
Что не так с машинным переводом?
С наступлением эры нейросетей СМИ любят писать, что машинный перевод вот-вот сравнится по качеству с продуктом профессионального переводчика. «Искусственный интеллект в машинном переводе догоняет человека», уверяют заголовки уважаемых технологических медиа. Но так ли это?
Искусственные нейронные сети, обученные на больших данных, действительно повысили качество машинного перевода настолько, что это видно невооруженным взглядом.
Как работает машинный перевод и какие у него недостатки?
С начала 2000-х и до 2015-2016 гг. в переводчиках вроде Google Translate использовался статистический машинный перевод по фразам (phrase-based). Он рубил текст на слова и цепочки слов, после чего использовал статистику переводов фраз с языка на язык. С приходом нейросетей машинные переводчики перешли на них. Нейросети не нужно заранее выделять в тексте фиксированные фразы: алгоритмы сами постепенно выучивают на больших объемах данных оптимальные решения. Благодаря этому качество работы машинных переводчиков так подскочило.
Однако действительно ли нейронный машинный перевод (НМП) приближается к человеческому? Ответ: нет! Пока что системы машинного перевода не сопоставимы с мозгом переводчика-человека. Они допускают ошибки, которых человек никогда бы не допустил — и которые свидетельствуют о том, что разговоры об «искусственном интеллекте» преждевременны.
Недостатки нейронных переводчиков можно поделить на 3 категории: достоверность, память и здравый смысл.
1. Достоверность
Системы НМП не вооружены методами определения достоверности фактов в тексте перевода.
Например, важнейшую строчку в знаменитом стихотворении Пушкина Я вас любил: любовь ещё, быть может нейросеть смогла развернуть на 180 градусов: дай бог превращается в god forbid, т.е. не дай бог.
Как дай вам бог любимой быть другим > How god forbid you be loved to be different
Используя данные реального мира, система НМТ вводит необоснованную информацию, и искажает не только данные, но и свои переводы. Так, переведенный с малайского текст, не содержащий никакой гендерной информации, в переводе на английский обозначает женскую и мужскую роль:
Dia bekerja sebagai jururawant > She works as a nurse
Dia bekerja sebagai pengaturcara > He works as a programmer
2. Память
Системы НМП имеют еще один заметный дефект: они сильно заточены на перевод отдельных предложений.
Нейросети в современных переводчиках плохо помнят, что было до того предложения, которое они переводят. Например, если бы в предыдущем примере система НМП имела доступ к другим предложениям этого текста, и в них упоминалось бы, что программист — женщина, система все равно не смогла бы использовать правильные местоимения.
3. Здравый смысл
Системы НМП не обладают здравым смыслом: знаниями или контекстом о мире, которые помогли бы помочь правильно перевести текст.
Предположим, вы читаете статью о музыкальном концерте и отправляете французский перевод (выполненный системой НМП) своим франкоязычным друзьям. В английской версии в статье есть интервью различных концертмейстеров, в том числе одного молодого человека, который восклицает: «Я большой поклонник металла!»
Однако в переводе, это предложение становится таким:
«Je suis un énorme ventilateur en métal» («Я огромный вентилятор из металла»)
Для эффективного перевода системе НМП необходимы общие знания о мире. Однако эти знания трудно кодировать в полном объеме и нелегко извлечь из объемов данных.
Мы работаем над этим… Как выглядит будущее?
Определение качества перевода — непростая задача. Сейчас наиболее распространенным способом является использование оценки BLEU, но она не может решить все озвученные проблемы. Google призвал исследователей к борьбе с искажениями фактов в НМП, выпустив новый набор метрик оценки специально для решения этой проблемы.
Можно ожидать и ускорения распространения новых исследований. Гарвардский OpenNMT — реализация нейронного машинного перевода с открытым исходным кодом в LuaTorch, PyTorch и Tensorflow — теперь другие легко могут брать за основу лучшие системы.
С наступлением эры нейросетей СМИ любят писать, что машинный перевод вот-вот сравнится по качеству с продуктом профессионального переводчика. «Искусственный интеллект в машинном переводе догоняет человека», уверяют заголовки уважаемых технологических медиа. Но так ли это?
Искусственные нейронные сети, обученные на больших данных, действительно повысили качество машинного перевода настолько, что это видно невооруженным взглядом.
Как работает машинный перевод и какие у него недостатки?
С начала 2000-х и до 2015-2016 гг. в переводчиках вроде Google Translate использовался статистический машинный перевод по фразам (phrase-based). Он рубил текст на слова и цепочки слов, после чего использовал статистику переводов фраз с языка на язык. С приходом нейросетей машинные переводчики перешли на них. Нейросети не нужно заранее выделять в тексте фиксированные фразы: алгоритмы сами постепенно выучивают на больших объемах данных оптимальные решения. Благодаря этому качество работы машинных переводчиков так подскочило.
Однако действительно ли нейронный машинный перевод (НМП) приближается к человеческому? Ответ: нет! Пока что системы машинного перевода не сопоставимы с мозгом переводчика-человека. Они допускают ошибки, которых человек никогда бы не допустил — и которые свидетельствуют о том, что разговоры об «искусственном интеллекте» преждевременны.
Недостатки нейронных переводчиков можно поделить на 3 категории: достоверность, память и здравый смысл.
1. Достоверность
Системы НМП не вооружены методами определения достоверности фактов в тексте перевода.
Например, важнейшую строчку в знаменитом стихотворении Пушкина Я вас любил: любовь ещё, быть может нейросеть смогла развернуть на 180 градусов: дай бог превращается в god forbid, т.е. не дай бог.
Как дай вам бог любимой быть другим > How god forbid you be loved to be different
Используя данные реального мира, система НМТ вводит необоснованную информацию, и искажает не только данные, но и свои переводы. Так, переведенный с малайского текст, не содержащий никакой гендерной информации, в переводе на английский обозначает женскую и мужскую роль:
Dia bekerja sebagai jururawant > She works as a nurse
Dia bekerja sebagai pengaturcara > He works as a programmer
2. Память
Системы НМП имеют еще один заметный дефект: они сильно заточены на перевод отдельных предложений.
Нейросети в современных переводчиках плохо помнят, что было до того предложения, которое они переводят. Например, если бы в предыдущем примере система НМП имела доступ к другим предложениям этого текста, и в них упоминалось бы, что программист — женщина, система все равно не смогла бы использовать правильные местоимения.
3. Здравый смысл
Системы НМП не обладают здравым смыслом: знаниями или контекстом о мире, которые помогли бы помочь правильно перевести текст.
Предположим, вы читаете статью о музыкальном концерте и отправляете французский перевод (выполненный системой НМП) своим франкоязычным друзьям. В английской версии в статье есть интервью различных концертмейстеров, в том числе одного молодого человека, который восклицает: «Я большой поклонник металла!»
Однако в переводе, это предложение становится таким:
«Je suis un énorme ventilateur en métal» («Я огромный вентилятор из металла»)
Для эффективного перевода системе НМП необходимы общие знания о мире. Однако эти знания трудно кодировать в полном объеме и нелегко извлечь из объемов данных.
Мы работаем над этим… Как выглядит будущее?
Определение качества перевода — непростая задача. Сейчас наиболее распространенным способом является использование оценки BLEU, но она не может решить все озвученные проблемы. Google призвал исследователей к борьбе с искажениями фактов в НМП, выпустив новый набор метрик оценки специально для решения этой проблемы.
Можно ожидать и ускорения распространения новых исследований. Гарвардский OpenNMT — реализация нейронного машинного перевода с открытым исходным кодом в LuaTorch, PyTorch и Tensorflow — теперь другие легко могут брать за основу лучшие системы.
{kind=link}
Новый мобильный Google Translate
В прошлом году Google внес изменения в функцию камеры в своем мобильном приложении Translate. Новая версия приложения поддерживает 60 новых языков и лучше фиксирует переведенный текст на изображении; кроме того, компания обновила основные модели перевода, в некоторых случаях сократив частотность ошибок на 85 %.
Все это на радость постоянным пользователям приложения Google Translate, которым функция камеры нужна, чтобы переводить, например, меню или дорожные знаки. Ранее неоднократно звучали жалобы на некачественный перевод, нестабильную работу приложения и ограниченное число языков.Теперь поводов для недовольства должно стать меньше.
Как это работает?
Google наконец-то добавил в приложение свою систему нейронного машинного перевода (ранее она была доступна только в веб-версии Google Translate). Благодаря возможностям Google Lens приложение распознает текст и переводит его на целевой язык в режиме реального времени.
Сервис Google Lens был создан для мгновенного распознавания и обработки информации с изображений. Интеграция с ним позволяет Google Translate переводить как ранее сделанные фотографии, так и текст на незнакомом языке, который еще не сфотографирован, — достаточно просто навести на него камеру. Перевод можно прослушать, причем система маркером выделит для пользователя слово, которое читает прямо сейчас.
Куда теперь можно поехать, не зная языка?
Новая версия теперь поддерживает африкаанс, арабский, бенгальский, эстонский, греческий, хинди, игбо, яванский, курдский, латинский, латышский, малайский, монгольский, непальский, пушту, персидский, самоанский, сесото, словенский, суахили, тайский, вьетнамский, валлийский, коса, йоруба и зулу — всего поддерживаемых языков более 80. Google Translate также автоматически определит язык текста, что весьма полезно для путешествий в регионах, где распространено несколько языков. Путешествуем смело!
Источник: Google’s live camera translation is getting better AI and 60 new languages
В прошлом году Google внес изменения в функцию камеры в своем мобильном приложении Translate. Новая версия приложения поддерживает 60 новых языков и лучше фиксирует переведенный текст на изображении; кроме того, компания обновила основные модели перевода, в некоторых случаях сократив частотность ошибок на 85 %.
Все это на радость постоянным пользователям приложения Google Translate, которым функция камеры нужна, чтобы переводить, например, меню или дорожные знаки. Ранее неоднократно звучали жалобы на некачественный перевод, нестабильную работу приложения и ограниченное число языков.Теперь поводов для недовольства должно стать меньше.
Как это работает?
Google наконец-то добавил в приложение свою систему нейронного машинного перевода (ранее она была доступна только в веб-версии Google Translate). Благодаря возможностям Google Lens приложение распознает текст и переводит его на целевой язык в режиме реального времени.
Сервис Google Lens был создан для мгновенного распознавания и обработки информации с изображений. Интеграция с ним позволяет Google Translate переводить как ранее сделанные фотографии, так и текст на незнакомом языке, который еще не сфотографирован, — достаточно просто навести на него камеру. Перевод можно прослушать, причем система маркером выделит для пользователя слово, которое читает прямо сейчас.
