
«Прямо как в Plague. Inc!» Что объединяет игры и фильмы про эпидемии
#society
В связи с коронавирусом резко выросла популярность не самой новой (2012) игры Plague Inc. Цель игры — истребить или поработить человечество, используя смертельный патоген. Игрок управляет патогеном, наделяет его новыми симптомами и способами передачи. Обычные сюжетные роли перевернуты: злодей является протагонистом.
В последнее время стало появляться много шуток, связывающих игру и пандемию коронавируса. Люди начинают думать в терминах игры и используют игровые тропы для описания реального мира.
Тропы — повествовательные схемы, ментальные конструкции, которые обнаруживаются в разных видах творческих произведений (игры, фильмы, сериалы и прочее) — простой способ описания узнаваемых ситуаций, «кирпичики», составляющие повествование.
Мы решили узнать, какие тропы объединяют Plague Inc. и другие произведения, сюжет которых построен вокруг эпидемий. Для сравнения мы выбрали настольную игру Pandemic, фильмы Contagion и 28 Days Later и видео игру Left 4 Dead.
Мы использовали сетевой анализ. Анализируя тропы сетевым методом, можно быстро получить достаточно полное представление о самом произведении и понять, что его объединяет с другими: сразу видно общие детали сюжета или сеттинга.
Примеры тропов, которые встретились в нескольких произведениях:
Zombie Apocalypse (Зомби-апокалипсис)
Где встречается: Plague Inc., Pandemic, Left 4 Dead.
По-разному реализуется в каждой игре.
Patient Zero (Нулевой пациент)
Где встречается: Plague Inc., Contagion, Pandemic.
Первый зараженный может быть ключом к вакцине.
Ripped From The Headlines («Сюжет стащили из новостей») .
Где встречается: Contagion, Plague Inc., 28 Days Later
Здесь довольно любопытно то, что описание тропа несколько уже его фактического применения. Название и примеры передают больше информации, чем описание. Вкратце: общая канва истории основана на реальных событиях с некоторыми изменениями. Кроме того в Plague Inc. регулярно добавляют новые новости с отсылками, что делает структуру сложнее.
Spreading Disaster Map Graphic (Карта распространения вируса)
Где встречается: Plague Inc., Contagion, Pandemic
Карта с распространением вируса — прямо как в новостях
Oh, Crap! («О, чёрт!»)
Где присутствует: Plague Inc., Contagion, 28 Days Later, Left 4 Dead.
Момент осознания всего ужаса ситуации. Как говорится, «вы находитесь здесь».
Обо всех результатах и о том, как проводится сетевой анализ, читайте по ссылке: https://sysblok.ru/society/prjamo-kak-v-plague-inc-chto-obedinjaet-igry-i-filmy-pro-jepidemii/
#society
В связи с коронавирусом резко выросла популярность не самой новой (2012) игры Plague Inc. Цель игры — истребить или поработить человечество, используя смертельный патоген. Игрок управляет патогеном, наделяет его новыми симптомами и способами передачи. Обычные сюжетные роли перевернуты: злодей является протагонистом.
В последнее время стало появляться много шуток, связывающих игру и пандемию коронавируса. Люди начинают думать в терминах игры и используют игровые тропы для описания реального мира.
Тропы — повествовательные схемы, ментальные конструкции, которые обнаруживаются в разных видах творческих произведений (игры, фильмы, сериалы и прочее) — простой способ описания узнаваемых ситуаций, «кирпичики», составляющие повествование.
Мы решили узнать, какие тропы объединяют Plague Inc. и другие произведения, сюжет которых построен вокруг эпидемий. Для сравнения мы выбрали настольную игру Pandemic, фильмы Contagion и 28 Days Later и видео игру Left 4 Dead.
Мы использовали сетевой анализ. Анализируя тропы сетевым методом, можно быстро получить достаточно полное представление о самом произведении и понять, что его объединяет с другими: сразу видно общие детали сюжета или сеттинга.
Примеры тропов, которые встретились в нескольких произведениях:
Zombie Apocalypse (Зомби-апокалипсис)
Где встречается: Plague Inc., Pandemic, Left 4 Dead.
По-разному реализуется в каждой игре.
Patient Zero (Нулевой пациент)
Где встречается: Plague Inc., Contagion, Pandemic.
Первый зараженный может быть ключом к вакцине.
Ripped From The Headlines («Сюжет стащили из новостей») .
Где встречается: Contagion, Plague Inc., 28 Days Later
Здесь довольно любопытно то, что описание тропа несколько уже его фактического применения. Название и примеры передают больше информации, чем описание. Вкратце: общая канва истории основана на реальных событиях с некоторыми изменениями. Кроме того в Plague Inc. регулярно добавляют новые новости с отсылками, что делает структуру сложнее.
Spreading Disaster Map Graphic (Карта распространения вируса)
Где встречается: Plague Inc., Contagion, Pandemic
Карта с распространением вируса — прямо как в новостях
Oh, Crap! («О, чёрт!»)
Где присутствует: Plague Inc., Contagion, 28 Days Later, Left 4 Dead.
Момент осознания всего ужаса ситуации. Как говорится, «вы находитесь здесь».
Обо всех результатах и о том, как проводится сетевой анализ, читайте по ссылке: https://sysblok.ru/society/prjamo-kak-v-plague-inc-chto-obedinjaet-igry-i-filmy-pro-jepidemii/
{kind=link}
Музыка нас связала: универсалии в музыке мира
#musicology #news
Есть ли что-то общее у горлового пения эскимосов, традиционного аккомпанемента японского драматического театра, но и мелодий, сыгранных австралийскими аборигенами на диджериду?
Различия в музыкальных традициях мира убедили некоторых музыковедов-фольклористов в том, что идея об универсальности мировой музыки не состоятельна. Однако, музыковед Самуил Мэр и другие исследователи Гарвардского университета нашли доказательства тому, что мировую музыку объединяют общие акустические признаки.
Исследование
Самуил Мэр с командой исследователей записал множество песен, типичных для разных культур. В выборку вошли только песни с вокальным элементом. Из собранных песен исследователей привлекли четыре типа: колыбельные, плясовые, любовные песни и песни-заговоры. Ученые их транскрибировали и проанализировали с помощью программ для обработки звучащей речи.
Также провели онлайн-эксперимент, цель которого — узнать, смогут ли слушатели разделить песни на категории, анализируя исключительно акустические признаки мелодий. Участники слушали песни, информация о содержании которых была скрыта, и распределяли их по четырем категориям.
Еще исследовали, во всех ли песнях есть лад, то есть системная организация тонов и отношений между ними. Для этого 30 музыковедов прослушали отрывки из песен и ответили, звучит ли в них хоть одна тоника (трезвучие, построенное на первой ступени ладового звукоряда).
Результаты
Предварительный анализ показал, что у песен каждого типа есть сходные элементы. Некоторые сходства очевидны: например, у плясовых песен более энергичный темп, по сравнению с колыбельными. Также выяснили, что в любовных песнях тональный диапазон шире, чем в колыбельных; плясовые песни более мелодически разнородны, в сравнении с заговорами; а в заговорах используется небольшое количество близких по звучанию нот.
Исследование выделило три измерения, которыми можно объяснить основные различия между четырьмя типами песен: церемониальность, возбуждение и религиозность. Так, плясовые песни отличает высокая церемониальность и возбуждение, но низкая религиозность. У заговоров все три аспекта ярко выражены, а у колыбельных, наоборот, менее всего.
Участники онлайн-эксперимента правильно угадали тип песни в 42% случаев, что гораздо выше 25% случайного распределения.
При исследовании лада 90% музыковедов выявили тонику в 113 из 118 песен, что указывает на универсальную природу лада.
Выводы исследователей
Полученные результаты указывают на то, что в акустических свойствах песен закодирован поведенческий контекст, общий для мировых культур. Принципиальное различие между песнями разных культур значительно ниже, чем разнообразие контекстов внутри отдельно взятой культуры. Значит, несмотря на вариации в манере исполнения и инструментах, по всему миру сходные песни используются в сходных контекстах.
Пока не до конца ясно, чем можно объяснить несоответствие социальных контекстов и акустических свойств песен. Кроме того, в исследовании пока представлены не все мировые культуры. В будущем можно создать обширную базу данных, аннотированную текстом и видео, в которую войдут аудиозаписи песен разных культур и стилей.
О зарождении музыки
Недавнее исследование ископаемых останков выявило, что гейдельбергский человек — общий предок человека разумного и неандертальца — мог менять высоту своего голоса , то есть «петь», уже более миллиона лет назад.
В ходе другого археологического исследования обнаружили дудки, выточенные из костей лебедей и ястребов, возраст которых составляет около 40 тысяч лет. Можно представить, что эти изделия — результат долгой эволюции музыкальных инструментов, а более ранние образцы были сделаны из травы, тростника и дерева — тех материалов, которые не так часто встречаются в ископаемых находках.
Есть мнение, что музыка — эволюционное приспособление, финальное или — как результат другого приспособления — побочное.
Вера Шимко
https://sysblok.ru/news/muzyka-nas-svjazala-universalii-v-muzyke-mira/
#musicology #news
Есть ли что-то общее у горлового пения эскимосов, традиционного аккомпанемента японского драматического театра, но и мелодий, сыгранных австралийскими аборигенами на диджериду?
Различия в музыкальных традициях мира убедили некоторых музыковедов-фольклористов в том, что идея об универсальности мировой музыки не состоятельна. Однако, музыковед Самуил Мэр и другие исследователи Гарвардского университета нашли доказательства тому, что мировую музыку объединяют общие акустические признаки.
Исследование
Самуил Мэр с командой исследователей записал множество песен, типичных для разных культур. В выборку вошли только песни с вокальным элементом. Из собранных песен исследователей привлекли четыре типа: колыбельные, плясовые, любовные песни и песни-заговоры. Ученые их транскрибировали и проанализировали с помощью программ для обработки звучащей речи.
Также провели онлайн-эксперимент, цель которого — узнать, смогут ли слушатели разделить песни на категории, анализируя исключительно акустические признаки мелодий. Участники слушали песни, информация о содержании которых была скрыта, и распределяли их по четырем категориям.
Еще исследовали, во всех ли песнях есть лад, то есть системная организация тонов и отношений между ними. Для этого 30 музыковедов прослушали отрывки из песен и ответили, звучит ли в них хоть одна тоника (трезвучие, построенное на первой ступени ладового звукоряда).
Результаты
Предварительный анализ показал, что у песен каждого типа есть сходные элементы. Некоторые сходства очевидны: например, у плясовых песен более энергичный темп, по сравнению с колыбельными. Также выяснили, что в любовных песнях тональный диапазон шире, чем в колыбельных; плясовые песни более мелодически разнородны, в сравнении с заговорами; а в заговорах используется небольшое количество близких по звучанию нот.
Исследование выделило три измерения, которыми можно объяснить основные различия между четырьмя типами песен: церемониальность, возбуждение и религиозность. Так, плясовые песни отличает высокая церемониальность и возбуждение, но низкая религиозность. У заговоров все три аспекта ярко выражены, а у колыбельных, наоборот, менее всего.
Участники онлайн-эксперимента правильно угадали тип песни в 42% случаев, что гораздо выше 25% случайного распределения.
При исследовании лада 90% музыковедов выявили тонику в 113 из 118 песен, что указывает на универсальную природу лада.
Выводы исследователей
Полученные результаты указывают на то, что в акустических свойствах песен закодирован поведенческий контекст, общий для мировых культур. Принципиальное различие между песнями разных культур значительно ниже, чем разнообразие контекстов внутри отдельно взятой культуры. Значит, несмотря на вариации в манере исполнения и инструментах, по всему миру сходные песни используются в сходных контекстах.
Пока не до конца ясно, чем можно объяснить несоответствие социальных контекстов и акустических свойств песен. Кроме того, в исследовании пока представлены не все мировые культуры. В будущем можно создать обширную базу данных, аннотированную текстом и видео, в которую войдут аудиозаписи песен разных культур и стилей.
О зарождении музыки
Недавнее исследование ископаемых останков выявило, что гейдельбергский человек — общий предок человека разумного и неандертальца — мог менять высоту своего голоса , то есть «петь», уже более миллиона лет назад.
В ходе другого археологического исследования обнаружили дудки, выточенные из костей лебедей и ястребов, возраст которых составляет около 40 тысяч лет. Можно представить, что эти изделия — результат долгой эволюции музыкальных инструментов, а более ранние образцы были сделаны из травы, тростника и дерева — тех материалов, которые не так часто встречаются в ископаемых находках.
Есть мнение, что музыка — эволюционное приспособление, финальное или — как результат другого приспособления — побочное.
Вера Шимко
https://sysblok.ru/news/muzyka-nas-svjazala-universalii-v-muzyke-mira/
{kind=link}
Как 3D-технологии воскресили Страстной монастырь
#history
Страстной монастырь основали в середине 17-го века. Со временем его облик и значение менялись: его перестраивали, восстанавливали после пожаров, добавляли функциональные постройки. А в 1937 году монастырь был полностью уничтожен. Сейчас на месте, где стоял монастырь, находится Пушкинская площадь и стоит памятник А. С. Пушкину.
Активисты выдвигали предложения о переносе памятника и восстановлении Страстного монастыря, но проект не был поддержан. Однако, в 2016 году монастырь восстановили в виртуальном городе: был организован масштабный проект по 3D-реконструкции облика Страстного монастыря в разные эпохи.
Реконструкция выполнена для трех отрезков времени: рубеж 17-го и 18-го веков, 1830-ые годы и начало 20-го века. 3D-модели монастырского комплекса, а также отдельных его зданий и сооружений можно посмотреть здесь. Теперь любой человек может «погулять» по Страстному монастырю и площади вокруг него.
О том, как велась работа над проектом, читайте в нашей статье: https://sysblok.ru/history/kak-3d-tehnologii-voskresili-strastnoj-monastyr/
#history
Страстной монастырь основали в середине 17-го века. Со временем его облик и значение менялись: его перестраивали, восстанавливали после пожаров, добавляли функциональные постройки. А в 1937 году монастырь был полностью уничтожен. Сейчас на месте, где стоял монастырь, находится Пушкинская площадь и стоит памятник А. С. Пушкину.
Активисты выдвигали предложения о переносе памятника и восстановлении Страстного монастыря, но проект не был поддержан. Однако, в 2016 году монастырь восстановили в виртуальном городе: был организован масштабный проект по 3D-реконструкции облика Страстного монастыря в разные эпохи.
Реконструкция выполнена для трех отрезков времени: рубеж 17-го и 18-го веков, 1830-ые годы и начало 20-го века. 3D-модели монастырского комплекса, а также отдельных его зданий и сооружений можно посмотреть здесь. Теперь любой человек может «погулять» по Страстному монастырю и площади вокруг него.
О том, как велась работа над проектом, читайте в нашей статье: https://sysblok.ru/history/kak-3d-tehnologii-voskresili-strastnoj-monastyr/
YouTube
Виртуальная реконструкция Страстного монастыря нач. XX века
Проект "Виртуальная реконструкция московского Страстного монастыря (середина XVII - начало XX вв.): анализ эволюции пространственной инфраструктуры на основе методов 3D моделирования" поддержан грантом Российского научного Фонда (РНФ) № 14-18-03473. Проект…
Европейское культурное наследие онлайн
#arts
Пока границы закрыты, изучим возможности, которые предоставляют крупнейшие онлайн-коллекции объектов культурного наследия.
Europeana
Общеевропейская база. Архивы, музеи и библиотеки разных стран (включая Россию) выкладывают сюда свои электронные коллекции. Здесь можно найти произведения изобразительного искусства, старинные книги, газеты, географические карты, нотные издания и рукописи, звукозаписи и многое другое.
Условия использования прописаны для каждого объекта. Материалы могут быть как общедоступными, так и платными, либо вообще запрещенными для воспроизведения.
Google Arts And Culture
Онлайн-платформа от Google, посвященная культурному наследию. Здесь есть три основных раздела: коллекция изображений произведений искусства (в высоком разрешении, доступны для свободного скачивания), панорамные видео и виртуальные экскурсии по достопримечательностям (на основе технологии Street View).
На платформе представлены экспонаты из более чем 1200 музеев и архивов со всего мира.
Gallica
Проект Национальной библиотеки Франции. На портале есть следующие разделы: печатные книги, рукописи, карты, изображения, звукозаписи, ноты и видео. По документам доступен полнотекстовый поиск.
Большинство объектов находятся в публичном доступе, т. е. разрешено их использование в некоммерческих целях. Однако это относится не ко всей коллекции, поэтому в каждом конкретном случае необходимо уточнять условия копирайта.
