
Виртуальный хор Эрика Витакера
#musicology
Более десяти лет назад девушка по имени Бритлин Лоси выложила на YouTube видео, на котором она исполняет партию сопрано из композиции Эрика Витакера «Sleep». Свое пение она предварила теплым вступительным словом в адрес композитора, где признается в любви к его творчеству.
Видео тронуло Витакера и навело его на мысль обратиться к людям со следующим предложением: записать отдельные партии из его сочинений для того, чтобы потом свести их в единый файл. Он создал видео, в котором рассказал концепцию своего сочинения под названием «Lux Aurumque», а затем продирижировал для будущих исполнителей под аккомпанемент фортепиано — чтобы певцы могли делать свои записи, используя эту «минусовку».
Версии 1.0 — 4.0
На просьбу отозвалось множество людей. Первый «Виртуальный хор» (2010) включал 185 певцов из 12 стран.
Проект всем так понравился, что вскоре был анонсирован «Виртуальный хор 2.0» — на композицию «Sleep» (ту самую, которую пела в фанатском видео Бритлин Лоси). Это видео, опубликованное в 2011 году, включало на порядок больше участников — 2000 человек из 58 стран.
В дальнейшем количество участников все увеличивалось. В «Виртуальном хоре 3.0» (2012), исполняющем произведение «Water Night» приняло участие около 4000 музыкантов из 73 стран.
В версии 4.0 (2013, композиция «Fly to Paradise») смонтированы 8409 видеозаписей от 5905 человек из 101 страны.
Версия Live
Разумеется, невозможно было лишь до бесконечности увеличивать количество участников. Тогда Эрик Витакер решил устроить живое выступление «виртуального хора». Для этого проекта он сделал новую редакцию своего сочинения «Cloudburst». Это было необходимо из-за того, что сигнал по скайпу передается с задержкой почти в секунду. Витакер использовал это запаздывание как художественный прием.
Премьера «Виртуального хора. Live» прошла в феврале 2013 года во время очередного выступления Эрика Витакера на знаменитой конференции TED. На сцене присутствовал живой сводный хор, состоящий из трех университетских коллективов и нескольких любительских хоров. К реальным певцам в процессе исполнения присоединились по скайпу еще 30 музыкантов из разных стран мира. Их лица транслировались на экране за спинами живого хора.
Версия 5.0. Deep Field
Проект «Виртуальный хор 5.0», старт которого был анонсирован в 2018 году, предлагал исполнить произведение под названием «Deep Field». На его создание Витакера вдохновил космический телескоп «Хаббл» и сделанное с его помощью открытие — изображение небольшой области в созвездии Большой медведицы, получившее название Deep Field.
Проект разросся далеко за пределы очередного «виртуального хора». В настоящий момент существуют фильм IMAX 4k «Deep Field: The Impossible Magnitude of the Universe», а также версия для живого концертного исполнения, в котором задействованы реальные оркестр и хор (Royal Philharmonic Orchestra и Eric Whitacre Singers), Кроме того, есть виртуальный хор 5.0 (см. видео ниже), состоящий из 8000 певцов из 120 стран. Выступление сопровождается проекцией изображений области Deep Field.
Как опыт Эрика Витакера может помочь нам в 2020-м?
В одном из интервью композитор признается: «для меня петь вместе, музицировать вместе — это основополагающий человеческий опыт, и мне нравится идея, что технологии могут объединить людей со всего мира и дать им возможность попробовать что-то, выходящее за пределы их обычной жизни».
Сейчас, когда обычная жизнь для многих сузилась до пределов их квартир или домов, самое время подробнее изучить многолетний опыт Эрика Витакера и, возможно, найти в нем вдохновение, чтобы продвинуться еще дальше в соединении творчества и технологий.
Василиса Александрова
https://sysblok.ru/musicology/ideja-dlja-karantina-virtualnyj-hor/
#musicology
Более десяти лет назад девушка по имени Бритлин Лоси выложила на YouTube видео, на котором она исполняет партию сопрано из композиции Эрика Витакера «Sleep». Свое пение она предварила теплым вступительным словом в адрес композитора, где признается в любви к его творчеству.
Видео тронуло Витакера и навело его на мысль обратиться к людям со следующим предложением: записать отдельные партии из его сочинений для того, чтобы потом свести их в единый файл. Он создал видео, в котором рассказал концепцию своего сочинения под названием «Lux Aurumque», а затем продирижировал для будущих исполнителей под аккомпанемент фортепиано — чтобы певцы могли делать свои записи, используя эту «минусовку».
Версии 1.0 — 4.0
На просьбу отозвалось множество людей. Первый «Виртуальный хор» (2010) включал 185 певцов из 12 стран.
Проект всем так понравился, что вскоре был анонсирован «Виртуальный хор 2.0» — на композицию «Sleep» (ту самую, которую пела в фанатском видео Бритлин Лоси). Это видео, опубликованное в 2011 году, включало на порядок больше участников — 2000 человек из 58 стран.
В дальнейшем количество участников все увеличивалось. В «Виртуальном хоре 3.0» (2012), исполняющем произведение «Water Night» приняло участие около 4000 музыкантов из 73 стран.
В версии 4.0 (2013, композиция «Fly to Paradise») смонтированы 8409 видеозаписей от 5905 человек из 101 страны.
Версия Live
Разумеется, невозможно было лишь до бесконечности увеличивать количество участников. Тогда Эрик Витакер решил устроить живое выступление «виртуального хора». Для этого проекта он сделал новую редакцию своего сочинения «Cloudburst». Это было необходимо из-за того, что сигнал по скайпу передается с задержкой почти в секунду. Витакер использовал это запаздывание как художественный прием.
Премьера «Виртуального хора. Live» прошла в феврале 2013 года во время очередного выступления Эрика Витакера на знаменитой конференции TED. На сцене присутствовал живой сводный хор, состоящий из трех университетских коллективов и нескольких любительских хоров. К реальным певцам в процессе исполнения присоединились по скайпу еще 30 музыкантов из разных стран мира. Их лица транслировались на экране за спинами живого хора.
Версия 5.0. Deep Field
Проект «Виртуальный хор 5.0», старт которого был анонсирован в 2018 году, предлагал исполнить произведение под названием «Deep Field». На его создание Витакера вдохновил космический телескоп «Хаббл» и сделанное с его помощью открытие — изображение небольшой области в созвездии Большой медведицы, получившее название Deep Field.
Проект разросся далеко за пределы очередного «виртуального хора». В настоящий момент существуют фильм IMAX 4k «Deep Field: The Impossible Magnitude of the Universe», а также версия для живого концертного исполнения, в котором задействованы реальные оркестр и хор (Royal Philharmonic Orchestra и Eric Whitacre Singers), Кроме того, есть виртуальный хор 5.0 (см. видео ниже), состоящий из 8000 певцов из 120 стран. Выступление сопровождается проекцией изображений области Deep Field.
Как опыт Эрика Витакера может помочь нам в 2020-м?
В одном из интервью композитор признается: «для меня петь вместе, музицировать вместе — это основополагающий человеческий опыт, и мне нравится идея, что технологии могут объединить людей со всего мира и дать им возможность попробовать что-то, выходящее за пределы их обычной жизни».
Сейчас, когда обычная жизнь для многих сузилась до пределов их квартир или домов, самое время подробнее изучить многолетний опыт Эрика Витакера и, возможно, найти в нем вдохновение, чтобы продвинуться еще дальше в соединении творчества и технологий.
Василиса Александрова
https://sysblok.ru/musicology/ideja-dlja-karantina-virtualnyj-hor/
YouTube
Deep Field: The Impossible Magnitude of our Universe
Eric Whitacre's 'Deep Field: The Impossible Magnitude of our Universe' is a unique film and musical experience inspired by one of the most important scientific discoveries of all time: the Hubble Telescope's Deep Field image.
Download now from Apple: LINK…
Download now from Apple: LINK…
Как сделать чат-бота с помощью DeepPavlov
#nlp
Сегодня уже мало кому нужно объяснять, что такое чат-боты. Мы неизбежно сталкиваемся с ними, когда хотим открыть вклад в банке, уточнить тариф у мобильного оператора или просто заказать пиццу.
Чат-боты вызывают интерес у бизнеса, ищущего способы сократить расходы на колл-центры и улучшить взаимодействие с клиентами. Кто-то идет дальше — и создает Алису, способную болтать на разные темы, развлекая вас, когда вам скучно, а значит, повышая вашу лояльность.
Наряду с разработкой таких ботов-гигантов, как Алекса, Сири и Алиса, за которыми стоят крупнейшие IT-корпорации, появляются и доступные инструменты для создания своих небольших, но полноценных целеориентированных чат-ботов. Отличным примером этого служат инструменты из библиотеки DeepPavlov от группы разработчиков на базе МФТИ.
Как устроены чат-боты
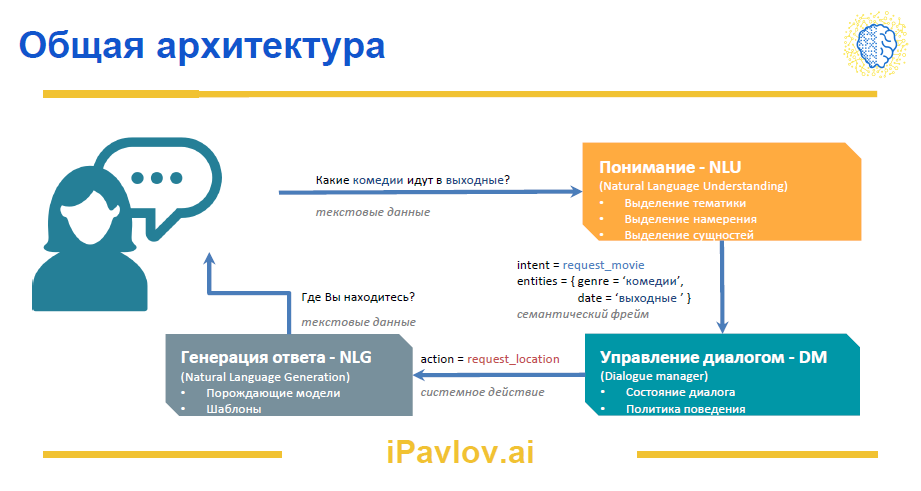
На прикрепленной схеме — общая архитектура диалоговой системы чат-бота. В статье рассказываем обо всех ее компонентах и отвечаем на вопросы:
- как научить бота понимать пользователя?
- как управлять диалогом?
- как генерировать сообщения?
-как инструменты DeepPavlov могут упростить создание бота?
Полезные инструменты DeepPavlov
- предобученные модели нейронных сетей на основе BERT для классификации входящего сообщения, то есть определения домена — предметной области — разговора и интента — намерения — пользователя.
- модели для решения задачи NER — распознавания именованных сущностей, — стабильно показывающие высокое качество для русского языка (F1 score до 98.1).
- специальный компонент slotfiller в пайплайне распознавания именованных сущностей — для вставки распознанных сущностей в слоты.
- удобный спеллчекинг, помогающий справляться с опечатками в сообщениях пользователей и не плодить лишних сущностей — все вариации написания в рамках определенного порога приводятся к одному слову.
- несколько доступных конфигураций для целеориентированных ботов — для решения задач управления диалогом.
Подробный рассказ по ссылке: https://sysblok.ru/nlp/trudno-byt-botom-kak-sdelat-chatbota-s-pomoshhju-deeppavlov/
#nlp
Сегодня уже мало кому нужно объяснять, что такое чат-боты. Мы неизбежно сталкиваемся с ними, когда хотим открыть вклад в банке, уточнить тариф у мобильного оператора или просто заказать пиццу.
Чат-боты вызывают интерес у бизнеса, ищущего способы сократить расходы на колл-центры и улучшить взаимодействие с клиентами. Кто-то идет дальше — и создает Алису, способную болтать на разные темы, развлекая вас, когда вам скучно, а значит, повышая вашу лояльность.
Наряду с разработкой таких ботов-гигантов, как Алекса, Сири и Алиса, за которыми стоят крупнейшие IT-корпорации, появляются и доступные инструменты для создания своих небольших, но полноценных целеориентированных чат-ботов. Отличным примером этого служат инструменты из библиотеки DeepPavlov от группы разработчиков на базе МФТИ.
Как устроены чат-боты
На прикрепленной схеме — общая архитектура диалоговой системы чат-бота. В статье рассказываем обо всех ее компонентах и отвечаем на вопросы:
- как научить бота понимать пользователя?
- как управлять диалогом?
- как генерировать сообщения?
-как инструменты DeepPavlov могут упростить создание бота?
Полезные инструменты DeepPavlov
- предобученные модели нейронных сетей на основе BERT для классификации входящего сообщения, то есть определения домена — предметной области — разговора и интента — намерения — пользователя.
- модели для решения задачи NER — распознавания именованных сущностей, — стабильно показывающие высокое качество для русского языка (F1 score до 98.1).
- специальный компонент slotfiller в пайплайне распознавания именованных сущностей — для вставки распознанных сущностей в слоты.
- удобный спеллчекинг, помогающий справляться с опечатками в сообщениях пользователей и не плодить лишних сущностей — все вариации написания в рамках определенного порога приводятся к одному слову.
- несколько доступных конфигураций для целеориентированных ботов — для решения задач управления диалогом.
Подробный рассказ по ссылке: https://sysblok.ru/nlp/trudno-byt-botom-kak-sdelat-chatbota-s-pomoshhju-deeppavlov/
{kind=link}
Кого учили иезуиты
#history
Орден иезуитов был передовым отрядом католической церкви в деле сопротивления Реформации. Иезуиты создали сеть школ и университетов по всей Европе. Получив исключительно высокое для своего времени образование, выпускники этих учебных заведений вели успешную работу по возвращению «заблудшие душ» в лоно Католической церкви.
Специально для «Системного Блока» историк Дмитрий Жаров рассказывает, что можно узнать, если создать и проанализировать базу данных студентов, которых обучал орден.
Откуда мы знаем об этих студентах
Группа, выбранная для анализа, — это студенты иезуитского университета города Грац (Штирия, современная Австрийская республика), проходившие обучение в период между 1586 и 1599 годами.
Источниками знаний об этих студентах послужили общеуниверситетские матрикулы (списки, куда вносили имена новых студентов) Грацского университета, а также список («Каталог») воспитанников особого пансиона для бедных студентов, который был аффилирован с университетом.
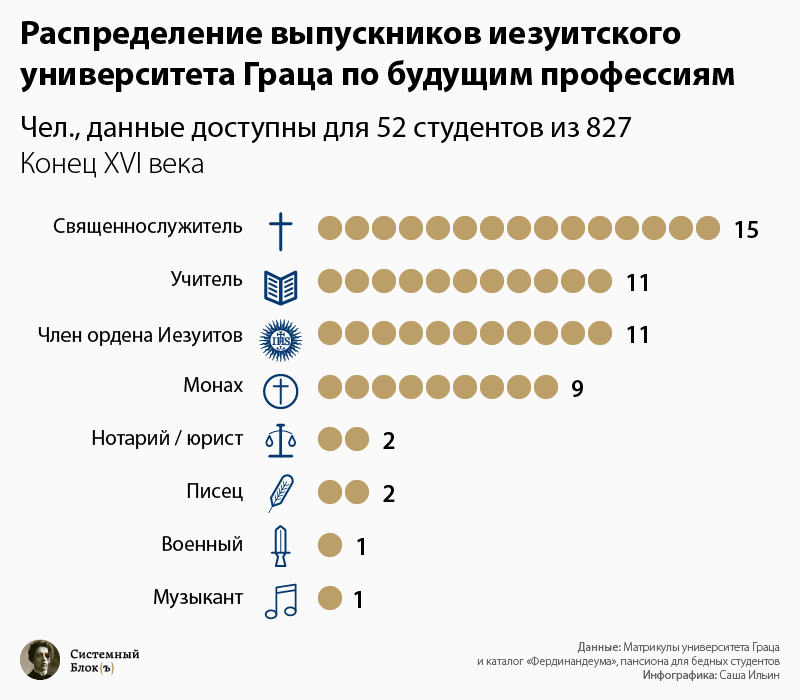
Эти источники дают нам информацию о сотнях студентов, а их крайне формализованный вид позволяет создать базу данных и применять ее как исследовательский инструмент. Сделать это можно с помощью традиционной СУБД Microsoft Access. Всего в базу вошли 827 студентов.
Коллективный портрет студенчества
У иезуитов учились главным образом люди незнатного происхождения, однако достаточно богатые для того, чтобы оплатить связанные с обучением расходы.
Большая часть студентов приезжала в Грац из австрийских, немецких и венгерских земель, однако были и отдельные личности, которые так хотели учиться в этом университете, что добирались до него из Франции, Италии, Англии и даже Литвы.
Средний возраст «абитуриента» был фактически таким же, как и сегодня — 18 лет, однако разброс в значениях был значительным: от 14 до 30 лет.
После окончания университета большая часть выпускников, сохранивших связь с alma mater, выбирала себе профессии, необходимые для утверждения католицизма на местах: священники, учителя. Некоторые становились монахами или сами вступали в орден иезуитов и продолжали там карьеру.
Нетипичные студенты
Среди выпускников встречаются и абсолютно исключительные личности, чьи судьбы явно не вписываются в «коллективную биографию». Так, например, в 1589 г. в Грац из далекой Померании (побережье Балтийского моря) прибыл 24-летний Алекс Неандр. До этого он успел отучиться в университете Франкфурта-на-Одере. Проучившись в Граце всего 4 месяца, он направился дальше, в сторону Кёльна, крупнейшего католического центра Германии.