Куда теперь можно поехать, не зная языка?
Новая версия теперь поддерживает африкаанс, арабский, бенгальский, эстонский, греческий, хинди, игбо, яванский, курдский, латинский, латышский, малайский, монгольский, непальский, пушту, персидский, самоанский, сесото, словенский, суахили, тайский, вьетнамский, валлийский, коса, йоруба и зулу — всего поддерживаемых языков более 80. Google Translate также автоматически определит язык текста, что весьма полезно для путешествий в регионах, где распространено несколько языков. Путешествуем смело!
Источник: Google’s live camera translation is getting better AI and 60 new languages
{kind=link}
«Best of Блокъ»: лучшие посты 2019 года
Весь 2019 год «Системный Блокъ» рассказывал, как высокие технологии становятся частью современной науки, культуры и повседневности, принося хорошее и плохое.
За год в «СБъ» вышло больше 220 материалов. Предлагаем вам подборку из 12 постов, которые стоит перечитать:
Новый, мертвый, хороший: визуализация текстов Гражданской Обороны
Пост-трибьют иконе русского панк-рока, написанный к 11-летию со дня смерти. Мы исследовали корпус текстов Летова цифровыми методами и визуализировали результаты.
Word2Vec: покажи мне свой контекст, и я скажу, кто ты
Рассказываем, как работает одна из самых актуальных технологий в основе современной компьютерной лингвистики и искусственного интеллекта — дистрибутивная семантика.
Зачем нужны гуманитарии в эпоху машинного обучения?
Наш перевод эссе Теда Андервуда о том, почему «непрактичные» и «невостребованные» навыки гуманитариев могут оказаться тем самым, что спасет всех нас в эпоху всепроникающих технологий и торжества ИИ.
Данные нас связали: где и как применяют статью 20.2 КоАП РФ
Изучаем статистику применения административной статьи 20.2 — той самой, которую в 2019 году массово использовали против задержанных на митингах и шествиях. Данные собрали и опубликовали «ОВД-Инфо», а мы исследовали их и нашли в два нестандартные случаи применения статьи 20.2.
Как работают фильтры в Инстаграме + Как посмотреть на мир глазами нейросетей
Технологический лонгрид в двух частях о том, как работает современное компьютерное зрение, что делает Instagram с вашими фотографиями и как нейросеть отличает дорогой дом на снимке — от дешевого.
Прокачиваем гуманитария до программиста: инструкция
Я — филолог (лингвист, историк, философ, культуролог, etc) и хочу заняться программированием. В чем мои сильные стороны? Что делать? Рассказывает гуманитарий, перековавшийся в программиста.
Пусти пожить болельщика: чемпионат в Москве и рынок Airbnb
Исследуем статистику Airbnb по Москве, чтобы понять, как Чемпионат мира по футболу 2018 года повлиял на рынок съемного жилья. Какие районы наводнили туристы, как они селились вокруг стадионов, а кто переоценил свою привлекательность для болельщиков?
Учат в школе… Чему?
Чему учат в современной началке? Мы проанализировали более 20 тыс. заданий в учебниках по русскому языку 1-4 классов и постарались разобраться, из чего они состоят — и чего требуют от школьника. Специальный пост к 1 сентября.
Что случилось с самыми унылыми стихотворениями XIX века
Элегия — ключевой поэтический жанр «золотого века» русской поэзии. Что можно узнать о нем, используя количественные методы: подсчет частотности слов, тематическое моделирование, статистику длины стихотворений?
Я/МЫ НКРЯ: что происходит с национальным корпусом
Этот текст стал частью борьбы за сохранение Национального корпуса русского языка, который переживал в 2019 году нелегкие времена. Осенью лингвисты обнаружили по знакомому адресу сильно урезанный и криво работающий корпус. Давно тлевшие слухи о полном отказе «Яндекса» от поддержки НКРЯ и его «закрытии» стали разлетаться по сети со скоростью фейсбучного репоста. Поисковику пришлось реагировать: старую версию НКРЯ вернули, а ученых заверили, что «Яндекс» корпус не бросит, т.к. его завещал беречь сам Илья Сегалович.
Жутко громко, запредельно тихо: звуки в романах
Цифровые методы анализируют голоса героев романа и их громкость. Одно исследование — в рамках отдельной книги («Идиот» Достоевского). Другое — на матреиале тысячи британских романов.
Зрение, мозг и нейросети
Если с помощью томографии зафиксировать активность мозга, когда человек смотрит на разные картинки, а потом скормить это вместе с картинками нейросети… она научится считывать то, что видит человек, прямо из мозга. Звучит как фантастика, но это уже здесь.
Весь 2019 год «Системный Блокъ» рассказывал, как высокие технологии становятся частью современной науки, культуры и повседневности, принося хорошее и плохое.
За год в «СБъ» вышло больше 220 материалов. Предлагаем вам подборку из 12 постов, которые стоит перечитать:
Новый, мертвый, хороший: визуализация текстов Гражданской Обороны
Пост-трибьют иконе русского панк-рока, написанный к 11-летию со дня смерти. Мы исследовали корпус текстов Летова цифровыми методами и визуализировали результаты.
Word2Vec: покажи мне свой контекст, и я скажу, кто ты
Рассказываем, как работает одна из самых актуальных технологий в основе современной компьютерной лингвистики и искусственного интеллекта — дистрибутивная семантика.
Зачем нужны гуманитарии в эпоху машинного обучения?
Наш перевод эссе Теда Андервуда о том, почему «непрактичные» и «невостребованные» навыки гуманитариев могут оказаться тем самым, что спасет всех нас в эпоху всепроникающих технологий и торжества ИИ.
Данные нас связали: где и как применяют статью 20.2 КоАП РФ
Изучаем статистику применения административной статьи 20.2 — той самой, которую в 2019 году массово использовали против задержанных на митингах и шествиях. Данные собрали и опубликовали «ОВД-Инфо», а мы исследовали их и нашли в два нестандартные случаи применения статьи 20.2.
Как работают фильтры в Инстаграме + Как посмотреть на мир глазами нейросетей
Технологический лонгрид в двух частях о том, как работает современное компьютерное зрение, что делает Instagram с вашими фотографиями и как нейросеть отличает дорогой дом на снимке — от дешевого.
Прокачиваем гуманитария до программиста: инструкция
Я — филолог (лингвист, историк, философ, культуролог, etc) и хочу заняться программированием. В чем мои сильные стороны? Что делать? Рассказывает гуманитарий, перековавшийся в программиста.
Пусти пожить болельщика: чемпионат в Москве и рынок Airbnb
Исследуем статистику Airbnb по Москве, чтобы понять, как Чемпионат мира по футболу 2018 года повлиял на рынок съемного жилья. Какие районы наводнили туристы, как они селились вокруг стадионов, а кто переоценил свою привлекательность для болельщиков?
Учат в школе… Чему?
Чему учат в современной началке? Мы проанализировали более 20 тыс. заданий в учебниках по русскому языку 1-4 классов и постарались разобраться, из чего они состоят — и чего требуют от школьника. Специальный пост к 1 сентября.
Что случилось с самыми унылыми стихотворениями XIX века
Элегия — ключевой поэтический жанр «золотого века» русской поэзии. Что можно узнать о нем, используя количественные методы: подсчет частотности слов, тематическое моделирование, статистику длины стихотворений?
Я/МЫ НКРЯ: что происходит с национальным корпусом
Этот текст стал частью борьбы за сохранение Национального корпуса русского языка, который переживал в 2019 году нелегкие времена. Осенью лингвисты обнаружили по знакомому адресу сильно урезанный и криво работающий корпус. Давно тлевшие слухи о полном отказе «Яндекса» от поддержки НКРЯ и его «закрытии» стали разлетаться по сети со скоростью фейсбучного репоста. Поисковику пришлось реагировать: старую версию НКРЯ вернули, а ученых заверили, что «Яндекс» корпус не бросит, т.к. его завещал беречь сам Илья Сегалович.
Жутко громко, запредельно тихо: звуки в романах
Цифровые методы анализируют голоса героев романа и их громкость. Одно исследование — в рамках отдельной книги («Идиот» Достоевского). Другое — на матреиале тысячи британских романов.
Зрение, мозг и нейросети
Если с помощью томографии зафиксировать активность мозга, когда человек смотрит на разные картинки, а потом скормить это вместе с картинками нейросети… она научится считывать то, что видит человек, прямо из мозга. Звучит как фантастика, но это уже здесь.
{kind=link}
Код «Мастера и Маргариты»
С помощью методов цифрового литературоведения можно увидеть скрытые закономерности в художественном произведении. Мы проанализировали роман М. А. Булгакова «Мастер и Маргарита», используя методы сетевого анализа и анализа тональности текста (сентимент-анализа).
Социальная сеть персонажей
При построении социальной сети персонажей видно, что все они распределены по сюжетным линиям романа. Выделяются три персонажа-посредника: Иешуа, Левий Матвей и Пилат, которые соединяют две сюжетные линии. Главный из этой тройки — Пилат. Именно он выступает одним из главных действующих лиц в Ершалаиме, и именно о нем говорят и главные герои во время событий в Москве. Без него система персонажей романа развалится на две обособленные и самодостаточные части.
Распределение персонажей в романе
Построим диаграмму рассеяния, своего рода «рентген» текста романа, на которой видно распределение персонажей по сюжету. Чтобы построить эту диаграмму, представим текст романа как список слов, идущих друг за другом в том же порядке, в каком их расположил автор. Далее представим текст романа как вектор, равный по длине числу слов в романе. Если в конкретном месте романа есть упоминание соответствующего персонажа, то там ставится значение 1, а если нет, то 0.
На диаграмме видно, как чередуются между собой основные сюжетные линии персонажей, как московские главы сменяются библейскими и наоборот. Заметно, как внимание автора перешло от линии Иван — Воланд к линии Воланд — Маргарита.
Анализ сюжета
Сюжет романа можно исследовать с помощью анализа тональности текста (сентимент-анализа). Этот метод поможет увидеть динамику сюжета и смену настроений. Сентимент-анализ опирается на выделение восьми «основных» эмоций человека — это гнев, ожидание, радость, принятие, страх, удивление, грусть и отвращение. Каждую из этих эмоций можно назвать разными словами, имеющими положительную или отрицательную окраску.
Таким образом, проанализировав, какие и как эмоционально окрашенные слова представлены в тексте, можно предположить эмоциональное состояние читателя этого текста.
В первой главе «Мастера и Маргариты» — умеренно положительный настрой. Затем автор рассказывает о допросе и пытках Иешуа, смерти Берлиоза и погоне Ивана за Воландом и его свитой, что приводит к резкому падению настроения. Небольшой просвет есть в момент, когда Иван приходит к Грибоедову, но затем снова начинает преобладать негатив вплоть до успокаивающего разговора с профессором.
