями отличается преобладанием «перформанс» (там же расположены крупнейшие театры), тогда как для индустриального Ист-энд более характерен дизайн.
Также в статье рассказываем, насколько культурные показатели коррелируют с успешностью района, и показываем графики: https://sysblok.ru/urban/kak-izmerit-gorodskuju-kulturu/
#urban
В 1980-х годах французский социолог Пьер Бурдье предложил теорию, согласно которой успех человека определяется соотношением его экономического и культурного капитала — два измерения социального пространства, схематично изображенного на рисунке ниже.
Исследовательская компания GoodCityLife решила проверить эту теорию на уровне городских районов, то есть выяснить, в какой степени успешность городского развития определяется не только экономическими, но и культурными факторами. Но как можно измерить такую нематериальную вещь как культура?
Мы уже писали об одном из проектов этой компании, суть которого состояла в создании карты запахов города на основе фотографий из социальных сетей. Здесь похожий принцип: берём несколько миллионов фотографий из Flickr с геопривязкой к одному из районов Лондона или Нью-Йорка и анализируем теги.
Культурный капитал
Общее количество фотографий с культурными тегами позволяет определить значение культурного капитала. Исследователи визуализировали районы Лондона и Нью-Йорка на графиках, аналогичных социальному пространству Бурдье, а также на интерактивных картах, и решили выяснить, какая из девяти основных категорий культурного капитала преобладает в данном конкретном районе.
Оказалось, что в обоих городах категория «перформанс» преобладает в центральных районах, тогда как многие периферийные районы выделяются категорией «архитектура», видимо, потому что другие виды культурной специализации развиты слабо.
Любопытно, как четко разграничиваются западная и восточная части Внутреннего Лондона: богатый и респектабельный Вест-энд со своими торгово-развлекательными кварталами и туристическими достопримечательностями отличается преобладанием «перформанс» (там же расположены крупнейшие театры), тогда как для индустриального Ист-энд более характерен дизайн.
Также в статье рассказываем, насколько культурные показатели коррелируют с успешностью района, и показываем графики: https://sysblok.ru/urban/kak-izmerit-gorodskuju-kulturu/
{kind=link}
Русский рэп через тематическое моделирование: о чем читает русскоговорящая хип-хоп сцена
#arts
«Русский рэпер» — словосочетание, ставшее если не ругательным, то как минимум пренебрежительным. Оно связано с целым букетом стереотипов. Представьте себе русского рэпера. Что вы видите? Человека в спортивках, окруженного «своими пацанами», или, может, парня с золотыми грилзами перед его новенькой машиной? Долой стереотипы! Время разобраться с тем, кто такие русские рэперы, и о чем они читают на самом деле.
Рэп как жанр зародился в 1970-ых годах в Южном Бронксе (район в Нью-Йорке). Первые рэперы — представители бедного чернокожего населения, поднимавшие в своем творчестве проблемы убийств, нищеты, употребления наркотиков. С тех пор рэп сильно изменился — из маленькой культуры бедного района Нью-Йорка он вырос в популярный жанр, приобретая в каждой стране свои особенности.
В Россию рэп пришел в конце 1980-ых и на заре своего существования многое заимствовал с западных образцов. Позже он обрел относительную самостоятельность как жанр, создавая свой стиль как в музыке, так и в смысловой нагрузке текстов.
В 2017 году рэпу удалось обойти по прослушиваниям рок, который больше 50 лет держал первенство музыкального олимпа, и стать самым популярным жанром музыки в мире. Рэп, будучи настолько популярным, может влиять на то, как сотни тысяч людей мыслят и каких ценностей придерживаются. Значит, важно разобраться, о чем он говорит.
Как мы изучали рэп
Перед анализом и извлечением транслируемых идей нам предстояло собрать данные. Для исследования мы взяли два сайта: ныне уже не существующий рэп-текст. рф и genius.com. Всего после удаления дубликатов и искаженных текстов для анализа осталось 11 396 уникальных текстов. Все тексты мы предобработали — удалили все символы, кроме кириллических, произвели лемматизация и удалили стоп-слова.