В университете параллельно с учебой Алекс зарабатывал деньги, выступая как певец и, возможно, музыкант. Неандр за время своего недолгого обучения сумел произвести хорошее впечатление на своих наставников. Об этом нам говорит короткая приписка, которую составители матрикул сделали в графе со сведениями об Алексе: «Дай Бог ему доброй дороги». Никто другой из уходящих студентов не удостоился такого личного пожелания.
До Кёльна Неандр так и не дошел, а остановился в городе Вюрцбург во Франконии (это примерно на полпути от Граца до Кёльна), который был древним епископским центром. В Вюрцбурге бывший студент сделал блестящую и, что особенно интересно, музыкальную карьеру. Сначала он стал префектом музыки в городской иезуитской гимназии, а затем получил место музыкального директора в городском кафедральном соборе, где и оставался до своей смерти в 1605 г. Алекс Неандр был в католической среде достаточно известным композитором: он сочинил более 100 мотетов (особый музыкальный жанр) на духовную тему.
Подробный рассказ с инфографикой — по ссылке: https://sysblok.ru/history/kogo-uchili-iezuity/
#history
Орден иезуитов был передовым отрядом католической церкви в деле сопротивления Реформации. Иезуиты создали сеть школ и университетов по всей Европе. Получив исключительно высокое для своего времени образование, выпускники этих учебных заведений вели успешную работу по возвращению «заблудшие душ» в лоно Католической церкви.
Специально для «Системного Блока» историк Дмитрий Жаров рассказывает, что можно узнать, если создать и проанализировать базу данных студентов, которых обучал орден.
Откуда мы знаем об этих студентах
Группа, выбранная для анализа, — это студенты иезуитского университета города Грац (Штирия, современная Австрийская республика), проходившие обучение в период между 1586 и 1599 годами.
Источниками знаний об этих студентах послужили общеуниверситетские матрикулы (списки, куда вносили имена новых студентов) Грацского университета, а также список («Каталог») воспитанников особого пансиона для бедных студентов, который был аффилирован с университетом.
Эти источники дают нам информацию о сотнях студентов, а их крайне формализованный вид позволяет создать базу данных и применять ее как исследовательский инструмент. Сделать это можно с помощью традиционной СУБД Microsoft Access. Всего в базу вошли 827 студентов.
Коллективный портрет студенчества
У иезуитов учились главным образом люди незнатного происхождения, однако достаточно богатые для того, чтобы оплатить связанные с обучением расходы.
Большая часть студентов приезжала в Грац из австрийских, немецких и венгерских земель, однако были и отдельные личности, которые так хотели учиться в этом университете, что добирались до него из Франции, Италии, Англии и даже Литвы.
Средний возраст «абитуриента» был фактически таким же, как и сегодня — 18 лет, однако разброс в значениях был значительным: от 14 до 30 лет.
После окончания университета большая часть выпускников, сохранивших связь с alma mater, выбирала себе профессии, необходимые для утверждения католицизма на местах: священники, учителя. Некоторые становились монахами или сами вступали в орден иезуитов и продолжали там карьеру.
Нетипичные студенты
Среди выпускников встречаются и абсолютно исключительные личности, чьи судьбы явно не вписываются в «коллективную биографию». Так, например, в 1589 г. в Грац из далекой Померании (побережье Балтийского моря) прибыл 24-летний Алекс Неандр. До этого он успел отучиться в университете Франкфурта-на-Одере. Проучившись в Граце всего 4 месяца, он направился дальше, в сторону Кёльна, крупнейшего католического центра Германии.
В университете параллельно с учебой Алекс зарабатывал деньги, выступая как певец и, возможно, музыкант. Неандр за время своего недолгого обучения сумел произвести хорошее впечатление на своих наставников. Об этом нам говорит короткая приписка, которую составители матрикул сделали в графе со сведениями об Алексе: «Дай Бог ему доброй дороги». Никто другой из уходящих студентов не удостоился такого личного пожелания.
До Кёльна Неандр так и не дошел, а остановился в городе Вюрцбург во Франконии (это примерно на полпути от Граца до Кёльна), который был древним епископским центром. В Вюрцбурге бывший студент сделал блестящую и, что особенно интересно, музыкальную карьеру. Сначала он стал префектом музыки в городской иезуитской гимназии, а затем получил место музыкального директора в городском кафедральном соборе, где и оставался до своей смерти в 1605 г. Алекс Неандр был в католической среде достаточно известным композитором: он сочинил более 100 мотетов (особый музыкальный жанр) на духовную тему.
Подробный рассказ с инфографикой — по ссылке: https://sysblok.ru/history/kogo-uchili-iezuity/
{kind=link}
Разделить цену победы: большое исследование призыва в ВОВ от команды «Системного Блока»
#history #research
В истории Войны много неизвестных и спорных мест. К сожалению, до сих пор многие данные засекречены, ведутся споры о количестве погибших, многие до сих пор не знают, чем закончился путь их дедушки или отца. Мы предлагаем посмотреть на историю ВОВ через историю призыва и опираться не на единичные источники, а сразу на миллионы свидетельств.
Команда «Системного Блока» провела для вас собственное исследование — мы изучили 26 миллионов карточек военно-пересыльных пунктов, через которые солдаты направлялись на фронт. Сквозь призму призыва нам удается посмотреть на историю участия в войне отдельных республик и восстановить хронологию событий.
Исследование динамики призыва позволило выделить характерные портреты призыва в республиках и объединить схожие республики в группы. Призыв во многом схож в РСФСР, Казахстане и Киргизии. Совершенно по-другому выглядит призыв в республиках, которые были оккупированы в ходе войны — всю историю оккупации и освобождения можно видеть через графики призыва. В Грузинской, Азербайджанской и Армянской ССР активный призыв ведется до 1943 года, а для республик Средней Азии характерен особый вид призыва — трудовой. И все эти явления видны в данных.
Обработанные данные мы выложили в наш открытый репозиторий, они доступны исследователям. Мы выступаем за открытость всех общественно важных данных и материалов по Великой Отечественной войне и XX веку в целом.
Полный текст исследования и интерактивные визуализации по ссылке:
https://sysblok.ru/history/neizvestnyj-soldat/
#history #research
В истории Войны много неизвестных и спорных мест. К сожалению, до сих пор многие данные засекречены, ведутся споры о количестве погибших, многие до сих пор не знают, чем закончился путь их дедушки или отца. Мы предлагаем посмотреть на историю ВОВ через историю призыва и опираться не на единичные источники, а сразу на миллионы свидетельств.
Команда «Системного Блока» провела для вас собственное исследование — мы изучили 26 миллионов карточек военно-пересыльных пунктов, через которые солдаты направлялись на фронт. Сквозь призму призыва нам удается посмотреть на историю участия в войне отдельных республик и восстановить хронологию событий.
Исследование динамики призыва позволило выделить характерные портреты призыва в республиках и объединить схожие республики в группы. Призыв во многом схож в РСФСР, Казахстане и Киргизии. Совершенно по-другому выглядит призыв в республиках, которые были оккупированы в ходе войны — всю историю оккупации и освобождения можно видеть через графики призыва. В Грузинской, Азербайджанской и Армянской ССР активный призыв ведется до 1943 года, а для республик Средней Азии характерен особый вид призыва — трудовой. И все эти явления видны в данных.
Обработанные данные мы выложили в наш открытый репозиторий, они доступны исследователям. Мы выступаем за открытость всех общественно важных данных и материалов по Великой Отечественной войне и XX веку в целом.
Полный текст исследования и интерактивные визуализации по ссылке:
https://sysblok.ru/history/neizvestnyj-soldat/
{kind=link}
Картирование криминала и рост средневековых городов: зачем историкам ГИСы
#society #history
Мы пользуемся геоинформационными системами (ГИСами) каждый день, когда лезем в карты на телефоне или едем куда-то по навигатору. А зачем ГИСы историку, если он изучает Российскую империю или средневековый Новгород? Разбор от специалиста по исторической информатике — специально для «Системного Блока».
В широком смысле ГИСы — программное обеспечение, а точнее, информационные системы, способные обрабатывать любую информацию из баз данных. Например, в роли таких приложений могут выступать ArcView, QGIS, MapInfo и др.
Что касается исторической науки, то здесь ГИСами называют как информационные системы, так и сам метод, благодаря которому историк может анализировать различного рода данные. Карта для историка — это набор пространственно-географических и исторических данных, где историк может комбинировать различные характеристики, добавлять иные данные. Проще говоря, у историков появилась возможность собрать значимые данные в привязке к географическому положению и проанализировать их разными способами.
Применение ГИСов для исследования частотности совершения преступлений в губерниях Российской империи
У нас были данные о количестве осужденных за все преступления в Европейской России 1896 года, взятые из обзоров отчетов губернаторов 50 губерний Европейской России. Для представления этой информации на карте нам потребовались также данные переписи населения 1897 года. С их помощью можно получить относительные числа (то есть количество осужденных на 100 000 человек), а без них графическое представление данных вышло бы искаженным.
На первом этапе мы собрали информацию об осужденных в таблицу в Excel. Далее мы привязали эти данные к используемому шаблону карты (который был предоставлен кафедрой исторической информатики МГУ им. М. В. Ломоносова) в программе MapInfo Pro 15.0. Затем по заданному запросу мы сформировали единую таблицу, которая легла в основу создаваемых карт. На последнем этапе мы сформировали сами карты, задав диапазоны и цвета объектов.
Результаты исследования
Изначально у нас была гипотеза о том, что в промышленных и урбанизированных губерниях наиболее часто совершаются преступления против собственности (это разбои, грабежи, кражи и мошенничество), а в сельских — против личности (убийства, нанесение ран и увечий).
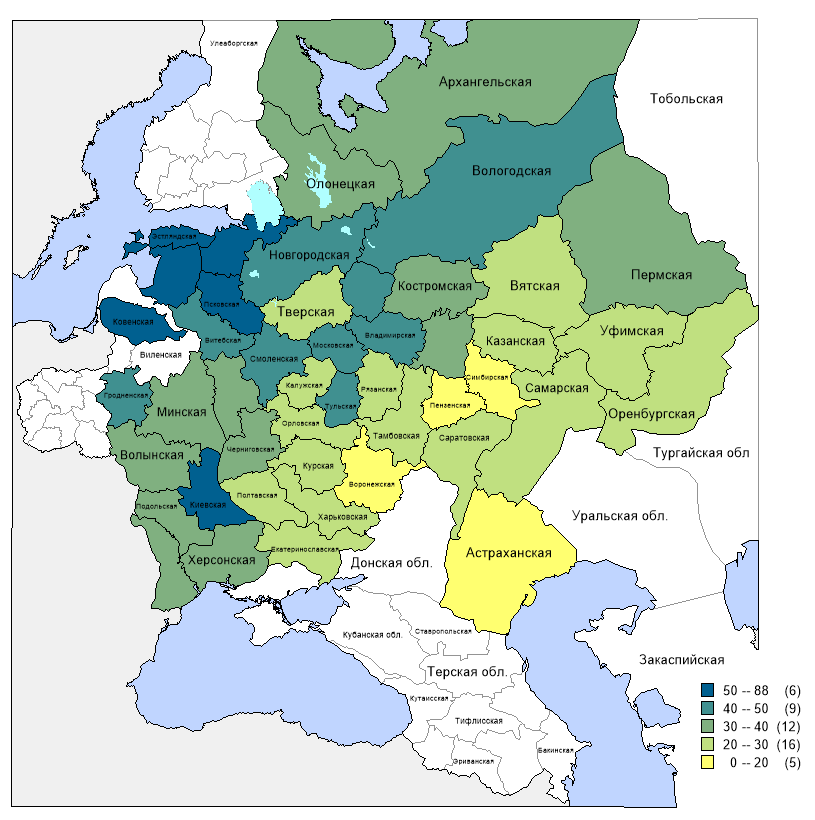
Мы увидели, что наибольшее количество осужденных (на 100 000 человек) встречается в прибалтийских губерниях, а также в Киевской. Далее идут губернии центрального промышленного района и других.
Мы выделили три основных типа преступлений для всего региона: это преступления против личности, против собственности и против общественного благоустройства и благочиния.
Мы выяснили, что преступления против собственности характерны для территорий, где проживает больше городского населения, и для промышленных регионов Европейской России в целом, а связь преступлений против личности с сельскими регионами не наблюдается. Этот тип преступлений также связан с регионами с преобладающей долей городского населения.
Помимо карт мы использовали метод подсчета коэффициентов корреляции для числа осужденных за каждое преступление и данных из переписи. В итоге гипотеза была подтверждена лишь частично и с рядом оговорок, так как у нас были все-таки данные не о числе преступлений, а о количестве осужденных за эти преступления — а это разные вещи.
Ниже прикреплена карта относительной плотности осужденных за все преступления в 1896 г. по губерниям Европейской России (на 100 тысяч человек).
Екатерина Олейникова
По ссылке подробно и со скриншотами рассказываем о создании ГИСов, о развитии геоинформатики и о других исследованиях, с ипользованием ГИСов: https://sysblok.ru/history/kartirovanie-kriminala-i-rost-srednevekovyh-gorodov-zachem-istorikam-gisy/
#society #history
Мы пользуемся геоинформационными системами (ГИСами) каждый день, когда лезем в карты на телефоне или едем куда-то по навигатору. А зачем ГИСы историку, если он изучает Российскую империю или средневековый Новгород? Разбор от специалиста по исторической информатике — специально для «Системного Блока».
В широком смысле ГИСы — программное обеспечение, а точнее, информационные системы, способные обрабатывать любую информацию из баз данных. Например, в роли таких приложений могут выступать ArcView, QGIS, MapInfo и др.
Что касается исторической науки, то здесь ГИСами называют как информационные системы, так и сам метод, благодаря которому историк может анализировать различного рода данные. Карта для историка — это набор пространственно-географических и исторических данных, где историк может комбинировать различные характеристики, добавлять иные данные. Проще говоря, у историков появилась возможность собрать значимые данные в привязке к географическому положению и проанализировать их разными способами.
Применение ГИСов для исследования частотности совершения преступлений в губерниях Российской империи
У нас были данные о количестве осужденных за все преступления в Европейской России 1896 года, взятые из обзоров отчетов губернаторов 50 губерний Европейской России. Для представления этой информации на карте нам потребовались также данные переписи населения 1897 года. С их помощью можно получить относительные числа (то есть количество осужденных на 100 000 человек), а без них графическое представление данных вышло бы искаженным.
На первом этапе мы собрали информацию об осужденных в таблицу в Excel. Далее мы привязали эти данные к используемому шаблону карты (который был предоставлен кафедрой исторической информатики МГУ им. М. В. Ломоносова) в программе MapInfo Pro 15.0. Затем по заданному запросу мы сформировали единую таблицу, которая легла в основу создаваемых карт. На последнем этапе мы сформировали сами карты, задав диапазоны и цвета объектов.
Результаты исследования
Изначально у нас была гипотеза о том, что в промышленных и урбанизированных губерниях наиболее часто совершаются преступления против собственности (это разбои, грабежи, кражи и мошенничество), а в сельских — против личности (убийства, нанесение ран и увечий).
Мы увидели, что наибольшее количество осужденных (на 100 000 человек) встречается в прибалтийских губерниях, а также в Киевской. Далее идут губернии центрального промышленного района и других.
Мы выделили три основных типа преступлений для всего региона: это преступления против личности, против собственности и против общественного благоустройства и благочиния.
Мы выяснили, что преступления против собственности характерны для территорий, где проживает больше городского населения, и для промышленных регионов Европейской России в целом, а связь преступлений против личности с сельскими регионами не наблюдается. Этот тип преступлений также связан с регионами с преобладающей долей городского населения.
Помимо карт мы использовали метод подсчета коэффициентов корреляции для числа осужденных за каждое преступление и данных из переписи. В итоге гипотеза была подтверждена лишь частично и с рядом оговорок, так как у нас были все-таки данные не о числе преступлений, а о количестве осужденных за эти преступления — а это разные вещи.
Ниже прикреплена карта относительной плотности осужденных за все преступления в 1896 г. по губерниям Европейской России (на 100 тысяч человек).
Екатерина Олейникова
По ссылке подробно и со скриншотами рассказываем о создании ГИСов, о развитии геоинформатики и о других исследованиях, с ипользованием ГИСов: https://sysblok.ru/history/kartirovanie-kriminala-i-rost-srednevekovyh-gorodov-zachem-istorikam-gisy/
{kind=link}
Айтрекинг в психологии искусства: что и как влияет на восприятие великих полотен
#arts
Восприятие искусства — комплексный процесс, включающий понимание, запоминание и составление собственного впечатления, допустим, о картине. Когда мы смотрим на картину, мы ее «сканируем»: сначала быстро фиксируем как единое целое, а затем начинаем перескакивать с одной детали на другую. Что наиболее бросается в глаза, то и «перехватывает» наше внимание. Если знать, сколько времени зритель посвящает изучению полотна, можно сделать вывод о его потребностях, интересах и эстетических взглядах. А если зрителей много — о потребностях и интересах целой аудитории.
Технология айтрекинга
Айтрекинг или управление взглядом — технология для определения положения глаз зрителя относительно дисплея, на который выведено изображение. Данные, полученные в ходе «слежения» за глазом, позволяют проанализировать как люди воспринимают визуальную информацию, что вызывает у них интерес, а какие элементы работают неэффективно.