Коллекции музеев Парижа
Портал, объединяющий онлайн-коллекции 14 муниципальных парижских музеев, среди которых есть художественные, исторические, дома художников и писателей. В их числе Карнавале (музей истории Парижа), Катакомбы (сеть подземных тоннелей на месте древних римских каменоломен), Крипта паперти Нотр-Дама (здесь выставлены археологические находки), Музей современного искусства, дома-музеи Оноре де Бальзака и Виктора Гюго.
На портале доступны более 150 тысяч цифровых репродукций произведений из коллекций музеев Парижа. Изображения находятся в свободном доступе, их можно скачать (в разрешении 300 dpi).
#arts
Пока границы закрыты, изучим возможности, которые предоставляют крупнейшие онлайн-коллекции объектов культурного наследия.
Europeana
Общеевропейская база. Архивы, музеи и библиотеки разных стран (включая Россию) выкладывают сюда свои электронные коллекции. Здесь можно найти произведения изобразительного искусства, старинные книги, газеты, географические карты, нотные издания и рукописи, звукозаписи и многое другое.
Условия использования прописаны для каждого объекта. Материалы могут быть как общедоступными, так и платными, либо вообще запрещенными для воспроизведения.
Google Arts And Culture
Онлайн-платформа от Google, посвященная культурному наследию. Здесь есть три основных раздела: коллекция изображений произведений искусства (в высоком разрешении, доступны для свободного скачивания), панорамные видео и виртуальные экскурсии по достопримечательностям (на основе технологии Street View).
На платформе представлены экспонаты из более чем 1200 музеев и архивов со всего мира.
Gallica
Проект Национальной библиотеки Франции. На портале есть следующие разделы: печатные книги, рукописи, карты, изображения, звукозаписи, ноты и видео. По документам доступен полнотекстовый поиск.
Большинство объектов находятся в публичном доступе, т. е. разрешено их использование в некоммерческих целях. Однако это относится не ко всей коллекции, поэтому в каждом конкретном случае необходимо уточнять условия копирайта.
Коллекции музеев Парижа
Портал, объединяющий онлайн-коллекции 14 муниципальных парижских музеев, среди которых есть художественные, исторические, дома художников и писателей. В их числе Карнавале (музей истории Парижа), Катакомбы (сеть подземных тоннелей на месте древних римских каменоломен), Крипта паперти Нотр-Дама (здесь выставлены археологические находки), Музей современного искусства, дома-музеи Оноре де Бальзака и Виктора Гюго.
На портале доступны более 150 тысяч цифровых репродукций произведений из коллекций музеев Парижа. Изображения находятся в свободном доступе, их можно скачать (в разрешении 300 dpi).
{kind=link}
Кэти Перри невиновна: цифровые музыковеды опровергают плагиат в песне Dark Horse
#musicology #news
В прошлом году певицу Кэти Перри обвинили в плагиате песни «Joyful Noise» рэпера Флейма (Flame). Суд обязал Кэти Перри выплатить 2,8 миллионов долларов за использованное в ее композиции «Dark Horse» остинато, которое якобы было заимствовано.
Остинато — это многократное повторение мелодической фразы, ритмической фигуры или гармонического оборота. Группа музыковедов, называющая себя Amici, доказывает, что остинато вовсе не является объектом авторского права, т. к. лишено оригинальности. Поэтому они категорически не согласны с решением суда Калифорнии, который присудил Кэти Перри штраф.
Исследование
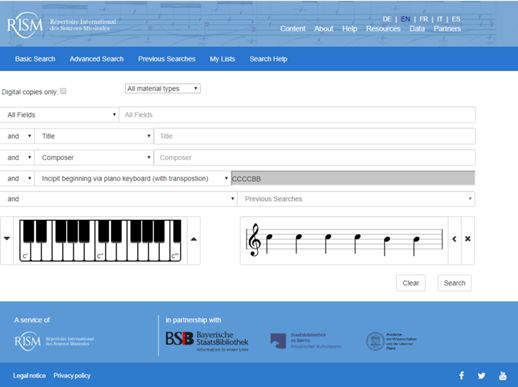
Сначала выявили последовательность нот, которую содержат обе композиции: она состоит из нот CCCCBB (в буквенной нотации). Затем ввели эту последовательность в базу данных RISM, которая содержит более 1,4 миллиона музыкальных инципитов (вступлений).
Музыкальный инципит — это поле, в котором закодированы несколько первых нот или тактов музыкального источника. Поиск по инципиту выполняется только с помощью расширенного поиска RISM. Предлагается использовать либо экранную клавиатуру пианино, либо поле Music incipit (с транспозицией): введите CCCCBB и нажмите Search.
Дополнительно музыковеды задействовали корпус Themefinder.org. Это некоммерческий проект поиска музыкальных фрагментов, созданный Центром компьютерных гуманитарных исследований (CCARH) и Лабораторией когнитивного и систематического музыковедения в Университете штата Огайо.
Результаты
Результаты поиска в RISM представляют собой те композиции, где эта последовательность нот (в этой или в другой тональности) встречается в начале произведения, и включают музыкальные источники, найденные по всей Европе. Музыковеды обнаружили около 2300 (по состоянию на январь 2020 года) песен по заданным параметрам, причем, большинство из них были написаны в 18-ом и 19-ом веках.
Результаты поиска в корпусе Themefinder также подтвердили широкое распространение последовательности нот, за которую судили Кэти Перри.
Ольга Чхотуа
https://sysblok.ru/musicology/kjeti-pjerri-nevinovna-cifrovye-muzykovedy-oprovergajut-plagiat-v-dark-horse/
#musicology #news
В прошлом году певицу Кэти Перри обвинили в плагиате песни «Joyful Noise» рэпера Флейма (Flame). Суд обязал Кэти Перри выплатить 2,8 миллионов долларов за использованное в ее композиции «Dark Horse» остинато, которое якобы было заимствовано.
Остинато — это многократное повторение мелодической фразы, ритмической фигуры или гармонического оборота. Группа музыковедов, называющая себя Amici, доказывает, что остинато вовсе не является объектом авторского права, т. к. лишено оригинальности. Поэтому они категорически не согласны с решением суда Калифорнии, который присудил Кэти Перри штраф.
Исследование
Сначала выявили последовательность нот, которую содержат обе композиции: она состоит из нот CCCCBB (в буквенной нотации). Затем ввели эту последовательность в базу данных RISM, которая содержит более 1,4 миллиона музыкальных инципитов (вступлений).
Музыкальный инципит — это поле, в котором закодированы несколько первых нот или тактов музыкального источника. Поиск по инципиту выполняется только с помощью расширенного поиска RISM. Предлагается использовать либо экранную клавиатуру пианино, либо поле Music incipit (с транспозицией): введите CCCCBB и нажмите Search.
Дополнительно музыковеды задействовали корпус Themefinder.org. Это некоммерческий проект поиска музыкальных фрагментов, созданный Центром компьютерных гуманитарных исследований (CCARH) и Лабораторией когнитивного и систематического музыковедения в Университете штата Огайо.
Результаты
Результаты поиска в RISM представляют собой те композиции, где эта последовательность нот (в этой или в другой тональности) встречается в начале произведения, и включают музыкальные источники, найденные по всей Европе. Музыковеды обнаружили около 2300 (по состоянию на январь 2020 года) песен по заданным параметрам, причем, большинство из них были написаны в 18-ом и 19-ом веках.
Результаты поиска в корпусе Themefinder также подтвердили широкое распространение последовательности нот, за которую судили Кэти Перри.
Ольга Чхотуа
https://sysblok.ru/musicology/kjeti-pjerri-nevinovna-cifrovye-muzykovedy-oprovergajut-plagiat-v-dark-horse/
{kind=link}
Компьютерный анализ Сезанна: что объединяет серию Купальщиков
#arts
Поль Сезанн был воспитан культурой Ренессанса и воспевал неоплатонические идеи. В мировой культуре он остался художником, для которого искусство было самоцелью. «Купальщики» — самая длительная и монументальная серия его творчества: к этому сюжету он возвращался на протяжении всей жизни. Полотно «Большие купальщицы» стало последней работой, поставленной Сезанном на мольберт перед смертью.
Возможности компьютерного анализа произведений искусства
Сегодня для анализа произведений искусства применяются разнообразные технологии. Сравнительный анализ и основы классификации произведений искусства, которыми пользуются по сей день, открыл миру Генрих Вельфлин.
Методы анализа полотен с помощью рентгеновских и ультрафиолетовых лучей могут выявить нижние слои картин, идентифицировать свойства пигментов и связующих веществ, подтвердить подлинность произведений искусства и обнаружить подделки. Полученные сведения помогают составить оптимальные проекты для музея.
Компьютерные алгоритмы используются для измерения и подсчета мазков кисти, классификации картин по стилю, выявления их характерных черт и создания трехмерных моделей, которые иллюстрируют методы работы художника. Программы способны одновременно перерабатывать большой объем данных, не опираясь при этом на прошлый опыт исследователей, подвергать сомнению уже имеющиеся категории и выявлять ошибки в нашем понимании и оценке живописи.
Таким образом, компьютеры способны создать уникальные культурные карты, которые оригинальным образом свяжут исторические артефакты.
Применение программ DIAS и DENDRON
В медицине программы DIAS и DENDRON (сокращ. DDA) используют для изучения микозов и раковых клеток. DIAS отвечает за анализ морфологии клеток, изучает их движения и динамику популяции, а DENDRON — сортирует и сравнивает генетические отпечатки инфекционных организмов, формируя их в древообразные дендрограммы.
Группа исследователей из Массачусетса стала первой, кто использовал DDA в искусстве. Метод кластерного анализа или построения дендрограмм был применен к 55 оцифрованным картинам. Программа DDA позволила перенести все оцифрованные картины в единую базу.
С помощью сравнительного анализа полотна удалось автоматически распределить по девяти разным параметрам: яркости, насыщенности, сложности, красного, оранжевого, желтого, зеленого, голубого и пурпурного оттенков. Каждая пара или группа картин была отсортирована, исходя из соответствия единому признаку, и распределена в порядке растущей прогрессии. Далее коэффициент прогрессии генерировал матрицы, на основе которых были сформированы дендрограммы.
Результаты исследования
Результаты исследования подтвердили художественную связь Веронезе и Сезанна: в своей работе «Стоящая купальщица моет волосы» Сезанн использует паттерны картины «Брак в Кане Галилейской», написанной Паоло Веронезе в 16-ом веке.
Анализ работ также выявил скрытую единую композиционную структуру, отмеченную во всех полотнах Сезанна. Удалось установить, что, вероятнее всего, Сезанн в своем творчестве руководствовался математическими расчетами, а не интуитивными мотивами. Это изменило сложившиеся в искусствоведении представление о неуклюжести и дисбалансе форм Сезанна, на идею о точной выверенной им композиции, соответствующей правилам «золотого сечения».
Благодаря программе DDA можно предположить, что Сезанн закладывал в свои работы не только игру цвета и формы, но и особую головоломку — главную идею своего творчества.
Дара Марич
https://sysblok.ru/arts/kompjuternyj-analiz-sezanna-chto-obedinjaet-seriju-kupalshhikov/
#arts
Поль Сезанн был воспитан культурой Ренессанса и воспевал неоплатонические идеи. В мировой культуре он остался художником, для которого искусство было самоцелью. «Купальщики» — самая длительная и монументальная серия его творчества: к этому сюжету он возвращался на протяжении всей жизни. Полотно «Большие купальщицы» стало последней работой, поставленной Сезанном на мольберт перед смертью.
Возможности компьютерного анализа произведений искусства
Сегодня для анализа произведений искусства применяются разнообразные технологии. Сравнительный анализ и основы классификации произведений искусства, которыми пользуются по сей день, открыл миру Генрих Вельфлин.
Методы анализа полотен с помощью рентгеновских и ультрафиолетовых лучей могут выявить нижние слои картин, идентифицировать свойства пигментов и связующих веществ, подтвердить подлинность произведений искусства и обнаружить подделки. Полученные сведения помогают составить оптимальные проекты для музея.
Компьютерные алгоритмы используются для измерения и подсчета мазков кисти, классификации картин по стилю, выявления их характерных черт и создания трехмерных моделей, которые иллюстрируют методы работы художника. Программы способны одновременно перерабатывать большой объем данных, не опираясь при этом на прошлый опыт исследователей, подвергать сомнению уже имеющиеся категории и выявлять ошибки в нашем понимании и оценке живописи.
Таким образом, компьютеры способны создать уникальные культурные карты, которые оригинальным образом свяжут исторические артефакты.
Применение программ DIAS и DENDRON
В медицине программы DIAS и DENDRON (сокращ. DDA) используют для изучения микозов и раковых клеток. DIAS отвечает за анализ морфологии клеток, изучает их движения и динамику популяции, а DENDRON — сортирует и сравнивает генетические отпечатки инфекционных организмов, формируя их в древообразные дендрограммы.
Группа исследователей из Массачусетса стала первой, кто использовал DDA в искусстве. Метод кластерного анализа или построения дендрограмм был применен к 55 оцифрованным картинам. Программа DDA позволила перенести все оцифрованные картины в единую базу.
С помощью сравнительного анализа полотна удалось автоматически распределить по девяти разным параметрам: яркости, насыщенности, сложности, красного, оранжевого, желтого, зеленого, голубого и пурпурного оттенков. Каждая пара или группа картин была отсортирована, исходя из соответствия единому признаку, и распределена в порядке растущей прогрессии. Далее коэффициент прогрессии генерировал матрицы, на основе которых были сформированы дендрограммы.
Результаты исследования
Результаты исследования подтвердили художественную связь Веронезе и Сезанна: в своей работе «Стоящая купальщица моет волосы» Сезанн использует паттерны картины «Брак в Кане Галилейской», написанной Паоло Веронезе в 16-ом веке.
Анализ работ также выявил скрытую единую композиционную структуру, отмеченную во всех полотнах Сезанна. Удалось установить, что, вероятнее всего, Сезанн в своем творчестве руководствовался математическими расчетами, а не интуитивными мотивами. Это изменило сложившиеся в искусствоведении представление о неуклюжести и дисбалансе форм Сезанна, на идею о точной выверенной им композиции, соответствующей правилам «золотого сечения».
Благодаря программе DDA можно предположить, что Сезанн закладывал в свои работы не только игру цвета и формы, но и особую головоломку — главную идею своего творчества.
Дара Марич
https://sysblok.ru/arts/kompjuternyj-analiz-sezanna-chto-obedinjaet-seriju-kupalshhikov/
{kind=link}
Перенос стиля рукописей Леонардо да Винчи
#arts
Обычно все показывают перенос стиля на «Звездной ночи» Ван Гога. Но вообще-то технология переноса стиля универсальна и дает возможность проявить немного фантазии.
Идея совместить да Винчи и Data Science пришла в голову исследователю из Вышки Борису Орехову, который и поделился с Системным Блоком этими картинками.
На современные научные статьи о нейросетях наложен визуальный стиль трактатов да Винчи. Посмотрите сами: слева — статья про нейронные сети, справа — рукопись да Винчи, а посередине — результат переноса стиля рукописи на статью.
Как это сделано? C помощью предобученной сверточной нейросети VGG-19, которая способна извлекать признаки из изображений. Из сети нужно удалить все полносвязные слои, чтобы можно было работать со своим входным изображением.
А по ссылке вы найдете еще примеры и сможете проследить стадии переноса стиля на разном числе итераций работы нейросети: https://sysblok.ru/arts/nejronnye-seti-pridumal-leonardo-da-vinchi/
#arts
Обычно все показывают перенос стиля на «Звездной ночи» Ван Гога. Но вообще-то технология переноса стиля универсальна и дает возможность проявить немного фантазии.
Идея совместить да Винчи и Data Science пришла в голову исследователю из Вышки Борису Орехову, который и поделился с Системным Блоком этими картинками.
На современные научные статьи о нейросетях наложен визуальный стиль трактатов да Винчи. Посмотрите сами: слева — статья про нейронные сети, справа — рукопись да Винчи, а посередине — результат переноса стиля рукописи на статью.
Как это сделано? C помощью предобученной сверточной нейросети VGG-19, которая способна извлекать признаки из изображений. Из сети нужно удалить все полносвязные слои, чтобы можно было работать со своим входным изображением.
А по ссылке вы найдете еще примеры и сможете проследить стадии переноса стиля на разном числе итераций работы нейросети: https://sysblok.ru/arts/nejronnye-seti-pridumal-leonardo-da-vinchi/
{kind=link}
Все переплетено: как распутать социальную сеть раввинской литературы
Когда мы читаем «Войну и Мир» или смотрим «Игру престолов», нам часто приходится возвращаться назад, и вспоминать, кто вообще такой этот Несвицкий? Мозг протестует и отказывается запоминать всех многочисленных персонажей.