Основным методом анализа мы выбрали тематическое моделирование — набор методов, направленных на извлечение из большого корпуса текстов так называемых тем, то есть наборов связанных слов. «Системный Блокъ» уже рассказывал, как работает тематическое моделирование, а также как его можно делать в Tableau и в Mallet.
Мы использовали тематическую модель BigARTM, которая позволяет найти устойчивую базовую модель и, изменяя ее параметры, улучшать ее как с точки зрения интерпретации, так и с позиции формальных метрик. Результатом использования метода стала тематическая модель русского рэпа, состоящая из 17 тем.
О чем же читают рэперы
Нам удалось выделить следующие темы: «смерть», «природа», «житейские истории», «размышления о мире», «поиск и „становление“ себя», «(несчастная) любовь», «город», «создание и чтение рэпа», «мат», «разборки», «жизнь на районе», «вечеринки и секс», «(тяжелое) детство», «размышления о родине», «исполнение музыки», «успех» и «рэперские атрибуты».
Оказалось, что чаще всего рэперы читают о своем жизненном пути, о любви и о природе. Ниже прикреплена визуализация итоговой тематической модели.
Если высокая распространенность тем жизненного пути и любви кажется закономерной, то тема природы и ее высокая распространенность выглядит подозрительно. Но появление темы природы в тексте рэпера вовсе не означает, что рэпер решил прочитать о своей любимой сосне или речке. Просто рэперы часто используют образы природы как художественный прием, как метафору для описания обстановки. Так, например, в тексте Скриптонита «Положение» мы видим строчки:
Тихо, как падал снег, падал весь квартал, мы падали на полпути во сне в поисках нала.
Слово «снег» в данном случае «поднимет» вероятность встретить тему природы в тексте артиста, однако о природе как таковой речи здесь не идет.
Подробнее про каждую из тем рассказываем в нашей статье: https://sysblok.ru/arts/russkij-rjep-cherez-tematicheskoe-modelirovanie-o-chem-chitaet-russkogovorjashhaja-hip-hop-scena/
Антон Бойченко, Светлана Жучкова
#arts
«Русский рэпер» — словосочетание, ставшее если не ругательным, то как минимум пренебрежительным. Оно связано с целым букетом стереотипов. Представьте себе русского рэпера. Что вы видите? Человека в спортивках, окруженного «своими пацанами», или, может, парня с золотыми грилзами перед его новенькой машиной? Долой стереотипы! Время разобраться с тем, кто такие русские рэперы, и о чем они читают на самом деле.
Рэп как жанр зародился в 1970-ых годах в Южном Бронксе (район в Нью-Йорке). Первые рэперы — представители бедного чернокожего населения, поднимавшие в своем творчестве проблемы убийств, нищеты, употребления наркотиков. С тех пор рэп сильно изменился — из маленькой культуры бедного района Нью-Йорка он вырос в популярный жанр, приобретая в каждой стране свои особенности.
В Россию рэп пришел в конце 1980-ых и на заре своего существования многое заимствовал с западных образцов. Позже он обрел относительную самостоятельность как жанр, создавая свой стиль как в музыке, так и в смысловой нагрузке текстов.
В 2017 году рэпу удалось обойти по прослушиваниям рок, который больше 50 лет держал первенство музыкального олимпа, и стать самым популярным жанром музыки в мире. Рэп, будучи настолько популярным, может влиять на то, как сотни тысяч людей мыслят и каких ценностей придерживаются. Значит, важно разобраться, о чем он говорит.
Как мы изучали рэп
Перед анализом и извлечением транслируемых идей нам предстояло собрать данные. Для исследования мы взяли два сайта: ныне уже не существующий рэп-текст. рф и genius.com. Всего после удаления дубликатов и искаженных текстов для анализа осталось 11 396 уникальных текстов. Все тексты мы предобработали — удалили все символы, кроме кириллических, произвели лемматизация и удалили стоп-слова.