Далее, в 10-й и 11-й главе, сюжет идет ровно, рассказывая о серии проделок нечистой силы в Москве, о расколе Ивана. Но потом, когда в 13-й главе романа появляется главный персонаж, Мастер, настроение снова идет вверх.
Хотя роман и имеет положительную динамику в конце, он все же не выбирается в плюс: слов с отрицательной эмоциональной окраской оказалось больше, и сцена с допросом в начале очень сильно влияет на всю тональность романа.
https://sysblok.ru/philology/kod-mastera-i-margarity/
С помощью методов цифрового литературоведения можно увидеть скрытые закономерности в художественном произведении. Мы проанализировали роман М. А. Булгакова «Мастер и Маргарита», используя методы сетевого анализа и анализа тональности текста (сентимент-анализа).
Социальная сеть персонажей
При построении социальной сети персонажей видно, что все они распределены по сюжетным линиям романа. Выделяются три персонажа-посредника: Иешуа, Левий Матвей и Пилат, которые соединяют две сюжетные линии. Главный из этой тройки — Пилат. Именно он выступает одним из главных действующих лиц в Ершалаиме, и именно о нем говорят и главные герои во время событий в Москве. Без него система персонажей романа развалится на две обособленные и самодостаточные части.
Распределение персонажей в романе
Построим диаграмму рассеяния, своего рода «рентген» текста романа, на которой видно распределение персонажей по сюжету. Чтобы построить эту диаграмму, представим текст романа как список слов, идущих друг за другом в том же порядке, в каком их расположил автор. Далее представим текст романа как вектор, равный по длине числу слов в романе. Если в конкретном месте романа есть упоминание соответствующего персонажа, то там ставится значение 1, а если нет, то 0.
На диаграмме видно, как чередуются между собой основные сюжетные линии персонажей, как московские главы сменяются библейскими и наоборот. Заметно, как внимание автора перешло от линии Иван — Воланд к линии Воланд — Маргарита.
Анализ сюжета
Сюжет романа можно исследовать с помощью анализа тональности текста (сентимент-анализа). Этот метод поможет увидеть динамику сюжета и смену настроений. Сентимент-анализ опирается на выделение восьми «основных» эмоций человека — это гнев, ожидание, радость, принятие, страх, удивление, грусть и отвращение. Каждую из этих эмоций можно назвать разными словами, имеющими положительную или отрицательную окраску.
Таким образом, проанализировав, какие и как эмоционально окрашенные слова представлены в тексте, можно предположить эмоциональное состояние читателя этого текста.
В первой главе «Мастера и Маргариты» — умеренно положительный настрой. Затем автор рассказывает о допросе и пытках Иешуа, смерти Берлиоза и погоне Ивана за Воландом и его свитой, что приводит к резкому падению настроения. Небольшой просвет есть в момент, когда Иван приходит к Грибоедову, но затем снова начинает преобладать негатив вплоть до успокаивающего разговора с профессором.
Далее, в 10-й и 11-й главе, сюжет идет ровно, рассказывая о серии проделок нечистой силы в Москве, о расколе Ивана. Но потом, когда в 13-й главе романа появляется главный персонаж, Мастер, настроение снова идет вверх.
Хотя роман и имеет положительную динамику в конце, он все же не выбирается в плюс: слов с отрицательной эмоциональной окраской оказалось больше, и сцена с допросом в начале очень сильно влияет на всю тональность романа.
https://sysblok.ru/philology/kod-mastera-i-margarity/
{kind=link}
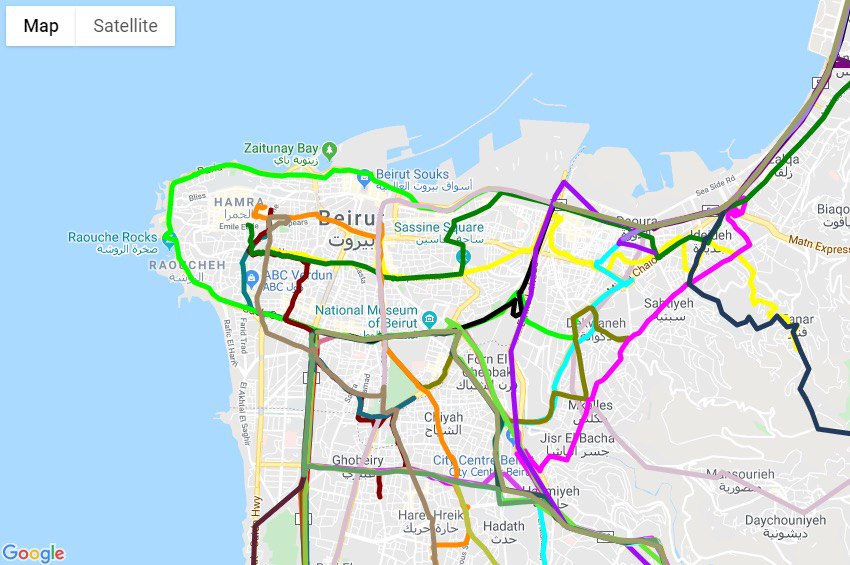
GPS против автобусного хаоса: как студенты и волонтеры оцифровывали городские маршруты в Ливане
Жители большинства городов мира привыкли к тому, что общественный транспорт работает так: человек приходит на специально определенное место и садится на определенный вид транспорта. Транспорт доставляет его в другое определенное место, где поездку можно прекратить. Но это возможно только если создана система остановок и маршрутов, по которым этот транспорт ходит. Согласитесь, это применимо к любым видам, будь то самолеты (хотя не очень-то он и общественный), паромы или автобусы.
Автобусы и война
Но есть и особые случаи. Ливан — страна Ближнего Востока, расположенная на побережье Средиземного моря. С 1975 по 1990 годы, целых 15 лет, здесь бушевала гражданская война, которая оставила после себя полностью уничтоженную систему автобусного сообщения внутри страны и крупных городов. Прошло уже почти тридцать лет с момента установления мира, но в столице страны Бейруте вы не найдете ни одной автобусной остановки.
Связать водителя и пассажиров: YallaBus
Группа студентов из Американского университета Бейрута взялась исправить ситуацию с общественным транспортом в городе. Конечно, речь не идет о запуске собственных маршрутов — но о документировании уже существующих. Для этого использовались данные GPS и наблюдения волонтеров, и в результате команда, давшая своему продукту название YallaBus, получила примерную схему маршрутов городских автобусов Бейрута. Основываясь на ней, разработчики хотели «соединить» водителей автобусов и потенциальных пассажиров, показывая последним виртуальные места остановок, где проще всего поймать автобус, а первым — места сосредоточения пассажиров. К сожалению, сейчас проект выглядит замороженным, но хочется надеяться, что это временно.
Автобус с GPS
Похожий проект Bus Map Project был основан двумя ливанцами в 2016 году, и также собирает информацию о маршрутах автобусов, в основном самым простым способом — волонтеры проекта ездят на автобусах и записывают GPS-трек перемещения. В этом году участники проекта также сделали печатную карту маршрутов автобусов, которую старались распространять по мере возможности.
Частая проблема в попытке картографировать маршруты общественного транспорта (возможно, присущая странам Ближнего Востока) — место здесь не всегда имеет четкую привязку, вроде координат или номеров домов, а чаще описывается особенными деталями и признаками. Нет смысла искать дом по адресу, если ими все равно никто не пользуется, гораздо быстрее найти место по его описанию.
Из-за таких особенностей Bus Map Project часто подчеркивает, что все собранные ими данные не являются полными и полностью достоверными — всегда есть чем их улучшить, к чему они и приглашают всех заинтересовавшихся.
Нелли Бурцева
Жители большинства городов мира привыкли к тому, что общественный транспорт работает так: человек приходит на специально определенное место и садится на определенный вид транспорта. Транспорт доставляет его в другое определенное место, где поездку можно прекратить. Но это возможно только если создана система остановок и маршрутов, по которым этот транспорт ходит. Согласитесь, это применимо к любым видам, будь то самолеты (хотя не очень-то он и общественный), паромы или автобусы.
Автобусы и война
Но есть и особые случаи. Ливан — страна Ближнего Востока, расположенная на побережье Средиземного моря. С 1975 по 1990 годы, целых 15 лет, здесь бушевала гражданская война, которая оставила после себя полностью уничтоженную систему автобусного сообщения внутри страны и крупных городов. Прошло уже почти тридцать лет с момента установления мира, но в столице страны Бейруте вы не найдете ни одной автобусной остановки.
Связать водителя и пассажиров: YallaBus
Группа студентов из Американского университета Бейрута взялась исправить ситуацию с общественным транспортом в городе. Конечно, речь не идет о запуске собственных маршрутов — но о документировании уже существующих. Для этого использовались данные GPS и наблюдения волонтеров, и в результате команда, давшая своему продукту название YallaBus, получила примерную схему маршрутов городских автобусов Бейрута. Основываясь на ней, разработчики хотели «соединить» водителей автобусов и потенциальных пассажиров, показывая последним виртуальные места остановок, где проще всего поймать автобус, а первым — места сосредоточения пассажиров. К сожалению, сейчас проект выглядит замороженным, но хочется надеяться, что это временно.
Автобус с GPS
Похожий проект Bus Map Project был основан двумя ливанцами в 2016 году, и также собирает информацию о маршрутах автобусов, в основном самым простым способом — волонтеры проекта ездят на автобусах и записывают GPS-трек перемещения. В этом году участники проекта также сделали печатную карту маршрутов автобусов, которую старались распространять по мере возможности.
Частая проблема в попытке картографировать маршруты общественного транспорта (возможно, присущая странам Ближнего Востока) — место здесь не всегда имеет четкую привязку, вроде координат или номеров домов, а чаще описывается особенными деталями и признаками. Нет смысла искать дом по адресу, если ими все равно никто не пользуется, гораздо быстрее найти место по его описанию.
Из-за таких особенностей Bus Map Project часто подчеркивает, что все собранные ими данные не являются полными и полностью достоверными — всегда есть чем их улучшить, к чему они и приглашают всех заинтересовавшихся.
Нелли Бурцева
{kind=link}
Лучшие посты "Системного Блока" о кино (к 100-летию Феллини)
Сегодня 100 лет со дня рождения Федерико Феллини. В этот исторический для мирового кинематографа день мы решили вспомнить лучшие посты «Системного Блока» о киноисследованиях.