А что делать, если текст размером как пять романов Толстого? Этим вопросом задались исследователи раввинской литературы Мааян Житомирский-Геффет и Гила Пребор из университета Бар-Илана в Израиле. Они создали «социальную сеть» раввинских мудрецов, упоминающихся в Мишне — самом древнем письменном тексте, содержащем главные положения иудаизма.
Идентификация личности раввинских мудрецов
Раввинские Мудрецы — праведники, проповедники и теологи, жившие в 200 г. до н. э.-200 г. н. э. Они традиционно делятся на десять поколений: пары — первые пять поколений, и учителя — следующие пять. Все эти мудрецы участвовали в богословском обсуждении Мишны и сами же становились ее героями.
Среди мудрецов оказалось много тезок и однофамильцев. Поэтому, каждому мудрецу в социальной сети помимо личного имени были присвоены его статус и титул (Рабби, Раббан, и т. д.), а также прозвища и необязательные части имени, которые указывают на географическую или родовую принадлежность мудреца (Человек из Галилеи, сын Гиркана).
После присвоения всех этих частей, типичное полное имя мудреца выглядит так:
titel private_name titel father_name fathers_nickname/location
Раббан Симеон сын Раббан Гамалиил Явне
Взаимоотношения между мудрецами
Основной задачей исследователей было составить понятную структуру взаимоотношений не только между несколькими мудрецами, но и между целыми поколениями. При построении такой сети авторы опирались на отношения 160 главных раввинских мудрецов и использовали имена каждого из них.
Для определения связей и отношений между героями, исследователи присваивали каждой паре мудрецов, упомянутых в Мишне, один из типов взаимодействия: согласие, несогласие и цитирование. Кроме того, для каждого мудреца учитывались его родственные связи, внутренние отношения — единомышленники/противники, географическое местоположение и поколение, к которому этот мудрец относится.
Общая полученная сеть включает 347 пар мудрецов и около 1500 разных отношений между ними. Анализируя отношения этих 347 пар, исследователи построили отдельные социальные сети для каждого типа взаимодействий.
Результаты анализа социальной сети мудрецов
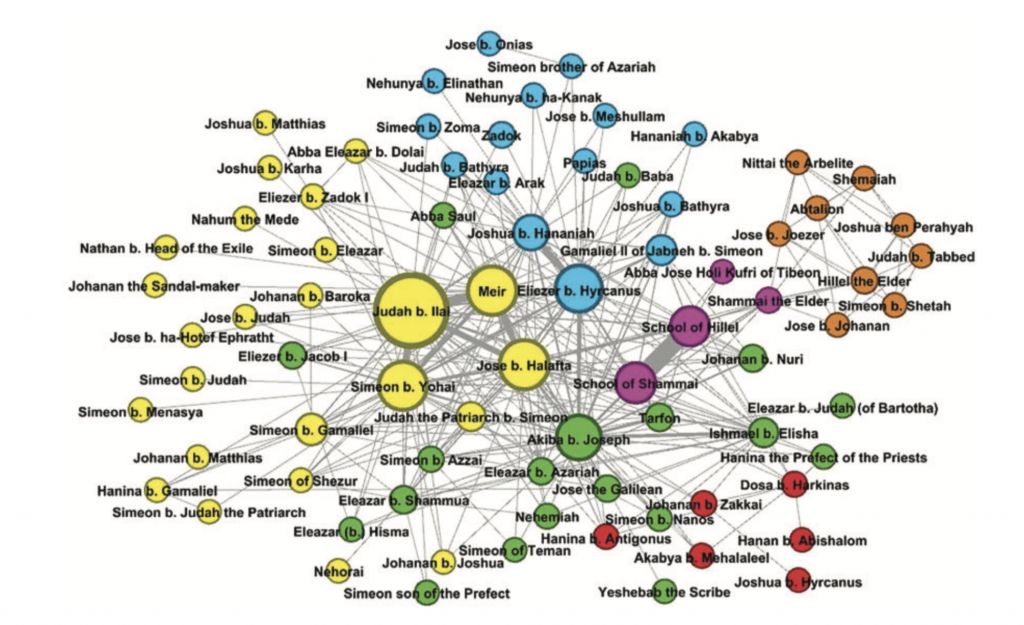
Чаще всего мудрецы оказываются не согласны друг с другом (304 пары), 50 пар соглашаются или поддерживают друг друга, в 39 парах мудрецы друг друга цитируют.
91% всех отношений между мудрецами — несогласие. Мы видим (см. иллюстрацию), что споры мудрецов часто бывают как внутри поколения, так и между разными хронологическими группами. Кроме того, мы можем увидеть на графе прочную связь между школой Шаммая и школой Гиллеля — серьезными идеологическими оппонентами.
Сеть согласия включает только 84 мудреца и оказывается гораздо тоньше сети несогласия. Сравнив два этих графа, можно подумать, что мудрецы в Мишне вообще не соглашаются и только спорят. Однако, это не совсем так. Текст Мишны очень лаконичен, и если в каком-то эпизоде два мудреца поддерживают друг друга, их диалог часто не доводится до конца, а один из двух согласных может вообще не упоминаться. При этом, если у мудрецов возникают разногласия, в Мишне всегда подробно приводятся оба мнения.
Цитирования в Мишне чаще всего оказываются межпоколенческими. Например, Хосе бен Халафта цитирует своего учителя Акибу бен Иосифа. Наиболее цитируемыми мудрецами являются Меир, Иоханан бен Заккай и Иисус Навин.
Эти данные подтверждают и доказывают многие отдельные наблюдения, сделанные в ходе традиционного исследования текста Мишны.
Ксения Костомарова
По ссылке вы также найдете граф поддержки и согласия мудрецов, граф цитирования мудрецов, а также диаграмму «сущность-связь» для данных каждого мудреца: https://sysblok.ru/philology/vse-perepleteno-kak-rasputat-socialnuju-set-ravvinskoj-literatury/
Когда мы читаем «Войну и Мир» или смотрим «Игру престолов», нам часто приходится возвращаться назад, и вспоминать, кто вообще такой этот Несвицкий? Мозг протестует и отказывается запоминать всех многочисленных персонажей.
А что делать, если текст размером как пять романов Толстого? Этим вопросом задались исследователи раввинской литературы Мааян Житомирский-Геффет и Гила Пребор из университета Бар-Илана в Израиле. Они создали «социальную сеть» раввинских мудрецов, упоминающихся в Мишне — самом древнем письменном тексте, содержащем главные положения иудаизма.
Идентификация личности раввинских мудрецов
Раввинские Мудрецы — праведники, проповедники и теологи, жившие в 200 г. до н. э.-200 г. н. э. Они традиционно делятся на десять поколений: пары — первые пять поколений, и учителя — следующие пять. Все эти мудрецы участвовали в богословском обсуждении Мишны и сами же становились ее героями.
Среди мудрецов оказалось много тезок и однофамильцев. Поэтому, каждому мудрецу в социальной сети помимо личного имени были присвоены его статус и титул (Рабби, Раббан, и т. д.), а также прозвища и необязательные части имени, которые указывают на географическую или родовую принадлежность мудреца (Человек из Галилеи, сын Гиркана).
После присвоения всех этих частей, типичное полное имя мудреца выглядит так:
titel private_name titel father_name fathers_nickname/location
Раббан Симеон сын Раббан Гамалиил Явне
Взаимоотношения между мудрецами
Основной задачей исследователей было составить понятную структуру взаимоотношений не только между несколькими мудрецами, но и между целыми поколениями. При построении такой сети авторы опирались на отношения 160 главных раввинских мудрецов и использовали имена каждого из них.
Для определения связей и отношений между героями, исследователи присваивали каждой паре мудрецов, упомянутых в Мишне, один из типов взаимодействия: согласие, несогласие и цитирование. Кроме того, для каждого мудреца учитывались его родственные связи, внутренние отношения — единомышленники/противники, географическое местоположение и поколение, к которому этот мудрец относится.
Общая полученная сеть включает 347 пар мудрецов и около 1500 разных отношений между ними. Анализируя отношения этих 347 пар, исследователи построили отдельные социальные сети для каждого типа взаимодействий.
Результаты анализа социальной сети мудрецов
Чаще всего мудрецы оказываются не согласны друг с другом (304 пары), 50 пар соглашаются или поддерживают друг друга, в 39 парах мудрецы друг друга цитируют.
91% всех отношений между мудрецами — несогласие. Мы видим (см. иллюстрацию), что споры мудрецов часто бывают как внутри поколения, так и между разными хронологическими группами. Кроме того, мы можем увидеть на графе прочную связь между школой Шаммая и школой Гиллеля — серьезными идеологическими оппонентами.
Сеть согласия включает только 84 мудреца и оказывается гораздо тоньше сети несогласия. Сравнив два этих графа, можно подумать, что мудрецы в Мишне вообще не соглашаются и только спорят. Однако, это не совсем так. Текст Мишны очень лаконичен, и если в каком-то эпизоде два мудреца поддерживают друг друга, их диалог часто не доводится до конца, а один из двух согласных может вообще не упоминаться. При этом, если у мудрецов возникают разногласия, в Мишне всегда подробно приводятся оба мнения.
Цитирования в Мишне чаще всего оказываются межпоколенческими. Например, Хосе бен Халафта цитирует своего учителя Акибу бен Иосифа. Наиболее цитируемыми мудрецами являются Меир, Иоханан бен Заккай и Иисус Навин.
Эти данные подтверждают и доказывают многие отдельные наблюдения, сделанные в ходе традиционного исследования текста Мишны.
Ксения Костомарова
По ссылке вы также найдете граф поддержки и согласия мудрецов, граф цитирования мудрецов, а также диаграмму «сущность-связь» для данных каждого мудреца: https://sysblok.ru/philology/vse-perepleteno-kak-rasputat-socialnuju-set-ravvinskoj-literatury/
{kind=link}
Как изменились тексты поп-песен за последние 50 лет
#society #arts
Поп-музыка — практически неограниченное пространство для исследователя. Можно изучать ее инструментами социологии, теории музыки, культурологии и еще десятка дисциплин, но самый простой способ — проверить, как меняются тексты.
Анализ текстов методом семантического анализа
В исследовании использовались два датасета: «100 лучших песен года по мнению Billboard», состоящий из широко известных в США песен с 1965 по 2015 годы, и слова песен с сайта Musixmatch, состоящий из более чем 150000 англоязычных песен. Тренды, найденные в Billboard и на Musixmatch, совпали, поэтому можно сказать, что тенденция универсальна.
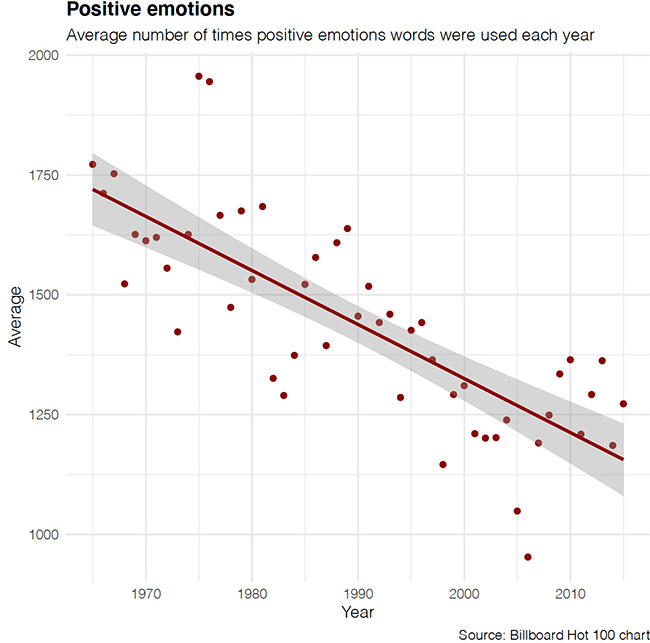
Англоязычные песни стали негативнее: употребление слов, связанных с негативными эмоциями, выросло на треть, а доля позитивных слов сократилась (см. график ниже). Однако, в целом количество позитивных слов превышает количество негативных в любой момент наблюдения — это универсальная характеристика человеческого языка, также известная как принцип Поллианны, названный в честь оптимистичной протагонистки одноименной книги.
Частотность использования слова «любовь» за 50 лет снизилась вдвое, а слово «ненависть», наоборот, используется сейчас где-то 20–30 раз в год, учитывая, что до 90-х годов в песнях из датасета Billboard его вообще не использовали.
Почему поп-песни стали «грустнее»
Одно из объяснений — это культурная эволюция. Культура способна эволюционировать, следуя принципам Дарвина: при наличии разнообразия, отбора и размножения можно ожидать, что самые успешные культурные характеристики закрепятся, а менее успешные — исчезнут.
Многие поведенческие характеристики передаются социальным путем, и чтобы социальное обучение было успешным, оно должно быть избирательным.На предпочтения в выборе примера для подражания могут влиять: успешность примера, конформизм обучающегося, престиж обучающего и содержание примера. Каждому из них соответствует свой вид смещения.
Избирательность обучения по принципу «насколько хорош результат процесса» можно назвать смещением по успеху, или success bias. Наличие смещения по успеху проверялось сравнением количества негативных текстов песен, вышедших в конкретном году, с количеством негативных текстов песен, вышедших в предыдущие годы; иными словами, правда ли, что авторы песен ориентировались на хиты прошлых лет.
Смещение по престижу (prestige bias) оценивали, проверяя, много ли популярных исполнителей прошедших лет пели песни с негативным содержанием. Под популярным исполнителем понимался такой, который появлялся в чартах неприлично большое количество раз.
Проверяли и смещение по содержанию (content bias): вдруг песни с негативным содержанием в принципе лучше приживались в чартах, вне зависимости от артиста. Если бы это так и было, можно было бы сказать, что в самом содержании негативных песен было что-то такое, что притягивало слушателей.
Влияние смещения по успеху и по престижу в датасете обнаружено не было, зато роль смещения по содержанию в увеличении доли негативных слов в песнях была наибольшей. Негативная информация запоминается и распространяется лучше позитивной (Твиттер — отличное тому подтверждение).
Мария Маслова
https://sysblok.ru/arts/stali-li-sovremennye-pop-pesni-grustnee-za-poslednie-50-let/
#society #arts
Поп-музыка — практически неограниченное пространство для исследователя. Можно изучать ее инструментами социологии, теории музыки, культурологии и еще десятка дисциплин, но самый простой способ — проверить, как меняются тексты.
Анализ текстов методом семантического анализа
В исследовании использовались два датасета: «100 лучших песен года по мнению Billboard», состоящий из широко известных в США песен с 1965 по 2015 годы, и слова песен с сайта Musixmatch, состоящий из более чем 150000 англоязычных песен. Тренды, найденные в Billboard и на Musixmatch, совпали, поэтому можно сказать, что тенденция универсальна.
Англоязычные песни стали негативнее: употребление слов, связанных с негативными эмоциями, выросло на треть, а доля позитивных слов сократилась (см. график ниже). Однако, в целом количество позитивных слов превышает количество негативных в любой момент наблюдения — это универсальная характеристика человеческого языка, также известная как принцип Поллианны, названный в честь оптимистичной протагонистки одноименной книги.
Частотность использования слова «любовь» за 50 лет снизилась вдвое, а слово «ненависть», наоборот, используется сейчас где-то 20–30 раз в год, учитывая, что до 90-х годов в песнях из датасета Billboard его вообще не использовали.
Почему поп-песни стали «грустнее»
Одно из объяснений — это культурная эволюция. Культура способна эволюционировать, следуя принципам Дарвина: при наличии разнообразия, отбора и размножения можно ожидать, что самые успешные культурные характеристики закрепятся, а менее успешные — исчезнут.
Многие поведенческие характеристики передаются социальным путем, и чтобы социальное обучение было успешным, оно должно быть избирательным.На предпочтения в выборе примера для подражания могут влиять: успешность примера, конформизм обучающегося, престиж обучающего и содержание примера. Каждому из них соответствует свой вид смещения.
Избирательность обучения по принципу «насколько хорош результат процесса» можно назвать смещением по успеху, или success bias. Наличие смещения по успеху проверялось сравнением количества негативных текстов песен, вышедших в конкретном году, с количеством негативных текстов песен, вышедших в предыдущие годы; иными словами, правда ли, что авторы песен ориентировались на хиты прошлых лет.
Смещение по престижу (prestige bias) оценивали, проверяя, много ли популярных исполнителей прошедших лет пели песни с негативным содержанием. Под популярным исполнителем понимался такой, который появлялся в чартах неприлично большое количество раз.
Проверяли и смещение по содержанию (content bias): вдруг песни с негативным содержанием в принципе лучше приживались в чартах, вне зависимости от артиста. Если бы это так и было, можно было бы сказать, что в самом содержании негативных песен было что-то такое, что притягивало слушателей.