Устройство айтрекера состоит из камер и осветителей, которые крепятся на монитор компьютера. Инфракрасный луч света направляется на сетчатку глаза, а сверхчувствительная камера записывает малейшие изменения ее положения (в том числе сужение-расширение зрачка). Математические алгоритмы сопоставляют изображение, на которое смотрит человек, с последовательными движениями глаз. Визуализированные траектории взгляда показывают, что привлекает внимание зрителя в первую очередь, а тепловые карты — что вызвало наибольший интерес.
Исследование влияния подписи к картине на ее восприятие
В совместном проекте университетов Оксфорда и Дарема ученые поставили цель выяснить, как современный человек оценивает картины и что может повлиять на его мнение. Предположили, что на восприятие могут влиять краткие описания, которые сопровождают картины в галереях и музеях. Ученые предложили участникам эксперимента сначала ознакомиться с информацией о каждой картине, а затем измеряли время, уделенное изучению деталей, и направление движений глаз, используя технологии айтрекинга в лабораторных условиях.
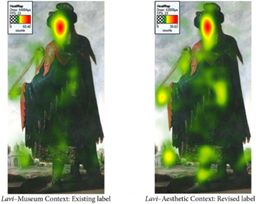
Исследования проводились в лаборатории с использованием цифровых копий картин из цикла «Иаков и его 12 сыновей» Франциско де Сурбарана, испанского художника 17-го века. Каждой картине серии присвоили по три подписи, которые характеризовали их с трех разных позиций. Участников эксперимента разделили соответственно на три группы. Группе 1 «Музейный контекст» представили описание, делающее акцент на смысловой составляющей картины — на Библейской легенде; группе 2 «Эстетический контекст» — описание художественной ценности полотен; группе 3 «Авторский контекст» — общую информацию о картине и ее авторе.
Результаты исследования
Внимание групп 1 и 3 сосредотачивалось в основном на лицах и символах-атрибутах, а группы 2 — было более рассеяно. Пример тепловой карты на основе изображения брата Левия прикреплен ниже.
Также, гипотеза — чем больше информации получает зритель перед просмотром, тем больше ему нравится картина — не подтвердилась. Ярлыки с подробным описанием картины заставляли испытуемых меньше смотреть на лица, и картины они находили менее приятными. Наиболее заинтересованы в картинах оказались участники, которым дали минимум информации.
После эксперимента участникам было предложено оценить работы, как это делалось бы на аукционе. Как выяснилось, конкретика, данная изначально в описании работы, придавала участникам больше уверенности при оценке. Участники группы 1, опираясь на ветхозаветные описания героев картин, назвали самыми дорогими шесть холстов, группа 2 с точки зрения культурной ценности — всего пять, а группа 3 распространила свои суждения на восемь полотен.
Мария Черных
https://sysblok.ru/arts/ajtreking-v-psihologii-iskusstva-vyjasnjaem-chto-i-kak-vlijaet-na-nashe-vosprijatie-velikih-poloten/
#arts
Восприятие искусства — комплексный процесс, включающий понимание, запоминание и составление собственного впечатления, допустим, о картине. Когда мы смотрим на картину, мы ее «сканируем»: сначала быстро фиксируем как единое целое, а затем начинаем перескакивать с одной детали на другую. Что наиболее бросается в глаза, то и «перехватывает» наше внимание. Если знать, сколько времени зритель посвящает изучению полотна, можно сделать вывод о его потребностях, интересах и эстетических взглядах. А если зрителей много — о потребностях и интересах целой аудитории.
Технология айтрекинга
Айтрекинг или управление взглядом — технология для определения положения глаз зрителя относительно дисплея, на который выведено изображение. Данные, полученные в ходе «слежения» за глазом, позволяют проанализировать как люди воспринимают визуальную информацию, что вызывает у них интерес, а какие элементы работают неэффективно.
Устройство айтрекера состоит из камер и осветителей, которые крепятся на монитор компьютера. Инфракрасный луч света направляется на сетчатку глаза, а сверхчувствительная камера записывает малейшие изменения ее положения (в том числе сужение-расширение зрачка). Математические алгоритмы сопоставляют изображение, на которое смотрит человек, с последовательными движениями глаз. Визуализированные траектории взгляда показывают, что привлекает внимание зрителя в первую очередь, а тепловые карты — что вызвало наибольший интерес.
Исследование влияния подписи к картине на ее восприятие
В совместном проекте университетов Оксфорда и Дарема ученые поставили цель выяснить, как современный человек оценивает картины и что может повлиять на его мнение. Предположили, что на восприятие могут влиять краткие описания, которые сопровождают картины в галереях и музеях. Ученые предложили участникам эксперимента сначала ознакомиться с информацией о каждой картине, а затем измеряли время, уделенное изучению деталей, и направление движений глаз, используя технологии айтрекинга в лабораторных условиях.
Исследования проводились в лаборатории с использованием цифровых копий картин из цикла «Иаков и его 12 сыновей» Франциско де Сурбарана, испанского художника 17-го века. Каждой картине серии присвоили по три подписи, которые характеризовали их с трех разных позиций. Участников эксперимента разделили соответственно на три группы. Группе 1 «Музейный контекст» представили описание, делающее акцент на смысловой составляющей картины — на Библейской легенде; группе 2 «Эстетический контекст» — описание художественной ценности полотен; группе 3 «Авторский контекст» — общую информацию о картине и ее авторе.
Результаты исследования
Внимание групп 1 и 3 сосредотачивалось в основном на лицах и символах-атрибутах, а группы 2 — было более рассеяно. Пример тепловой карты на основе изображения брата Левия прикреплен ниже.
Также, гипотеза — чем больше информации получает зритель перед просмотром, тем больше ему нравится картина — не подтвердилась. Ярлыки с подробным описанием картины заставляли испытуемых меньше смотреть на лица, и картины они находили менее приятными. Наиболее заинтересованы в картинах оказались участники, которым дали минимум информации.
После эксперимента участникам было предложено оценить работы, как это делалось бы на аукционе. Как выяснилось, конкретика, данная изначально в описании работы, придавала участникам больше уверенности при оценке. Участники группы 1, опираясь на ветхозаветные описания героев картин, назвали самыми дорогими шесть холстов, группа 2 с точки зрения культурной ценности — всего пять, а группа 3 распространила свои суждения на восемь полотен.
Мария Черных
https://sysblok.ru/arts/ajtreking-v-psihologii-iskusstva-vyjasnjaem-chto-i-kak-vlijaet-na-nashe-vosprijatie-velikih-poloten/
{kind=link}
Вся классика в один клик: как выделить из текста события
#philology
Школьники, зависающие на сайтах с краткими содержаниями, многое бы отдали за чудо-ресурс, которому можно было бы отдать художественное произведение и получить взамен описание событий в тексте. Рассказываем, как работает технология извлечения событий из художественных текстов и что она позволяет узнать о литературе уже сейчас.
Художественные произведения — сложный материал для анализа, так как они длинные, структура событий в них сложная и запутанная, а их первостепенная цель — эмоциональное воздействие на читателя.
Сбор и разметка данных
Ученые собрали корпус на основе текстов, публично доступных на ресурсе Project Gutenberg. В корпусе есть и произведения, относящиеся высокому литературному стилю («Улисс» Джеймса Джойса), и более массовая литература («Рваный Дик» Горацио Элджера). Все тексты были опубликованы до 1923 г. и из каждого взяты первые 2000 слов, чтобы уравнять все произведения.
Исследователи решили, что их интересуют события, действительно произошедшие в произведении. При разметке они руководствовались следующими правилами:
1. Полярность: размечались только произошедшие события с положительной полярностью. События-отрицания не размечались как произошедшие.
2. Грамматическое время: размечались события, выраженные глаголами в настоящем или прошедшем времени.
3. Универсальность: все универсальные события, описывающие обыденные действия, которые могли бы выглядеть и быть описаны абсолютно так же в другом произведении (например, собаки лаяли) не размечались.
4. Модальность: размечались только те события, о которых говорилось с уверенностью.
Помимо самих событий, авторы также размечали триггеры к ним — одно слово, которое может описать событие. В корпусе из 210 532 токенов-слов получилось 7 849 событий; результат разметки находится в открытом доступе.
В результате оказалось, что большинство событий можно разбить на четыре категории: разговор, движение, восприятие и обладание. Таблица ниже показывает, как часто встречались слова из этих категорий.
Анализ событий с помощью нейросетей
Из полученного датасета сделали два набора признаковых описаний: в одном из них использовалось векторное описание слов, в другом, помимо векторного описания, были лингвистические признаки: часть речи, информация о контексте, информация о семантике слова, полученная при помощи WordNet, и специфическая информация о конкретном слове (например, если это bare plural — существительное во множественном числе, которое используется в основном для того, чтобы фраза получила универсальное прочтение: «Кошки любят молоко»).
Исследователи определили свою задачу как выявление связи между рассматриваемым словом и событием. Для этого использовались нейронные сети двух различных архитектур — одно- и двунаправленная LSTM и свёрточная нейронная сеть (CNN). В итоге лучшей комбинацией стала двунаправленная LSTM-сеть, в которой векторное описание слов было получено при помощи BERT — модели, которая для вычисления вектора слова также учитывает его контекст. Такая модель выделила события с F-мерой 73.9.
Дальнее чтение корпуса
Ученые решили посмотреть, отличаются ли предсказания сети для текстов разного уровня литературного мастерства.
В среднем в высокохудожественных произведениях оказалось чуть меньше событий (4.6% против 5.5%), которые чуть более подробно описаны: в среднем между двумя найденными событиями более «элитного» текста помещалось 23.4 слова, а в менее элитарных текстах — 19.2 слова.
Также авторы сравнили произведения, разделив их по популярности, но здесь различий не обнаружили: во всех текстах в среднем случалось около 4.5% событий примерно одной длины.
Дарья Максимова
https://sysblok.ru/philology/vsja-klassika-v-odin-klik-kak-vydelit-iz-teksta-sobytija/
#philology
Школьники, зависающие на сайтах с краткими содержаниями, многое бы отдали за чудо-ресурс, которому можно было бы отдать художественное произведение и получить взамен описание событий в тексте. Рассказываем, как работает технология извлечения событий из художественных текстов и что она позволяет узнать о литературе уже сейчас.
Художественные произведения — сложный материал для анализа, так как они длинные, структура событий в них сложная и запутанная, а их первостепенная цель — эмоциональное воздействие на читателя.
Сбор и разметка данных
Ученые собрали корпус на основе текстов, публично доступных на ресурсе Project Gutenberg. В корпусе есть и произведения, относящиеся высокому литературному стилю («Улисс» Джеймса Джойса), и более массовая литература («Рваный Дик» Горацио Элджера). Все тексты были опубликованы до 1923 г. и из каждого взяты первые 2000 слов, чтобы уравнять все произведения.
Исследователи решили, что их интересуют события, действительно произошедшие в произведении. При разметке они руководствовались следующими правилами:
1. Полярность: размечались только произошедшие события с положительной полярностью. События-отрицания не размечались как произошедшие.
2. Грамматическое время: размечались события, выраженные глаголами в настоящем или прошедшем времени.
3. Универсальность: все универсальные события, описывающие обыденные действия, которые могли бы выглядеть и быть описаны абсолютно так же в другом произведении (например, собаки лаяли) не размечались.
4. Модальность: размечались только те события, о которых говорилось с уверенностью.
Помимо самих событий, авторы также размечали триггеры к ним — одно слово, которое может описать событие. В корпусе из 210 532 токенов-слов получилось 7 849 событий; результат разметки находится в открытом доступе.
В результате оказалось, что большинство событий можно разбить на четыре категории: разговор, движение, восприятие и обладание. Таблица ниже показывает, как часто встречались слова из этих категорий.
Анализ событий с помощью нейросетей
Из полученного датасета сделали два набора признаковых описаний: в одном из них использовалось векторное описание слов, в другом, помимо векторного описания, были лингвистические признаки: часть речи, информация о контексте, информация о семантике слова, полученная при помощи WordNet, и специфическая информация о конкретном слове (например, если это bare plural — существительное во множественном числе, которое используется в основном для того, чтобы фраза получила универсальное прочтение: «Кошки любят молоко»).
Исследователи определили свою задачу как выявление связи между рассматриваемым словом и событием. Для этого использовались нейронные сети двух различных архитектур — одно- и двунаправленная LSTM и свёрточная нейронная сеть (CNN). В итоге лучшей комбинацией стала двунаправленная LSTM-сеть, в которой векторное описание слов было получено при помощи BERT — модели, которая для вычисления вектора слова также учитывает его контекст. Такая модель выделила события с F-мерой 73.9.
Дальнее чтение корпуса
Ученые решили посмотреть, отличаются ли предсказания сети для текстов разного уровня литературного мастерства.
В среднем в высокохудожественных произведениях оказалось чуть меньше событий (4.6% против 5.5%), которые чуть более подробно описаны: в среднем между двумя найденными событиями более «элитного» текста помещалось 23.4 слова, а в менее элитарных текстах — 19.2 слова.
Также авторы сравнили произведения, разделив их по популярности, но здесь различий не обнаружили: во всех текстах в среднем случалось около 4.5% событий примерно одной длины.
Дарья Максимова
https://sysblok.ru/philology/vsja-klassika-v-odin-klik-kak-vydelit-iz-teksta-sobytija/
{kind=link}
Как работают рекомендательные системы — и что с ними будет завтра
#arts
Часто ли вы сталкиваетесь с проблемой выбора фильма на вечер? И как эту проблему вы решаете сегодня? Подборки на тематических порталах, советы друзей, оценки критиков. К сожалению, эти инструменты обладают одной существенной погрешностью — они исключают персонализацию. Еще одна проблема лежит в поведенческой номенклатуре нашего мозга и чистой математике: чем больше выбор — тем сложнее выбирать.
Основные принципы рекомендательных систем
Рекомендательные системы в своей привычной форме существуют порядка 30 лет, однако архитектурно не претерпели больших перемен. Можно выделить две основные методики, применяемые в производстве: коллаборативная фильтрация (User-Based Filtering) и фильтрация по содержанию (Content-Based Filtering).
Коллаборативная фильтрация строит прогноз на основе пользователей со схожими признаками, интересами или поведением, группируя их в кластеры. Выявить степень «схожести» можно с помощью формулы расчета корреляции, например, Пирсона.
Второй способ фильтрации (Content-Based Filtering) отличает лишь то, что за основу берутся похожие группы контента (в нашем случае — похожие фильмы). И по тому же принципу выявляет степень соседства между фильмами.
На деле применение алгоритма выглядит куда сложнее и чаще всего представляет собой гибридную модель.
Какие есть трудности
Из-за дефицита данных могут возникать проблемы. К примеру, проблема холодного старта (когда мы ничего не знаем о пользователе, следовательно, неясно что ему рекомендовать), или проблема нового контента (что порождает проблему разнообразия), или синонимия (когда похожие и одинаковые предметы имеют разные имена, например, жанры «детский фильм» и «фильм для детей»). Поэтому приходится логировать (т. е. сохранять в памяти системы) все, пытаясь «между строк» предугадать намерение пользователя.
Так, совокупность данных формируют явные (explicit ratings) и неявные (implicit ratings) информационные сигналы, получаемые от пользователей. На примере кино: явным сигналом может служить оценка, неявным — просмотр трейлера. Вес этих сигналов также будет индивидуален (оценка представляет большую ценность для сервиса).
Пример Netflix
Для демонстрации современного образца рекомендательных систем обратимся к Netflix. В 2006 году компания решила повысить релевантность рекомендаций и объявила конкурс на 1 млн. долларов, который достанется тому, кто сможет улучшить текущее качество прогноза не менее чем на 10%. Качество прогноза измерялось на основе среднеквадратичного отклонения (Root Mean Square Error) и на момент объявления конкурса составляла 0.9514. Целью же было снизить эту ошибку как минимум до 0.8563.
Соревнование длилось порядка трех лет. В качестве обучающих данных был использован датасет из 100 с лишним миллионов реальных оценок пользователей сервиса. Победителем стала команда «BellKor’s Pragmatic Chaos», которой удалось улучшить результаты на 10,06%.
Сейчас обучающийся алгоритм Netflix учитывает не только оценки пользователей, но и весь доступный контекст — время суток, данные о возрасте и поле, географическое положение. Сам алгоритм использует не только регрессионные методы прогнозирования, но и метод сингулярного разложения, генеративные стохастические нейронные сети, обучение ассоциативным правилам, градиентный бустинг и многое другое, что формирует архитектуру под капотом.
Чего ждать от рекомендательных систем завтра
При выборе фильма существует еще одна проблема — мы часто сами не знаем, чего по-настоящему хотим. Можно предположить, что стриминговые сервисы (Netflix, Amazon Prime, Hulu, HBO и другие) будут влиять на киноиндустрию, определяя принципы производства нового контента.
Иными словами, будут снимать ровно то, что будет востребовано, и вопросы «что я хочу посмотреть» перестанут волновать аудиторию, поскольку ответ будет получен до возникновения самого вопроса.
Михаил Бабасян
https://sysblok.ru/arts/kak-rabotajut-rekomendatelnye-sistemy-i-chto-s-nimi-budet-zavtra/
#arts
Часто ли вы сталкиваетесь с проблемой выбора фильма на вечер? И как эту проблему вы решаете сегодня? Подборки на тематических порталах, советы друзей, оценки критиков. К сожалению, эти инструменты обладают одной существенной погрешностью — они исключают персонализацию. Еще одна проблема лежит в поведенческой номенклатуре нашего мозга и чистой математике: чем больше выбор — тем сложнее выбирать.