Основным методом анализа мы выбрали тематическое моделирование — набор методов, направленных на извлечение из большого корпуса текстов так называемых тем, то есть наборов связанных слов. «Системный Блокъ» уже рассказывал, как работает тематическое моделирование, а также как его можно делать в Tableau и в Mallet.
Мы использовали тематическую модель BigARTM, которая позволяет найти устойчивую базовую модель и, изменяя ее параметры, улучшать ее как с точки зрения интерпретации, так и с позиции формальных метрик. Результатом использования метода стала тематическая модель русского рэпа, состоящая из 17 тем.
О чем же читают рэперы
Нам удалось выделить следующие темы: «смерть», «природа», «житейские истории», «размышления о мире», «поиск и „становление“ себя», «(несчастная) любовь», «город», «создание и чтение рэпа», «мат», «разборки», «жизнь на районе», «вечеринки и секс», «(тяжелое) детство», «размышления о родине», «исполнение музыки», «успех» и «рэперские атрибуты».
Оказалось, что чаще всего рэперы читают о своем жизненном пути, о любви и о природе. Ниже прикреплена визуализация итоговой тематической модели.
Если высокая распространенность тем жизненного пути и любви кажется закономерной, то тема природы и ее высокая распространенность выглядит подозрительно. Но появление темы природы в тексте рэпера вовсе не означает, что рэпер решил прочитать о своей любимой сосне или речке. Просто рэперы часто используют образы природы как художественный прием, как метафору для описания обстановки. Так, например, в тексте Скриптонита «Положение» мы видим строчки:
Тихо, как падал снег, падал весь квартал, мы падали на полпути во сне в поисках нала.
Слово «снег» в данном случае «поднимет» вероятность встретить тему природы в тексте артиста, однако о природе как таковой речи здесь не идет.
Подробнее про каждую из тем рассказываем в нашей статье: https://sysblok.ru/arts/russkij-rjep-cherez-tematicheskoe-modelirovanie-o-chem-chitaet-russkogovorjashhaja-hip-hop-scena/
Антон Бойченко, Светлана Жучкова
{kind=link}
Исторические глобусы в 3D: покрутить может каждый
#arts #history
В Британской библиотеке хранится около четырёх миллионов картографических материалов. В основном это земные и астрономические глобусы, созданные западноевропейскими исследователями в 1600–1950 годах. Экспонаты очень хрупки, и до недавнего времени все они находились в закрытых хранилищах, не были доступны даже фотографии отдельных фрагментов, и только узкий круг исследователей имел к ним доступ.
В этом году Британская библиотека оцифровала эти старинные глобусы. Теперь онлайн-пользователь из любой точки мира может изучить более 30 картографических материалов XVII–XX веков. Посмотреть на трёхмерные модели глобусов можно на сайте библиотеки.
Также библиотека планирует создать 3D-модели трети всех материалов. Среди них 32 наиболее редкие и значимые карты. Например, доступным станет первый китайский глобус 1623 года.
3D-модель создается с помощью многокамерной съёмки в субмиллиметровом спектре: множество камер снимают материал кусочками размером меньше миллиметра. При этом используется метод фокус-стекинга (от англ. stacking — «складировать»): глобус фотографируют с разных точек фокусировки и собирают полученные кадры в объёмную модель. Это позволяет многократно увеличить резкость конечного изображения. С такой системой заметными становятся самые мелкие части карты, которые раньше были скрыты от человеческого глаза.
Атлас Кленке: двухметровый символ власти
В 1828 году в Британский музей из личной коллекции короля Георга III был доставлен Атлас Кленке. Его ширина достигает двух метров и это один из самых больших атласов мира. В книге — 41 атлас «золотого века» голландской картографии. Среди них находятся изображения двух полушарий, карты Европы, Азии, Африки, Северной и Южной Америки, отдельные материалы о Британии, Нидерландах, Италии и Украине.