1. Спецэффекты на минималках
Первый фильм со спецэффектом был снят уже в 1895 году — на киностудии Томаса Эдисона «обезглавили» Марию Шотландскую, заменив актрису на манекен. Остальным актерам пришлось в это время замереть. А как еще исхитрялись режиссеры в эпоху, когда не было компьютерной графики и 3D?
2. О чем говорят герои фильмов Уэса Андерсона?
Узнать фильм Уэса Андерсона несложно: идеально симметричные кадры, теплая палитра, удивительные детали, странные костюмы… Это своего рода «сказки для взрослых» с терапевтическим эффектом. К юбилею режиссера мы исследовали, что говорят его герои, собрав и проанализировав корпус субтитров. В посте описано, как можно повторить такое исследование.
3. Диалоги в голливудских фильмах: герои против героинь
Голливуд активно пытается справиться с проблемами неравенства на экране. Но пока белые мужчины получают больше всего экранного времени, а женщин перестают снимать, когда они стареют. Не верите? Смотрите статистику.
4. Технологии в кино: как работают спецэффекты
В материале «Спецэффекты на минималках» мы рассказывали о том, как режиссеры создавали космические миры и ужасных монстров с помощью картона, папье маше и умелого монтажа. Теперь пришло время компьютерных эффектов. Разбираемся, как делают кинотрюки в XXI веке и что пришлось делать Бенедикту Камбербэтчу, когда он играл в «Хоббите» дракона Смауга.
5. За гранью разумного: нейросеть придумала кино
Да-да, именно так. Автор сценария — рекуррентная нейросеть (LSTM) по имени Бенджамин. Фильм сняли — и он получился на удивление неплох. Посмотрите сами.
Сегодня 100 лет со дня рождения Федерико Феллини. В этот исторический для мирового кинематографа день мы решили вспомнить лучшие посты «Системного Блока» о киноисследованиях.
1. Спецэффекты на минималках
Первый фильм со спецэффектом был снят уже в 1895 году — на киностудии Томаса Эдисона «обезглавили» Марию Шотландскую, заменив актрису на манекен. Остальным актерам пришлось в это время замереть. А как еще исхитрялись режиссеры в эпоху, когда не было компьютерной графики и 3D?
2. О чем говорят герои фильмов Уэса Андерсона?
Узнать фильм Уэса Андерсона несложно: идеально симметричные кадры, теплая палитра, удивительные детали, странные костюмы… Это своего рода «сказки для взрослых» с терапевтическим эффектом. К юбилею режиссера мы исследовали, что говорят его герои, собрав и проанализировав корпус субтитров. В посте описано, как можно повторить такое исследование.
3. Диалоги в голливудских фильмах: герои против героинь
Голливуд активно пытается справиться с проблемами неравенства на экране. Но пока белые мужчины получают больше всего экранного времени, а женщин перестают снимать, когда они стареют. Не верите? Смотрите статистику.
4. Технологии в кино: как работают спецэффекты
В материале «Спецэффекты на минималках» мы рассказывали о том, как режиссеры создавали космические миры и ужасных монстров с помощью картона, папье маше и умелого монтажа. Теперь пришло время компьютерных эффектов. Разбираемся, как делают кинотрюки в XXI веке и что пришлось делать Бенедикту Камбербэтчу, когда он играл в «Хоббите» дракона Смауга.
5. За гранью разумного: нейросеть придумала кино
Да-да, именно так. Автор сценария — рекуррентная нейросеть (LSTM) по имени Бенджамин. Фильм сняли — и он получился на удивление неплох. Посмотрите сами.
{kind=link}
Невидимые кинозвезды: как Голливуд не замечает женщин-режиссеров
В 2010 году «Оскар» за лучшую режиссуру впервые получила женщина — Кэтрин Бигелоу с фильмом «Повелитель бури». Стали ли после этого режиссеры женского пола более заметными фигурами в киноиндустрии? Редакция «Системного Блока» провела исследование, проследив динамику упоминаний женщин-режиссеров в статьях популярных киножурналов.
Мы оттолкнулись от предположения, что активная деятельность феминистского сообщества и внимание общественности к проблеме гендерного неравенства должны были изменить ситуацию в киноиндустрии в части дискриминации женщин. Наша гипотеза состояла в том, что количество упоминаний женщин-режиссеров в СМИ должно было значительно возрасти в последние несколько лет.
Оказывается, интерес к запросу в google по словосочетанию female director вырос вдвое за последние десять лет, но фактически — женщины-режиссеры по прежнему остаются незаметными.
https://sysblok.ru/research/nevidimye-kinozvezdy/
В 2010 году «Оскар» за лучшую режиссуру впервые получила женщина — Кэтрин Бигелоу с фильмом «Повелитель бури». Стали ли после этого режиссеры женского пола более заметными фигурами в киноиндустрии? Редакция «Системного Блока» провела исследование, проследив динамику упоминаний женщин-режиссеров в статьях популярных киножурналов.
Мы оттолкнулись от предположения, что активная деятельность феминистского сообщества и внимание общественности к проблеме гендерного неравенства должны были изменить ситуацию в киноиндустрии в части дискриминации женщин. Наша гипотеза состояла в том, что количество упоминаний женщин-режиссеров в СМИ должно было значительно возрасти в последние несколько лет.
Оказывается, интерес к запросу в google по словосочетанию female director вырос вдвое за последние десять лет, но фактически — женщины-режиссеры по прежнему остаются незаметными.
https://sysblok.ru/research/nevidimye-kinozvezdy/
{kind=link}
Обзор курсов по математике для Data Science
Всякое знакомство с машинным обучением неизбежно приводит к «линейной регрессии» и «градиентному спуску», «дифференцируемым функциям» и «экстремумам» – понятиям, которые вызывают священный трепет у изучавших высшую математику в вузе и страх у тех, кто с ними не знаком. В этой подборке мы собрали курсы по математике, которые позволят заполнить пробелы или освежить в памяти ключевые математические аспекты.
1. Курс «Essential Math for Machine Learning: Python Edition» от Microsoft
Входные требования: базовые знания математики, опыт программирования (предпочтительно на языке Python)
Доступность: бесплатно
Язык: английский
Темы: линейная алгебра, методы оптимизации, математическая статистика и теория вероятностей
Подробнее
2. Курсы Khan Academy: «Linear Algebra», «Probability & Statistics», «Multivariable Calculus» и «Optimization»
Доступность: бесплатно
Язык: английский
Темы: линейная алгебра, математическая статистика и теория вероятностей, математический анализ, методы оптимизации
Подробнее:
Linear Algebra, Probability & Statistics, Multivariable Calculus, Optimization
3. Специализация «Mathematics for Machine Learning Specialization» от Imperial College London
Входные требования: базовые знания математики на школьном уровне
Доступность: платно, 3 т.р./месяц или по подписке Coursera Plus. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid
Язык: английский
Темы: линейная алгебра, математический анализ, PCA
Подробнее
4. Специализация «Mathematics for Data Science» от ВШЭ
Входные требования: базовые знания математики, основы программирования на языке Python
Доступность: платно, 2,5 т.р./месяц или по подписке Coursera Plus. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid
Язык: английский
Темы: дискретная математика, математический анализ, линейная алгебра, теория вероятностей
Подробнее
5. Курс «Математика и Python для анализа данных» от МФТИ и Яндекс
Входные требования: опыт программирования
Доступность: платно, 5 т.р./месяц. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid.
Язык: русский
Темы: линейная алгебра, методы оптимизации, математическая статистика и теория вероятностей
Подробнее
6. Курс «Математика для Data Science» от преподавателя ВШЭ Петра Лукьянченко и наших партнеров OTUS
Входные требования: достаточно знать математику на школьном уровне
Доступность: курс платный, доступен бесплатный вебинар, на котором можно узнать подробности про задачи курса
Язык: русский
О преподавателе: Петр Лукьянченко уже 10 лет преподает высшую математику в ВШЭ и имеет богатый опыт работы в Data Science.
Темы: математический анализ, линейная алгебра, теория вероятности и статистика
Подробнее
Бесплатный вебинар 27 января: регистрация.
Всякое знакомство с машинным обучением неизбежно приводит к «линейной регрессии» и «градиентному спуску», «дифференцируемым функциям» и «экстремумам» – понятиям, которые вызывают священный трепет у изучавших высшую математику в вузе и страх у тех, кто с ними не знаком. В этой подборке мы собрали курсы по математике, которые позволят заполнить пробелы или освежить в памяти ключевые математические аспекты.
1. Курс «Essential Math for Machine Learning: Python Edition» от Microsoft
Входные требования: базовые знания математики, опыт программирования (предпочтительно на языке Python)
Доступность: бесплатно
Язык: английский
Темы: линейная алгебра, методы оптимизации, математическая статистика и теория вероятностей
Подробнее
2. Курсы Khan Academy: «Linear Algebra», «Probability & Statistics», «Multivariable Calculus» и «Optimization»
Доступность: бесплатно
Язык: английский
Темы: линейная алгебра, математическая статистика и теория вероятностей, математический анализ, методы оптимизации
Подробнее:
Linear Algebra, Probability & Statistics, Multivariable Calculus, Optimization
3. Специализация «Mathematics for Machine Learning Specialization» от Imperial College London
Входные требования: базовые знания математики на школьном уровне
Доступность: платно, 3 т.р./месяц или по подписке Coursera Plus. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid
Язык: английский
Темы: линейная алгебра, математический анализ, PCA
Подробнее
4. Специализация «Mathematics for Data Science» от ВШЭ
Входные требования: базовые знания математики, основы программирования на языке Python
Доступность: платно, 2,5 т.р./месяц или по подписке Coursera Plus. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid
Язык: английский
Темы: дискретная математика, математический анализ, линейная алгебра, теория вероятностей
Подробнее
5. Курс «Математика и Python для анализа данных» от МФТИ и Яндекс
Входные требования: опыт программирования
Доступность: платно, 5 т.р./месяц. Доступен 7-дневный бесплатный пробный период или можно запросить Financial aid.
Язык: русский
Темы: линейная алгебра, методы оптимизации, математическая статистика и теория вероятностей
Подробнее
6. Курс «Математика для Data Science» от преподавателя ВШЭ Петра Лукьянченко и наших партнеров OTUS
Входные требования: достаточно знать математику на школьном уровне
Доступность: курс платный, доступен бесплатный вебинар, на котором можно узнать подробности про задачи курса
Язык: русский
О преподавателе: Петр Лукьянченко уже 10 лет преподает высшую математику в ВШЭ и имеет богатый опыт работы в Data Science.
Темы: математический анализ, линейная алгебра, теория вероятности и статистика
Подробнее
Бесплатный вебинар 27 января: регистрация.