Основные принципы рекомендательных систем
Рекомендательные системы в своей привычной форме существуют порядка 30 лет, однако архитектурно не претерпели больших перемен. Можно выделить две основные методики, применяемые в производстве: коллаборативная фильтрация (User-Based Filtering) и фильтрация по содержанию (Content-Based Filtering).
Коллаборативная фильтрация строит прогноз на основе пользователей со схожими признаками, интересами или поведением, группируя их в кластеры. Выявить степень «схожести» можно с помощью формулы расчета корреляции, например, Пирсона.
Второй способ фильтрации (Content-Based Filtering) отличает лишь то, что за основу берутся похожие группы контента (в нашем случае — похожие фильмы). И по тому же принципу выявляет степень соседства между фильмами.
На деле применение алгоритма выглядит куда сложнее и чаще всего представляет собой гибридную модель.
Какие есть трудности
Из-за дефицита данных могут возникать проблемы. К примеру, проблема холодного старта (когда мы ничего не знаем о пользователе, следовательно, неясно что ему рекомендовать), или проблема нового контента (что порождает проблему разнообразия), или синонимия (когда похожие и одинаковые предметы имеют разные имена, например, жанры «детский фильм» и «фильм для детей»). Поэтому приходится логировать (т. е. сохранять в памяти системы) все, пытаясь «между строк» предугадать намерение пользователя.
Так, совокупность данных формируют явные (explicit ratings) и неявные (implicit ratings) информационные сигналы, получаемые от пользователей. На примере кино: явным сигналом может служить оценка, неявным — просмотр трейлера. Вес этих сигналов также будет индивидуален (оценка представляет большую ценность для сервиса).
Пример Netflix
Для демонстрации современного образца рекомендательных систем обратимся к Netflix. В 2006 году компания решила повысить релевантность рекомендаций и объявила конкурс на 1 млн. долларов, который достанется тому, кто сможет улучшить текущее качество прогноза не менее чем на 10%. Качество прогноза измерялось на основе среднеквадратичного отклонения (Root Mean Square Error) и на момент объявления конкурса составляла 0.9514. Целью же было снизить эту ошибку как минимум до 0.8563.
Соревнование длилось порядка трех лет. В качестве обучающих данных был использован датасет из 100 с лишним миллионов реальных оценок пользователей сервиса. Победителем стала команда «BellKor’s Pragmatic Chaos», которой удалось улучшить результаты на 10,06%.
Сейчас обучающийся алгоритм Netflix учитывает не только оценки пользователей, но и весь доступный контекст — время суток, данные о возрасте и поле, географическое положение. Сам алгоритм использует не только регрессионные методы прогнозирования, но и метод сингулярного разложения, генеративные стохастические нейронные сети, обучение ассоциативным правилам, градиентный бустинг и многое другое, что формирует архитектуру под капотом.
Чего ждать от рекомендательных систем завтра
При выборе фильма существует еще одна проблема — мы часто сами не знаем, чего по-настоящему хотим. Можно предположить, что стриминговые сервисы (Netflix, Amazon Prime, Hulu, HBO и другие) будут влиять на киноиндустрию, определяя принципы производства нового контента.
Иными словами, будут снимать ровно то, что будет востребовано, и вопросы «что я хочу посмотреть» перестанут волновать аудиторию, поскольку ответ будет получен до возникновения самого вопроса.
Михаил Бабасян
https://sysblok.ru/arts/kak-rabotajut-rekomendatelnye-sistemy-i-chto-s-nimi-budet-zavtra/
{kind=link}
Как мы теряем природные ресурсы темноты
#urban
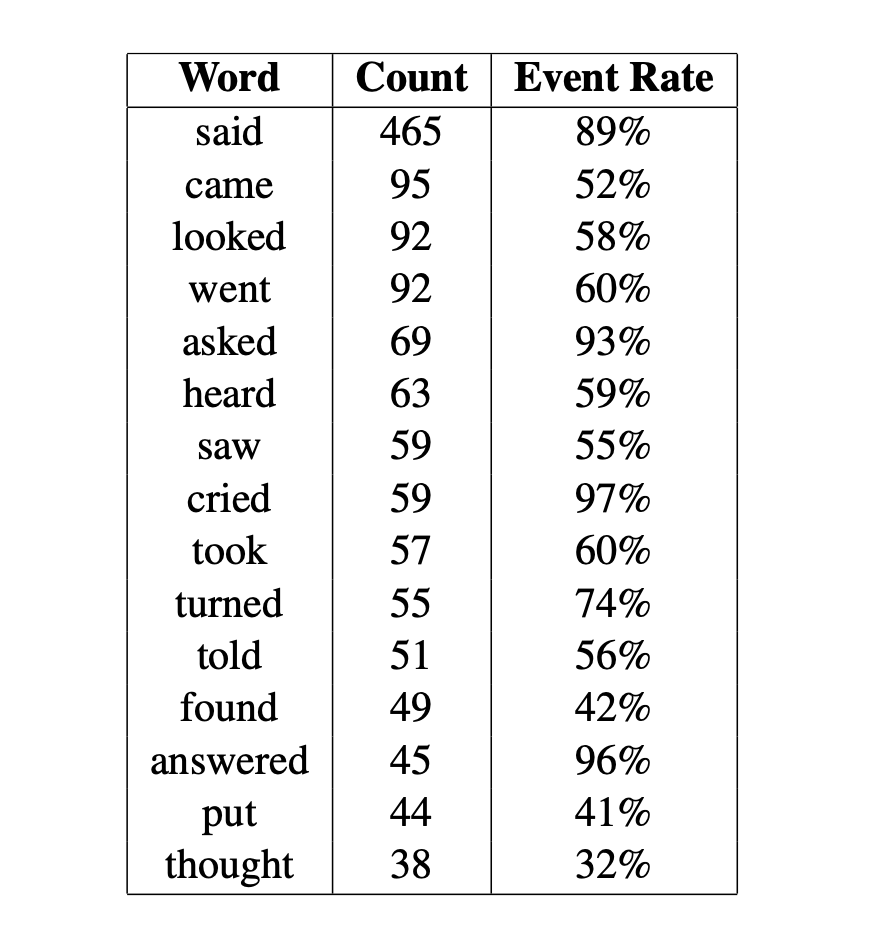
По снимкам ночной Земли урбанисты научились оценивать плотность и численность населения во всех регионах Земли с достаточной регулярностью. На снимках также хорошо видны электрифицированные регионы, что позволяет оценить и уровень жизни населения.
Интенсивное освещение обычно сопровождает города. Общее правило звучит так: «больше людей — больше света». Это называют световым загрязнением — по аналогии с загрязнением других сред жизни человека и всех живых существ. И это тоже экологическая проблема.
Свет от искусственных источников рассеивается в нижних слоях атмосферы, что вызывает изменения в биоритмах ночных существ, сбивает птиц с их курса миграции и мешает нам увидеть ночное небо.
Что влияет на световой ландшафт
Картограф Descartes Lab Тим Уоллас решил уточнить, от чего конкретно зависит освещенность планеты. Для этого он нормализовал яркость точек на снимках на численность населения. Ниже прикреплены три карты, иллюстрирующие 1) ночную освещенность территории США, 2) распределение населения по территории США, 3) освещенность, нормализованную по населению.
На третьей карте световой ландшафт сильно отличается от того, что было на первой карте. Видно, что самые яркие точки находятся вовсе не в мегаполисах, а за их пределами.
Тим Уоллас и Джон Барентайн, член Международной Ассоциации Темного Неба (International Dark-Sky Association), выделяют три основных типа явлений, световой след от которых виден из космоса: добыча нефти и газа, склады и теплицы.
Добыча нефти и газа
Сейчас США являются лидерами по добыче сланцевой нефти. Нефтеносные регионы выделяются яркими пятнами, а на более детальных участках можно даже рассмотреть регулярную структуру площадок добычи.
Основными источниками света здесь являются факелы сжигаемого попутного природного газа (излишки газа, образующиеся при добыче нефти, перерабатывать которые экономически нецелесообразно) и освещение площадок добычи и жилых площадей работников.
В некоторых регионах добычи с 2010 по 2013 год рассеянное освещение от искусственных источников увеличилось на 500%. После 2014 года, когда цены на нефть на мировых рынках рухнули, активное развитие добычи сланцевой нефти прекратилось, но световое воздействие не уменьшилось.
Склады
Быстрая доставка любых товаров — кажется, одна из характеристик современных США. Amazon, FedEx, UPS, DHL и многие другие — каждая из этих компаний владеет огромными площадями складских помещений, без которых доставка затягивалась бы на гораздо большие сроки. Многие из них расположены за пределами крупных городов, где дешевле владеть большими участками земли. Все они ярко освещены по ночам, так как работа там редко останавливается.
Теплицы
Тим Уоллас особенно выделяет одну точку на карте штата Мэн: посреди довольно темного фона светится яркая точка — это внушительные 42 акра теплиц фирмы Backyard Farm, которая специализируется на выращивании помидоров.
Исследователи отмечают, что производители тепличной продукции любят менять спектр освещения, адаптируя условия для отдельных культур. Это стало возможным с развитием LED-освещения (светодиодов).
Возможно, вы видели снимки фиолетового неба, сделанные в январе этого года жителями города Сноуфлейк в штате Аризона — оказалось, что это отсветы освещения теплиц огромной плантации марихуаны неподалеку, усиленные погодными условиями — низкой облачностью и туманом.
Если же вам придется как-нибудь пролетать над Нидерландами ночью, обратите внимание на сияющие оранжевые пятна, разбросанные по территории страны — теплицы, в которых выращивают тюльпаны.
Нелли Бурцева
https://sysblok.ru/urban/kak-my-terjaem-prirodnye-resursy-temnoty/
#urban
По снимкам ночной Земли урбанисты научились оценивать плотность и численность населения во всех регионах Земли с достаточной регулярностью. На снимках также хорошо видны электрифицированные регионы, что позволяет оценить и уровень жизни населения.
Интенсивное освещение обычно сопровождает города. Общее правило звучит так: «больше людей — больше света». Это называют световым загрязнением — по аналогии с загрязнением других сред жизни человека и всех живых существ. И это тоже экологическая проблема.
Свет от искусственных источников рассеивается в нижних слоях атмосферы, что вызывает изменения в биоритмах ночных существ, сбивает птиц с их курса миграции и мешает нам увидеть ночное небо.
Что влияет на световой ландшафт
Картограф Descartes Lab Тим Уоллас решил уточнить, от чего конкретно зависит освещенность планеты. Для этого он нормализовал яркость точек на снимках на численность населения. Ниже прикреплены три карты, иллюстрирующие 1) ночную освещенность территории США, 2) распределение населения по территории США, 3) освещенность, нормализованную по населению.
На третьей карте световой ландшафт сильно отличается от того, что было на первой карте. Видно, что самые яркие точки находятся вовсе не в мегаполисах, а за их пределами.
Тим Уоллас и Джон Барентайн, член Международной Ассоциации Темного Неба (International Dark-Sky Association), выделяют три основных типа явлений, световой след от которых виден из космоса: добыча нефти и газа, склады и теплицы.
Добыча нефти и газа
Сейчас США являются лидерами по добыче сланцевой нефти. Нефтеносные регионы выделяются яркими пятнами, а на более детальных участках можно даже рассмотреть регулярную структуру площадок добычи.
Основными источниками света здесь являются факелы сжигаемого попутного природного газа (излишки газа, образующиеся при добыче нефти, перерабатывать которые экономически нецелесообразно) и освещение площадок добычи и жилых площадей работников.
В некоторых регионах добычи с 2010 по 2013 год рассеянное освещение от искусственных источников увеличилось на 500%. После 2014 года, когда цены на нефть на мировых рынках рухнули, активное развитие добычи сланцевой нефти прекратилось, но световое воздействие не уменьшилось.
Склады
Быстрая доставка любых товаров — кажется, одна из характеристик современных США. Amazon, FedEx, UPS, DHL и многие другие — каждая из этих компаний владеет огромными площадями складских помещений, без которых доставка затягивалась бы на гораздо большие сроки. Многие из них расположены за пределами крупных городов, где дешевле владеть большими участками земли. Все они ярко освещены по ночам, так как работа там редко останавливается.
Теплицы
Тим Уоллас особенно выделяет одну точку на карте штата Мэн: посреди довольно темного фона светится яркая точка — это внушительные 42 акра теплиц фирмы Backyard Farm, которая специализируется на выращивании помидоров.
Исследователи отмечают, что производители тепличной продукции любят менять спектр освещения, адаптируя условия для отдельных культур. Это стало возможным с развитием LED-освещения (светодиодов).
Возможно, вы видели снимки фиолетового неба, сделанные в январе этого года жителями города Сноуфлейк в штате Аризона — оказалось, что это отсветы освещения теплиц огромной плантации марихуаны неподалеку, усиленные погодными условиями — низкой облачностью и туманом.
Если же вам придется как-нибудь пролетать над Нидерландами ночью, обратите внимание на сияющие оранжевые пятна, разбросанные по территории страны — теплицы, в которых выращивают тюльпаны.
Нелли Бурцева
https://sysblok.ru/urban/kak-my-terjaem-prirodnye-resursy-temnoty/
{kind=link}
Проект OneSoil Map: как нейросеть помогает сельскому хозяйству
#visualisation
Про Никиту Хрущева шутили, что он запустил не только спутник, но и сельское хозяйство… Но с появлением искусственного интеллекта эти две сферы подружились: теперь спутниковые технологии работают на успех аграрного производства. Разбираемся, как искусственный интеллект и снимки из космоса помогают выбрать плодородное поле для посадки картошки.
Многие наверняка слышали о роли технологий в сельском хозяйстве. Это и альтернативные источники энергии, и генно-модифицированные организмы, и беспилотные машины для уборки урожая. С каждым десятилетием хозяйство вести все легче. У использования новых технологий в сельском хозяйстве есть название: точное (или «прецизионное», от англ. precision) земледелие.
Точное земледелие позволят эффективнее расходовать семена и удобрения, чтобы получать богатый урожай. Среди ресурсов, относящихся к точному земледелию, — проект OneSoil Map. Это карта всех полей Европы и США за три года, на которой видно, кто где что сажает и как и где развивается сельское хозяйство.
Карта — интерактивная, и работает на алгоритмах искусственного интеллекта и спутниковых снимках. Она располагает информацией о 60 миллионах полей и 27 культурах в 44 странах мира. Этот инструмент помогает фермерам, инвесторам и правительству в оптимизации отрасли сельского хозяйства.
Функционал OneSoil Map
При разработке сервиса OneSoil Map использовались снимки спутника Sentinel-2. Данные со спутника представляют собой около 250 терабайт информации о полях США и Европы. Спутниковые фотографии обработали следующим образом:
1. Сделали препроцессинг снимков: почистили облака, тени и снег. После этого этапа объем данных сократился до 50 терабайт.
2. Нашли границы полей, создали классификаторы для разных полей. Итог этого этапа — 250 гигабайт данных, содержащих векторные карты полей с сельскохозяйственными культурами.
3. Вычислили статистику, рейтинг и популярность разных культур в странах мира.
4. Для улучшения алгоритмов предоставили пользователям возможность уведомлять разработчиков о различных ошибках на картах.
При создании карт применялись два подхода. Во-первых, создали растровую карту: поделили карту на квадраты и выполнили последующий рендер в картинки. Браузер подгружает несколько картинок, а когда пользователь перемещается по карте — двигает их. Из плюсов — все поля отображаются без фильтрации, из минусов — растровые изображения довольно долго загружаются из-за большого объема файлов.
Во-вторых, создали векторную карту: анимировали векторные данные в браузере, как в картах Google и Yandeх. Из плюсов — можно использовать файлы меньшего объема, а также кастомизировать способ отображения данных.
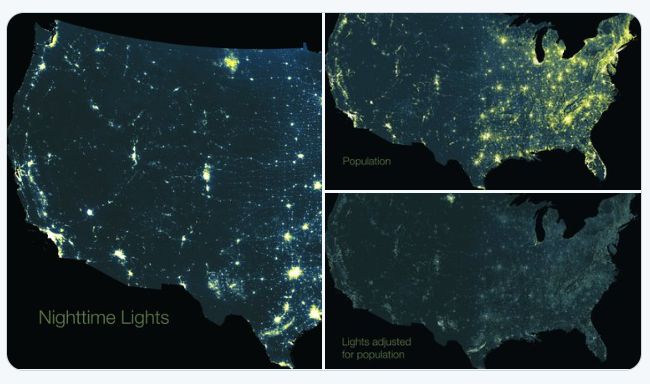
Визуальная часть проекта также тщательно продумана. Для визуализации использовался сервис Mapbox. Для популярных культур выбрали контрастные цвета, для остальных — наименее контрастные. А чтобы привлечь к сервису внимание не только узких специалистов, разработали кнопку «рандомные красивые поля». Например, ниже прикреплена карта полей одного из регионов Франции.
В итоге разработчики стали первыми людьми, кто нанес на карту все поля США и Европы за три года, что не могло не привлечь внимание инвесторов, научных исследователей и фондов. Проект планируют развивать и дальше: цель на ближайшее будущее — автоматически распознавать поля и в остальных странах. Разработчики карты ведут блог, в котором пишут о мониторинге полей, экспериментах, больших данных и историях фермеров.