Этот атлас голландский учёный и купец Иоганн Кленке подарил королю Карлу II в. 1600 году в честь восстановления в Англии монархии. В эпоху Возрождения книга считалась не только хранительницей человеческих знаний, но и символом власти. Поэтому такой атлас в руках короля показывал превосходство английской монархии. Карлу II подарок понравился, он разместил карту среди любимой коллекции, а Кленке посвятил в рыцари.
Атлас одним из первых был оцифрован Британской библиотекой. Сейчас его 3D-модель находится в открытом доступе на сайте учреждения.
Первые оцифровщики глобусов
Впервые старинные глобусы оцифровали работники американской библиотеки карт Ошера при университете Саутерн Мэн. Там также пользовались системой сканирования: для создания 3D моделей было сделано от 216 до 900 снимков карт. Самым известным экспонатом библиотеки сегодня является Небесный глобус Джованни Мария Кассини 1792 года.
https://sysblok.ru/arts/istoricheskie-globusy-v-3d-pokrutit-mozhet-kazhdyj/
Дарья Сотникова
#arts #history
В Британской библиотеке хранится около четырёх миллионов картографических материалов. В основном это земные и астрономические глобусы, созданные западноевропейскими исследователями в 1600–1950 годах. Экспонаты очень хрупки, и до недавнего времени все они находились в закрытых хранилищах, не были доступны даже фотографии отдельных фрагментов, и только узкий круг исследователей имел к ним доступ.
В этом году Британская библиотека оцифровала эти старинные глобусы. Теперь онлайн-пользователь из любой точки мира может изучить более 30 картографических материалов XVII–XX веков. Посмотреть на трёхмерные модели глобусов можно на сайте библиотеки.
Также библиотека планирует создать 3D-модели трети всех материалов. Среди них 32 наиболее редкие и значимые карты. Например, доступным станет первый китайский глобус 1623 года.
3D-модель создается с помощью многокамерной съёмки в субмиллиметровом спектре: множество камер снимают материал кусочками размером меньше миллиметра. При этом используется метод фокус-стекинга (от англ. stacking — «складировать»): глобус фотографируют с разных точек фокусировки и собирают полученные кадры в объёмную модель. Это позволяет многократно увеличить резкость конечного изображения. С такой системой заметными становятся самые мелкие части карты, которые раньше были скрыты от человеческого глаза.
Атлас Кленке: двухметровый символ власти
В 1828 году в Британский музей из личной коллекции короля Георга III был доставлен Атлас Кленке. Его ширина достигает двух метров и это один из самых больших атласов мира. В книге — 41 атлас «золотого века» голландской картографии. Среди них находятся изображения двух полушарий, карты Европы, Азии, Африки, Северной и Южной Америки, отдельные материалы о Британии, Нидерландах, Италии и Украине.
Этот атлас голландский учёный и купец Иоганн Кленке подарил королю Карлу II в. 1600 году в честь восстановления в Англии монархии. В эпоху Возрождения книга считалась не только хранительницей человеческих знаний, но и символом власти. Поэтому такой атлас в руках короля показывал превосходство английской монархии. Карлу II подарок понравился, он разместил карту среди любимой коллекции, а Кленке посвятил в рыцари.
Атлас одним из первых был оцифрован Британской библиотекой. Сейчас его 3D-модель находится в открытом доступе на сайте учреждения.
Первые оцифровщики глобусов
Впервые старинные глобусы оцифровали работники американской библиотеки карт Ошера при университете Саутерн Мэн. Там также пользовались системой сканирования: для создания 3D моделей было сделано от 216 до 900 снимков карт. Самым известным экспонатом библиотеки сегодня является Небесный глобус Джованни Мария Кассини 1792 года.
https://sysblok.ru/arts/istoricheskie-globusy-v-3d-pokrutit-mozhet-kazhdyj/
Дарья Сотникова
{kind=link}
«Если бы по Евангелию жили бездумные роботы, они были бы одноглазые, однорукие и одноногие»
#interview
Как сочетаются компьютерные технологии и Церковь? Зачем настоятелю монастыря алгоритм дистрибутивной семантики word2vec? Исследовать церковные тексты цифровыми методами — это вообще нормально? Системный Блокъ поговорил об этом с настоятелем Свято-Троицкого Данилова монастыря игуменом Пантелеимоном.