Вебинар «Математика для Data Science»
27 января, 20:00
Машинное обучение и Data Science похожи на ядерную физику в начале 50-х или кибернетику в 60-е. Мечтают делать многие, понимают немногие, делают — совсем немногие. Главная преграда — математика. Все эти «линейные регрессии», «градиентные спуски» и «дифференцируемые функции» пугают, особенно если вы не открывали учебники со школы. Да и если открывали — матан и линал все равно немного бросают в дрожь. А без математики в Data Science никуда.
Простой пример — производные. В школе их изучение обычно привязывают к физике. Помните, там скорость разных едущих/бегущих/летящих объектов вычислялась как производная от расстояния, а ускорение — как производная от скорости... Так вот, в Data Science производные используются в обучении нейросетей. Чтобы нейросеть всё лучше переводила тексты или распознавала котиков на фото, применяют алгоритм «обратного распространения ошибки» и тот самый «градиентный спуск». А в его основе — как раз расчет производных!
Вот только в Data Science производные посложнее, чем в школьной программе. В школе нужно было найти точку с нулевой производной на двумерном графике — а здесь многомерные гиперплоскости… Разобраться в этом самому непросто. Гораздо проще понять математику в основе нейросетей, расспрашивая опытного дата-сайнтиста. Такая возможность будет сегодня в 20:00 по московскому времени онлайн — наши партнеры OTUS проведут бесплатный вебинар «Математика в Data Science». Регистрация по ссылке.
Что будет на вебинаре?
На вебинаре вам расскажут:
— какая математика нужна для Data Science, а без чего можно обойтись
— с чего правильно начинать обучение, чтобы было понятно и не страшно
— как развиваться в Data Science и строить свою карьеру
Кто ведет?
Курс ведёт Пётр Лукьянченко — преподаватель высшей математики в НИУ-ВШЭ с 10 летним стажем и data-саентист. Учился в Лондонской школе экономики, работал Team Lead Analytics в Lamoda, занимался анализом экспериментальных данных в научной организации.
Что будет за вебинаром?
Если вебинар вам понравится, вы сможете подключиться к обучению на основном курсе «Математика в Data Science». У курса есть базовая версия для новичков — и продвинутая, для тех, кто уже начал разбираться в Data Science, но хочет прокачаться. Курс платный, ознакомиться с программой можно тут.
#Промо
27 января, 20:00
Машинное обучение и Data Science похожи на ядерную физику в начале 50-х или кибернетику в 60-е. Мечтают делать многие, понимают немногие, делают — совсем немногие. Главная преграда — математика. Все эти «линейные регрессии», «градиентные спуски» и «дифференцируемые функции» пугают, особенно если вы не открывали учебники со школы. Да и если открывали — матан и линал все равно немного бросают в дрожь. А без математики в Data Science никуда.
Простой пример — производные. В школе их изучение обычно привязывают к физике. Помните, там скорость разных едущих/бегущих/летящих объектов вычислялась как производная от расстояния, а ускорение — как производная от скорости... Так вот, в Data Science производные используются в обучении нейросетей. Чтобы нейросеть всё лучше переводила тексты или распознавала котиков на фото, применяют алгоритм «обратного распространения ошибки» и тот самый «градиентный спуск». А в его основе — как раз расчет производных!
Вот только в Data Science производные посложнее, чем в школьной программе. В школе нужно было найти точку с нулевой производной на двумерном графике — а здесь многомерные гиперплоскости… Разобраться в этом самому непросто. Гораздо проще понять математику в основе нейросетей, расспрашивая опытного дата-сайнтиста. Такая возможность будет сегодня в 20:00 по московскому времени онлайн — наши партнеры OTUS проведут бесплатный вебинар «Математика в Data Science». Регистрация по ссылке.
Что будет на вебинаре?
На вебинаре вам расскажут:
— какая математика нужна для Data Science, а без чего можно обойтись
— с чего правильно начинать обучение, чтобы было понятно и не страшно
— как развиваться в Data Science и строить свою карьеру
Кто ведет?
Курс ведёт Пётр Лукьянченко — преподаватель высшей математики в НИУ-ВШЭ с 10 летним стажем и data-саентист. Учился в Лондонской школе экономики, работал Team Lead Analytics в Lamoda, занимался анализом экспериментальных данных в научной организации.
Что будет за вебинаром?
Если вебинар вам понравится, вы сможете подключиться к обучению на основном курсе «Математика в Data Science». У курса есть базовая версия для новичков — и продвинутая, для тех, кто уже начал разбираться в Data Science, но хочет прокачаться. Курс платный, ознакомиться с программой можно тут.
#Промо
Шесть рукопожатий Фрэнсиса Бэкона
Фрэнсис Бэкон — главный эмпирик мировой философии, выдающийся ученый, крупный политик, талантливый литератор и знатный коррупционер. Рассказываем о том, как ученые восстановили социальную сеть Бэкона и построили из нее целый «фейсбук» Англии 500-летней давности, исследовать который может каждый.
Проект Six Degrees of Francis Bacon («Шесть рукопожатий Фрэнсиса») создан совместными усилиями Университета Карнеги — Меллона и Джорджтаунского университета. Это хороший пример того, как цифровые технологии могут использоваться в гуманитарных дисциплинах. На сайте можно проследить связи Бэкона с самыми разными историческими деятелями того времени: от короля Англии Якова I до философа Томаса Гоббса и драматурга Уильяма Шекспира.
https://sysblok.ru/visual/shest-rukopozhatij-frjensisa-bjekona/
Фрэнсис Бэкон — главный эмпирик мировой философии, выдающийся ученый, крупный политик, талантливый литератор и знатный коррупционер. Рассказываем о том, как ученые восстановили социальную сеть Бэкона и построили из нее целый «фейсбук» Англии 500-летней давности, исследовать который может каждый.
Проект Six Degrees of Francis Bacon («Шесть рукопожатий Фрэнсиса») создан совместными усилиями Университета Карнеги — Меллона и Джорджтаунского университета. Это хороший пример того, как цифровые технологии могут использоваться в гуманитарных дисциплинах. На сайте можно проследить связи Бэкона с самыми разными историческими деятелями того времени: от короля Англии Якова I до философа Томаса Гоббса и драматурга Уильяма Шекспира.
https://sysblok.ru/visual/shest-rukopozhatij-frjensisa-bjekona/
{kind=link}
Сети Чехова: откуда вырос «Вишневый сад»
Сегодня 160 лет Антону Павловичу Чехову. За несколько месяцев до смерти Чехов сказал Бунину, что читать его будут «лет семь». А в итоге оказался звездой мировой литературы, вместе с Достоевским и Толстым. Чеховым вдохновлялись Джеймс Джойс, Вирджиния Вулф и Бернард Шоу, его пьесы ставят по всему миру. В театре Чехов стал таким же новатором, как Эйнштейн в физике или Стив Джобс в электронике. Чехов переизобрел драматургию: в его пьесах часто нет главного героя, нет однозначно хороших или плохих персонажей, вообще — нет диктата автора. Автор рисует тонких, сложных, психологически нагруженных персонажей, а режиссеру достается свобода создавать из них самые разные сценические прочтения — вплоть до противоположных друг другу. Ничего подобного не было и не могло быть в пьесах драматургов до-чеховской поры, вроде Островского.
Цифровые методы пока что плохо приспособлены для исследования литературного творчества. Digital Literary Studies, цифровое литературоведение, делает свои первые шаги. Тем не менее первые робкие подходы к исследованию драматургии, и конкретно творчества Чехова, уже есть. Сегодня мы хотим поделиться работой русско-немецкой команды ученых, которая исследовала и визуализировала пьесы Чехова с использованием сетевого анализа (англ. network analysis, нем. Netzwerkanalyse).
Каждая пьеса — от ранних «На большой дороге» и «Ночи перед судом» до классических «Чайки», «Дяди Вани», «Трех сестер» и «Вишневого сада», ставших венцом чеховской драматургии, — представлена в виде социальной сети персонажей. Сети построены на основе разметки взаимодействия между героями. Сила взаимодействия (толщина связи в сети) пропорциональна числу диалогов двух персонажей. Цветами обозначен пол героев.
Также в центре этой визуализации приведена статистика. В столбцах показаны распределения центральностей персонажей в социальных сетях наиболее значимых Чеховских пьес (мы рассказывали о том, как измеряется центральность, вот здесь). Под столбцами — два графика: правый показывает плотность социальных сетей, левый — соотношение мужской и женской речи в пьесах Чехова.
Что дает такое представление?
Во-первых, информация о центральностях персонажей подтверждает тезис об отсутствии главного героя в большинстве пьес. Центральности распределены равномерно, а в «Дяде Ване» и «Чайке» наиболее центральный персонаж меняется в зависимости от метрики.
Во-вторых, Чехов оказывается практически единственным классическим русским драматургом, у которого доля женской речи в пьесах сопоставима с мужской. У других крупных авторов пьес, например, Островского или Гоголя, мужчины говорят в разы больше, чем женщины. У Чехова же практически гендерный паритет.
В-третьих, мы можем проследить своеобразную эволюцию структуры Чеховских пьес. В 80-е годы, первый период взрослого творчества Чехова, испытываются разные конфигурации героев: от самых маленьких, на 2-3 персонажа, в небольших шуточных пьесах вроде «Медведя», «Предложения» или «Трагика поневоле», до нагромождения лиц и фигур в написанной не для сцены «Татьяне Репиной». К концу творческой биографии Чехова (условный период с 1895 по 1904) видна некоторая стабилизация: писатель оставил малые шуточные формы, но и не создает больше сценических толп. Его поздние пьесы — зрелые полновесные драматические произведения со сложными, но не переусложненными конфигурациями персонажей.
Оригинал визуализации
Сегодня 160 лет Антону Павловичу Чехову. За несколько месяцев до смерти Чехов сказал Бунину, что читать его будут «лет семь». А в итоге оказался звездой мировой литературы, вместе с Достоевским и Толстым. Чеховым вдохновлялись Джеймс Джойс, Вирджиния Вулф и Бернард Шоу, его пьесы ставят по всему миру. В театре Чехов стал таким же новатором, как Эйнштейн в физике или Стив Джобс в электронике. Чехов переизобрел драматургию: в его пьесах часто нет главного героя, нет однозначно хороших или плохих персонажей, вообще — нет диктата автора. Автор рисует тонких, сложных, психологически нагруженных персонажей, а режиссеру достается свобода создавать из них самые разные сценические прочтения — вплоть до противоположных друг другу. Ничего подобного не было и не могло быть в пьесах драматургов до-чеховской поры, вроде Островского.