Влияние смещения по успеху и по престижу в датасете обнаружено не было, зато роль смещения по содержанию в увеличении доли негативных слов в песнях была наибольшей. Негативная информация запоминается и распространяется лучше позитивной (Твиттер — отличное тому подтверждение).
Мария Маслова
https://sysblok.ru/arts/stali-li-sovremennye-pop-pesni-grustnee-za-poslednie-50-let/
{kind=link}
Виртуальный хор Эрика Витакера
#musicology
Более десяти лет назад девушка по имени Бритлин Лоси выложила на YouTube видео, на котором она исполняет партию сопрано из композиции Эрика Витакера «Sleep». Свое пение она предварила теплым вступительным словом в адрес композитора, где признается в любви к его творчеству.
Видео тронуло Витакера и навело его на мысль обратиться к людям со следующим предложением: записать отдельные партии из его сочинений для того, чтобы потом свести их в единый файл. Он создал видео, в котором рассказал концепцию своего сочинения под названием «Lux Aurumque», а затем продирижировал для будущих исполнителей под аккомпанемент фортепиано — чтобы певцы могли делать свои записи, используя эту «минусовку».
Версии 1.0 — 4.0
На просьбу отозвалось множество людей. Первый «Виртуальный хор» (2010) включал 185 певцов из 12 стран.
Проект всем так понравился, что вскоре был анонсирован «Виртуальный хор 2.0» — на композицию «Sleep» (ту самую, которую пела в фанатском видео Бритлин Лоси). Это видео, опубликованное в 2011 году, включало на порядок больше участников — 2000 человек из 58 стран.
В дальнейшем количество участников все увеличивалось. В «Виртуальном хоре 3.0» (2012), исполняющем произведение «Water Night» приняло участие около 4000 музыкантов из 73 стран.
В версии 4.0 (2013, композиция «Fly to Paradise») смонтированы 8409 видеозаписей от 5905 человек из 101 страны.
Версия Live
Разумеется, невозможно было лишь до бесконечности увеличивать количество участников. Тогда Эрик Витакер решил устроить живое выступление «виртуального хора». Для этого проекта он сделал новую редакцию своего сочинения «Cloudburst». Это было необходимо из-за того, что сигнал по скайпу передается с задержкой почти в секунду. Витакер использовал это запаздывание как художественный прием.
Премьера «Виртуального хора. Live» прошла в феврале 2013 года во время очередного выступления Эрика Витакера на знаменитой конференции TED. На сцене присутствовал живой сводный хор, состоящий из трех университетских коллективов и нескольких любительских хоров. К реальным певцам в процессе исполнения присоединились по скайпу еще 30 музыкантов из разных стран мира. Их лица транслировались на экране за спинами живого хора.
Версия 5.0. Deep Field
Проект «Виртуальный хор 5.0», старт которого был анонсирован в 2018 году, предлагал исполнить произведение под названием «Deep Field». На его создание Витакера вдохновил космический телескоп «Хаббл» и сделанное с его помощью открытие — изображение небольшой области в созвездии Большой медведицы, получившее название Deep Field.
Проект разросся далеко за пределы очередного «виртуального хора». В настоящий момент существуют фильм IMAX 4k «Deep Field: The Impossible Magnitude of the Universe», а также версия для живого концертного исполнения, в котором задействованы реальные оркестр и хор (Royal Philharmonic Orchestra и Eric Whitacre Singers), Кроме того, есть виртуальный хор 5.0 (см. видео ниже), состоящий из 8000 певцов из 120 стран. Выступление сопровождается проекцией изображений области Deep Field.
Как опыт Эрика Витакера может помочь нам в 2020-м?
В одном из интервью композитор признается: «для меня петь вместе, музицировать вместе — это основополагающий человеческий опыт, и мне нравится идея, что технологии могут объединить людей со всего мира и дать им возможность попробовать что-то, выходящее за пределы их обычной жизни».
Сейчас, когда обычная жизнь для многих сузилась до пределов их квартир или домов, самое время подробнее изучить многолетний опыт Эрика Витакера и, возможно, найти в нем вдохновение, чтобы продвинуться еще дальше в соединении творчества и технологий.
Василиса Александрова
https://sysblok.ru/musicology/ideja-dlja-karantina-virtualnyj-hor/
#musicology
Более десяти лет назад девушка по имени Бритлин Лоси выложила на YouTube видео, на котором она исполняет партию сопрано из композиции Эрика Витакера «Sleep». Свое пение она предварила теплым вступительным словом в адрес композитора, где признается в любви к его творчеству.
Видео тронуло Витакера и навело его на мысль обратиться к людям со следующим предложением: записать отдельные партии из его сочинений для того, чтобы потом свести их в единый файл. Он создал видео, в котором рассказал концепцию своего сочинения под названием «Lux Aurumque», а затем продирижировал для будущих исполнителей под аккомпанемент фортепиано — чтобы певцы могли делать свои записи, используя эту «минусовку».
Версии 1.0 — 4.0
На просьбу отозвалось множество людей. Первый «Виртуальный хор» (2010) включал 185 певцов из 12 стран.
Проект всем так понравился, что вскоре был анонсирован «Виртуальный хор 2.0» — на композицию «Sleep» (ту самую, которую пела в фанатском видео Бритлин Лоси). Это видео, опубликованное в 2011 году, включало на порядок больше участников — 2000 человек из 58 стран.
В дальнейшем количество участников все увеличивалось. В «Виртуальном хоре 3.0» (2012), исполняющем произведение «Water Night» приняло участие около 4000 музыкантов из 73 стран.
В версии 4.0 (2013, композиция «Fly to Paradise») смонтированы 8409 видеозаписей от 5905 человек из 101 страны.
Версия Live
Разумеется, невозможно было лишь до бесконечности увеличивать количество участников. Тогда Эрик Витакер решил устроить живое выступление «виртуального хора». Для этого проекта он сделал новую редакцию своего сочинения «Cloudburst». Это было необходимо из-за того, что сигнал по скайпу передается с задержкой почти в секунду. Витакер использовал это запаздывание как художественный прием.
Премьера «Виртуального хора. Live» прошла в феврале 2013 года во время очередного выступления Эрика Витакера на знаменитой конференции TED. На сцене присутствовал живой сводный хор, состоящий из трех университетских коллективов и нескольких любительских хоров. К реальным певцам в процессе исполнения присоединились по скайпу еще 30 музыкантов из разных стран мира. Их лица транслировались на экране за спинами живого хора.
Версия 5.0. Deep Field
Проект «Виртуальный хор 5.0», старт которого был анонсирован в 2018 году, предлагал исполнить произведение под названием «Deep Field». На его создание Витакера вдохновил космический телескоп «Хаббл» и сделанное с его помощью открытие — изображение небольшой области в созвездии Большой медведицы, получившее название Deep Field.
Проект разросся далеко за пределы очередного «виртуального хора». В настоящий момент существуют фильм IMAX 4k «Deep Field: The Impossible Magnitude of the Universe», а также версия для живого концертного исполнения, в котором задействованы реальные оркестр и хор (Royal Philharmonic Orchestra и Eric Whitacre Singers), Кроме того, есть виртуальный хор 5.0 (см. видео ниже), состоящий из 8000 певцов из 120 стран. Выступление сопровождается проекцией изображений области Deep Field.
Как опыт Эрика Витакера может помочь нам в 2020-м?
В одном из интервью композитор признается: «для меня петь вместе, музицировать вместе — это основополагающий человеческий опыт, и мне нравится идея, что технологии могут объединить людей со всего мира и дать им возможность попробовать что-то, выходящее за пределы их обычной жизни».
Сейчас, когда обычная жизнь для многих сузилась до пределов их квартир или домов, самое время подробнее изучить многолетний опыт Эрика Витакера и, возможно, найти в нем вдохновение, чтобы продвинуться еще дальше в соединении творчества и технологий.
Василиса Александрова
https://sysblok.ru/musicology/ideja-dlja-karantina-virtualnyj-hor/
YouTube
Deep Field: The Impossible Magnitude of our Universe
Eric Whitacre's 'Deep Field: The Impossible Magnitude of our Universe' is a unique film and musical experience inspired by one of the most important scientific discoveries of all time: the Hubble Telescope's Deep Field image.
Download now from Apple: LINK…
Download now from Apple: LINK…
Как сделать чат-бота с помощью DeepPavlov
#nlp
Сегодня уже мало кому нужно объяснять, что такое чат-боты. Мы неизбежно сталкиваемся с ними, когда хотим открыть вклад в банке, уточнить тариф у мобильного оператора или просто заказать пиццу.
Чат-боты вызывают интерес у бизнеса, ищущего способы сократить расходы на колл-центры и улучшить взаимодействие с клиентами. Кто-то идет дальше — и создает Алису, способную болтать на разные темы, развлекая вас, когда вам скучно, а значит, повышая вашу лояльность.
Наряду с разработкой таких ботов-гигантов, как Алекса, Сири и Алиса, за которыми стоят крупнейшие IT-корпорации, появляются и доступные инструменты для создания своих небольших, но полноценных целеориентированных чат-ботов. Отличным примером этого служат инструменты из библиотеки DeepPavlov от группы разработчиков на базе МФТИ.
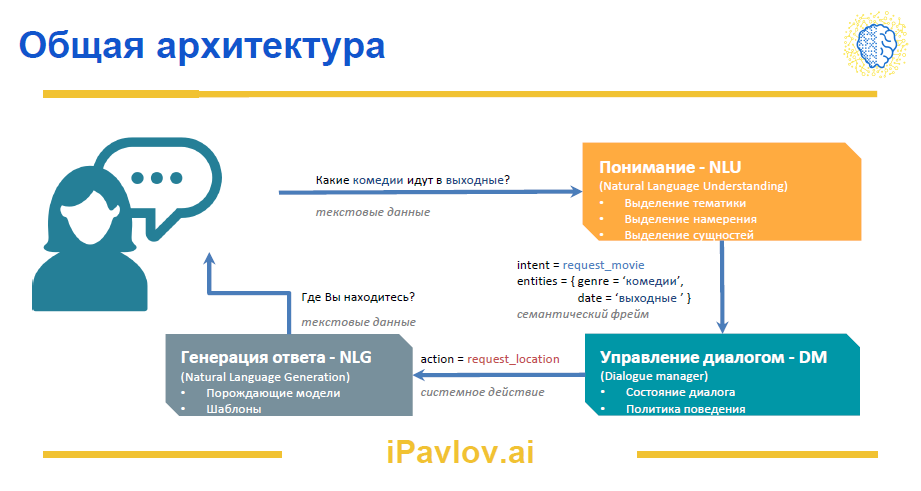
Как устроены чат-боты
На прикрепленной схеме — общая архитектура диалоговой системы чат-бота. В статье рассказываем обо всех ее компонентах и отвечаем на вопросы:
- как научить бота понимать пользователя?
- как управлять диалогом?
- как генерировать сообщения?
-как инструменты DeepPavlov могут упростить создание бота?
Полезные инструменты DeepPavlov
- предобученные модели нейронных сетей на основе BERT для классификации входящего сообщения, то есть определения домена — предметной области — разговора и интента — намерения — пользователя.
- модели для решения задачи NER — распознавания именованных сущностей, — стабильно показывающие высокое качество для русского языка (F1 score до 98.1).
- специальный компонент slotfiller в пайплайне распознавания именованных сущностей — для вставки распознанных сущностей в слоты.
- удобный спеллчекинг, помогающий справляться с опечатками в сообщениях пользователей и не плодить лишних сущностей — все вариации написания в рамках определенного порога приводятся к одному слову.
- несколько доступных конфигураций для целеориентированных ботов — для решения задач управления диалогом.
Подробный рассказ по ссылке: https://sysblok.ru/nlp/trudno-byt-botom-kak-sdelat-chatbota-s-pomoshhju-deeppavlov/
#nlp
Сегодня уже мало кому нужно объяснять, что такое чат-боты. Мы неизбежно сталкиваемся с ними, когда хотим открыть вклад в банке, уточнить тариф у мобильного оператора или просто заказать пиццу.
Чат-боты вызывают интерес у бизнеса, ищущего способы сократить расходы на колл-центры и улучшить взаимодействие с клиентами. Кто-то идет дальше — и создает Алису, способную болтать на разные темы, развлекая вас, когда вам скучно, а значит, повышая вашу лояльность.
Наряду с разработкой таких ботов-гигантов, как Алекса, Сири и Алиса, за которыми стоят крупнейшие IT-корпорации, появляются и доступные инструменты для создания своих небольших, но полноценных целеориентированных чат-ботов. Отличным примером этого служат инструменты из библиотеки DeepPavlov от группы разработчиков на базе МФТИ.
Как устроены чат-боты
На прикрепленной схеме — общая архитектура диалоговой системы чат-бота. В статье рассказываем обо всех ее компонентах и отвечаем на вопросы:
- как научить бота понимать пользователя?
- как управлять диалогом?
- как генерировать сообщения?
-как инструменты DeepPavlov могут упростить создание бота?
Полезные инструменты DeepPavlov
- предобученные модели нейронных сетей на основе BERT для классификации входящего сообщения, то есть определения домена — предметной области — разговора и интента — намерения — пользователя.
- модели для решения задачи NER — распознавания именованных сущностей, — стабильно показывающие высокое качество для русского языка (F1 score до 98.1).
- специальный компонент slotfiller в пайплайне распознавания именованных сущностей — для вставки распознанных сущностей в слоты.
- удобный спеллчекинг, помогающий справляться с опечатками в сообщениях пользователей и не плодить лишних сущностей — все вариации написания в рамках определенного порога приводятся к одному слову.
- несколько доступных конфигураций для целеориентированных ботов — для решения задач управления диалогом.
Подробный рассказ по ссылке: https://sysblok.ru/nlp/trudno-byt-botom-kak-sdelat-chatbota-s-pomoshhju-deeppavlov/
{kind=link}
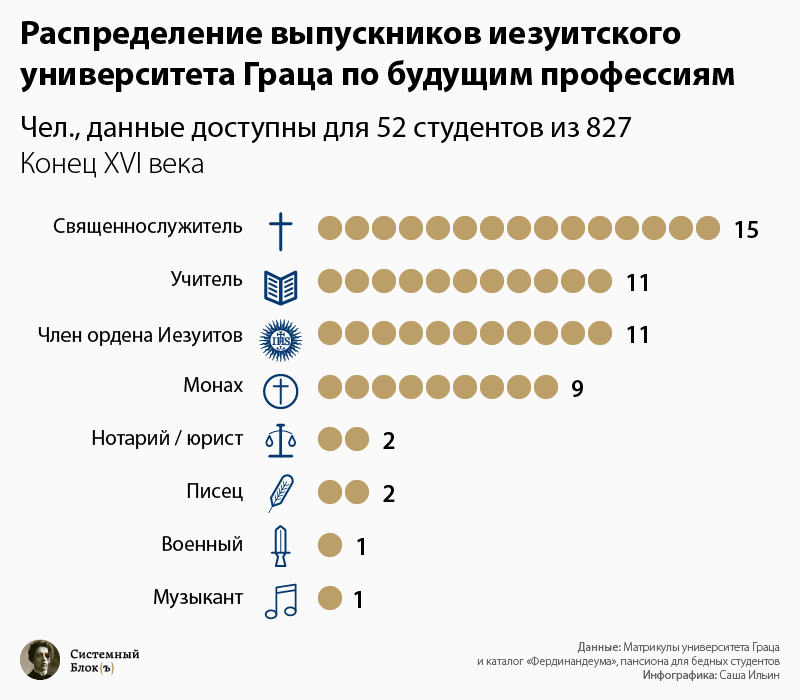
Кого учили иезуиты
#history
Орден иезуитов был передовым отрядом католической церкви в деле сопротивления Реформации. Иезуиты создали сеть школ и университетов по всей Европе. Получив исключительно высокое для своего времени образование, выпускники этих учебных заведений вели успешную работу по возвращению «заблудшие душ» в лоно Католической церкви.
Специально для «Системного Блока» историк Дмитрий Жаров рассказывает, что можно узнать, если создать и проанализировать базу данных студентов, которых обучал орден.
Откуда мы знаем об этих студентах
Группа, выбранная для анализа, — это студенты иезуитского университета города Грац (Штирия, современная Австрийская республика), проходившие обучение в период между 1586 и 1599 годами.
Источниками знаний об этих студентах послужили общеуниверситетские матрикулы (списки, куда вносили имена новых студентов) Грацского университета, а также список («Каталог») воспитанников особого пансиона для бедных студентов, который был аффилирован с университетом.