Отец Пантелеимон уже не первый год применяет методы компьютерной лингвистики в своей научной работе, рассказывает о дистрибутивной семантике студентам духовных учебных заведений, а также привлекает компьютерных лингвистов из Вышки к исследованию богослужебных текстов.
https://sysblok.ru/interviews/esli-by-po-evangeliju-zhili-bezdumnye-roboty-oni-byli-by-odnoglazye-odnorukie-i-odnonogie/
Даниил Скоринкин, Герман Пальчиков
#interview
Как сочетаются компьютерные технологии и Церковь? Зачем настоятелю монастыря алгоритм дистрибутивной семантики word2vec? Исследовать церковные тексты цифровыми методами — это вообще нормально? Системный Блокъ поговорил об этом с настоятелем Свято-Троицкого Данилова монастыря игуменом Пантелеимоном.
Отец Пантелеимон уже не первый год применяет методы компьютерной лингвистики в своей научной работе, рассказывает о дистрибутивной семантике студентам духовных учебных заведений, а также привлекает компьютерных лингвистов из Вышки к исследованию богослужебных текстов.
https://sysblok.ru/interviews/esli-by-po-evangeliju-zhili-bezdumnye-roboty-oni-byli-by-odnoglazye-odnorukie-i-odnonogie/
Даниил Скоринкин, Герман Пальчиков
{kind=link}
С миру по нитке — фельдшеру зарплата: финансирование здравоохранения в Москве в начале XX века
#history
История здравоохранения — составная часть социальной истории, которая приобрела большую актуальность во второй половине XX — начале XXI века. Для исследования этой темы применяются различные методы и подходы: от исследования политики в области здравоохранения на уровне центральных органов власти до микроисторического подхода, изучающего как люди болели, лечились и выздоравливали, и за чей счёт.
В этом исследовании анализируются статистические источники о финансировании. Основной источник — «Отчеты о состоянии народного здравия и организации врачебной помощи в России» управления главного врачебного инспектора, выходившие в 1904—1916 гг. Эти отчеты хранят сведения о численности населения и его динамике, заболеваемости и смертности населения, больничной инфраструктуре и численности врачей.
Вот, что удалось узнать о финансировании в целом:
— С 1902 по 1914 гг. количество средств, затраченных на здравоохранение, увеличилось практически в 3 раза.
— Финансирование растет более высокими темпами, нежели нагрузка на больничную инфраструктуру.
— И содержание врачей растет более высокими темпами, чем нагрузка на них. Динамику нагрузки и оплаты труда мед. персонала (в отн. к 1902 г.) смотрите на прикрепленном ниже графике.
— Подавляющую часть средств на здравоохранение выделял город — Московская городская управа.
— Доля правительственного финансирования невысока, а в 1906 году его уровень падает практически до нуля — вероятно, это связано с событиями Первой русской революции.
И о расходах на борьбу с эпидемиями:
— В 1907—1909 гг. в Москве было зафиксировано увеличивающееся число заражения инфекционными болезнями (в числе которых корь, скарлатина, коклюш, грипп и др.). Пик эпидемии пришелся на 1909 год, когда число зараженных превысило 400 тысяч.
— В 1909 году расходы на здравоохранение достигли рекордной отметки в 328 тысяч рублей, что на 78% больше, чем в предыдущем году.
— Однако уже в следующем году содержание борьбы с эпидемиями снизилось до 20 тысяч рублей (-94%!), и это снижение несоразмерно с уменьшением заболеваний заразными болезнями на 15%.
— В 1912–1914 годах содержание борьбы с эпидемиями вновь увеличилось — одновременно с повышением и заболеваемости заразными болезнями.