Колобов Денис
https://sysblok.ru/visual/kak-nejroset-sazhaet-kartoshku-iz-kosmosa/
#visualisation
Про Никиту Хрущева шутили, что он запустил не только спутник, но и сельское хозяйство… Но с появлением искусственного интеллекта эти две сферы подружились: теперь спутниковые технологии работают на успех аграрного производства. Разбираемся, как искусственный интеллект и снимки из космоса помогают выбрать плодородное поле для посадки картошки.
Многие наверняка слышали о роли технологий в сельском хозяйстве. Это и альтернативные источники энергии, и генно-модифицированные организмы, и беспилотные машины для уборки урожая. С каждым десятилетием хозяйство вести все легче. У использования новых технологий в сельском хозяйстве есть название: точное (или «прецизионное», от англ. precision) земледелие.
Точное земледелие позволят эффективнее расходовать семена и удобрения, чтобы получать богатый урожай. Среди ресурсов, относящихся к точному земледелию, — проект OneSoil Map. Это карта всех полей Европы и США за три года, на которой видно, кто где что сажает и как и где развивается сельское хозяйство.
Карта — интерактивная, и работает на алгоритмах искусственного интеллекта и спутниковых снимках. Она располагает информацией о 60 миллионах полей и 27 культурах в 44 странах мира. Этот инструмент помогает фермерам, инвесторам и правительству в оптимизации отрасли сельского хозяйства.
Функционал OneSoil Map
При разработке сервиса OneSoil Map использовались снимки спутника Sentinel-2. Данные со спутника представляют собой около 250 терабайт информации о полях США и Европы. Спутниковые фотографии обработали следующим образом:
1. Сделали препроцессинг снимков: почистили облака, тени и снег. После этого этапа объем данных сократился до 50 терабайт.
2. Нашли границы полей, создали классификаторы для разных полей. Итог этого этапа — 250 гигабайт данных, содержащих векторные карты полей с сельскохозяйственными культурами.
3. Вычислили статистику, рейтинг и популярность разных культур в странах мира.
4. Для улучшения алгоритмов предоставили пользователям возможность уведомлять разработчиков о различных ошибках на картах.
При создании карт применялись два подхода. Во-первых, создали растровую карту: поделили карту на квадраты и выполнили последующий рендер в картинки. Браузер подгружает несколько картинок, а когда пользователь перемещается по карте — двигает их. Из плюсов — все поля отображаются без фильтрации, из минусов — растровые изображения довольно долго загружаются из-за большого объема файлов.
Во-вторых, создали векторную карту: анимировали векторные данные в браузере, как в картах Google и Yandeх. Из плюсов — можно использовать файлы меньшего объема, а также кастомизировать способ отображения данных.
Визуальная часть проекта также тщательно продумана. Для визуализации использовался сервис Mapbox. Для популярных культур выбрали контрастные цвета, для остальных — наименее контрастные. А чтобы привлечь к сервису внимание не только узких специалистов, разработали кнопку «рандомные красивые поля». Например, ниже прикреплена карта полей одного из регионов Франции.
В итоге разработчики стали первыми людьми, кто нанес на карту все поля США и Европы за три года, что не могло не привлечь внимание инвесторов, научных исследователей и фондов. Проект планируют развивать и дальше: цель на ближайшее будущее — автоматически распознавать поля и в остальных странах. Разработчики карты ведут блог, в котором пишут о мониторинге полей, экспериментах, больших данных и историях фермеров.
Колобов Денис
https://sysblok.ru/visual/kak-nejroset-sazhaet-kartoshku-iz-kosmosa/
{kind=link}
Как вычислить эмоции компьютерными методами
Рассказываем на примере анализа песен группы Битлз.
#philology
В 1996 году психолог Синтия Уиссел опубликовала статью, в которой сравнила между собой песни Пола МакКартни и Джона Леннона при помощи методов традиционной и эмоциональной стилометрии. В статье Уиссел пытается ответить на два вопроса:
1. Действительно ли песни Джона грустнее песен Пола?
2. Как менялась эмоциональная составляющая песен Битлз на протяжении четырех стадий их творчества (1962–1964, 1965–1966, 1967–1968, 1969–1970)?
Методы стилометрического анализа
Стилометрия часто использует измерения слова в качестве минимальной единицы. Из слова можно получить множество качеств для изучения текста: длину, частотность и др. Нас интересует коннотация. Коннотации каждого слова вычисляются разными способами опрашивания информантов. Затем результаты документируются в словарях эмоций (Dictionary of Affect). Один из таких словарей Уиссел сама и составила.
Измеряют коннотацию по трем шкалам: оценка, сила и активность. Вместе эти факторы описывают эмоцию человека по отношению к тому, что это слово обозначает, и их достаточно для дифференцирования значений большинства слов. У каждой шкалы две крайности: у оценки это «плохой» и «хороший», у силы — «сильный» и «слабый», а у активности — «активный» и «неактивный».
Для стилометрического исследования не обязательно рассматривать все три шкалы. В статье Уиссел рассматривает только оценку и активность, используя значения из своего словаря. Каждому слову в словаре даны значения на двух семибалльных шкалах: оценки и активности. К примеру, слово delighted ‘восхищенный’ имеет значения 6.4 (оценка) и 4.2 (активность), а gloomy ‘угрюмый’ — 3.2 (оценка) и 2.4 (активность).
Анализ текстов песен группы Битлз
Уиссел посчитала, какой процент наиболее «приятных» и наиболее «активных» слов (в топ 25% по оценке и активности соответственно) присутствует в их песнях на протяжении четырех периодов их творчества. Кроме того, она сконструировала из этих двух шкал еще четыре и тоже их подсчитала:
1. «Радостность» (Cheerfulness) — наиболее приятные и наиболее активные
2. «Гадкость» (Nastiness) — наименее приятные и наиболее активные
3. «Мягкость» (Softness) — наиболее приятные и наименее активные
4. «Грустность» (Sadness) — наименее приятные и наименее активные
Оказалось, что МакКартни использовал на 2% больше «приятных» слов, чем Леннон, который использовал больше «гадких», «мягких» и «грустных» слов.
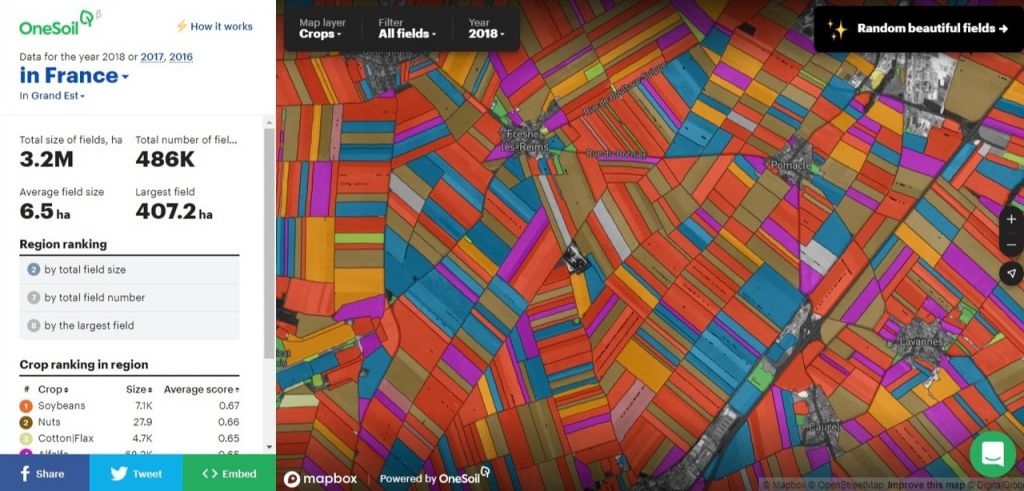
Часы эмоций
Для наглядной демонстрации результатов своих исследований Уиссел использовала т.н. часы эмоций. Схема прикреплена ниже.
Это пространство с двумя осями — оценки и активности. Значения, которые проставляются в этой системе координат, не абсолютные: они нормализованы относительно корпуса из около 50 текстов, включающих в себя художественную литературу, эссе студентов, описания людьми собственных эмоций.
Чем интенсивнее эмоции в тексте, тем вектор (т. е. расстояние от центра до точки, обозначающей текст) будет длиннее, а в зависимости от угла, который образует этот вектор, меняется и общее настроение текста. Для этого и нужна окружность, на которой обозначены различные эмоции.
В среднем все песни Битлз оказываются более «радостными», чем подобранный корпус. А по отдельности песни по-разному располагаются на часах: самой «депрессивной» оказывается песня Джона Леннона «Nowhere Man», самой «приятной» — песня Пола Маккартни «I’ll Follow the Sun».
Сложно понять, насколько эти данные достоверны. Однако интересно, что субъективное мнение критиков, что песни Джона более грустные, как будто подтверждается методами эмоциональной стилометрии. Если два разных подхода к анализу текстов приходят к одному выводу, оба подхода становятся легитимнее, и поэтому, возможно, у эмоциональной стилометрии есть право на существование.
Миша Сонькин
https://sysblok.ru/philology/kak-menjalis-pesni-bitlov-i-mozhno-li-vychislit-jemocii-kompjuternymi-metodami/
Рассказываем на примере анализа песен группы Битлз.
#philology
В 1996 году психолог Синтия Уиссел опубликовала статью, в которой сравнила между собой песни Пола МакКартни и Джона Леннона при помощи методов традиционной и эмоциональной стилометрии. В статье Уиссел пытается ответить на два вопроса:
1. Действительно ли песни Джона грустнее песен Пола?
2. Как менялась эмоциональная составляющая песен Битлз на протяжении четырех стадий их творчества (1962–1964, 1965–1966, 1967–1968, 1969–1970)?
Методы стилометрического анализа
Стилометрия часто использует измерения слова в качестве минимальной единицы. Из слова можно получить множество качеств для изучения текста: длину, частотность и др. Нас интересует коннотация. Коннотации каждого слова вычисляются разными способами опрашивания информантов. Затем результаты документируются в словарях эмоций (Dictionary of Affect). Один из таких словарей Уиссел сама и составила.
Измеряют коннотацию по трем шкалам: оценка, сила и активность. Вместе эти факторы описывают эмоцию человека по отношению к тому, что это слово обозначает, и их достаточно для дифференцирования значений большинства слов. У каждой шкалы две крайности: у оценки это «плохой» и «хороший», у силы — «сильный» и «слабый», а у активности — «активный» и «неактивный».
Для стилометрического исследования не обязательно рассматривать все три шкалы. В статье Уиссел рассматривает только оценку и активность, используя значения из своего словаря. Каждому слову в словаре даны значения на двух семибалльных шкалах: оценки и активности. К примеру, слово delighted ‘восхищенный’ имеет значения 6.4 (оценка) и 4.2 (активность), а gloomy ‘угрюмый’ — 3.2 (оценка) и 2.4 (активность).
Анализ текстов песен группы Битлз
Уиссел посчитала, какой процент наиболее «приятных» и наиболее «активных» слов (в топ 25% по оценке и активности соответственно) присутствует в их песнях на протяжении четырех периодов их творчества. Кроме того, она сконструировала из этих двух шкал еще четыре и тоже их подсчитала:
1. «Радостность» (Cheerfulness) — наиболее приятные и наиболее активные
2. «Гадкость» (Nastiness) — наименее приятные и наиболее активные
3. «Мягкость» (Softness) — наиболее приятные и наименее активные
4. «Грустность» (Sadness) — наименее приятные и наименее активные
Оказалось, что МакКартни использовал на 2% больше «приятных» слов, чем Леннон, который использовал больше «гадких», «мягких» и «грустных» слов.
Часы эмоций
Для наглядной демонстрации результатов своих исследований Уиссел использовала т.н. часы эмоций. Схема прикреплена ниже.
Это пространство с двумя осями — оценки и активности. Значения, которые проставляются в этой системе координат, не абсолютные: они нормализованы относительно корпуса из около 50 текстов, включающих в себя художественную литературу, эссе студентов, описания людьми собственных эмоций.
Чем интенсивнее эмоции в тексте, тем вектор (т. е. расстояние от центра до точки, обозначающей текст) будет длиннее, а в зависимости от угла, который образует этот вектор, меняется и общее настроение текста. Для этого и нужна окружность, на которой обозначены различные эмоции.
В среднем все песни Битлз оказываются более «радостными», чем подобранный корпус. А по отдельности песни по-разному располагаются на часах: самой «депрессивной» оказывается песня Джона Леннона «Nowhere Man», самой «приятной» — песня Пола Маккартни «I’ll Follow the Sun».
Сложно понять, насколько эти данные достоверны. Однако интересно, что субъективное мнение критиков, что песни Джона более грустные, как будто подтверждается методами эмоциональной стилометрии. Если два разных подхода к анализу текстов приходят к одному выводу, оба подхода становятся легитимнее, и поэтому, возможно, у эмоциональной стилометрии есть право на существование.
Миша Сонькин
https://sysblok.ru/philology/kak-menjalis-pesni-bitlov-i-mozhno-li-vychislit-jemocii-kompjuternymi-metodami/
{kind=link}
Как вам может помочь музыкальный поисковик Musipedia
#musicology
Тун, тун, ту-тун, тун-тутун, тун-тутууун… Угадали?
Musipedia — Википедия от мира музыки — способна определить мелодию, навязчивый мотив которой не отпускает вас уже несколько дней. Это постоянно обновляемая коллекция музыки со всего мира. В библиотеке проекта более 30 тысяч треков: от сонат Бетховена до Rolling Stones.
«Musipedia» была создана в 2002 году Райнэром Типке, выпускником старейшего в Германии Технологического института Карлсруэ. Сами авторы отмечают, что «Musipedia» была вдохновлена Википедией, однако не является ее частью.
Поисковик позволяет найти и идентифицировать музыку, даже если вы знаете только её приблизительное звучание. Ввести мелодию в поисковик можно разными способами:
1. Наиграть на подключенной MIDI-клавиатуре.
Она похожа на синтезатор, но для извлечения звука в большинстве случаев ей требуется подключение к компьютеру, так как у нее нет встроенных колонок. Обычно она используется преимущественно для звукозаписи.
2. Ввести с клавиатуры компьютера.
Можно отбить только ритм песни на клавише «space», а можно — наиграть мелодию на клавишах (каждая клавиша будет отвечать за определенную ноту).
3. Ввести при помощи компьютерной мыши и виртуальных клавиш.
Ниже прикреплен скрин электронной клавиатуры сайта.
4. Насвистеть или напеть в микрофон.
5. Использовать код Парсонса.
Это код для мелодических контуров, в которых происходит так называемое «melodic motion» — движение мелодии вверх или вниз относительно тона предыдущей ноты. Если нота выше предыдущей, она отмечается латинской U (Up), ниже — D (Down), повторяет звучание — R (Repeat). Первая нота отмечается звездочкой ().
На основе такой записи знаменитая колыбельная «Twinkle Twinkle Little Star» будет звучать следующим образом: RURURDDRDRDRDURDRDRDURDRDRDDRURURDDRDRDRD. В русском языке на ту же мелодию играется детская песенка «Как под горкой — под горой».
Когда пользователь набрал мелодию, алгоритм начинает подбор наиболее похожих на нее песен из коллекции «Musipedia». Эту коллекцию можно и пополнить, загрузив трек на сайт. Далее алгоритм программы самостоятельно переведет ноты на понятный ему язык и добавит предложенную мелодию в общую коллекцию. Сайт использует язык нотной записи LilyPond, где каждой ноте соответствует своя буква. Таким образом, привычный нотный стан больше напоминает текстовый документ (‘до’= ‘c’, ‘ре’ = ‘d’ и т. д.).
Мария Черных
https://sysblok.ru/musicology/muzykalnyj-poiskovik-musipedia-ot-mocarta-do-jeltona-dzhona/
#musicology
Тун, тун, ту-тун, тун-тутун, тун-тутууун… Угадали?
Musipedia — Википедия от мира музыки — способна определить мелодию, навязчивый мотив которой не отпускает вас уже несколько дней. Это постоянно обновляемая коллекция музыки со всего мира. В библиотеке проекта более 30 тысяч треков: от сонат Бетховена до Rolling Stones.
«Musipedia» была создана в 2002 году Райнэром Типке, выпускником старейшего в Германии Технологического института Карлсруэ. Сами авторы отмечают, что «Musipedia» была вдохновлена Википедией, однако не является ее частью.
Поисковик позволяет найти и идентифицировать музыку, даже если вы знаете только её приблизительное звучание. Ввести мелодию в поисковик можно разными способами:
1. Наиграть на подключенной MIDI-клавиатуре.
Она похожа на синтезатор, но для извлечения звука в большинстве случаев ей требуется подключение к компьютеру, так как у нее нет встроенных колонок. Обычно она используется преимущественно для звукозаписи.
2. Ввести с клавиатуры компьютера.
Можно отбить только ритм песни на клавише «space», а можно — наиграть мелодию на клавишах (каждая клавиша будет отвечать за определенную ноту).
3. Ввести при помощи компьютерной мыши и виртуальных клавиш.
Ниже прикреплен скрин электронной клавиатуры сайта.
4. Насвистеть или напеть в микрофон.
5. Использовать код Парсонса.