Цифровые методы пока что плохо приспособлены для исследования литературного творчества. Digital Literary Studies, цифровое литературоведение, делает свои первые шаги. Тем не менее первые робкие подходы к исследованию драматургии, и конкретно творчества Чехова, уже есть. Сегодня мы хотим поделиться работой русско-немецкой команды ученых, которая исследовала и визуализировала пьесы Чехова с использованием сетевого анализа (англ. network analysis, нем. Netzwerkanalyse).
Каждая пьеса — от ранних «На большой дороге» и «Ночи перед судом» до классических «Чайки», «Дяди Вани», «Трех сестер» и «Вишневого сада», ставших венцом чеховской драматургии, — представлена в виде социальной сети персонажей. Сети построены на основе разметки взаимодействия между героями. Сила взаимодействия (толщина связи в сети) пропорциональна числу диалогов двух персонажей. Цветами обозначен пол героев.
Также в центре этой визуализации приведена статистика. В столбцах показаны распределения центральностей персонажей в социальных сетях наиболее значимых Чеховских пьес (мы рассказывали о том, как измеряется центральность, вот здесь). Под столбцами — два графика: правый показывает плотность социальных сетей, левый — соотношение мужской и женской речи в пьесах Чехова.
Что дает такое представление?
Во-первых, информация о центральностях персонажей подтверждает тезис об отсутствии главного героя в большинстве пьес. Центральности распределены равномерно, а в «Дяде Ване» и «Чайке» наиболее центральный персонаж меняется в зависимости от метрики.
Во-вторых, Чехов оказывается практически единственным классическим русским драматургом, у которого доля женской речи в пьесах сопоставима с мужской. У других крупных авторов пьес, например, Островского или Гоголя, мужчины говорят в разы больше, чем женщины. У Чехова же практически гендерный паритет.
В-третьих, мы можем проследить своеобразную эволюцию структуры Чеховских пьес. В 80-е годы, первый период взрослого творчества Чехова, испытываются разные конфигурации героев: от самых маленьких, на 2-3 персонажа, в небольших шуточных пьесах вроде «Медведя», «Предложения» или «Трагика поневоле», до нагромождения лиц и фигур в написанной не для сцены «Татьяне Репиной». К концу творческой биографии Чехова (условный период с 1895 по 1904) видна некоторая стабилизация: писатель оставил малые шуточные формы, но и не создает больше сценических толп. Его поздние пьесы — зрелые полновесные драматические произведения со сложными, но не переусложненными конфигурациями персонажей.
Оригинал визуализации
{kind=link}
10 каналов о культуре
Писать о высоком без пафоса умеют немногие. Мы сделали подборку каналов о культуре, у которых это получается. Сегодня в номере: Толстой как хипстер, блатняк на латыни, бытовые страдания Чехова, нейросети против художников.
— @altaaetasmedia — Высокое Средневековье
Чем современные российские полицейские похожи на средневековых королей? Почему демоны на гравюрах XV века стреляют из ружей? Откуда на православных иконах Ленин с пистолетом? Есть ли настоящие Средние века в «Игре престолов»? Это не смешно, всё правда так было!
— @latinapopacanski — Латынь по-пацански
Как звучат на латыни дворовые фразы из «Бригады», песни Меладзе, цитаты Лукашенко, популярные мемасы или рождественский хит Jingle Bells? Какие сумасшествия творили римские императоры, как развлекались патриции и плебеи? Такую латынь, такую историю по учебникам не выучишь. Канал ведет переводчик интерфейсов ВК и Телеграма на латинский язык.
— @vatnikstan — VATNIKSTAN
Русский космизм и советские политические инфографики. Газета Спид-ИНФО и дореволюционный журнал «Флирт». Русский Париж 1920-х и советский Ташкент 1940-х. Все это — VATNIKSTAN. Познавательный журнал о русскоязычной цивилизации.
— @discoursio — Дискурс
Острые тексты о культуре, науке и обществе. Что делать с шедеврами нацистского кинематографа: прятать в архивах — или выложить в открытый доступ? Каково это — лежать в переполненной палате провинциальной психбольницы? Как благодаря коррупции выйти из российской тюрьмы и получить убежище в Лондоне? На что способен гуманитарий, чтобы стать программистом? Как перестать стыдиться и начать получать удовольствие от секса? Дискурс управляется горизонтальной редакцией, и вы тоже можете публиковать в журнале свои тексты.
— @monocler — Моноклер
Как живет культурная память в эпоху мессенджеров и соцсетей? Почему на смену идеологии души в обществе потребления пришел нарциссический культ тела и что думают об этом современные философы? Что делает с мозгом Tinder? Как происходит упадок цивилизаций, будет ли нам сложно восстановить науку и культуру после всемирной катастрофы? Моноклер рассказывает о современном преломлении фундаментальных философских вопросов.
— @FromTolstoy — From:Tolstoy
Лев Толстой как хипстер, любитель ЗОЖ, тусовщик, прокрастинатор и оппозиционер. В письмах великого писателя — его повседневная жизнь, отношения с женой и детьми, ненависть к Тургеневу склоки и дружба с коллегами-литераторами, протесты в адрес правительства, рецензии на школьные стихи, болезненное самокопание, признания в любви. Выходит при участии Музея Л.Н. Толстого.
— @chekhovpishet — Чехов Пишет
Трогательные письма самого интеллигентного классика русской литературы. Чехов пишет жене-«актрисуле» с признаниями в любви — и тут же рассказывает о лечении зубов. Обсуждает с Короленко цензуру. Жалуется брату на маленькие гонорары. Обращения прекрасны: мордуся, лошадка, милая моя собака (это тоже о жене). И почти везде — узнаваемый чеховский юмор, местами чёрный.
— @tolstoy_life — Лев Толстой. Лайфстайл
Житейская мудрость из дневников Льва Николаевича. Дневниковые записи Толстого в духе «Целый день шалопутничал», «Наелся сладостей. Засиделся. Лгал», «Надо быть сильным или спать» давно превратились в гуманитарный мем. Но хуже они от этого не становятся!
— @concrete_music — Бетонная шкатулка
Канал дирижёра Кристины, которая окончила Московскую консерваторию, а сейчас живёт в Торонто и дирижирует в разных странах. В своем канале Кристина пишет о музыке (академической и электронной), композиторах и архитектуре.
— @sysblok — Системный Блокъ
Образовательный и научно-популярный проект о проникновении IT в культуру и общество. Как нейросети распознают египетские иероглифы? Что можно увидеть из анализа текстов Егора Летова и Ивана Голунова? Как предсказать популярность художника по первой выставке, и в каких цветах страдало Средневековье? Как нейросети пишут музыку и как работают музыкальные поисковики? Хотите начать свой путь в технологии или следить за влиянием технологий на культуру — присоединяйтесь.
Писать о высоком без пафоса умеют немногие. Мы сделали подборку каналов о культуре, у которых это получается. Сегодня в номере: Толстой как хипстер, блатняк на латыни, бытовые страдания Чехова, нейросети против художников.
— @altaaetasmedia — Высокое Средневековье
Чем современные российские полицейские похожи на средневековых королей? Почему демоны на гравюрах XV века стреляют из ружей? Откуда на православных иконах Ленин с пистолетом? Есть ли настоящие Средние века в «Игре престолов»? Это не смешно, всё правда так было!
— @latinapopacanski — Латынь по-пацански
Как звучат на латыни дворовые фразы из «Бригады», песни Меладзе, цитаты Лукашенко, популярные мемасы или рождественский хит Jingle Bells? Какие сумасшествия творили римские императоры, как развлекались патриции и плебеи? Такую латынь, такую историю по учебникам не выучишь. Канал ведет переводчик интерфейсов ВК и Телеграма на латинский язык.
— @vatnikstan — VATNIKSTAN
Русский космизм и советские политические инфографики. Газета Спид-ИНФО и дореволюционный журнал «Флирт». Русский Париж 1920-х и советский Ташкент 1940-х. Все это — VATNIKSTAN. Познавательный журнал о русскоязычной цивилизации.
— @discoursio — Дискурс
Острые тексты о культуре, науке и обществе. Что делать с шедеврами нацистского кинематографа: прятать в архивах — или выложить в открытый доступ? Каково это — лежать в переполненной палате провинциальной психбольницы? Как благодаря коррупции выйти из российской тюрьмы и получить убежище в Лондоне? На что способен гуманитарий, чтобы стать программистом? Как перестать стыдиться и начать получать удовольствие от секса? Дискурс управляется горизонтальной редакцией, и вы тоже можете публиковать в журнале свои тексты.
— @monocler — Моноклер
Как живет культурная память в эпоху мессенджеров и соцсетей? Почему на смену идеологии души в обществе потребления пришел нарциссический культ тела и что думают об этом современные философы? Что делает с мозгом Tinder? Как происходит упадок цивилизаций, будет ли нам сложно восстановить науку и культуру после всемирной катастрофы? Моноклер рассказывает о современном преломлении фундаментальных философских вопросов.
— @FromTolstoy — From:Tolstoy
Лев Толстой как хипстер, любитель ЗОЖ, тусовщик, прокрастинатор и оппозиционер. В письмах великого писателя — его повседневная жизнь, отношения с женой и детьми, ненависть к Тургеневу склоки и дружба с коллегами-литераторами, протесты в адрес правительства, рецензии на школьные стихи, болезненное самокопание, признания в любви. Выходит при участии Музея Л.Н. Толстого.
— @chekhovpishet — Чехов Пишет
Трогательные письма самого интеллигентного классика русской литературы. Чехов пишет жене-«актрисуле» с признаниями в любви — и тут же рассказывает о лечении зубов. Обсуждает с Короленко цензуру. Жалуется брату на маленькие гонорары. Обращения прекрасны: мордуся, лошадка, милая моя собака (это тоже о жене). И почти везде — узнаваемый чеховский юмор, местами чёрный.
— @tolstoy_life — Лев Толстой. Лайфстайл
Житейская мудрость из дневников Льва Николаевича. Дневниковые записи Толстого в духе «Целый день шалопутничал», «Наелся сладостей. Засиделся. Лгал», «Надо быть сильным или спать» давно превратились в гуманитарный мем. Но хуже они от этого не становятся!
— @concrete_music — Бетонная шкатулка
Канал дирижёра Кристины, которая окончила Московскую консерваторию, а сейчас живёт в Торонто и дирижирует в разных странах. В своем канале Кристина пишет о музыке (академической и электронной), композиторах и архитектуре.
— @sysblok — Системный Блокъ
Образовательный и научно-популярный проект о проникновении IT в культуру и общество. Как нейросети распознают египетские иероглифы? Что можно увидеть из анализа текстов Егора Летова и Ивана Голунова? Как предсказать популярность художника по первой выставке, и в каких цветах страдало Средневековье? Как нейросети пишут музыку и как работают музыкальные поисковики? Хотите начать свой путь в технологии или следить за влиянием технологий на культуру — присоединяйтесь.