Эти источники дают нам информацию о сотнях студентов, а их крайне формализованный вид позволяет создать базу данных и применять ее как исследовательский инструмент. Сделать это можно с помощью традиционной СУБД Microsoft Access. Всего в базу вошли 827 студентов.
Коллективный портрет студенчества
У иезуитов учились главным образом люди незнатного происхождения, однако достаточно богатые для того, чтобы оплатить связанные с обучением расходы.
Большая часть студентов приезжала в Грац из австрийских, немецких и венгерских земель, однако были и отдельные личности, которые так хотели учиться в этом университете, что добирались до него из Франции, Италии, Англии и даже Литвы.
Средний возраст «абитуриента» был фактически таким же, как и сегодня — 18 лет, однако разброс в значениях был значительным: от 14 до 30 лет.
После окончания университета большая часть выпускников, сохранивших связь с alma mater, выбирала себе профессии, необходимые для утверждения католицизма на местах: священники, учителя. Некоторые становились монахами или сами вступали в орден иезуитов и продолжали там карьеру.
Нетипичные студенты
Среди выпускников встречаются и абсолютно исключительные личности, чьи судьбы явно не вписываются в «коллективную биографию». Так, например, в 1589 г. в Грац из далекой Померании (побережье Балтийского моря) прибыл 24-летний Алекс Неандр. До этого он успел отучиться в университете Франкфурта-на-Одере. Проучившись в Граце всего 4 месяца, он направился дальше, в сторону Кёльна, крупнейшего католического центра Германии.
В университете параллельно с учебой Алекс зарабатывал деньги, выступая как певец и, возможно, музыкант. Неандр за время своего недолгого обучения сумел произвести хорошее впечатление на своих наставников. Об этом нам говорит короткая приписка, которую составители матрикул сделали в графе со сведениями об Алексе: «Дай Бог ему доброй дороги». Никто другой из уходящих студентов не удостоился такого личного пожелания.
До Кёльна Неандр так и не дошел, а остановился в городе Вюрцбург во Франконии (это примерно на полпути от Граца до Кёльна), который был древним епископским центром. В Вюрцбурге бывший студент сделал блестящую и, что особенно интересно, музыкальную карьеру. Сначала он стал префектом музыки в городской иезуитской гимназии, а затем получил место музыкального директора в городском кафедральном соборе, где и оставался до своей смерти в 1605 г. Алекс Неандр был в католической среде достаточно известным композитором: он сочинил более 100 мотетов (особый музыкальный жанр) на духовную тему.
Подробный рассказ с инфографикой — по ссылке: https://sysblok.ru/history/kogo-uchili-iezuity/
#history
Орден иезуитов был передовым отрядом католической церкви в деле сопротивления Реформации. Иезуиты создали сеть школ и университетов по всей Европе. Получив исключительно высокое для своего времени образование, выпускники этих учебных заведений вели успешную работу по возвращению «заблудшие душ» в лоно Католической церкви.
Специально для «Системного Блока» историк Дмитрий Жаров рассказывает, что можно узнать, если создать и проанализировать базу данных студентов, которых обучал орден.
Откуда мы знаем об этих студентах
Группа, выбранная для анализа, — это студенты иезуитского университета города Грац (Штирия, современная Австрийская республика), проходившие обучение в период между 1586 и 1599 годами.
Источниками знаний об этих студентах послужили общеуниверситетские матрикулы (списки, куда вносили имена новых студентов) Грацского университета, а также список («Каталог») воспитанников особого пансиона для бедных студентов, который был аффилирован с университетом.
Эти источники дают нам информацию о сотнях студентов, а их крайне формализованный вид позволяет создать базу данных и применять ее как исследовательский инструмент. Сделать это можно с помощью традиционной СУБД Microsoft Access. Всего в базу вошли 827 студентов.
Коллективный портрет студенчества
У иезуитов учились главным образом люди незнатного происхождения, однако достаточно богатые для того, чтобы оплатить связанные с обучением расходы.
Большая часть студентов приезжала в Грац из австрийских, немецких и венгерских земель, однако были и отдельные личности, которые так хотели учиться в этом университете, что добирались до него из Франции, Италии, Англии и даже Литвы.
Средний возраст «абитуриента» был фактически таким же, как и сегодня — 18 лет, однако разброс в значениях был значительным: от 14 до 30 лет.
После окончания университета большая часть выпускников, сохранивших связь с alma mater, выбирала себе профессии, необходимые для утверждения католицизма на местах: священники, учителя. Некоторые становились монахами или сами вступали в орден иезуитов и продолжали там карьеру.
Нетипичные студенты
Среди выпускников встречаются и абсолютно исключительные личности, чьи судьбы явно не вписываются в «коллективную биографию». Так, например, в 1589 г. в Грац из далекой Померании (побережье Балтийского моря) прибыл 24-летний Алекс Неандр. До этого он успел отучиться в университете Франкфурта-на-Одере. Проучившись в Граце всего 4 месяца, он направился дальше, в сторону Кёльна, крупнейшего католического центра Германии.
В университете параллельно с учебой Алекс зарабатывал деньги, выступая как певец и, возможно, музыкант. Неандр за время своего недолгого обучения сумел произвести хорошее впечатление на своих наставников. Об этом нам говорит короткая приписка, которую составители матрикул сделали в графе со сведениями об Алексе: «Дай Бог ему доброй дороги». Никто другой из уходящих студентов не удостоился такого личного пожелания.
До Кёльна Неандр так и не дошел, а остановился в городе Вюрцбург во Франконии (это примерно на полпути от Граца до Кёльна), который был древним епископским центром. В Вюрцбурге бывший студент сделал блестящую и, что особенно интересно, музыкальную карьеру. Сначала он стал префектом музыки в городской иезуитской гимназии, а затем получил место музыкального директора в городском кафедральном соборе, где и оставался до своей смерти в 1605 г. Алекс Неандр был в католической среде достаточно известным композитором: он сочинил более 100 мотетов (особый музыкальный жанр) на духовную тему.
Подробный рассказ с инфографикой — по ссылке: https://sysblok.ru/history/kogo-uchili-iezuity/
{kind=link}
Разделить цену победы: большое исследование призыва в ВОВ от команды «Системного Блока»
#history #research
В истории Войны много неизвестных и спорных мест. К сожалению, до сих пор многие данные засекречены, ведутся споры о количестве погибших, многие до сих пор не знают, чем закончился путь их дедушки или отца. Мы предлагаем посмотреть на историю ВОВ через историю призыва и опираться не на единичные источники, а сразу на миллионы свидетельств.
Команда «Системного Блока» провела для вас собственное исследование — мы изучили 26 миллионов карточек военно-пересыльных пунктов, через которые солдаты направлялись на фронт. Сквозь призму призыва нам удается посмотреть на историю участия в войне отдельных республик и восстановить хронологию событий.
Исследование динамики призыва позволило выделить характерные портреты призыва в республиках и объединить схожие республики в группы. Призыв во многом схож в РСФСР, Казахстане и Киргизии. Совершенно по-другому выглядит призыв в республиках, которые были оккупированы в ходе войны — всю историю оккупации и освобождения можно видеть через графики призыва. В Грузинской, Азербайджанской и Армянской ССР активный призыв ведется до 1943 года, а для республик Средней Азии характерен особый вид призыва — трудовой. И все эти явления видны в данных.
Обработанные данные мы выложили в наш открытый репозиторий, они доступны исследователям. Мы выступаем за открытость всех общественно важных данных и материалов по Великой Отечественной войне и XX веку в целом.
Полный текст исследования и интерактивные визуализации по ссылке:
https://sysblok.ru/history/neizvestnyj-soldat/
#history #research
В истории Войны много неизвестных и спорных мест. К сожалению, до сих пор многие данные засекречены, ведутся споры о количестве погибших, многие до сих пор не знают, чем закончился путь их дедушки или отца. Мы предлагаем посмотреть на историю ВОВ через историю призыва и опираться не на единичные источники, а сразу на миллионы свидетельств.
Команда «Системного Блока» провела для вас собственное исследование — мы изучили 26 миллионов карточек военно-пересыльных пунктов, через которые солдаты направлялись на фронт. Сквозь призму призыва нам удается посмотреть на историю участия в войне отдельных республик и восстановить хронологию событий.
Исследование динамики призыва позволило выделить характерные портреты призыва в республиках и объединить схожие республики в группы. Призыв во многом схож в РСФСР, Казахстане и Киргизии. Совершенно по-другому выглядит призыв в республиках, которые были оккупированы в ходе войны — всю историю оккупации и освобождения можно видеть через графики призыва. В Грузинской, Азербайджанской и Армянской ССР активный призыв ведется до 1943 года, а для республик Средней Азии характерен особый вид призыва — трудовой. И все эти явления видны в данных.
Обработанные данные мы выложили в наш открытый репозиторий, они доступны исследователям. Мы выступаем за открытость всех общественно важных данных и материалов по Великой Отечественной войне и XX веку в целом.
Полный текст исследования и интерактивные визуализации по ссылке:
https://sysblok.ru/history/neizvestnyj-soldat/
{kind=link}
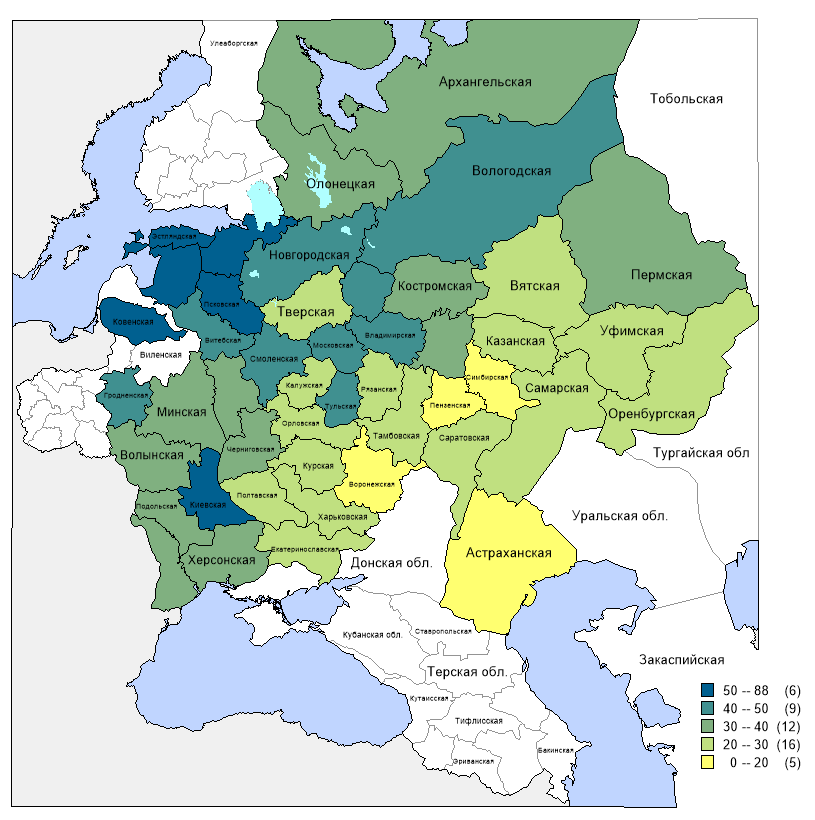
Картирование криминала и рост средневековых городов: зачем историкам ГИСы
#society #history
Мы пользуемся геоинформационными системами (ГИСами) каждый день, когда лезем в карты на телефоне или едем куда-то по навигатору. А зачем ГИСы историку, если он изучает Российскую империю или средневековый Новгород? Разбор от специалиста по исторической информатике — специально для «Системного Блока».
В широком смысле ГИСы — программное обеспечение, а точнее, информационные системы, способные обрабатывать любую информацию из баз данных. Например, в роли таких приложений могут выступать ArcView, QGIS, MapInfo и др.
Что касается исторической науки, то здесь ГИСами называют как информационные системы, так и сам метод, благодаря которому историк может анализировать различного рода данные. Карта для историка — это набор пространственно-географических и исторических данных, где историк может комбинировать различные характеристики, добавлять иные данные. Проще говоря, у историков появилась возможность собрать значимые данные в привязке к географическому положению и проанализировать их разными способами.
Применение ГИСов для исследования частотности совершения преступлений в губерниях Российской империи
У нас были данные о количестве осужденных за все преступления в Европейской России 1896 года, взятые из обзоров отчетов губернаторов 50 губерний Европейской России. Для представления этой информации на карте нам потребовались также данные переписи населения 1897 года. С их помощью можно получить относительные числа (то есть количество осужденных на 100 000 человек), а без них графическое представление данных вышло бы искаженным.
На первом этапе мы собрали информацию об осужденных в таблицу в Excel. Далее мы привязали эти данные к используемому шаблону карты (который был предоставлен кафедрой исторической информатики МГУ им. М. В. Ломоносова) в программе MapInfo Pro 15.0. Затем по заданному запросу мы сформировали единую таблицу, которая легла в основу создаваемых карт. На последнем этапе мы сформировали сами карты, задав диапазоны и цвета объектов.
Результаты исследования
Изначально у нас была гипотеза о том, что в промышленных и урбанизированных губерниях наиболее часто совершаются преступления против собственности (это разбои, грабежи, кражи и мошенничество), а в сельских — против личности (убийства, нанесение ран и увечий).
Мы увидели, что наибольшее количество осужденных (на 100 000 человек) встречается в прибалтийских губерниях, а также в Киевской. Далее идут губернии центрального промышленного района и других.
Мы выделили три основных типа преступлений для всего региона: это преступления против личности, против собственности и против общественного благоустройства и благочиния.
Мы выяснили, что преступления против собственности характерны для территорий, где проживает больше городского населения, и для промышленных регионов Европейской России в целом, а связь преступлений против личности с сельскими регионами не наблюдается. Этот тип преступлений также связан с регионами с преобладающей долей городского населения.
Помимо карт мы использовали метод подсчета коэффициентов корреляции для числа осужденных за каждое преступление и данных из переписи. В итоге гипотеза была подтверждена лишь частично и с рядом оговорок, так как у нас были все-таки данные не о числе преступлений, а о количестве осужденных за эти преступления — а это разные вещи.
Ниже прикреплена карта относительной плотности осужденных за все преступления в 1896 г. по губерниям Европейской России (на 100 тысяч человек).
Екатерина Олейникова
По ссылке подробно и со скриншотами рассказываем о создании ГИСов, о развитии геоинформатики и о других исследованиях, с ипользованием ГИСов: https://sysblok.ru/history/kartirovanie-kriminala-i-rost-srednevekovyh-gorodov-zachem-istorikam-gisy/
#society #history
Мы пользуемся геоинформационными системами (ГИСами) каждый день, когда лезем в карты на телефоне или едем куда-то по навигатору. А зачем ГИСы историку, если он изучает Российскую империю или средневековый Новгород? Разбор от специалиста по исторической информатике — специально для «Системного Блока».
В широком смысле ГИСы — программное обеспечение, а точнее, информационные системы, способные обрабатывать любую информацию из баз данных. Например, в роли таких приложений могут выступать ArcView, QGIS, MapInfo и др.
Что касается исторической науки, то здесь ГИСами называют как информационные системы, так и сам метод, благодаря которому историк может анализировать различного рода данные. Карта для историка — это набор пространственно-географических и исторических данных, где историк может комбинировать различные характеристики, добавлять иные данные. Проще говоря, у историков появилась возможность собрать значимые данные в привязке к географическому положению и проанализировать их разными способами.
Применение ГИСов для исследования частотности совершения преступлений в губерниях Российской империи
У нас были данные о количестве осужденных за все преступления в Европейской России 1896 года, взятые из обзоров отчетов губернаторов 50 губерний Европейской России. Для представления этой информации на карте нам потребовались также данные переписи населения 1897 года. С их помощью можно получить относительные числа (то есть количество осужденных на 100 000 человек), а без них графическое представление данных вышло бы искаженным.
На первом этапе мы собрали информацию об осужденных в таблицу в Excel. Далее мы привязали эти данные к используемому шаблону карты (который был предоставлен кафедрой исторической информатики МГУ им. М. В. Ломоносова) в программе MapInfo Pro 15.0. Затем по заданному запросу мы сформировали единую таблицу, которая легла в основу создаваемых карт. На последнем этапе мы сформировали сами карты, задав диапазоны и цвета объектов.
Результаты исследования
Изначально у нас была гипотеза о том, что в промышленных и урбанизированных губерниях наиболее часто совершаются преступления против собственности (это разбои, грабежи, кражи и мошенничество), а в сельских — против личности (убийства, нанесение ран и увечий).
Мы увидели, что наибольшее количество осужденных (на 100 000 человек) встречается в прибалтийских губерниях, а также в Киевской. Далее идут губернии центрального промышленного района и других.