Это код для мелодических контуров, в которых происходит так называемое «melodic motion» — движение мелодии вверх или вниз относительно тона предыдущей ноты. Если нота выше предыдущей, она отмечается латинской U (Up), ниже — D (Down), повторяет звучание — R (Repeat). Первая нота отмечается звездочкой ().
На основе такой записи знаменитая колыбельная «Twinkle Twinkle Little Star» будет звучать следующим образом: RURURDDRDRDRDURDRDRDURDRDRDDRURURDDRDRDRD. В русском языке на ту же мелодию играется детская песенка «Как под горкой — под горой».
Когда пользователь набрал мелодию, алгоритм начинает подбор наиболее похожих на нее песен из коллекции «Musipedia». Эту коллекцию можно и пополнить, загрузив трек на сайт. Далее алгоритм программы самостоятельно переведет ноты на понятный ему язык и добавит предложенную мелодию в общую коллекцию. Сайт использует язык нотной записи LilyPond, где каждой ноте соответствует своя буква. Таким образом, привычный нотный стан больше напоминает текстовый документ (‘до’= ‘c’, ‘ре’ = ‘d’ и т. д.).
Мария Черных
https://sysblok.ru/musicology/muzykalnyj-poiskovik-musipedia-ot-mocarta-do-jeltona-dzhona/
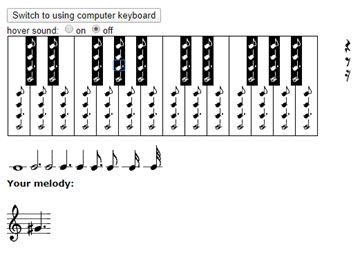{kind=link}
Музеи — передовики цифровизации: кто вносит больше объектов в Госкаталог музейного фонда
#opendata #открытыеданные
Госкаталог РФ — инициатива Министерства культуры по оцифровке всего российского музейного фонда. Государственные музеи в России обязаны оцифровывать свои фонды и вносить их в Госкаталог. Но размеры музеев не равны, как не равны и их возможности по оцифровке. Нам стало интересно исследовать это неравенство и посчитать, чьих объектов в Госкаталоге больше всего.
Как выяснилось, 1% музеев внес почти треть работ каталога (32%). По количеству это как полторы коллекции Эрмитажа. В среднем каждый из этих музеев оцифровал почти половину своей коллекции (45%) и выложил 225 тыс. экспонатов. Сам Эрмитаж тоже входит в топ 1% и выложил 15% своих экспонатов.
В этот 1% входит 24 учреждения федерального уровня или из крупных городов. В основном это музеи с большими коллекциями, суммарный объем которых больше четверти всего музейного фонда (28%).
10 музеев из топа находятся в Москве. Лидер по числу оцифрованных объектов — театральный музей имени Бахрушина: оцифровано более 622 тыс. работ (46% коллекции). Помимо декораций и афиш, около 500 тыс. из них посвящены грампластинкам и жизни генерального директора. Например, это фотографии приглашений на мероприятия и благодарностей.
Лидер по доле оцифрованной коллекции находится уже в регионе. Это Владимиро-Суздальский музей-заповедник. Его сотрудники внесли в Госкаталог 96% экспонатов — более 314 тыс. работ. Основные активы заповедника — древние соборы из списка ЮНЕСКО. В электронном виде музей предоставляет фотографии предметов быта: книг, грампластинок, сувениров из стекла и материалов раскопок.
Помимо Владимиро-Суздальского в топе оказались еще 6 музеев-заповедников: Новгородский (361 тыс. оцифрованных объектов), Ставропольский (128 тыс.), Смоленский (117 тыс.), Ростово-Ярославский (88 тыс.), Тобольский (87 тыс.) и Петергоф (99 тыс.).
В начале 2020 каталог Музейного фонда включает более 16 млн оцифрованных и описанных экспонатов, что больше четверти от общей коллекции музеев России (61,6 млн объектов в конце 2018). 2218 музеев внесли свои экспонаты в каталог. В среднем каждый выложил 7 тыс. объектов.
Данные: Минкульт
Ксения Тихомирова
#opendata #открытыеданные
Госкаталог РФ — инициатива Министерства культуры по оцифровке всего российского музейного фонда. Государственные музеи в России обязаны оцифровывать свои фонды и вносить их в Госкаталог. Но размеры музеев не равны, как не равны и их возможности по оцифровке. Нам стало интересно исследовать это неравенство и посчитать, чьих объектов в Госкаталоге больше всего.
Как выяснилось, 1% музеев внес почти треть работ каталога (32%). По количеству это как полторы коллекции Эрмитажа. В среднем каждый из этих музеев оцифровал почти половину своей коллекции (45%) и выложил 225 тыс. экспонатов. Сам Эрмитаж тоже входит в топ 1% и выложил 15% своих экспонатов.
В этот 1% входит 24 учреждения федерального уровня или из крупных городов. В основном это музеи с большими коллекциями, суммарный объем которых больше четверти всего музейного фонда (28%).
10 музеев из топа находятся в Москве. Лидер по числу оцифрованных объектов — театральный музей имени Бахрушина: оцифровано более 622 тыс. работ (46% коллекции). Помимо декораций и афиш, около 500 тыс. из них посвящены грампластинкам и жизни генерального директора. Например, это фотографии приглашений на мероприятия и благодарностей.
Лидер по доле оцифрованной коллекции находится уже в регионе. Это Владимиро-Суздальский музей-заповедник. Его сотрудники внесли в Госкаталог 96% экспонатов — более 314 тыс. работ. Основные активы заповедника — древние соборы из списка ЮНЕСКО. В электронном виде музей предоставляет фотографии предметов быта: книг, грампластинок, сувениров из стекла и материалов раскопок.
Помимо Владимиро-Суздальского в топе оказались еще 6 музеев-заповедников: Новгородский (361 тыс. оцифрованных объектов), Ставропольский (128 тыс.), Смоленский (117 тыс.), Ростово-Ярославский (88 тыс.), Тобольский (87 тыс.) и Петергоф (99 тыс.).
В начале 2020 каталог Музейного фонда включает более 16 млн оцифрованных и описанных экспонатов, что больше четверти от общей коллекции музеев России (61,6 млн объектов в конце 2018). 2218 музеев внесли свои экспонаты в каталог. В среднем каждый выложил 7 тыс. объектов.
Данные: Минкульт
Ксения Тихомирова
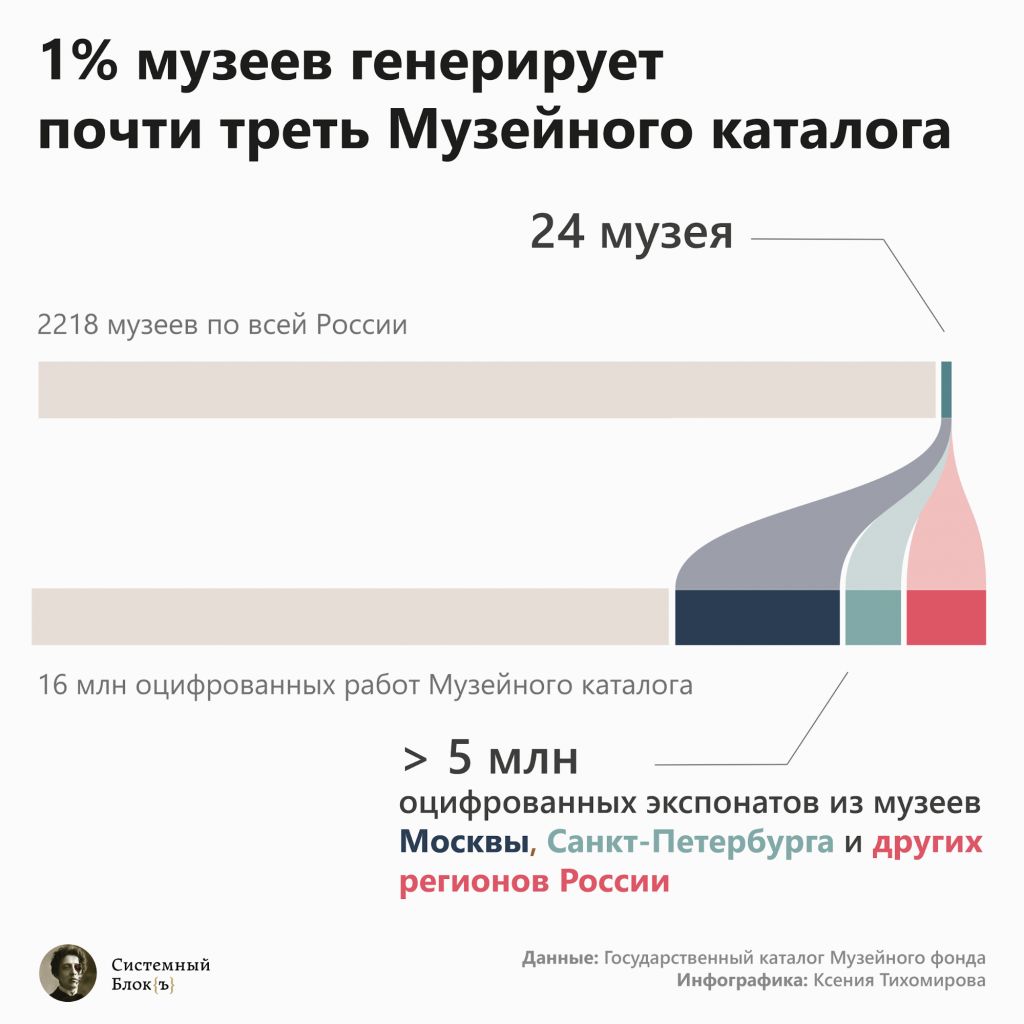{kind=link}
Поясни за смайлик: смех и слезы в интернете
#philology
Рассказываем, как люди начали пользоваться эмотиконами и как теперь их семантику изучают компьютерными методами. Посвящается тем, кто хотя бы раз не понял, что означает сообщение со смайликом.
В письменной речи смайлики — главный способ выражения эмоций: они заменяют интонацию и жесты; могут выступать в качестве слов или выражать отношение говорящего к ситуации.
Смайлики не всегда легко проинтерпретировать, однако и со словами может возникнуть та же проблема. Чтобы понять значение слова, мы обычно смотрим на контекст. Со смайликами этот метод тоже работает. Если контекст не помогает, можно обратиться к словарю.
Разработчики Unicode создали настоящий словарь с описаниями изображений, но вряд ли люди туда часто заглядывают, потому что у смайликов есть преимущество перед словами — визуальная информация. Глядя на слово, мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству.
Цифровые исследования семантики смайликов
Специалисты в области NLP используют эти идеи для переноса значения смайликов в машиночитаемый формат. Ученые уже давно пользуются моделями, которые переводят слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову.
Впервые анализ эмодзи провели в 2015 году. Томас Димсон, один из разработчиков Инстаграма, обучил word2vec на выборке в 50 млн комментариев и поделился результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании — в нашей статье.
Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы. Для оценки близости смайликов были предложены два критерия:
1. сходство (можно ли заменить один смайлик другим);
2. соотнесенность (можно ли встретить эти смайлики в одном контексте).
Группа респондентов также оценила 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов.
Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Визуализация прикреплена ниже: чем ближе смайлики, тем больше они похожи. На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки, буквенных символов и растений.
Лондонские NLP-специалисты пошли другим путем. В 2016 году они представили своеобразное расширение для традиционной предобученной модели word2vec — emoji2vec. Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений, однако попытки пока не увенчались успехом.
Аня Аксенова
Подробнее читайте по ссылке: https://sysblok.ru/philology/pojasni-za-smajlik-smeh-i-slezy-v-internete/
#philology
Рассказываем, как люди начали пользоваться эмотиконами и как теперь их семантику изучают компьютерными методами. Посвящается тем, кто хотя бы раз не понял, что означает сообщение со смайликом.
В письменной речи смайлики — главный способ выражения эмоций: они заменяют интонацию и жесты; могут выступать в качестве слов или выражать отношение говорящего к ситуации.
Смайлики не всегда легко проинтерпретировать, однако и со словами может возникнуть та же проблема. Чтобы понять значение слова, мы обычно смотрим на контекст. Со смайликами этот метод тоже работает. Если контекст не помогает, можно обратиться к словарю.
Разработчики Unicode создали настоящий словарь с описаниями изображений, но вряд ли люди туда часто заглядывают, потому что у смайликов есть преимущество перед словами — визуальная информация. Глядя на слово, мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству.
Цифровые исследования семантики смайликов
Специалисты в области NLP используют эти идеи для переноса значения смайликов в машиночитаемый формат. Ученые уже давно пользуются моделями, которые переводят слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову.
Впервые анализ эмодзи провели в 2015 году. Томас Димсон, один из разработчиков Инстаграма, обучил word2vec на выборке в 50 млн комментариев и поделился результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании — в нашей статье.
Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы. Для оценки близости смайликов были предложены два критерия:
1. сходство (можно ли заменить один смайлик другим);
2. соотнесенность (можно ли встретить эти смайлики в одном контексте).
Группа респондентов также оценила 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов.
Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Визуализация прикреплена ниже: чем ближе смайлики, тем больше они похожи. На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки, буквенных символов и растений.
Лондонские NLP-специалисты пошли другим путем. В 2016 году они представили своеобразное расширение для традиционной предобученной модели word2vec — emoji2vec. Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений, однако попытки пока не увенчались успехом.
Аня Аксенова
Подробнее читайте по ссылке: https://sysblok.ru/philology/pojasni-za-smajlik-smeh-i-slezy-v-internete/
{kind=link}
Как работают семантические поисковые системы
На примере поисковика по стихам А. С. Пушкина
#nlp
Как найти «то, не знаю что», а если точнее — совершить нечеткий поиск? Вот бы можно было найти в интернете «похожую мысль», «что-нибудь по теме» или «такое же по смыслу». Жаль, что напрямую со смыслом слов Гугл пока что работать не умеет… Зато нечто похожее умеет маленький поисковик по стихам Пушкина.
Посмотрите на скрине ниже, что нашел этот поисковик по запросу «интернет». Как так получилось, что, хотя Пушкин не писал про интернет, поисковик нашел в его стихах строчки про книгу, в которой можно «искать и найти»? Ответ: благодаря семантическим векторам.
Семантический вектор слова
Лингвист Джон Руперт Фёрс однажды сказал: «Слово узнаешь по его окружению». Грубо говоря, на этой гипотезе строится основа дистрибутивной семантики — направления лингвистики, которое вычисляет, насколько близки два слова по смыслу, исходя из частоты их совместной встречаемости в текстовых корпусах.
Так можно найти синонимы и антонимы к слову или классифицировать его в тематический «отдел»; автоматически определить тематику документа, не давая прочесть его человеку; постараться смоделировать перифразы или выяснить правила сочетаемости слов.
Для таких операций каждому новому слову нужно присвоить набор чисел, характеризующий его смысл. Этот набор называется семантическим вектором слова. Его вычисляют на больших корпусах текстов.
В 2013 году Томаш Миколов разработал систему Word2vec, которая строит для слов векторы заданной размерности. Метод Миколова состоит в применении двух нейронных моделей: continuous bag-of-words (CBOW) и skip-gram. Первый предсказывает слово на основе данного контекста, а второй — наоборот, старается угадать контекст данного слова. В результате слова, встречающиеся в тексте в одинаковом окружении (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.
Семантический поисковик по стихам А. С. Пушкина
На сайте RusVectores выложены готовые наборы семантических векторов для огромного числа слов, полученные после обработки различных корпусов текстов алгоритмами word2vec с разными параметрами. Эти «векторные модели» можно скачать и использовать как готовую базу данных семантических векторов. Пользуясь этой возможностью, пользователь GitLab opennota написал семантический поисковик по стихам А. С. Пушкина.
Интерфейс программы — поле запроса, где пользователь может ввести слово или группу слов. Введенный запрос сохраняется в буфер обмена, где морфологический анализатор pymorphy2 распознает формы и леммы слов.
Для каждого слова запроса из предварительно рассчитанной модели word2vec извлекается семантический вектор. В случае, если поисковой запрос содержал несколько слов, их векторы суммируются и нормализуются.
Извлечение векторов отдельных слов, их суммирование и нормализация происходит также для каждого четверостишия из используемой базы данных: эта процедура реализуется при запуске программы. В результате для каждого четверостишия составляется единый семантический вектор.
После получения нормализованного вектора поискового запроса рассчитываются показатели косинусной близости вектора запроса и каждого из векторов четверостиший. Показатели сравниваются и программа выдает строфы, чей семантический вектор ближе всего к вектору слов из поискового запроса.
Поиск дает результаты и тогда, когда очевидно, что слова из поискового запроса не могут встречаться в произведениях Пушкина.
Данный пример демонстрирует, что при помощи инструментов word2vec и проекта RusVectores можно проводить семантический анализ и категоризацию текстов, выполняя поиск по нечетким критериям. Исследователь, работающий с подобной системой, сможет отыскать нестандартные контексты и значения лексических единиц на большом объеме данных.
Владимир Селеверстов
Больше подробностей в статье: https://sysblok.ru/philology/pushkin-terminator-i-zvezdolet/
На примере поисковика по стихам А. С. Пушкина
#nlp
Как найти «то, не знаю что», а если точнее — совершить нечеткий поиск? Вот бы можно было найти в интернете «похожую мысль», «что-нибудь по теме» или «такое же по смыслу». Жаль, что напрямую со смыслом слов Гугл пока что работать не умеет… Зато нечто похожее умеет маленький поисковик по стихам Пушкина.