«Шахерезада»: робот, рассказывающий истории
Большинство ИИ, умеющих писать художественную прозу, основываются на заранее известных комбинациях персонажей, мест, и действий, которые могут быть совершены. ИИ по имени «Шахерезада», который разработали в одной из лабораторий IBM, устроен по другому принципу: он основывается на последовательности событий.
Генерация истории — это процесс выбора последовательности событий. Допустим, «Шахерезаде» нужно создать историю на тему «ограбление банка». Система использует краудсорсинг, чтобы быстро получить ряд нужных для истории примеров, строит график на основе последовательности событий и определяет взаимоисключающие события.
После построения сюжетного графа остается только вопрос, какую из получившихся линий — историй — выбрать. Система генерирует истории, добавляя события в историю так, чтобы не нарушались никакие ограничения приоритета или отношения взаимного исключения. Чтобы быть добавленным в историю, событие должно быть выполнимым. Событие выполнимо, когда все его прямые, обязательные предшествующие элементы пройдены, кроме тех, которые взаимно исключают друг друга. История заканчивается, когда достигается одно конечное событие.
https://sysblok.ru/philology/shaherezada-robot-rasskazyvajushhij-istorii/
Большинство ИИ, умеющих писать художественную прозу, основываются на заранее известных комбинациях персонажей, мест, и действий, которые могут быть совершены. ИИ по имени «Шахерезада», который разработали в одной из лабораторий IBM, устроен по другому принципу: он основывается на последовательности событий.
Генерация истории — это процесс выбора последовательности событий. Допустим, «Шахерезаде» нужно создать историю на тему «ограбление банка». Система использует краудсорсинг, чтобы быстро получить ряд нужных для истории примеров, строит график на основе последовательности событий и определяет взаимоисключающие события.
После построения сюжетного графа остается только вопрос, какую из получившихся линий — историй — выбрать. Система генерирует истории, добавляя события в историю так, чтобы не нарушались никакие ограничения приоритета или отношения взаимного исключения. Чтобы быть добавленным в историю, событие должно быть выполнимым. Событие выполнимо, когда все его прямые, обязательные предшествующие элементы пройдены, кроме тех, которые взаимно исключают друг друга. История заканчивается, когда достигается одно конечное событие.
https://sysblok.ru/philology/shaherezada-robot-rasskazyvajushhij-istorii/
{kind=link}
Многомерное «Слово о полку Игореве»: от кукушки до алкогольного брендинга
Когда мобильный интернет был экзотикой, а отчёты по грантам сдавали на 3,5-дюймовых дискетах... в Рунете уже были цифровые гуманитарные проекты! Рассказываем в лицах и деталях об одном из них — о параллельном корпусе переводов «Слова о полку Игореве», который отмечает свое 13-летие.
Обстоятельства появления корпуса почти такие же легендарные, как у самого «Слова». Сначала проекту прочил неудачу патриарх цифровой филологии и создатель Русской виртуальной библиотеки Игорь Пильщиков. А когда в 2007 году корпус все же родился — первым об этом возвестил пионер Рунета Роман Лейбов.
Сегодня корпус переводов «Слова» — один из самых технически продвинутых параллельных корпусов. После апгрейда 2017 года там появилась визуализация различий, которая позволяет увидеть все развилки и схождения разных переводов.
Всего на сайте доступны 233 версии «Слова о полку Игореве»:
● 11 вариантов древнерусского оригинала: текст в представлении Р. О. Якобсона, А. А. Зализняка, варианты из различных копий рукописи.
● 107 переводов на русский язык, сделанных за последние два с лишним столетия: от самых ранних, появившихся еще до утраты рукописи «Слова» в пожаре 1812 года, до новейших. От ставших классикой переводов Жуковского, Майкова, Заболоцкого — до переложений на блатной жаргон.
● 115 переводов «Слова» на другие языки. «Слово о полку Игореве» можно почитать на украинском, белорусском, эстонском, арабском, иврите … и еще множестве языков. Раздел пополняется: при участии специалиста по абхазо-адыгским языкам Ю. А. Ландера готовится к добавлению на сайт адыгейский текст, при участии востоковеда А. С. Оськиной — японский.
https://sysblok.ru/philology/mnogomernoe-slovo-o-polku-igoreve-ot-kukushki-do-alkogolnogo-brendinga/
Когда мобильный интернет был экзотикой, а отчёты по грантам сдавали на 3,5-дюймовых дискетах... в Рунете уже были цифровые гуманитарные проекты! Рассказываем в лицах и деталях об одном из них — о параллельном корпусе переводов «Слова о полку Игореве», который отмечает свое 13-летие.
Обстоятельства появления корпуса почти такие же легендарные, как у самого «Слова». Сначала проекту прочил неудачу патриарх цифровой филологии и создатель Русской виртуальной библиотеки Игорь Пильщиков. А когда в 2007 году корпус все же родился — первым об этом возвестил пионер Рунета Роман Лейбов.
Сегодня корпус переводов «Слова» — один из самых технически продвинутых параллельных корпусов. После апгрейда 2017 года там появилась визуализация различий, которая позволяет увидеть все развилки и схождения разных переводов.
Всего на сайте доступны 233 версии «Слова о полку Игореве»:
● 11 вариантов древнерусского оригинала: текст в представлении Р. О. Якобсона, А. А. Зализняка, варианты из различных копий рукописи.
● 107 переводов на русский язык, сделанных за последние два с лишним столетия: от самых ранних, появившихся еще до утраты рукописи «Слова» в пожаре 1812 года, до новейших. От ставших классикой переводов Жуковского, Майкова, Заболоцкого — до переложений на блатной жаргон.
● 115 переводов «Слова» на другие языки. «Слово о полку Игореве» можно почитать на украинском, белорусском, эстонском, арабском, иврите … и еще множестве языков. Раздел пополняется: при участии специалиста по абхазо-адыгским языкам Ю. А. Ландера готовится к добавлению на сайт адыгейский текст, при участии востоковеда А. С. Оськиной — японский.
https://sysblok.ru/philology/mnogomernoe-slovo-o-polku-igoreve-ot-kukushki-do-alkogolnogo-brendinga/
{kind=link}
Открытые данные ФСИН: число осужденных в России растёт только по наркопреступлениям
На сайте Федеральной службы исполнения наказаний РФ есть раздел с открытыми данными. Там опубликованы цифры по количеству осужденных за разные типы преступлений в динамике. Если эти данные верные, то единственная категория преступлений, по которой количество осужденных растёт — это преступления, «связанные с распространением наркотиков» (формулировка ФСИН). С 2005 года их стало больше в 2,5 раза.
Как видно из графика, в этот же период практически перестали сажать в тюрьму за хулиганство — падение почти 100%. Число осужденных за изнасилования, кражи, вымогательство, грабежи и разбой упало более чем вдвое.
На этом фоне рост наркопреступлений заставляет задуматься: действительно ли на общем фоне снижения преступности полиция стала ловить в 2,5 раза больше наркоторговцев? Алексей Кнорре из Института проблем правоприменения при Европейском Университете в Санкт-Петербурге ещё в 2017 году выяснил, что три четверти осужденных за наркопреступления — это потребители, а не распространители наркотиков. Такой перекос, по мнению исследователей — результат «палочной» системы в МВД, когда за отчетный период необходимо раскрыть плановое количество преступлений: выявлять потребителей значительно легче, чем распространителей.
Есть на графике и другие странности. Например, еще сильнее, чем грабежи и изнасилования, упало число осужденных за «умышленное причинение тяжкого вреда здоровью». Однако это падение выглядит искусственным: оно подозрительно совпадает со всплеском убийств. Есть вероятность, что одни и те же действия до 2009 года квалифицировали как умышленное причинение тяжкого вреда, повлекшее за собой смерть потерпевшего, а начиная с 2010 — как убийство.
Пока прозрачность ФСИН ограничивается этим и ещё несколькими небогатыми датасетами, мы не можем уверенно говорить, что стоит за цифрами. Искать ответы придется по старинке журналистам и правозащитникам. Но открытые данные хороши уже тем, что позволяют видеть такие странности — и задавать неудобные вопросы. «Системный Блокъ» будет регулярно исследовать общедоступные датасеты — и визуализировать то, что заставляет задуматься.
Источник данных: ФСИН
#opendata
На сайте Федеральной службы исполнения наказаний РФ есть раздел с открытыми данными. Там опубликованы цифры по количеству осужденных за разные типы преступлений в динамике. Если эти данные верные, то единственная категория преступлений, по которой количество осужденных растёт — это преступления, «связанные с распространением наркотиков» (формулировка ФСИН). С 2005 года их стало больше в 2,5 раза.
Как видно из графика, в этот же период практически перестали сажать в тюрьму за хулиганство — падение почти 100%. Число осужденных за изнасилования, кражи, вымогательство, грабежи и разбой упало более чем вдвое.
На этом фоне рост наркопреступлений заставляет задуматься: действительно ли на общем фоне снижения преступности полиция стала ловить в 2,5 раза больше наркоторговцев? Алексей Кнорре из Института проблем правоприменения при Европейском Университете в Санкт-Петербурге ещё в 2017 году выяснил, что три четверти осужденных за наркопреступления — это потребители, а не распространители наркотиков. Такой перекос, по мнению исследователей — результат «палочной» системы в МВД, когда за отчетный период необходимо раскрыть плановое количество преступлений: выявлять потребителей значительно легче, чем распространителей.
Есть на графике и другие странности. Например, еще сильнее, чем грабежи и изнасилования, упало число осужденных за «умышленное причинение тяжкого вреда здоровью». Однако это падение выглядит искусственным: оно подозрительно совпадает со всплеском убийств. Есть вероятность, что одни и те же действия до 2009 года квалифицировали как умышленное причинение тяжкого вреда, повлекшее за собой смерть потерпевшего, а начиная с 2010 — как убийство.
Пока прозрачность ФСИН ограничивается этим и ещё несколькими небогатыми датасетами, мы не можем уверенно говорить, что стоит за цифрами. Искать ответы придется по старинке журналистам и правозащитникам. Но открытые данные хороши уже тем, что позволяют видеть такие странности — и задавать неудобные вопросы. «Системный Блокъ» будет регулярно исследовать общедоступные датасеты — и визуализировать то, что заставляет задуматься.
Источник данных: ФСИН
#opendata
{kind=link}
Семантические сдвиги и предсказание военных конфликтов — в интервью с Андреем Кутузовым
Значение слов постоянно меняется, отражаясь в контекстах. Следом меняются и типичные ассоциации, связанные со словами.