Мы выделили три основных типа преступлений для всего региона: это преступления против личности, против собственности и против общественного благоустройства и благочиния.
Мы выяснили, что преступления против собственности характерны для территорий, где проживает больше городского населения, и для промышленных регионов Европейской России в целом, а связь преступлений против личности с сельскими регионами не наблюдается. Этот тип преступлений также связан с регионами с преобладающей долей городского населения.
Помимо карт мы использовали метод подсчета коэффициентов корреляции для числа осужденных за каждое преступление и данных из переписи. В итоге гипотеза была подтверждена лишь частично и с рядом оговорок, так как у нас были все-таки данные не о числе преступлений, а о количестве осужденных за эти преступления — а это разные вещи.
Ниже прикреплена карта относительной плотности осужденных за все преступления в 1896 г. по губерниям Европейской России (на 100 тысяч человек).
Екатерина Олейникова
По ссылке подробно и со скриншотами рассказываем о создании ГИСов, о развитии геоинформатики и о других исследованиях, с ипользованием ГИСов: https://sysblok.ru/history/kartirovanie-kriminala-i-rost-srednevekovyh-gorodov-zachem-istorikam-gisy/
{kind=link}
Айтрекинг в психологии искусства: что и как влияет на восприятие великих полотен
#arts
Восприятие искусства — комплексный процесс, включающий понимание, запоминание и составление собственного впечатления, допустим, о картине. Когда мы смотрим на картину, мы ее «сканируем»: сначала быстро фиксируем как единое целое, а затем начинаем перескакивать с одной детали на другую. Что наиболее бросается в глаза, то и «перехватывает» наше внимание. Если знать, сколько времени зритель посвящает изучению полотна, можно сделать вывод о его потребностях, интересах и эстетических взглядах. А если зрителей много — о потребностях и интересах целой аудитории.
Технология айтрекинга
Айтрекинг или управление взглядом — технология для определения положения глаз зрителя относительно дисплея, на который выведено изображение. Данные, полученные в ходе «слежения» за глазом, позволяют проанализировать как люди воспринимают визуальную информацию, что вызывает у них интерес, а какие элементы работают неэффективно.
Устройство айтрекера состоит из камер и осветителей, которые крепятся на монитор компьютера. Инфракрасный луч света направляется на сетчатку глаза, а сверхчувствительная камера записывает малейшие изменения ее положения (в том числе сужение-расширение зрачка). Математические алгоритмы сопоставляют изображение, на которое смотрит человек, с последовательными движениями глаз. Визуализированные траектории взгляда показывают, что привлекает внимание зрителя в первую очередь, а тепловые карты — что вызвало наибольший интерес.
Исследование влияния подписи к картине на ее восприятие
В совместном проекте университетов Оксфорда и Дарема ученые поставили цель выяснить, как современный человек оценивает картины и что может повлиять на его мнение. Предположили, что на восприятие могут влиять краткие описания, которые сопровождают картины в галереях и музеях. Ученые предложили участникам эксперимента сначала ознакомиться с информацией о каждой картине, а затем измеряли время, уделенное изучению деталей, и направление движений глаз, используя технологии айтрекинга в лабораторных условиях.
Исследования проводились в лаборатории с использованием цифровых копий картин из цикла «Иаков и его 12 сыновей» Франциско де Сурбарана, испанского художника 17-го века. Каждой картине серии присвоили по три подписи, которые характеризовали их с трех разных позиций. Участников эксперимента разделили соответственно на три группы. Группе 1 «Музейный контекст» представили описание, делающее акцент на смысловой составляющей картины — на Библейской легенде; группе 2 «Эстетический контекст» — описание художественной ценности полотен; группе 3 «Авторский контекст» — общую информацию о картине и ее авторе.
Результаты исследования
Внимание групп 1 и 3 сосредотачивалось в основном на лицах и символах-атрибутах, а группы 2 — было более рассеяно. Пример тепловой карты на основе изображения брата Левия прикреплен ниже.
Также, гипотеза — чем больше информации получает зритель перед просмотром, тем больше ему нравится картина — не подтвердилась. Ярлыки с подробным описанием картины заставляли испытуемых меньше смотреть на лица, и картины они находили менее приятными. Наиболее заинтересованы в картинах оказались участники, которым дали минимум информации.
После эксперимента участникам было предложено оценить работы, как это делалось бы на аукционе. Как выяснилось, конкретика, данная изначально в описании работы, придавала участникам больше уверенности при оценке. Участники группы 1, опираясь на ветхозаветные описания героев картин, назвали самыми дорогими шесть холстов, группа 2 с точки зрения культурной ценности — всего пять, а группа 3 распространила свои суждения на восемь полотен.
Мария Черных
https://sysblok.ru/arts/ajtreking-v-psihologii-iskusstva-vyjasnjaem-chto-i-kak-vlijaet-na-nashe-vosprijatie-velikih-poloten/
#arts
Восприятие искусства — комплексный процесс, включающий понимание, запоминание и составление собственного впечатления, допустим, о картине. Когда мы смотрим на картину, мы ее «сканируем»: сначала быстро фиксируем как единое целое, а затем начинаем перескакивать с одной детали на другую. Что наиболее бросается в глаза, то и «перехватывает» наше внимание. Если знать, сколько времени зритель посвящает изучению полотна, можно сделать вывод о его потребностях, интересах и эстетических взглядах. А если зрителей много — о потребностях и интересах целой аудитории.
Технология айтрекинга
Айтрекинг или управление взглядом — технология для определения положения глаз зрителя относительно дисплея, на который выведено изображение. Данные, полученные в ходе «слежения» за глазом, позволяют проанализировать как люди воспринимают визуальную информацию, что вызывает у них интерес, а какие элементы работают неэффективно.
Устройство айтрекера состоит из камер и осветителей, которые крепятся на монитор компьютера. Инфракрасный луч света направляется на сетчатку глаза, а сверхчувствительная камера записывает малейшие изменения ее положения (в том числе сужение-расширение зрачка). Математические алгоритмы сопоставляют изображение, на которое смотрит человек, с последовательными движениями глаз. Визуализированные траектории взгляда показывают, что привлекает внимание зрителя в первую очередь, а тепловые карты — что вызвало наибольший интерес.
Исследование влияния подписи к картине на ее восприятие
В совместном проекте университетов Оксфорда и Дарема ученые поставили цель выяснить, как современный человек оценивает картины и что может повлиять на его мнение. Предположили, что на восприятие могут влиять краткие описания, которые сопровождают картины в галереях и музеях. Ученые предложили участникам эксперимента сначала ознакомиться с информацией о каждой картине, а затем измеряли время, уделенное изучению деталей, и направление движений глаз, используя технологии айтрекинга в лабораторных условиях.
Исследования проводились в лаборатории с использованием цифровых копий картин из цикла «Иаков и его 12 сыновей» Франциско де Сурбарана, испанского художника 17-го века. Каждой картине серии присвоили по три подписи, которые характеризовали их с трех разных позиций. Участников эксперимента разделили соответственно на три группы. Группе 1 «Музейный контекст» представили описание, делающее акцент на смысловой составляющей картины — на Библейской легенде; группе 2 «Эстетический контекст» — описание художественной ценности полотен; группе 3 «Авторский контекст» — общую информацию о картине и ее авторе.
Результаты исследования
Внимание групп 1 и 3 сосредотачивалось в основном на лицах и символах-атрибутах, а группы 2 — было более рассеяно. Пример тепловой карты на основе изображения брата Левия прикреплен ниже.
Также, гипотеза — чем больше информации получает зритель перед просмотром, тем больше ему нравится картина — не подтвердилась. Ярлыки с подробным описанием картины заставляли испытуемых меньше смотреть на лица, и картины они находили менее приятными. Наиболее заинтересованы в картинах оказались участники, которым дали минимум информации.
После эксперимента участникам было предложено оценить работы, как это делалось бы на аукционе. Как выяснилось, конкретика, данная изначально в описании работы, придавала участникам больше уверенности при оценке. Участники группы 1, опираясь на ветхозаветные описания героев картин, назвали самыми дорогими шесть холстов, группа 2 с точки зрения культурной ценности — всего пять, а группа 3 распространила свои суждения на восемь полотен.
Мария Черных
https://sysblok.ru/arts/ajtreking-v-psihologii-iskusstva-vyjasnjaem-chto-i-kak-vlijaet-na-nashe-vosprijatie-velikih-poloten/
{kind=link}
Вся классика в один клик: как выделить из текста события
#philology
Школьники, зависающие на сайтах с краткими содержаниями, многое бы отдали за чудо-ресурс, которому можно было бы отдать художественное произведение и получить взамен описание событий в тексте. Рассказываем, как работает технология извлечения событий из художественных текстов и что она позволяет узнать о литературе уже сейчас.
Художественные произведения — сложный материал для анализа, так как они длинные, структура событий в них сложная и запутанная, а их первостепенная цель — эмоциональное воздействие на читателя.
Сбор и разметка данных
Ученые собрали корпус на основе текстов, публично доступных на ресурсе Project Gutenberg. В корпусе есть и произведения, относящиеся высокому литературному стилю («Улисс» Джеймса Джойса), и более массовая литература («Рваный Дик» Горацио Элджера). Все тексты были опубликованы до 1923 г. и из каждого взяты первые 2000 слов, чтобы уравнять все произведения.
Исследователи решили, что их интересуют события, действительно произошедшие в произведении. При разметке они руководствовались следующими правилами:
1. Полярность: размечались только произошедшие события с положительной полярностью. События-отрицания не размечались как произошедшие.
2. Грамматическое время: размечались события, выраженные глаголами в настоящем или прошедшем времени.
3. Универсальность: все универсальные события, описывающие обыденные действия, которые могли бы выглядеть и быть описаны абсолютно так же в другом произведении (например, собаки лаяли) не размечались.
4. Модальность: размечались только те события, о которых говорилось с уверенностью.
Помимо самих событий, авторы также размечали триггеры к ним — одно слово, которое может описать событие. В корпусе из 210 532 токенов-слов получилось 7 849 событий; результат разметки находится в открытом доступе.
В результате оказалось, что большинство событий можно разбить на четыре категории: разговор, движение, восприятие и обладание. Таблица ниже показывает, как часто встречались слова из этих категорий.
Анализ событий с помощью нейросетей
Из полученного датасета сделали два набора признаковых описаний: в одном из них использовалось векторное описание слов, в другом, помимо векторного описания, были лингвистические признаки: часть речи, информация о контексте, информация о семантике слова, полученная при помощи WordNet, и специфическая информация о конкретном слове (например, если это bare plural — существительное во множественном числе, которое используется в основном для того, чтобы фраза получила универсальное прочтение: «Кошки любят молоко»).
Исследователи определили свою задачу как выявление связи между рассматриваемым словом и событием. Для этого использовались нейронные сети двух различных архитектур — одно- и двунаправленная LSTM и свёрточная нейронная сеть (CNN). В итоге лучшей комбинацией стала двунаправленная LSTM-сеть, в которой векторное описание слов было получено при помощи BERT — модели, которая для вычисления вектора слова также учитывает его контекст. Такая модель выделила события с F-мерой 73.9.
Дальнее чтение корпуса
Ученые решили посмотреть, отличаются ли предсказания сети для текстов разного уровня литературного мастерства.
В среднем в высокохудожественных произведениях оказалось чуть меньше событий (4.6% против 5.5%), которые чуть более подробно описаны: в среднем между двумя найденными событиями более «элитного» текста помещалось 23.4 слова, а в менее элитарных текстах — 19.2 слова.
Также авторы сравнили произведения, разделив их по популярности, но здесь различий не обнаружили: во всех текстах в среднем случалось около 4.5% событий примерно одной длины.
Дарья Максимова
https://sysblok.ru/philology/vsja-klassika-v-odin-klik-kak-vydelit-iz-teksta-sobytija/
#philology
Школьники, зависающие на сайтах с краткими содержаниями, многое бы отдали за чудо-ресурс, которому можно было бы отдать художественное произведение и получить взамен описание событий в тексте. Рассказываем, как работает технология извлечения событий из художественных текстов и что она позволяет узнать о литературе уже сейчас.
Художественные произведения — сложный материал для анализа, так как они длинные, структура событий в них сложная и запутанная, а их первостепенная цель — эмоциональное воздействие на читателя.
Сбор и разметка данных
Ученые собрали корпус на основе текстов, публично доступных на ресурсе Project Gutenberg. В корпусе есть и произведения, относящиеся высокому литературному стилю («Улисс» Джеймса Джойса), и более массовая литература («Рваный Дик» Горацио Элджера). Все тексты были опубликованы до 1923 г. и из каждого взяты первые 2000 слов, чтобы уравнять все произведения.
Исследователи решили, что их интересуют события, действительно произошедшие в произведении. При разметке они руководствовались следующими правилами:
1. Полярность: размечались только произошедшие события с положительной полярностью. События-отрицания не размечались как произошедшие.
2. Грамматическое время: размечались события, выраженные глаголами в настоящем или прошедшем времени.
3. Универсальность: все универсальные события, описывающие обыденные действия, которые могли бы выглядеть и быть описаны абсолютно так же в другом произведении (например, собаки лаяли) не размечались.
4. Модальность: размечались только те события, о которых говорилось с уверенностью.
Помимо самих событий, авторы также размечали триггеры к ним — одно слово, которое может описать событие. В корпусе из 210 532 токенов-слов получилось 7 849 событий; результат разметки находится в открытом доступе.
В результате оказалось, что большинство событий можно разбить на четыре категории: разговор, движение, восприятие и обладание. Таблица ниже показывает, как часто встречались слова из этих категорий.
Анализ событий с помощью нейросетей
Из полученного датасета сделали два набора признаковых описаний: в одном из них использовалось векторное описание слов, в другом, помимо векторного описания, были лингвистические признаки: часть речи, информация о контексте, информация о семантике слова, полученная при помощи WordNet, и специфическая информация о конкретном слове (например, если это bare plural — существительное во множественном числе, которое используется в основном для того, чтобы фраза получила универсальное прочтение: «Кошки любят молоко»).
Исследователи определили свою задачу как выявление связи между рассматриваемым словом и событием. Для этого использовались нейронные сети двух различных архитектур — одно- и двунаправленная LSTM и свёрточная нейронная сеть (CNN). В итоге лучшей комбинацией стала двунаправленная LSTM-сеть, в которой векторное описание слов было получено при помощи BERT — модели, которая для вычисления вектора слова также учитывает его контекст. Такая модель выделила события с F-мерой 73.9.
Дальнее чтение корпуса
Ученые решили посмотреть, отличаются ли предсказания сети для текстов разного уровня литературного мастерства.
В среднем в высокохудожественных произведениях оказалось чуть меньше событий (4.6% против 5.5%), которые чуть более подробно описаны: в среднем между двумя найденными событиями более «элитного» текста помещалось 23.4 слова, а в менее элитарных текстах — 19.2 слова.
Также авторы сравнили произведения, разделив их по популярности, но здесь различий не обнаружили: во всех текстах в среднем случалось около 4.5% событий примерно одной длины.
Дарья Максимова
https://sysblok.ru/philology/vsja-klassika-v-odin-klik-kak-vydelit-iz-teksta-sobytija/
{kind=link}
Как работают рекомендательные системы — и что с ними будет завтра
#arts
Часто ли вы сталкиваетесь с проблемой выбора фильма на вечер? И как эту проблему вы решаете сегодня? Подборки на тематических порталах, советы друзей, оценки критиков. К сожалению, эти инструменты обладают одной существенной погрешностью — они исключают персонализацию. Еще одна проблема лежит в поведенческой номенклатуре нашего мозга и чистой математике: чем больше выбор — тем сложнее выбирать.
Основные принципы рекомендательных систем
Рекомендательные системы в своей привычной форме существуют порядка 30 лет, однако архитектурно не претерпели больших перемен. Можно выделить две основные методики, применяемые в производстве: коллаборативная фильтрация (User-Based Filtering) и фильтрация по содержанию (Content-Based Filtering).
Коллаборативная фильтрация строит прогноз на основе пользователей со схожими признаками, интересами или поведением, группируя их в кластеры. Выявить степень «схожести» можно с помощью формулы расчета корреляции, например, Пирсона.
Второй способ фильтрации (Content-Based Filtering) отличает лишь то, что за основу берутся похожие группы контента (в нашем случае — похожие фильмы). И по тому же принципу выявляет степень соседства между фильмами.
На деле применение алгоритма выглядит куда сложнее и чаще всего представляет собой гибридную модель.