В начале ХХ века финансирование здравоохранения росло опережающими темпами относительно нагрузки на него. Можно заметить определенную нарастающую тенденцию — осознание общественностью необходимости поддерживать уровень общественного здоровья. Из этого следует, что финансирование здравоохранения подвержено сильному антропогенному фактору. Его уровень зависит от мнения органов, в чью компетенцию входит определение бюджета, в том числе медицинского.
О том, как выбирались источники, как велась работа с данными и как разрабатывалась методика исследования, читайте в нашей статье. А также смотрите графики, по которым были сделаны выводы.
https://sysblok.ru/history/s-miru-po-nitke-feldsheru-zarplata-finansirovanie-zdravoohranenija-v-moskve-v-nachale-xx-veka/
Евгений Данилов
#history
История здравоохранения — составная часть социальной истории, которая приобрела большую актуальность во второй половине XX — начале XXI века. Для исследования этой темы применяются различные методы и подходы: от исследования политики в области здравоохранения на уровне центральных органов власти до микроисторического подхода, изучающего как люди болели, лечились и выздоравливали, и за чей счёт.
В этом исследовании анализируются статистические источники о финансировании. Основной источник — «Отчеты о состоянии народного здравия и организации врачебной помощи в России» управления главного врачебного инспектора, выходившие в 1904—1916 гг. Эти отчеты хранят сведения о численности населения и его динамике, заболеваемости и смертности населения, больничной инфраструктуре и численности врачей.
Вот, что удалось узнать о финансировании в целом:
— С 1902 по 1914 гг. количество средств, затраченных на здравоохранение, увеличилось практически в 3 раза.
— Финансирование растет более высокими темпами, нежели нагрузка на больничную инфраструктуру.
— И содержание врачей растет более высокими темпами, чем нагрузка на них. Динамику нагрузки и оплаты труда мед. персонала (в отн. к 1902 г.) смотрите на прикрепленном ниже графике.
— Подавляющую часть средств на здравоохранение выделял город — Московская городская управа.
— Доля правительственного финансирования невысока, а в 1906 году его уровень падает практически до нуля — вероятно, это связано с событиями Первой русской революции.
И о расходах на борьбу с эпидемиями:
— В 1907—1909 гг. в Москве было зафиксировано увеличивающееся число заражения инфекционными болезнями (в числе которых корь, скарлатина, коклюш, грипп и др.). Пик эпидемии пришелся на 1909 год, когда число зараженных превысило 400 тысяч.
— В 1909 году расходы на здравоохранение достигли рекордной отметки в 328 тысяч рублей, что на 78% больше, чем в предыдущем году.
— Однако уже в следующем году содержание борьбы с эпидемиями снизилось до 20 тысяч рублей (-94%!), и это снижение несоразмерно с уменьшением заболеваний заразными болезнями на 15%.
— В 1912–1914 годах содержание борьбы с эпидемиями вновь увеличилось — одновременно с повышением и заболеваемости заразными болезнями.
В начале ХХ века финансирование здравоохранения росло опережающими темпами относительно нагрузки на него. Можно заметить определенную нарастающую тенденцию — осознание общественностью необходимости поддерживать уровень общественного здоровья. Из этого следует, что финансирование здравоохранения подвержено сильному антропогенному фактору. Его уровень зависит от мнения органов, в чью компетенцию входит определение бюджета, в том числе медицинского.
О том, как выбирались источники, как велась работа с данными и как разрабатывалась методика исследования, читайте в нашей статье. А также смотрите графики, по которым были сделаны выводы.