Посмотрите на скрине ниже, что нашел этот поисковик по запросу «интернет». Как так получилось, что, хотя Пушкин не писал про интернет, поисковик нашел в его стихах строчки про книгу, в которой можно «искать и найти»? Ответ: благодаря семантическим векторам.
Семантический вектор слова
Лингвист Джон Руперт Фёрс однажды сказал: «Слово узнаешь по его окружению». Грубо говоря, на этой гипотезе строится основа дистрибутивной семантики — направления лингвистики, которое вычисляет, насколько близки два слова по смыслу, исходя из частоты их совместной встречаемости в текстовых корпусах.
Так можно найти синонимы и антонимы к слову или классифицировать его в тематический «отдел»; автоматически определить тематику документа, не давая прочесть его человеку; постараться смоделировать перифразы или выяснить правила сочетаемости слов.
Для таких операций каждому новому слову нужно присвоить набор чисел, характеризующий его смысл. Этот набор называется семантическим вектором слова. Его вычисляют на больших корпусах текстов.
В 2013 году Томаш Миколов разработал систему Word2vec, которая строит для слов векторы заданной размерности. Метод Миколова состоит в применении двух нейронных моделей: continuous bag-of-words (CBOW) и skip-gram. Первый предсказывает слово на основе данного контекста, а второй — наоборот, старается угадать контекст данного слова. В результате слова, встречающиеся в тексте в одинаковом окружении (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.
Семантический поисковик по стихам А. С. Пушкина
На сайте RusVectores выложены готовые наборы семантических векторов для огромного числа слов, полученные после обработки различных корпусов текстов алгоритмами word2vec с разными параметрами. Эти «векторные модели» можно скачать и использовать как готовую базу данных семантических векторов. Пользуясь этой возможностью, пользователь GitLab opennota написал семантический поисковик по стихам А. С. Пушкина.
Интерфейс программы — поле запроса, где пользователь может ввести слово или группу слов. Введенный запрос сохраняется в буфер обмена, где морфологический анализатор pymorphy2 распознает формы и леммы слов.
Для каждого слова запроса из предварительно рассчитанной модели word2vec извлекается семантический вектор. В случае, если поисковой запрос содержал несколько слов, их векторы суммируются и нормализуются.
Извлечение векторов отдельных слов, их суммирование и нормализация происходит также для каждого четверостишия из используемой базы данных: эта процедура реализуется при запуске программы. В результате для каждого четверостишия составляется единый семантический вектор.
После получения нормализованного вектора поискового запроса рассчитываются показатели косинусной близости вектора запроса и каждого из векторов четверостиший. Показатели сравниваются и программа выдает строфы, чей семантический вектор ближе всего к вектору слов из поискового запроса.
Поиск дает результаты и тогда, когда очевидно, что слова из поискового запроса не могут встречаться в произведениях Пушкина.
Данный пример демонстрирует, что при помощи инструментов word2vec и проекта RusVectores можно проводить семантический анализ и категоризацию текстов, выполняя поиск по нечетким критериям. Исследователь, работающий с подобной системой, сможет отыскать нестандартные контексты и значения лексических единиц на большом объеме данных.
Владимир Селеверстов
Больше подробностей в статье: https://sysblok.ru/philology/pushkin-terminator-i-zvezdolet/
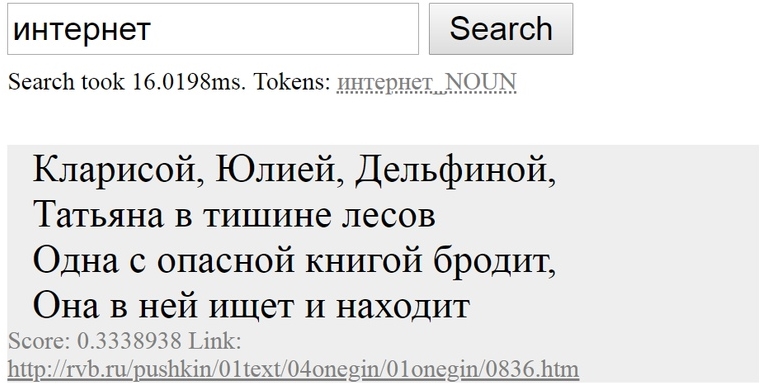{kind=link}
У вас стресс, Бэрримор!
#society #history
Сегодня нас раздражают электронная почта, поток каналов в мессенджерах и всяческий киберпанк. Викторианцев же нервировали бесконечные телеграммы, сообщения из газет и… всяческий стимпанк.
В 1869 году американский врач Джордж Миллер Берд выявил новую болезнь. Он дал ей название «неврастения» или «нервное истощение». В ее основе лежало пять элементов — символов XIX века. Ими были паровая энергетика, пресса, телеграфия, развитие науки и рост умственной и профессиональной деятельности женщин. Так появилось понятие «стресс».
Проект «Болезни современной жизни»
Вопрос о возникновении стресса был подробно рассмотрен в исследовательском проекте «Болезни современной жизни». Он финансировался Европейским советом по исследованиям и продолжался с 2014 по 2019 годы. Идея принадлежала Салли Шаттлворт, преподавательнице на факультете английского языка в колледже св. Анны в Оксфорде. В рамках проета изучались явления стресса, перегрузки и другие расстройства в XIX веке. Целью проекта было преодоление разделения психиатрической, экологической и литературной истории и исследование социокультурных явлений в совокупности.
Исследователи предлагали новые способы определения контекста проблем современности в XIX веке. Для этого они опирались на литературу, науку и медицину викторианской эпохи. Это позволило отследить распространение идей тревоги и беспокойства в различных областях. Особое внимание участники уделили роли печати: они рассматривали ее как причину обострения тревог и источник нервозности.
Причины появления стресса
Викторианская эпоха стала временем сильных потрясений и открытий. Ускорился не только технический прогресс, но и само время. Набирала силу урбанизация, строились новые железные дороги и фабрики, появлялись новые социальные классы. Пространства становились все более беспорядочными в социальном отношении. Перемены повлияли на сознание и настроение масс.
В июле 1862 года писатель и литературный критик Эдвард Бульвер-Литтон провел опрос среди британцев. Он обнаружил, что симптомы тревоги стали частью общества. «В состоянии цивилизации, в которой мы пребываем, теперь чаще жалуются из-за переутомления мозга …, нервного истощения и болезни, вызванными чрезмерным раздражением и длительной усталостью …».
По мнению Бульвера-Литтона, «высокоразвитое цивилизованное государство» с помощью прогресса оказывало сильное давление на людей. Этот механизм стал автономной силой, которую стало невозможно контролировать. В результате индустриализация и тревожность британцев создали страх перед современностью. Викторианцы столкнулись с созданной ими реальностью, что и породило стресс. Ниже на рисунке можно увидеть, как, по мнению викторианцев, выглядел этот «безумный новый мир».
О том, чего конкретно боялись британцы и как их лечили от стресса, читайте в нашей статье: https://sysblok.ru/society/u-vas-stress-bjerrimor/
#society #history
Сегодня нас раздражают электронная почта, поток каналов в мессенджерах и всяческий киберпанк. Викторианцев же нервировали бесконечные телеграммы, сообщения из газет и… всяческий стимпанк.
В 1869 году американский врач Джордж Миллер Берд выявил новую болезнь. Он дал ей название «неврастения» или «нервное истощение». В ее основе лежало пять элементов — символов XIX века. Ими были паровая энергетика, пресса, телеграфия, развитие науки и рост умственной и профессиональной деятельности женщин. Так появилось понятие «стресс».
Проект «Болезни современной жизни»
Вопрос о возникновении стресса был подробно рассмотрен в исследовательском проекте «Болезни современной жизни». Он финансировался Европейским советом по исследованиям и продолжался с 2014 по 2019 годы. Идея принадлежала Салли Шаттлворт, преподавательнице на факультете английского языка в колледже св. Анны в Оксфорде. В рамках проета изучались явления стресса, перегрузки и другие расстройства в XIX веке. Целью проекта было преодоление разделения психиатрической, экологической и литературной истории и исследование социокультурных явлений в совокупности.
Исследователи предлагали новые способы определения контекста проблем современности в XIX веке. Для этого они опирались на литературу, науку и медицину викторианской эпохи. Это позволило отследить распространение идей тревоги и беспокойства в различных областях. Особое внимание участники уделили роли печати: они рассматривали ее как причину обострения тревог и источник нервозности.
Причины появления стресса
Викторианская эпоха стала временем сильных потрясений и открытий. Ускорился не только технический прогресс, но и само время. Набирала силу урбанизация, строились новые железные дороги и фабрики, появлялись новые социальные классы. Пространства становились все более беспорядочными в социальном отношении. Перемены повлияли на сознание и настроение масс.
В июле 1862 года писатель и литературный критик Эдвард Бульвер-Литтон провел опрос среди британцев. Он обнаружил, что симптомы тревоги стали частью общества. «В состоянии цивилизации, в которой мы пребываем, теперь чаще жалуются из-за переутомления мозга …, нервного истощения и болезни, вызванными чрезмерным раздражением и длительной усталостью …».
По мнению Бульвера-Литтона, «высокоразвитое цивилизованное государство» с помощью прогресса оказывало сильное давление на людей. Этот механизм стал автономной силой, которую стало невозможно контролировать. В результате индустриализация и тревожность британцев создали страх перед современностью. Викторианцы столкнулись с созданной ими реальностью, что и породило стресс. Ниже на рисунке можно увидеть, как, по мнению викторианцев, выглядел этот «безумный новый мир».
О том, чего конкретно боялись британцы и как их лечили от стресса, читайте в нашей статье: https://sysblok.ru/society/u-vas-stress-bjerrimor/
{kind=link}
Сигнал в будущее: как сообщить потомкам о ядерной угрозе
#society
Около 70 лет прошло с тех пор, как человечество научилось расщеплять атом. За это время на Земле скопилось около 300 тысяч тонн высококонцентрированных радиоактивных отходов, которые будут представлять опасность в течение 100 тысяч лет. Создание прочного и надежного места для захоронения отходов — одна из важнейших инженерных задач современности. В то же время философы, семиотики и лингвисты должны разработать предупреждающий об опасности знак, который будет понятен в будущем более отдаленном, чем мы можем себе представить.
Сейчас проблема ядерных отходов решается их захоронением в геологически стабильных местах нашей планеты. По всему миру разрабатываются и возводятся такие сооружения с расчетом, что отработанное ядерное топливо и другие радиоактивные отходы смогут храниться там от 10 до 100 тысяч лет без какого-либо обслуживания. Наоборот, после того как объект консервируется, вмешательство человека оказывается куда большей проблемой, чем естественный износ или природные катаклизмы.
Экспертное заключение национальных лабораторий Сандия в США предложило три обобщенных сценария развития технологии в будущем: устойчивое развитие, устойчивый упадок и колебание между резкими научными прорывами и крахом технологий. Именно третий сценарий представляет наибольшие опасения, потому что в моменты взлета технологий люди будут иметь техническую возможность обнаружить место захоронения отходов и нарушить его целостность, в то время как периоды упадка могут прервать культурную преемственность человечества настолько, что знания об опасности ядерных отходов затеряются.
Как сделать так, чтобы наши далекие потомки не отнеслись к предупреждениям о реальной опасности так, как мы относимся к проклятиям на египетских пирамидах? В качестве возможных решений:
— атомное братство;
— меняющие цвет коты;
— искусственная луна;
— «Черная дыра»: огромный монолитный блок из черного материала, который поглощает жар пустыни и отражает его, создавая невыносимо высокую температуру вокруг себя;
— «Поле шипов», на котором в случайном порядке построены 15-метровые шипы, наводящие на мысли об опасности;
— наконец, наиболее вероятный сценарий: создание системы долговечных знаков, избыточно маркирующих местонахождение радиоактивных отходов.
Подробнее о каждом из возможных решений — в нашей статье:
https://sysblok.ru/society/signal-v-budushhee-vash-kot-soobshhaet-o-jadernoj-ugroze/
#society
Около 70 лет прошло с тех пор, как человечество научилось расщеплять атом. За это время на Земле скопилось около 300 тысяч тонн высококонцентрированных радиоактивных отходов, которые будут представлять опасность в течение 100 тысяч лет. Создание прочного и надежного места для захоронения отходов — одна из важнейших инженерных задач современности. В то же время философы, семиотики и лингвисты должны разработать предупреждающий об опасности знак, который будет понятен в будущем более отдаленном, чем мы можем себе представить.
Сейчас проблема ядерных отходов решается их захоронением в геологически стабильных местах нашей планеты. По всему миру разрабатываются и возводятся такие сооружения с расчетом, что отработанное ядерное топливо и другие радиоактивные отходы смогут храниться там от 10 до 100 тысяч лет без какого-либо обслуживания. Наоборот, после того как объект консервируется, вмешательство человека оказывается куда большей проблемой, чем естественный износ или природные катаклизмы.
Экспертное заключение национальных лабораторий Сандия в США предложило три обобщенных сценария развития технологии в будущем: устойчивое развитие, устойчивый упадок и колебание между резкими научными прорывами и крахом технологий. Именно третий сценарий представляет наибольшие опасения, потому что в моменты взлета технологий люди будут иметь техническую возможность обнаружить место захоронения отходов и нарушить его целостность, в то время как периоды упадка могут прервать культурную преемственность человечества настолько, что знания об опасности ядерных отходов затеряются.
Как сделать так, чтобы наши далекие потомки не отнеслись к предупреждениям о реальной опасности так, как мы относимся к проклятиям на египетских пирамидах? В качестве возможных решений:
— атомное братство;
— меняющие цвет коты;
— искусственная луна;
— «Черная дыра»: огромный монолитный блок из черного материала, который поглощает жар пустыни и отражает его, создавая невыносимо высокую температуру вокруг себя;
— «Поле шипов», на котором в случайном порядке построены 15-метровые шипы, наводящие на мысли об опасности;
— наконец, наиболее вероятный сценарий: создание системы долговечных знаков, избыточно маркирующих местонахождение радиоактивных отходов.
Подробнее о каждом из возможных решений — в нашей статье:
https://sysblok.ru/society/signal-v-budushhee-vash-kot-soobshhaet-o-jadernoj-ugroze/
{kind=link}
#best
Вчера отмечали международный день архивов. В честь этого события предлагаем вспомнить лучшие посты Системного Блока о цифровых архивах и сохранении данных.
Оцифровать Французскую революцию:
- Парламентские архивы
Рассказываем об архивах парламента Французской революции — того самого парламента, из которого вырос почти весь современный парламентаризм, а также классическое разделение на левых и правых. Оцифровка парламентских архивов — один из самых крупных проектов по дигитализации исторического наследия. Рассказываем, кто, как и зачем это сделал.
- Коллекция Бодуэна
Еще одна цифровая коллекция из времен Французской революции. Франсуа-Жан Бодуэн стал официальным печатником Национальной ассамблеи в июне 1789 года, когда предыдущая типография отказалась обслуживать взбунтовавшееся третье сословие. Его главной задачей было быстрое и качественное издание всех решений, вынесенных Ассамблеей. Изданные им шестьдесят семь томов Collection générale des décrets оказались наиболее полным и заслуживающим доверия сборником, на основе которого была создана база данных Collection Baudoin.
Краудсорсинг в Digital Humanities: опыт Латвийского фольклорного архива
Фольклорный архив Латвии придумал много разных способов пополнять свои цифровые коллекции с привлечением волонтеров и медиа. Ценный опыт, если у вас нет миллионов долларов на оцифровку. Пользователям предложили создавать аудиоверсии любимых стихов, сканировать рукописи для оцифровки, загружать в архив собственные записи старинных песен.
Европейское культурное наследие онлайн
Подборка европейских цифровых архивов: сотни тысяч произведений искусства, старинных рукописей, музейных экспонатов — and much more.
Биты или манускрипт: кто выживет в борьбе со временем?
Оцифровка культурного наследия — это не просто дорого, но и сложно на технологическом и системно-стратегическом уровне. Как обеспечить сохранность данных не через 10, а через 100 лет? Что будет, если сервер архива сгорит? Какие именно данные сохранять, если гуманитариям и социальным исследователям может быть интересно все что угодно, от порносайтов до форумов любителей аквариумных рыбок, а любой рядовой пользователь твиттера может через 30 лет стать президентом? Большая и немного философская статья о трудностях цифрового сохранения.
Ноты — в цифру: как музыковеды собирают данные
Доступ к источникам всегда был проблемой для музыковедов. Еще несколько лет назад для того, чтобы ознакомиться с каким-нибудь редким документом, нужно было найти его местонахождение, пользуясь печатным каталогом, написать в библиотеку и ждать изготовления микрофильма. Процесс мог длиться месяцами. В цифровую эру ситуация изменилась. Рассказываем, как именно.
Вчера отмечали международный день архивов. В честь этого события предлагаем вспомнить лучшие посты Системного Блока о цифровых архивах и сохранении данных.
Оцифровать Французскую революцию:
- Парламентские архивы
Рассказываем об архивах парламента Французской революции — того самого парламента, из которого вырос почти весь современный парламентаризм, а также классическое разделение на левых и правых. Оцифровка парламентских архивов — один из самых крупных проектов по дигитализации исторического наследия. Рассказываем, кто, как и зачем это сделал.