Какие есть трудности
Из-за дефицита данных могут возникать проблемы. К примеру, проблема холодного старта (когда мы ничего не знаем о пользователе, следовательно, неясно что ему рекомендовать), или проблема нового контента (что порождает проблему разнообразия), или синонимия (когда похожие и одинаковые предметы имеют разные имена, например, жанры «детский фильм» и «фильм для детей»). Поэтому приходится логировать (т. е. сохранять в памяти системы) все, пытаясь «между строк» предугадать намерение пользователя.
Так, совокупность данных формируют явные (explicit ratings) и неявные (implicit ratings) информационные сигналы, получаемые от пользователей. На примере кино: явным сигналом может служить оценка, неявным — просмотр трейлера. Вес этих сигналов также будет индивидуален (оценка представляет большую ценность для сервиса).
Пример Netflix
Для демонстрации современного образца рекомендательных систем обратимся к Netflix. В 2006 году компания решила повысить релевантность рекомендаций и объявила конкурс на 1 млн. долларов, который достанется тому, кто сможет улучшить текущее качество прогноза не менее чем на 10%. Качество прогноза измерялось на основе среднеквадратичного отклонения (Root Mean Square Error) и на момент объявления конкурса составляла 0.9514. Целью же было снизить эту ошибку как минимум до 0.8563.
Соревнование длилось порядка трех лет. В качестве обучающих данных был использован датасет из 100 с лишним миллионов реальных оценок пользователей сервиса. Победителем стала команда «BellKor’s Pragmatic Chaos», которой удалось улучшить результаты на 10,06%.
Сейчас обучающийся алгоритм Netflix учитывает не только оценки пользователей, но и весь доступный контекст — время суток, данные о возрасте и поле, географическое положение. Сам алгоритм использует не только регрессионные методы прогнозирования, но и метод сингулярного разложения, генеративные стохастические нейронные сети, обучение ассоциативным правилам, градиентный бустинг и многое другое, что формирует архитектуру под капотом.
Чего ждать от рекомендательных систем завтра
При выборе фильма существует еще одна проблема — мы часто сами не знаем, чего по-настоящему хотим. Можно предположить, что стриминговые сервисы (Netflix, Amazon Prime, Hulu, HBO и другие) будут влиять на киноиндустрию, определяя принципы производства нового контента.
Иными словами, будут снимать ровно то, что будет востребовано, и вопросы «что я хочу посмотреть» перестанут волновать аудиторию, поскольку ответ будет получен до возникновения самого вопроса.
Михаил Бабасян
https://sysblok.ru/arts/kak-rabotajut-rekomendatelnye-sistemy-i-chto-s-nimi-budet-zavtra/
#arts
Часто ли вы сталкиваетесь с проблемой выбора фильма на вечер? И как эту проблему вы решаете сегодня? Подборки на тематических порталах, советы друзей, оценки критиков. К сожалению, эти инструменты обладают одной существенной погрешностью — они исключают персонализацию. Еще одна проблема лежит в поведенческой номенклатуре нашего мозга и чистой математике: чем больше выбор — тем сложнее выбирать.
Основные принципы рекомендательных систем
Рекомендательные системы в своей привычной форме существуют порядка 30 лет, однако архитектурно не претерпели больших перемен. Можно выделить две основные методики, применяемые в производстве: коллаборативная фильтрация (User-Based Filtering) и фильтрация по содержанию (Content-Based Filtering).
Коллаборативная фильтрация строит прогноз на основе пользователей со схожими признаками, интересами или поведением, группируя их в кластеры. Выявить степень «схожести» можно с помощью формулы расчета корреляции, например, Пирсона.
Второй способ фильтрации (Content-Based Filtering) отличает лишь то, что за основу берутся похожие группы контента (в нашем случае — похожие фильмы). И по тому же принципу выявляет степень соседства между фильмами.
На деле применение алгоритма выглядит куда сложнее и чаще всего представляет собой гибридную модель.
Какие есть трудности
Из-за дефицита данных могут возникать проблемы. К примеру, проблема холодного старта (когда мы ничего не знаем о пользователе, следовательно, неясно что ему рекомендовать), или проблема нового контента (что порождает проблему разнообразия), или синонимия (когда похожие и одинаковые предметы имеют разные имена, например, жанры «детский фильм» и «фильм для детей»). Поэтому приходится логировать (т. е. сохранять в памяти системы) все, пытаясь «между строк» предугадать намерение пользователя.
Так, совокупность данных формируют явные (explicit ratings) и неявные (implicit ratings) информационные сигналы, получаемые от пользователей. На примере кино: явным сигналом может служить оценка, неявным — просмотр трейлера. Вес этих сигналов также будет индивидуален (оценка представляет большую ценность для сервиса).
Пример Netflix
Для демонстрации современного образца рекомендательных систем обратимся к Netflix. В 2006 году компания решила повысить релевантность рекомендаций и объявила конкурс на 1 млн. долларов, который достанется тому, кто сможет улучшить текущее качество прогноза не менее чем на 10%. Качество прогноза измерялось на основе среднеквадратичного отклонения (Root Mean Square Error) и на момент объявления конкурса составляла 0.9514. Целью же было снизить эту ошибку как минимум до 0.8563.
Соревнование длилось порядка трех лет. В качестве обучающих данных был использован датасет из 100 с лишним миллионов реальных оценок пользователей сервиса. Победителем стала команда «BellKor’s Pragmatic Chaos», которой удалось улучшить результаты на 10,06%.
Сейчас обучающийся алгоритм Netflix учитывает не только оценки пользователей, но и весь доступный контекст — время суток, данные о возрасте и поле, географическое положение. Сам алгоритм использует не только регрессионные методы прогнозирования, но и метод сингулярного разложения, генеративные стохастические нейронные сети, обучение ассоциативным правилам, градиентный бустинг и многое другое, что формирует архитектуру под капотом.
Чего ждать от рекомендательных систем завтра
При выборе фильма существует еще одна проблема — мы часто сами не знаем, чего по-настоящему хотим. Можно предположить, что стриминговые сервисы (Netflix, Amazon Prime, Hulu, HBO и другие) будут влиять на киноиндустрию, определяя принципы производства нового контента.
Иными словами, будут снимать ровно то, что будет востребовано, и вопросы «что я хочу посмотреть» перестанут волновать аудиторию, поскольку ответ будет получен до возникновения самого вопроса.
Михаил Бабасян
https://sysblok.ru/arts/kak-rabotajut-rekomendatelnye-sistemy-i-chto-s-nimi-budet-zavtra/
{kind=link}
Как мы теряем природные ресурсы темноты
#urban
По снимкам ночной Земли урбанисты научились оценивать плотность и численность населения во всех регионах Земли с достаточной регулярностью. На снимках также хорошо видны электрифицированные регионы, что позволяет оценить и уровень жизни населения.
Интенсивное освещение обычно сопровождает города. Общее правило звучит так: «больше людей — больше света». Это называют световым загрязнением — по аналогии с загрязнением других сред жизни человека и всех живых существ. И это тоже экологическая проблема.
Свет от искусственных источников рассеивается в нижних слоях атмосферы, что вызывает изменения в биоритмах ночных существ, сбивает птиц с их курса миграции и мешает нам увидеть ночное небо.
Что влияет на световой ландшафт
Картограф Descartes Lab Тим Уоллас решил уточнить, от чего конкретно зависит освещенность планеты. Для этого он нормализовал яркость точек на снимках на численность населения. Ниже прикреплены три карты, иллюстрирующие 1) ночную освещенность территории США, 2) распределение населения по территории США, 3) освещенность, нормализованную по населению.
На третьей карте световой ландшафт сильно отличается от того, что было на первой карте. Видно, что самые яркие точки находятся вовсе не в мегаполисах, а за их пределами.
Тим Уоллас и Джон Барентайн, член Международной Ассоциации Темного Неба (International Dark-Sky Association), выделяют три основных типа явлений, световой след от которых виден из космоса: добыча нефти и газа, склады и теплицы.
Добыча нефти и газа
Сейчас США являются лидерами по добыче сланцевой нефти. Нефтеносные регионы выделяются яркими пятнами, а на более детальных участках можно даже рассмотреть регулярную структуру площадок добычи.
Основными источниками света здесь являются факелы сжигаемого попутного природного газа (излишки газа, образующиеся при добыче нефти, перерабатывать которые экономически нецелесообразно) и освещение площадок добычи и жилых площадей работников.
В некоторых регионах добычи с 2010 по 2013 год рассеянное освещение от искусственных источников увеличилось на 500%. После 2014 года, когда цены на нефть на мировых рынках рухнули, активное развитие добычи сланцевой нефти прекратилось, но световое воздействие не уменьшилось.
Склады
Быстрая доставка любых товаров — кажется, одна из характеристик современных США. Amazon, FedEx, UPS, DHL и многие другие — каждая из этих компаний владеет огромными площадями складских помещений, без которых доставка затягивалась бы на гораздо большие сроки. Многие из них расположены за пределами крупных городов, где дешевле владеть большими участками земли. Все они ярко освещены по ночам, так как работа там редко останавливается.
Теплицы
Тим Уоллас особенно выделяет одну точку на карте штата Мэн: посреди довольно темного фона светится яркая точка — это внушительные 42 акра теплиц фирмы Backyard Farm, которая специализируется на выращивании помидоров.
Исследователи отмечают, что производители тепличной продукции любят менять спектр освещения, адаптируя условия для отдельных культур. Это стало возможным с развитием LED-освещения (светодиодов).
Возможно, вы видели снимки фиолетового неба, сделанные в январе этого года жителями города Сноуфлейк в штате Аризона — оказалось, что это отсветы освещения теплиц огромной плантации марихуаны неподалеку, усиленные погодными условиями — низкой облачностью и туманом.
Если же вам придется как-нибудь пролетать над Нидерландами ночью, обратите внимание на сияющие оранжевые пятна, разбросанные по территории страны — теплицы, в которых выращивают тюльпаны.
Нелли Бурцева
https://sysblok.ru/urban/kak-my-terjaem-prirodnye-resursy-temnoty/
#urban
По снимкам ночной Земли урбанисты научились оценивать плотность и численность населения во всех регионах Земли с достаточной регулярностью. На снимках также хорошо видны электрифицированные регионы, что позволяет оценить и уровень жизни населения.
Интенсивное освещение обычно сопровождает города. Общее правило звучит так: «больше людей — больше света». Это называют световым загрязнением — по аналогии с загрязнением других сред жизни человека и всех живых существ. И это тоже экологическая проблема.
Свет от искусственных источников рассеивается в нижних слоях атмосферы, что вызывает изменения в биоритмах ночных существ, сбивает птиц с их курса миграции и мешает нам увидеть ночное небо.
Что влияет на световой ландшафт
Картограф Descartes Lab Тим Уоллас решил уточнить, от чего конкретно зависит освещенность планеты. Для этого он нормализовал яркость точек на снимках на численность населения. Ниже прикреплены три карты, иллюстрирующие 1) ночную освещенность территории США, 2) распределение населения по территории США, 3) освещенность, нормализованную по населению.
На третьей карте световой ландшафт сильно отличается от того, что было на первой карте. Видно, что самые яркие точки находятся вовсе не в мегаполисах, а за их пределами.
Тим Уоллас и Джон Барентайн, член Международной Ассоциации Темного Неба (International Dark-Sky Association), выделяют три основных типа явлений, световой след от которых виден из космоса: добыча нефти и газа, склады и теплицы.
Добыча нефти и газа
Сейчас США являются лидерами по добыче сланцевой нефти. Нефтеносные регионы выделяются яркими пятнами, а на более детальных участках можно даже рассмотреть регулярную структуру площадок добычи.
Основными источниками света здесь являются факелы сжигаемого попутного природного газа (излишки газа, образующиеся при добыче нефти, перерабатывать которые экономически нецелесообразно) и освещение площадок добычи и жилых площадей работников.
В некоторых регионах добычи с 2010 по 2013 год рассеянное освещение от искусственных источников увеличилось на 500%. После 2014 года, когда цены на нефть на мировых рынках рухнули, активное развитие добычи сланцевой нефти прекратилось, но световое воздействие не уменьшилось.
Склады
Быстрая доставка любых товаров — кажется, одна из характеристик современных США. Amazon, FedEx, UPS, DHL и многие другие — каждая из этих компаний владеет огромными площадями складских помещений, без которых доставка затягивалась бы на гораздо большие сроки. Многие из них расположены за пределами крупных городов, где дешевле владеть большими участками земли. Все они ярко освещены по ночам, так как работа там редко останавливается.
Теплицы
Тим Уоллас особенно выделяет одну точку на карте штата Мэн: посреди довольно темного фона светится яркая точка — это внушительные 42 акра теплиц фирмы Backyard Farm, которая специализируется на выращивании помидоров.
Исследователи отмечают, что производители тепличной продукции любят менять спектр освещения, адаптируя условия для отдельных культур. Это стало возможным с развитием LED-освещения (светодиодов).
Возможно, вы видели снимки фиолетового неба, сделанные в январе этого года жителями города Сноуфлейк в штате Аризона — оказалось, что это отсветы освещения теплиц огромной плантации марихуаны неподалеку, усиленные погодными условиями — низкой облачностью и туманом.
Если же вам придется как-нибудь пролетать над Нидерландами ночью, обратите внимание на сияющие оранжевые пятна, разбросанные по территории страны — теплицы, в которых выращивают тюльпаны.
Нелли Бурцева
https://sysblok.ru/urban/kak-my-terjaem-prirodnye-resursy-temnoty/
{kind=link}
Проект OneSoil Map: как нейросеть помогает сельскому хозяйству
#visualisation
Про Никиту Хрущева шутили, что он запустил не только спутник, но и сельское хозяйство… Но с появлением искусственного интеллекта эти две сферы подружились: теперь спутниковые технологии работают на успех аграрного производства. Разбираемся, как искусственный интеллект и снимки из космоса помогают выбрать плодородное поле для посадки картошки.
Многие наверняка слышали о роли технологий в сельском хозяйстве. Это и альтернативные источники энергии, и генно-модифицированные организмы, и беспилотные машины для уборки урожая. С каждым десятилетием хозяйство вести все легче. У использования новых технологий в сельском хозяйстве есть название: точное (или «прецизионное», от англ. precision) земледелие.
Точное земледелие позволят эффективнее расходовать семена и удобрения, чтобы получать богатый урожай. Среди ресурсов, относящихся к точному земледелию, — проект OneSoil Map. Это карта всех полей Европы и США за три года, на которой видно, кто где что сажает и как и где развивается сельское хозяйство.
Карта — интерактивная, и работает на алгоритмах искусственного интеллекта и спутниковых снимках. Она располагает информацией о 60 миллионах полей и 27 культурах в 44 странах мира. Этот инструмент помогает фермерам, инвесторам и правительству в оптимизации отрасли сельского хозяйства.
Функционал OneSoil Map
При разработке сервиса OneSoil Map использовались снимки спутника Sentinel-2. Данные со спутника представляют собой около 250 терабайт информации о полях США и Европы. Спутниковые фотографии обработали следующим образом:
1. Сделали препроцессинг снимков: почистили облака, тени и снег. После этого этапа объем данных сократился до 50 терабайт.
2. Нашли границы полей, создали классификаторы для разных полей. Итог этого этапа — 250 гигабайт данных, содержащих векторные карты полей с сельскохозяйственными культурами.
3. Вычислили статистику, рейтинг и популярность разных культур в странах мира.
4. Для улучшения алгоритмов предоставили пользователям возможность уведомлять разработчиков о различных ошибках на картах.
При создании карт применялись два подхода. Во-первых, создали растровую карту: поделили карту на квадраты и выполнили последующий рендер в картинки. Браузер подгружает несколько картинок, а когда пользователь перемещается по карте — двигает их. Из плюсов — все поля отображаются без фильтрации, из минусов — растровые изображения довольно долго загружаются из-за большого объема файлов.
Во-вторых, создали векторную карту: анимировали векторные данные в браузере, как в картах Google и Yandeх. Из плюсов — можно использовать файлы меньшего объема, а также кастомизировать способ отображения данных.
Визуальная часть проекта также тщательно продумана. Для визуализации использовался сервис Mapbox. Для популярных культур выбрали контрастные цвета, для остальных — наименее контрастные. А чтобы привлечь к сервису внимание не только узких специалистов, разработали кнопку «рандомные красивые поля». Например, ниже прикреплена карта полей одного из регионов Франции.
В итоге разработчики стали первыми людьми, кто нанес на карту все поля США и Европы за три года, что не могло не привлечь внимание инвесторов, научных исследователей и фондов. Проект планируют развивать и дальше: цель на ближайшее будущее — автоматически распознавать поля и в остальных странах. Разработчики карты ведут блог, в котором пишут о мониторинге полей, экспериментах, больших данных и историях фермеров.