https://sysblok.ru/history/s-miru-po-nitke-feldsheru-zarplata-finansirovanie-zdravoohranenija-v-moskve-v-nachale-xx-veka/
Евгений Данилов
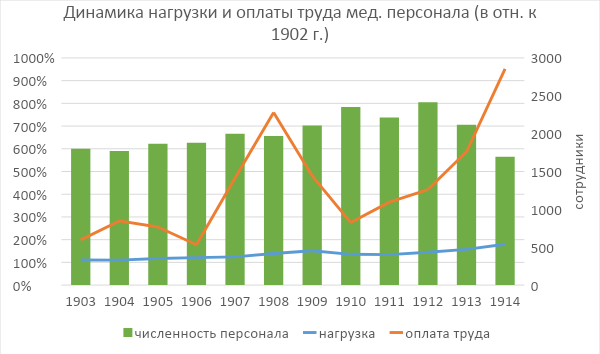{kind=link}
Барочный интерактив: что видно на рентгенах скульптур Аккермана
#digitalheritage #arts
Кристиан Аккерман — эстонский скульптор эпохи барокко. Кристиана считали скандальным типом, потому что он нарушал христианские обычаи того времени: жена Аккермана родила ребенка слишком скоро после свадьбы. Также, Аккерман понимал свое творческое превосходство и боролся с гильдейскими мастерами за право работать в качестве независимого мастера, что считалось нонсенсом в то время.
Разбираемся в тонкостях мультимедийного проекта и технологиях исследования.
3D-проектирование
Чтобы создать 3D-проекцию, сначала делают лазерное сканирование, в результате которого бесконтактно определяется положение миллионов точек, формирующих цифровой макет скульптуры. Если этих точек не хватает, исследователи сканируют «сложные» части поверхности скульптуры специальным метрологическим зеркалом.
Затем все данные досконально изучаются, сводятся в единую систему координат и редактируются. В частности, из макета убираются все грубые неточности. В итоге получается точная полигональная модель — четкая 3D-схема скульптуры с большим количеством полигонов (многоугольников).
Мультимедийные 3D-модели предоставляют возможность для тщательного осмотра и сравнения скульптур. Ниже прикрепляем 3D-модель скульптуры «Христос Непобедимый».
Рентгеновская съемка
Цифровой рентгеновский аппарат подходит для исследований различных предметов искусства от живописи до скульптуры. Это компактное портативное устройство, которое можно перевозить с собой, ведь многие произведения искусства не подлежат перевозке или даже небольшим перемещениям в пространстве.
Как это работает: ослабленные рентгеновские лучи проходят через скульптуру, а полученное изображение регистрируется и попадает на специальную пленку. Когда свет проходит сквозь материал, начинается образование пучков излучения, которые после рассеиваются и «замораживаются» на пленке.
Цифровая рентгенография позволяет увидеть внутренний каркас произведений искусства, разглядеть все скрытые составляющие и проанализировать режимы работы мастера. Также эта процедура помогает выявить скрытые дефекты, трещины, сколы, а также найти внутренние стержни предмета, металлические или деревянные.
Например, рентгеновский снимок скульптуры Аккермана «Святой Апостол Петр» показал, что в основе фигуры находятся блоки липы, которые были склеены и укреплены кузнечными гвоздями еще до начала резьбы.
Исследование в ультрафиолетовом излучении
УФ-анализ позволяет увидеть интегральное свечение защитных слоев (концентрацию минералов в покрытии), красочного слоя, грунта, да и вообще каждого компонента в отдельности. С помощью УФ-анализа можно узнать, в каком состоянии находится произведение: был ли утрачен красочный слой и грунт, или их вовсе не было, насколько велика глубина защитных слоев. Также УФ-анализ выявляет не только цвет, но и плотность, яркость и равномерность нанесения красок.
Выяснилось, что практически все скульптуры Аккермана первоначально имели цвет. Лица многих фигур были розовыми, глаза, брови и волосы — коричневыми или светлыми, губы — красными, а одеяния — позолоченными. Также исследователи обнажили полихромию «Иоанна Богослова» до половины его лица: на лице была нарисована улыбка, а взгляд, обращенный к небесам, был «открыт» с помощью краски.