- Коллекция Бодуэна
Еще одна цифровая коллекция из времен Французской революции. Франсуа-Жан Бодуэн стал официальным печатником Национальной ассамблеи в июне 1789 года, когда предыдущая типография отказалась обслуживать взбунтовавшееся третье сословие. Его главной задачей было быстрое и качественное издание всех решений, вынесенных Ассамблеей. Изданные им шестьдесят семь томов Collection générale des décrets оказались наиболее полным и заслуживающим доверия сборником, на основе которого была создана база данных Collection Baudoin.
Краудсорсинг в Digital Humanities: опыт Латвийского фольклорного архива
Фольклорный архив Латвии придумал много разных способов пополнять свои цифровые коллекции с привлечением волонтеров и медиа. Ценный опыт, если у вас нет миллионов долларов на оцифровку. Пользователям предложили создавать аудиоверсии любимых стихов, сканировать рукописи для оцифровки, загружать в архив собственные записи старинных песен.
Европейское культурное наследие онлайн
Подборка европейских цифровых архивов: сотни тысяч произведений искусства, старинных рукописей, музейных экспонатов — and much more.
Биты или манускрипт: кто выживет в борьбе со временем?
Оцифровка культурного наследия — это не просто дорого, но и сложно на технологическом и системно-стратегическом уровне. Как обеспечить сохранность данных не через 10, а через 100 лет? Что будет, если сервер архива сгорит? Какие именно данные сохранять, если гуманитариям и социальным исследователям может быть интересно все что угодно, от порносайтов до форумов любителей аквариумных рыбок, а любой рядовой пользователь твиттера может через 30 лет стать президентом? Большая и немного философская статья о трудностях цифрового сохранения.
Ноты — в цифру: как музыковеды собирают данные
Доступ к источникам всегда был проблемой для музыковедов. Еще несколько лет назад для того, чтобы ознакомиться с каким-нибудь редким документом, нужно было найти его местонахождение, пользуясь печатным каталогом, написать в библиотеку и ждать изготовления микрофильма. Процесс мог длиться месяцами. В цифровую эру ситуация изменилась. Рассказываем, как именно.
{kind=link}
«Республика учёных»: создание модели общества Раннего Нового времени
#history
Начиная с 15 века благодаря открытию новых университетов, изобретению печати и развитию почтовой системы, всё больше и больше образованных людей из разных стран могли связываться друг с другом, чтобы обсудить новые публикации, события или частную жизнь.
Таким образом, европейское научное сообщество оказалось неформально, но очень тесно связано. Сами себя члены этого огромного надгосударственного и независимого общества назвали respublica litteraria — республика учёных. Стать её частью можно было вне зависимости от происхождения или дохода, нужно было просто быть образованным и культурным человеком.
Самым важным и обширным свидетельством о существовании «республики» является корреспонденция, связывавшая воедино людей из разных концов мира. По приблизительным оценкам, с того времени до нас дошло более миллиона писем. Кроме того, сохранились различные сведения о путешествиях, религиозных обществах и университетах, а также книги, газеты и журналы.
Долгое время письма хранились в архивах, и ученым нужно было приложить усилия, чтобы получить к ним доступ. В наши дни ситуация улучшилась: много документов оцифровано и находится в открытом доступе. Нехватки источников уже давно нет, напротив, обилие информации делает невозможным всё проанализировать и составить общую картину происходящего. И здесь на помощь приходит Big Data.
С помощью инструментов Big Data можно узнать, как жили люди в эпоху Ренессанса и Просвещения, с кем они общались, где учились и о чём переписывались. Пошаговый анализ писем, а также визуализация результатов исследования — в нашей статье: https://sysblok.ru/history/respublika-uchjonyh-sozdanie-modeli-obshhestva-rannego-novogo-vremeni/
#history
Начиная с 15 века благодаря открытию новых университетов, изобретению печати и развитию почтовой системы, всё больше и больше образованных людей из разных стран могли связываться друг с другом, чтобы обсудить новые публикации, события или частную жизнь.
Таким образом, европейское научное сообщество оказалось неформально, но очень тесно связано. Сами себя члены этого огромного надгосударственного и независимого общества назвали respublica litteraria — республика учёных. Стать её частью можно было вне зависимости от происхождения или дохода, нужно было просто быть образованным и культурным человеком.
Самым важным и обширным свидетельством о существовании «республики» является корреспонденция, связывавшая воедино людей из разных концов мира. По приблизительным оценкам, с того времени до нас дошло более миллиона писем. Кроме того, сохранились различные сведения о путешествиях, религиозных обществах и университетах, а также книги, газеты и журналы.
Долгое время письма хранились в архивах, и ученым нужно было приложить усилия, чтобы получить к ним доступ. В наши дни ситуация улучшилась: много документов оцифровано и находится в открытом доступе. Нехватки источников уже давно нет, напротив, обилие информации делает невозможным всё проанализировать и составить общую картину происходящего. И здесь на помощь приходит Big Data.
С помощью инструментов Big Data можно узнать, как жили люди в эпоху Ренессанса и Просвещения, с кем они общались, где учились и о чём переписывались. Пошаговый анализ писем, а также визуализация результатов исследования — в нашей статье: https://sysblok.ru/history/respublika-uchjonyh-sozdanie-modeli-obshhestva-rannego-novogo-vremeni/
{kind=link}
Мама мыла LSTM: как устроены рекуррентные нейросети с долгой краткосрочной памятью
#knowhow
Системный Блокъ подготовил крафтовый техно-лонгрид, в котором разбирается по винтикам одна из самых ходовых технологий в современной компьютерной лингвистике — рекуррентные нейросети с архитектурой LSTM.
Именно на LSTM-сетях впервые взлетел качественный нейросетевой машинный перевод. Несмотря на бум нейросетей-трансформеров, о которых мы расскажем в наших следующих техно-лонгридах, рекуррентные LSTM-сети остаются одним из популярнейших рабочих инструментов в задачах машинной обработки естественного языка.
Зачем обрабатывать текст на компьютере
Было бы круто научить компьютер генерировать связный текст, выделять логические конструкции, потом делать с ними что-нибудь интересное, как умеет человек. Может получиться чат-бот, поисковая машина, «умная» клавиатура на телефоне, онлайн-переводчик, генератор пересказов.
Эти задачи решает обработка естественного языка. С ней есть сложности: в языке бывают омонимы, бывают многозначные слова. А что делать, если «Трофей не поместился в чемодан, потому что он был слишком большим»? Как тут программе сориентироваться, к чему относится слово «он»?
К счастью, речь людей статистически предсказуема. Есть популярные цепочки слов, которые повторяют почти все. Велика вероятность после слов «чайник уже» найти слово «вскипел». И напротив, есть последовательности, которые никогда не услышишь в речи. Например, «чайник уже… обиделся».
О чем рассказываем в статье:
— Как использовать неслучайность речи
— Как работает языковая модель на цепях Маркова без нейросетей
— Что такое рекуррентность
— Как RNN сохраняет свое состояние и передает его дальше
— Почему неэффективно передавать контекст со слоя на слой
— Что происходит внутри одного слоя нейронов
— Как работает LSTM — Long Short Term Memory
— Как реализуется забывание контекста в LSTM
— Как реализуется запоминание контекста в LSTM
— Как реализуется запись новых значений в контекст
— Как получается предсказание LSTM
Обо всем этом — в нашей статье: https://sysblok.ru/knowhow/mama-myla-lstm-kak-ustroeny-rekurrentnye-nejroseti-s-dolgoj-kratkosrochnoj-pamjatju/
#knowhow
Системный Блокъ подготовил крафтовый техно-лонгрид, в котором разбирается по винтикам одна из самых ходовых технологий в современной компьютерной лингвистике — рекуррентные нейросети с архитектурой LSTM.
Именно на LSTM-сетях впервые взлетел качественный нейросетевой машинный перевод. Несмотря на бум нейросетей-трансформеров, о которых мы расскажем в наших следующих техно-лонгридах, рекуррентные LSTM-сети остаются одним из популярнейших рабочих инструментов в задачах машинной обработки естественного языка.
Зачем обрабатывать текст на компьютере
Было бы круто научить компьютер генерировать связный текст, выделять логические конструкции, потом делать с ними что-нибудь интересное, как умеет человек. Может получиться чат-бот, поисковая машина, «умная» клавиатура на телефоне, онлайн-переводчик, генератор пересказов.
Эти задачи решает обработка естественного языка. С ней есть сложности: в языке бывают омонимы, бывают многозначные слова. А что делать, если «Трофей не поместился в чемодан, потому что он был слишком большим»? Как тут программе сориентироваться, к чему относится слово «он»?
К счастью, речь людей статистически предсказуема. Есть популярные цепочки слов, которые повторяют почти все. Велика вероятность после слов «чайник уже» найти слово «вскипел». И напротив, есть последовательности, которые никогда не услышишь в речи. Например, «чайник уже… обиделся».
О чем рассказываем в статье:
— Как использовать неслучайность речи
— Как работает языковая модель на цепях Маркова без нейросетей
— Что такое рекуррентность
— Как RNN сохраняет свое состояние и передает его дальше
— Почему неэффективно передавать контекст со слоя на слой
— Что происходит внутри одного слоя нейронов
— Как работает LSTM — Long Short Term Memory
— Как реализуется забывание контекста в LSTM
— Как реализуется запоминание контекста в LSTM
— Как реализуется запись новых значений в контекст
— Как получается предсказание LSTM
Обо всем этом — в нашей статье: https://sysblok.ru/knowhow/mama-myla-lstm-kak-ustroeny-rekurrentnye-nejroseti-s-dolgoj-kratkosrochnoj-pamjatju/
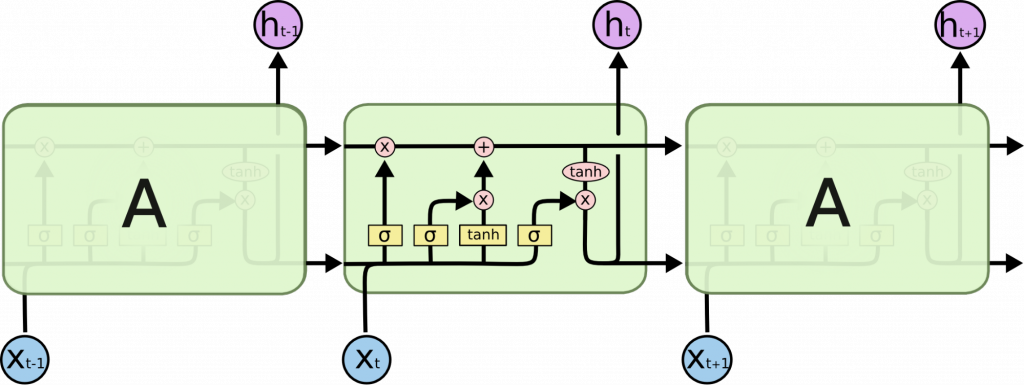{kind=link}
Как отслеживают мировую историю через анализ и визуализацию данных
На примере истории международных конгрессов XIX–XX веков
#history
Визуализация используется еще со времен Древнего Египта и майя. Со временем визуализация — способ отображения текстовой информации в более доступной форме на диаграммах, графиках или интерактивных картах — стала неотъемлемой частью любой науки. С недавнего времени она применяется и в качестве одного из ведущих методов изучения истории, ведь мировая история, записанная исключительно в текстовом формате или при помощи обычных карт, может быть трудна для восприятия.
Международные конгрессы
Развитие международного сотрудничества началось с самого начала человеческой истории. Вплоть до 20-го века, однако, это была скорее интернационализация, то есть кросскоммуникация между отдельными государствами. Привычная нам глобализация, когда все государства интегрируются в одну общую систему, не насчитывает в своей истории и ста лет.
Сегодня международные конгрессы — пережиток времен интернационализации — видятся как наследие ушедшей прекрасной эпохи. Они уступают место крупным всемирным организациям: ООН, НАТО, ВТО (а первой в их числе была Лига Наций, созданная после Первой Мировой войны).
Вокруг съездов и конгрессов со временем формируются организации, контролирующие их деятельность. Первой становится Союз Международных Ассоциаций (СМА). С 1907 он как неправительственный научно-исследовательский институт и центр документации ведет учет деятельности всех конгрессов и деятельности глобального гражданского общества.
Проект «Mapping a century of International Congresses»
Целью проекта «Mapping a century of International Congresses» стала визуализация огромного количества информации о более чем 8000 международных конгрессах 1840–1960 годов на основе документов ежегодных конгрессов и документации СМА.
Карты с акцентом на достоверность и точность были бы крайне громоздки и перенасыщены информацией, потому что они охватывают большую площадь и значительные временные рамки. Поэтому был выбран вариант, наиболее близкий к тепловым картам, где значения документации отображаются при помощи цвета или тона. Это позволило более просто визуализировать информацию.
Тепловая карта, прикрепленная ниже, позволяет с первого взгляда оценить распределение международных конгрессов по городам. Выделился «космпополитический треугольник»: три города, где чаще всего собирались конгрессмены, — Париж, Лондон, и Брюссель. Остальные города разделились на «европейский мегаполис» — урбанизированный район, протянувшийся от Манчестера на юг до Милана, и «периферийные столицы», в которых конгрессы проводились реже.
Анализ документации СМА
Для начала проанализировали рост числа конгрессов и их распределение по европейскому континенту. Выяснилось, что за весь период Европа приняла 85% от общего числа международных конгрессов. А до начала Первой Мировой так и все 92%. В то же время на территории Северной Америки проводится за все время чуть более 11% мероприятий.
Также создали гистограммы, которые отражают распределение конгрессов по городам между 1840 и 1960 годами. Из полученных данных были выявлены 12 ведущих стран, в разное время принимавших конгрессы на своей территории: Франция, Бельгия, Великобритания, Германия, Швейцария, США, Италия, Нидерладны, Австрия, Дания, Швеция и Испания.
По заявлениям самих исследователей подобный подход к представлению исторических данных помог понять процессы интернационализации международного сообщества и задокументировать общественно-научная история международных отношений.
Мария Черных
Все диаграммы и гистограммы — по ссылке: https://sysblok.ru/history/i-celogo-mira-malo-kak-otsledit-mirovuju-istoriju-cherez-analiz-i-vizualizaciju-dannyh/
На примере истории международных конгрессов XIX–XX веков
#history
Визуализация используется еще со времен Древнего Египта и майя. Со временем визуализация — способ отображения текстовой информации в более доступной форме на диаграммах, графиках или интерактивных картах — стала неотъемлемой частью любой науки. С недавнего времени она применяется и в качестве одного из ведущих методов изучения истории, ведь мировая история, записанная исключительно в текстовом формате или при помощи обычных карт, может быть трудна для восприятия.
Международные конгрессы
Развитие международного сотрудничества началось с самого начала человеческой истории. Вплоть до 20-го века, однако, это была скорее интернационализация, то есть кросскоммуникация между отдельными государствами. Привычная нам глобализация, когда все государства интегрируются в одну общую систему, не насчитывает в своей истории и ста лет.
Сегодня международные конгрессы — пережиток времен интернационализации — видятся как наследие ушедшей прекрасной эпохи. Они уступают место крупным всемирным организациям: ООН, НАТО, ВТО (а первой в их числе была Лига Наций, созданная после Первой Мировой войны).
Вокруг съездов и конгрессов со временем формируются организации, контролирующие их деятельность. Первой становится Союз Международных Ассоциаций (СМА). С 1907 он как неправительственный научно-исследовательский институт и центр документации ведет учет деятельности всех конгрессов и деятельности глобального гражданского общества.
Проект «Mapping a century of International Congresses»
Целью проекта «Mapping a century of International Congresses» стала визуализация огромного количества информации о более чем 8000 международных конгрессах 1840–1960 годов на основе документов ежегодных конгрессов и документации СМА.
Карты с акцентом на достоверность и точность были бы крайне громоздки и перенасыщены информацией, потому что они охватывают большую площадь и значительные временные рамки. Поэтому был выбран вариант, наиболее близкий к тепловым картам, где значения документации отображаются при помощи цвета или тона. Это позволило более просто визуализировать информацию.
Тепловая карта, прикрепленная ниже, позволяет с первого взгляда оценить распределение международных конгрессов по городам. Выделился «космпополитический треугольник»: три города, где чаще всего собирались конгрессмены, — Париж, Лондон, и Брюссель. Остальные города разделились на «европейский мегаполис» — урбанизированный район, протянувшийся от Манчестера на юг до Милана, и «периферийные столицы», в которых конгрессы проводились реже.
Анализ документации СМА
Для начала проанализировали рост числа конгрессов и их распределение по европейскому континенту. Выяснилось, что за весь период Европа приняла 85% от общего числа международных конгрессов. А до начала Первой Мировой так и все 92%. В то же время на территории Северной Америки проводится за все время чуть более 11% мероприятий.
Также создали гистограммы, которые отражают распределение конгрессов по городам между 1840 и 1960 годами. Из полученных данных были выявлены 12 ведущих стран, в разное время принимавших конгрессы на своей территории: Франция, Бельгия, Великобритания, Германия, Швейцария, США, Италия, Нидерладны, Австрия, Дания, Швеция и Испания.
По заявлениям самих исследователей подобный подход к представлению исторических данных помог понять процессы интернационализации международного сообщества и задокументировать общественно-научная история международных отношений.
Мария Черных
Все диаграммы и гистограммы — по ссылке: https://sysblok.ru/history/i-celogo-mira-malo-kak-otsledit-mirovuju-istoriju-cherez-analiz-i-vizualizaciju-dannyh/
{kind=link}