Колобов Денис
https://sysblok.ru/visual/kak-nejroset-sazhaet-kartoshku-iz-kosmosa/
#visualisation
Про Никиту Хрущева шутили, что он запустил не только спутник, но и сельское хозяйство… Но с появлением искусственного интеллекта эти две сферы подружились: теперь спутниковые технологии работают на успех аграрного производства. Разбираемся, как искусственный интеллект и снимки из космоса помогают выбрать плодородное поле для посадки картошки.
Многие наверняка слышали о роли технологий в сельском хозяйстве. Это и альтернативные источники энергии, и генно-модифицированные организмы, и беспилотные машины для уборки урожая. С каждым десятилетием хозяйство вести все легче. У использования новых технологий в сельском хозяйстве есть название: точное (или «прецизионное», от англ. precision) земледелие.
Точное земледелие позволят эффективнее расходовать семена и удобрения, чтобы получать богатый урожай. Среди ресурсов, относящихся к точному земледелию, — проект OneSoil Map. Это карта всех полей Европы и США за три года, на которой видно, кто где что сажает и как и где развивается сельское хозяйство.
Карта — интерактивная, и работает на алгоритмах искусственного интеллекта и спутниковых снимках. Она располагает информацией о 60 миллионах полей и 27 культурах в 44 странах мира. Этот инструмент помогает фермерам, инвесторам и правительству в оптимизации отрасли сельского хозяйства.
Функционал OneSoil Map
При разработке сервиса OneSoil Map использовались снимки спутника Sentinel-2. Данные со спутника представляют собой около 250 терабайт информации о полях США и Европы. Спутниковые фотографии обработали следующим образом:
1. Сделали препроцессинг снимков: почистили облака, тени и снег. После этого этапа объем данных сократился до 50 терабайт.
2. Нашли границы полей, создали классификаторы для разных полей. Итог этого этапа — 250 гигабайт данных, содержащих векторные карты полей с сельскохозяйственными культурами.
3. Вычислили статистику, рейтинг и популярность разных культур в странах мира.
4. Для улучшения алгоритмов предоставили пользователям возможность уведомлять разработчиков о различных ошибках на картах.
При создании карт применялись два подхода. Во-первых, создали растровую карту: поделили карту на квадраты и выполнили последующий рендер в картинки. Браузер подгружает несколько картинок, а когда пользователь перемещается по карте — двигает их. Из плюсов — все поля отображаются без фильтрации, из минусов — растровые изображения довольно долго загружаются из-за большого объема файлов.
Во-вторых, создали векторную карту: анимировали векторные данные в браузере, как в картах Google и Yandeх. Из плюсов — можно использовать файлы меньшего объема, а также кастомизировать способ отображения данных.
Визуальная часть проекта также тщательно продумана. Для визуализации использовался сервис Mapbox. Для популярных культур выбрали контрастные цвета, для остальных — наименее контрастные. А чтобы привлечь к сервису внимание не только узких специалистов, разработали кнопку «рандомные красивые поля». Например, ниже прикреплена карта полей одного из регионов Франции.
В итоге разработчики стали первыми людьми, кто нанес на карту все поля США и Европы за три года, что не могло не привлечь внимание инвесторов, научных исследователей и фондов. Проект планируют развивать и дальше: цель на ближайшее будущее — автоматически распознавать поля и в остальных странах. Разработчики карты ведут блог, в котором пишут о мониторинге полей, экспериментах, больших данных и историях фермеров.
Колобов Денис
https://sysblok.ru/visual/kak-nejroset-sazhaet-kartoshku-iz-kosmosa/
{kind=link}
Как вычислить эмоции компьютерными методами
Рассказываем на примере анализа песен группы Битлз.
#philology
В 1996 году психолог Синтия Уиссел опубликовала статью, в которой сравнила между собой песни Пола МакКартни и Джона Леннона при помощи методов традиционной и эмоциональной стилометрии. В статье Уиссел пытается ответить на два вопроса:
1. Действительно ли песни Джона грустнее песен Пола?
2. Как менялась эмоциональная составляющая песен Битлз на протяжении четырех стадий их творчества (1962–1964, 1965–1966, 1967–1968, 1969–1970)?
Методы стилометрического анализа
Стилометрия часто использует измерения слова в качестве минимальной единицы. Из слова можно получить множество качеств для изучения текста: длину, частотность и др. Нас интересует коннотация. Коннотации каждого слова вычисляются разными способами опрашивания информантов. Затем результаты документируются в словарях эмоций (Dictionary of Affect). Один из таких словарей Уиссел сама и составила.
Измеряют коннотацию по трем шкалам: оценка, сила и активность. Вместе эти факторы описывают эмоцию человека по отношению к тому, что это слово обозначает, и их достаточно для дифференцирования значений большинства слов. У каждой шкалы две крайности: у оценки это «плохой» и «хороший», у силы — «сильный» и «слабый», а у активности — «активный» и «неактивный».
Для стилометрического исследования не обязательно рассматривать все три шкалы. В статье Уиссел рассматривает только оценку и активность, используя значения из своего словаря. Каждому слову в словаре даны значения на двух семибалльных шкалах: оценки и активности. К примеру, слово delighted ‘восхищенный’ имеет значения 6.4 (оценка) и 4.2 (активность), а gloomy ‘угрюмый’ — 3.2 (оценка) и 2.4 (активность).
Анализ текстов песен группы Битлз
Уиссел посчитала, какой процент наиболее «приятных» и наиболее «активных» слов (в топ 25% по оценке и активности соответственно) присутствует в их песнях на протяжении четырех периодов их творчества. Кроме того, она сконструировала из этих двух шкал еще четыре и тоже их подсчитала:
1. «Радостность» (Cheerfulness) — наиболее приятные и наиболее активные
2. «Гадкость» (Nastiness) — наименее приятные и наиболее активные
3. «Мягкость» (Softness) — наиболее приятные и наименее активные
4. «Грустность» (Sadness) — наименее приятные и наименее активные
Оказалось, что МакКартни использовал на 2% больше «приятных» слов, чем Леннон, который использовал больше «гадких», «мягких» и «грустных» слов.
Часы эмоций
Для наглядной демонстрации результатов своих исследований Уиссел использовала т.н. часы эмоций. Схема прикреплена ниже.
Это пространство с двумя осями — оценки и активности. Значения, которые проставляются в этой системе координат, не абсолютные: они нормализованы относительно корпуса из около 50 текстов, включающих в себя художественную литературу, эссе студентов, описания людьми собственных эмоций.
Чем интенсивнее эмоции в тексте, тем вектор (т. е. расстояние от центра до точки, обозначающей текст) будет длиннее, а в зависимости от угла, который образует этот вектор, меняется и общее настроение текста. Для этого и нужна окружность, на которой обозначены различные эмоции.
В среднем все песни Битлз оказываются более «радостными», чем подобранный корпус. А по отдельности песни по-разному располагаются на часах: самой «депрессивной» оказывается песня Джона Леннона «Nowhere Man», самой «приятной» — песня Пола Маккартни «I’ll Follow the Sun».
Сложно понять, насколько эти данные достоверны. Однако интересно, что субъективное мнение критиков, что песни Джона более грустные, как будто подтверждается методами эмоциональной стилометрии. Если два разных подхода к анализу текстов приходят к одному выводу, оба подхода становятся легитимнее, и поэтому, возможно, у эмоциональной стилометрии есть право на существование.
Миша Сонькин
https://sysblok.ru/philology/kak-menjalis-pesni-bitlov-i-mozhno-li-vychislit-jemocii-kompjuternymi-metodami/
Рассказываем на примере анализа песен группы Битлз.
#philology
В 1996 году психолог Синтия Уиссел опубликовала статью, в которой сравнила между собой песни Пола МакКартни и Джона Леннона при помощи методов традиционной и эмоциональной стилометрии. В статье Уиссел пытается ответить на два вопроса:
1. Действительно ли песни Джона грустнее песен Пола?
2. Как менялась эмоциональная составляющая песен Битлз на протяжении четырех стадий их творчества (1962–1964, 1965–1966, 1967–1968, 1969–1970)?
Методы стилометрического анализа
Стилометрия часто использует измерения слова в качестве минимальной единицы. Из слова можно получить множество качеств для изучения текста: длину, частотность и др. Нас интересует коннотация. Коннотации каждого слова вычисляются разными способами опрашивания информантов. Затем результаты документируются в словарях эмоций (Dictionary of Affect). Один из таких словарей Уиссел сама и составила.
Измеряют коннотацию по трем шкалам: оценка, сила и активность. Вместе эти факторы описывают эмоцию человека по отношению к тому, что это слово обозначает, и их достаточно для дифференцирования значений большинства слов. У каждой шкалы две крайности: у оценки это «плохой» и «хороший», у силы — «сильный» и «слабый», а у активности — «активный» и «неактивный».
Для стилометрического исследования не обязательно рассматривать все три шкалы. В статье Уиссел рассматривает только оценку и активность, используя значения из своего словаря. Каждому слову в словаре даны значения на двух семибалльных шкалах: оценки и активности. К примеру, слово delighted ‘восхищенный’ имеет значения 6.4 (оценка) и 4.2 (активность), а gloomy ‘угрюмый’ — 3.2 (оценка) и 2.4 (активность).
Анализ текстов песен группы Битлз
Уиссел посчитала, какой процент наиболее «приятных» и наиболее «активных» слов (в топ 25% по оценке и активности соответственно) присутствует в их песнях на протяжении четырех периодов их творчества. Кроме того, она сконструировала из этих двух шкал еще четыре и тоже их подсчитала:
1. «Радостность» (Cheerfulness) — наиболее приятные и наиболее активные
2. «Гадкость» (Nastiness) — наименее приятные и наиболее активные
3. «Мягкость» (Softness) — наиболее приятные и наименее активные
4. «Грустность» (Sadness) — наименее приятные и наименее активные
Оказалось, что МакКартни использовал на 2% больше «приятных» слов, чем Леннон, который использовал больше «гадких», «мягких» и «грустных» слов.
Часы эмоций
Для наглядной демонстрации результатов своих исследований Уиссел использовала т.н. часы эмоций. Схема прикреплена ниже.
Это пространство с двумя осями — оценки и активности. Значения, которые проставляются в этой системе координат, не абсолютные: они нормализованы относительно корпуса из около 50 текстов, включающих в себя художественную литературу, эссе студентов, описания людьми собственных эмоций.
Чем интенсивнее эмоции в тексте, тем вектор (т. е. расстояние от центра до точки, обозначающей текст) будет длиннее, а в зависимости от угла, который образует этот вектор, меняется и общее настроение текста. Для этого и нужна окружность, на которой обозначены различные эмоции.
В среднем все песни Битлз оказываются более «радостными», чем подобранный корпус. А по отдельности песни по-разному располагаются на часах: самой «депрессивной» оказывается песня Джона Леннона «Nowhere Man», самой «приятной» — песня Пола Маккартни «I’ll Follow the Sun».
Сложно понять, насколько эти данные достоверны. Однако интересно, что субъективное мнение критиков, что песни Джона более грустные, как будто подтверждается методами эмоциональной стилометрии. Если два разных подхода к анализу текстов приходят к одному выводу, оба подхода становятся легитимнее, и поэтому, возможно, у эмоциональной стилометрии есть право на существование.
Миша Сонькин
https://sysblok.ru/philology/kak-menjalis-pesni-bitlov-i-mozhno-li-vychislit-jemocii-kompjuternymi-metodami/
{kind=link}
Как вам может помочь музыкальный поисковик Musipedia
#musicology
Тун, тун, ту-тун, тун-тутун, тун-тутууун… Угадали?
Musipedia — Википедия от мира музыки — способна определить мелодию, навязчивый мотив которой не отпускает вас уже несколько дней. Это постоянно обновляемая коллекция музыки со всего мира. В библиотеке проекта более 30 тысяч треков: от сонат Бетховена до Rolling Stones.
«Musipedia» была создана в 2002 году Райнэром Типке, выпускником старейшего в Германии Технологического института Карлсруэ. Сами авторы отмечают, что «Musipedia» была вдохновлена Википедией, однако не является ее частью.
Поисковик позволяет найти и идентифицировать музыку, даже если вы знаете только её приблизительное звучание. Ввести мелодию в поисковик можно разными способами:
1. Наиграть на подключенной MIDI-клавиатуре.
Она похожа на синтезатор, но для извлечения звука в большинстве случаев ей требуется подключение к компьютеру, так как у нее нет встроенных колонок. Обычно она используется преимущественно для звукозаписи.
2. Ввести с клавиатуры компьютера.
Можно отбить только ритм песни на клавише «space», а можно — наиграть мелодию на клавишах (каждая клавиша будет отвечать за определенную ноту).
3. Ввести при помощи компьютерной мыши и виртуальных клавиш.
Ниже прикреплен скрин электронной клавиатуры сайта.
4. Насвистеть или напеть в микрофон.
5. Использовать код Парсонса.
Это код для мелодических контуров, в которых происходит так называемое «melodic motion» — движение мелодии вверх или вниз относительно тона предыдущей ноты. Если нота выше предыдущей, она отмечается латинской U (Up), ниже — D (Down), повторяет звучание — R (Repeat). Первая нота отмечается звездочкой ().
На основе такой записи знаменитая колыбельная «Twinkle Twinkle Little Star» будет звучать следующим образом: RURURDDRDRDRDURDRDRDURDRDRDDRURURDDRDRDRD. В русском языке на ту же мелодию играется детская песенка «Как под горкой — под горой».
Когда пользователь набрал мелодию, алгоритм начинает подбор наиболее похожих на нее песен из коллекции «Musipedia». Эту коллекцию можно и пополнить, загрузив трек на сайт. Далее алгоритм программы самостоятельно переведет ноты на понятный ему язык и добавит предложенную мелодию в общую коллекцию. Сайт использует язык нотной записи LilyPond, где каждой ноте соответствует своя буква. Таким образом, привычный нотный стан больше напоминает текстовый документ (‘до’= ‘c’, ‘ре’ = ‘d’ и т. д.).
Мария Черных
https://sysblok.ru/musicology/muzykalnyj-poiskovik-musipedia-ot-mocarta-do-jeltona-dzhona/
#musicology
Тун, тун, ту-тун, тун-тутун, тун-тутууун… Угадали?
Musipedia — Википедия от мира музыки — способна определить мелодию, навязчивый мотив которой не отпускает вас уже несколько дней. Это постоянно обновляемая коллекция музыки со всего мира. В библиотеке проекта более 30 тысяч треков: от сонат Бетховена до Rolling Stones.
«Musipedia» была создана в 2002 году Райнэром Типке, выпускником старейшего в Германии Технологического института Карлсруэ. Сами авторы отмечают, что «Musipedia» была вдохновлена Википедией, однако не является ее частью.
Поисковик позволяет найти и идентифицировать музыку, даже если вы знаете только её приблизительное звучание. Ввести мелодию в поисковик можно разными способами:
1. Наиграть на подключенной MIDI-клавиатуре.
Она похожа на синтезатор, но для извлечения звука в большинстве случаев ей требуется подключение к компьютеру, так как у нее нет встроенных колонок. Обычно она используется преимущественно для звукозаписи.
2. Ввести с клавиатуры компьютера.
Можно отбить только ритм песни на клавише «space», а можно — наиграть мелодию на клавишах (каждая клавиша будет отвечать за определенную ноту).
3. Ввести при помощи компьютерной мыши и виртуальных клавиш.
Ниже прикреплен скрин электронной клавиатуры сайта.
4. Насвистеть или напеть в микрофон.
5. Использовать код Парсонса.
Это код для мелодических контуров, в которых происходит так называемое «melodic motion» — движение мелодии вверх или вниз относительно тона предыдущей ноты. Если нота выше предыдущей, она отмечается латинской U (Up), ниже — D (Down), повторяет звучание — R (Repeat). Первая нота отмечается звездочкой ().
На основе такой записи знаменитая колыбельная «Twinkle Twinkle Little Star» будет звучать следующим образом: RURURDDRDRDRDURDRDRDURDRDRDDRURURDDRDRDRD. В русском языке на ту же мелодию играется детская песенка «Как под горкой — под горой».
Когда пользователь набрал мелодию, алгоритм начинает подбор наиболее похожих на нее песен из коллекции «Musipedia». Эту коллекцию можно и пополнить, загрузив трек на сайт. Далее алгоритм программы самостоятельно переведет ноты на понятный ему язык и добавит предложенную мелодию в общую коллекцию. Сайт использует язык нотной записи LilyPond, где каждой ноте соответствует своя буква. Таким образом, привычный нотный стан больше напоминает текстовый документ (‘до’= ‘c’, ‘ре’ = ‘d’ и т. д.).
Мария Черных
https://sysblok.ru/musicology/muzykalnyj-poiskovik-musipedia-ot-mocarta-do-jeltona-dzhona/
{kind=link}