Результаты
Результаты проведенного исследования находятся в свободном доступе. На веб-платформе проекта можно найти интерактивные 3D-модели, рентгеновские и УФ-снимки резных скульптур Аккермана, а также интерактивные таймлайн и карту, где посетители веб-портала могут выбрать интересную им скульптуру или место ее нахождения и узнать о ней более подробную информацию.
https://sysblok.ru/digital-heritage/barochnyj-interaktiv-chto-vidno-na-rentgenah-skulptur-akkermana/
#digitalheritage #arts
Кристиан Аккерман — эстонский скульптор эпохи барокко. Кристиана считали скандальным типом, потому что он нарушал христианские обычаи того времени: жена Аккермана родила ребенка слишком скоро после свадьбы. Также, Аккерман понимал свое творческое превосходство и боролся с гильдейскими мастерами за право работать в качестве независимого мастера, что считалось нонсенсом в то время.
Разбираемся в тонкостях мультимедийного проекта и технологиях исследования.
3D-проектирование
Чтобы создать 3D-проекцию, сначала делают лазерное сканирование, в результате которого бесконтактно определяется положение миллионов точек, формирующих цифровой макет скульптуры. Если этих точек не хватает, исследователи сканируют «сложные» части поверхности скульптуры специальным метрологическим зеркалом.
Затем все данные досконально изучаются, сводятся в единую систему координат и редактируются. В частности, из макета убираются все грубые неточности. В итоге получается точная полигональная модель — четкая 3D-схема скульптуры с большим количеством полигонов (многоугольников).
Мультимедийные 3D-модели предоставляют возможность для тщательного осмотра и сравнения скульптур. Ниже прикрепляем 3D-модель скульптуры «Христос Непобедимый».
Рентгеновская съемка
Цифровой рентгеновский аппарат подходит для исследований различных предметов искусства от живописи до скульптуры. Это компактное портативное устройство, которое можно перевозить с собой, ведь многие произведения искусства не подлежат перевозке или даже небольшим перемещениям в пространстве.
Как это работает: ослабленные рентгеновские лучи проходят через скульптуру, а полученное изображение регистрируется и попадает на специальную пленку. Когда свет проходит сквозь материал, начинается образование пучков излучения, которые после рассеиваются и «замораживаются» на пленке.
Цифровая рентгенография позволяет увидеть внутренний каркас произведений искусства, разглядеть все скрытые составляющие и проанализировать режимы работы мастера. Также эта процедура помогает выявить скрытые дефекты, трещины, сколы, а также найти внутренние стержни предмета, металлические или деревянные.
Например, рентгеновский снимок скульптуры Аккермана «Святой Апостол Петр» показал, что в основе фигуры находятся блоки липы, которые были склеены и укреплены кузнечными гвоздями еще до начала резьбы.
Исследование в ультрафиолетовом излучении
УФ-анализ позволяет увидеть интегральное свечение защитных слоев (концентрацию минералов в покрытии), красочного слоя, грунта, да и вообще каждого компонента в отдельности. С помощью УФ-анализа можно узнать, в каком состоянии находится произведение: был ли утрачен красочный слой и грунт, или их вовсе не было, насколько велика глубина защитных слоев. Также УФ-анализ выявляет не только цвет, но и плотность, яркость и равномерность нанесения красок.
Выяснилось, что практически все скульптуры Аккермана первоначально имели цвет. Лица многих фигур были розовыми, глаза, брови и волосы — коричневыми или светлыми, губы — красными, а одеяния — позолоченными. Также исследователи обнажили полихромию «Иоанна Богослова» до половины его лица: на лице была нарисована улыбка, а взгляд, обращенный к небесам, был «открыт» с помощью краски.
Результаты
Результаты проведенного исследования находятся в свободном доступе. На веб-платформе проекта можно найти интерактивные 3D-модели, рентгеновские и УФ-снимки резных скульптур Аккермана, а также интерактивные таймлайн и карту, где посетители веб-портала могут выбрать интересную им скульптуру или место ее нахождения и узнать о ней более подробную информацию.
https://sysblok.ru/digital-heritage/barochnyj-interaktiv-chto-vidno-na-rentgenah-skulptur-akkermana/
{kind=link}