Цифровые методы позволяют отследить эти изменения. Классический пример — слово «cell», которое сначала означало только «тюремную камеру», потом постепенно начало появляться в значении «биологическая клетка», а вот в конце 90-х — начале 2000-х письменные тексты захлестнула волна использования слова «cell» в значении «сотовый телефон».
Системный Блокъ взял интервью у Андрея Кутузова, создателя сайта RusVectōrēs, постдока и сотрудника группы языковых технологий в университете Осло.
О чем мы поговорили в интервью с Андреем:
● о диахронических семантических сдвигах — как изучать изменения значений слов с течением времени.
● о том, как даже простые дистрибутивные модели выявляют тонкие семантические отношения.
● о предсказании вооруженных конфликтов. Оказывается, что семантические сдвиги предшествуют вооруженным конфликтам, а значит, теоретически могут их предсказывать.
https://sysblok.ru/interviews/oblast-v-kotoroj-ja-rabotaju-rozhdaetsja-prjamo-na-glazah/
Значение слов постоянно меняется, отражаясь в контекстах. Следом меняются и типичные ассоциации, связанные со словами.
Цифровые методы позволяют отследить эти изменения. Классический пример — слово «cell», которое сначала означало только «тюремную камеру», потом постепенно начало появляться в значении «биологическая клетка», а вот в конце 90-х — начале 2000-х письменные тексты захлестнула волна использования слова «cell» в значении «сотовый телефон».
Системный Блокъ взял интервью у Андрея Кутузова, создателя сайта RusVectōrēs, постдока и сотрудника группы языковых технологий в университете Осло.
О чем мы поговорили в интервью с Андреем:
● о диахронических семантических сдвигах — как изучать изменения значений слов с течением времени.
● о том, как даже простые дистрибутивные модели выявляют тонкие семантические отношения.
● о предсказании вооруженных конфликтов. Оказывается, что семантические сдвиги предшествуют вооруженным конфликтам, а значит, теоретически могут их предсказывать.
https://sysblok.ru/interviews/oblast-v-kotoroj-ja-rabotaju-rozhdaetsja-prjamo-na-glazah/
{kind=link}
5 российских библиотек с богатыми цифровыми коллекциями
Оцифровка культурных данных — необходимая база для цифровых гуманитарных исследований. Делимся списком крупных коллекций, созданных российскими библиотеками.
1. Национальная электронная библиотека
В разделе «Коллекции» размещены тематические подборки самых разнообразных изданий и документов. Например: «Русская классика», «Редкие и ценные издания», «Московская электронная нотная библиотека», «Собрание картографических материалов» и др.
Для книг, находящихся в общественном достоянии, доступна опция «скачать» (в формате pdf или epub). Книги, находящиеся в ограниченном доступе, можно изучать в читальных залах библиотек, подключенных к НЭБ (спросите в библиотеке по соседству — скорее всего, она подключена). С лета этого года из библиотек открылся доступ и к коллекции диссертаций.
2. Российская национальная библиотека
В разделе «Электронные коллекции» множество подборок, в том числе с редкими историческими источниками. Тут есть коллекции «Епархиальных ведомостей» и «Памятных книжек губерний Российской империи», «Аудиозаписи российского музыкального фольклора», коллекция материалов о Санкт-Петербурге, огромный массив художественной литературы.
Документы доступны для просмотра онлайн в приложении Vivaldi. Чтобы выбрать только те документы, которые можно просмотреть на сайте, отметьте в фильтре «Отображать только электронные копии».
3. Президентская библиотека
Библиотека специализируется на книгах и документах по истории российской государственности и русского языка. Среди онлайн-коллекций этой библиотеки — собрания книг, периодических изданий и архивных документов, связанные с жизнью и деятельностью крупнейших российских писателей, ученых, художников, музыкантов, государственных деятелей и многих других.
Например, в коллекции, посвященной А.П. Чехову, есть подборка его портретов и фотографий, исторические публикации, посвященные юбилейным датам, открытки с изображением памятников Чехову и т.д. А в разделе «Аудиовизуальные материалы» можно, например, посмотреть старую кинохронику или редкие документальные фильмы.
Книги и материалы доступны лишь для онлайн-просмотра на сайте, возможности скачивания нет.
4. Государственная публичная историческая библиотека
Историческая библиотека предлагает электронное собрание документов и материалов по отечественной и всеобщей истории, генеалогии, геральдике, истории военного дела, этнографии и географии России.
В разделе «Коллекции» есть подборки материалов по истории Первой мировой войны, русских революций, генеалогические и биографические справочники, коллекции листовок, иллюстрированные периодические издания, газеты.
Например, коллекция газет русского зарубежья включает издания из множества стран мира на русском языке.Коллекция библиотеки доступна для онлайн-просмотра на сайте. Скачивание возможно лишь постранично в формате jpeg.
5. Электронекрасовка
Среди книг и документов, оцифрованных московской Библиотекой им. Н.А. Некрасова — издания 1610–1961 годов, уникальные коллекции книг, журналов и газет. Здесь есть подборки «О театре», «История одежды», «Детская полка», «Фотокниги», «Шрифты и типографика», «Московское метро» и множество других.
Особенно выделяется коллекция периодики: многие из этих изданий впервые стали доступны в электронном виде именно благодаря «Электронекрасовке». Все электронные документы можно и просматривать на сайте, и скачать в формате pdf.
Оцифровка культурных данных — необходимая база для цифровых гуманитарных исследований. Делимся списком крупных коллекций, созданных российскими библиотеками.
1. Национальная электронная библиотека
В разделе «Коллекции» размещены тематические подборки самых разнообразных изданий и документов. Например: «Русская классика», «Редкие и ценные издания», «Московская электронная нотная библиотека», «Собрание картографических материалов» и др.
Для книг, находящихся в общественном достоянии, доступна опция «скачать» (в формате pdf или epub). Книги, находящиеся в ограниченном доступе, можно изучать в читальных залах библиотек, подключенных к НЭБ (спросите в библиотеке по соседству — скорее всего, она подключена). С лета этого года из библиотек открылся доступ и к коллекции диссертаций.
2. Российская национальная библиотека
В разделе «Электронные коллекции» множество подборок, в том числе с редкими историческими источниками. Тут есть коллекции «Епархиальных ведомостей» и «Памятных книжек губерний Российской империи», «Аудиозаписи российского музыкального фольклора», коллекция материалов о Санкт-Петербурге, огромный массив художественной литературы.
Документы доступны для просмотра онлайн в приложении Vivaldi. Чтобы выбрать только те документы, которые можно просмотреть на сайте, отметьте в фильтре «Отображать только электронные копии».
3. Президентская библиотека
Библиотека специализируется на книгах и документах по истории российской государственности и русского языка. Среди онлайн-коллекций этой библиотеки — собрания книг, периодических изданий и архивных документов, связанные с жизнью и деятельностью крупнейших российских писателей, ученых, художников, музыкантов, государственных деятелей и многих других.
Например, в коллекции, посвященной А.П. Чехову, есть подборка его портретов и фотографий, исторические публикации, посвященные юбилейным датам, открытки с изображением памятников Чехову и т.д. А в разделе «Аудиовизуальные материалы» можно, например, посмотреть старую кинохронику или редкие документальные фильмы.
Книги и материалы доступны лишь для онлайн-просмотра на сайте, возможности скачивания нет.
4. Государственная публичная историческая библиотека
Историческая библиотека предлагает электронное собрание документов и материалов по отечественной и всеобщей истории, генеалогии, геральдике, истории военного дела, этнографии и географии России.
В разделе «Коллекции» есть подборки материалов по истории Первой мировой войны, русских революций, генеалогические и биографические справочники, коллекции листовок, иллюстрированные периодические издания, газеты.
Например, коллекция газет русского зарубежья включает издания из множества стран мира на русском языке.Коллекция библиотеки доступна для онлайн-просмотра на сайте. Скачивание возможно лишь постранично в формате jpeg.
5. Электронекрасовка
Среди книг и документов, оцифрованных московской Библиотекой им. Н.А. Некрасова — издания 1610–1961 годов, уникальные коллекции книг, журналов и газет. Здесь есть подборки «О театре», «История одежды», «Детская полка», «Фотокниги», «Шрифты и типографика», «Московское метро» и множество других.
Особенно выделяется коллекция периодики: многие из этих изданий впервые стали доступны в электронном виде именно благодаря «Электронекрасовке». Все электронные документы можно и просматривать на сайте, и скачать в формате pdf.
{kind=link}
Шпионаж и слежка 400 лет назад
Спецслужбы собирают данные огромного количества людей и делают выводы на основе не только содержания, но и метаданных. А как найти шпиона по метаданным среди 20000 корреспондентов архива писем эпохи Тюдоров, если вам лень читать архив вручную?
Письма в архиве структурированы в xml формате. Учёные отделили только те, у которых заполнены метаданные «автор» и «получатель». Многие адресаты появлялись под несколькими именами, в течение жизни накапливая титулы. Потребовалась восемнадцать месяцев, чтобы разобрать, кто есть кто. Изначальный архив содержал 37101 уникальное имя корреспондентов, в процессе выяснилось, что на самом деле переписывалось только 20656 человек.
Для поиска аномалий среди корреспондентов использовался сетевой анализ. Наиболее полезными оказались метрики степень (то есть количество людей, которые получали или отправляли письма данному человеку) и промежуточность (сколько кратчайших путей от узла к узлу проходит через данный узел). О метриках сетевого анализа мы подробно писали тут.
Наиболее интересным для исследователей оказался график, где степень узла ставится в зависимость от его промежуточности. То есть шпионов выдаёт то, что через них курсировала информация от слишком большого числа людей. Среди попавших в список лиц — миссионеры, священники, дипломаты и послы.
https://sysblok.ru/history/shpionazh-i-slezhka-400-let-nazad-i-pochemu-jeto-vazhno-znat-segodnja/
Спецслужбы собирают данные огромного количества людей и делают выводы на основе не только содержания, но и метаданных. А как найти шпиона по метаданным среди 20000 корреспондентов архива писем эпохи Тюдоров, если вам лень читать архив вручную?
Письма в архиве структурированы в xml формате. Учёные отделили только те, у которых заполнены метаданные «автор» и «получатель». Многие адресаты появлялись под несколькими именами, в течение жизни накапливая титулы. Потребовалась восемнадцать месяцев, чтобы разобрать, кто есть кто. Изначальный архив содержал 37101 уникальное имя корреспондентов, в процессе выяснилось, что на самом деле переписывалось только 20656 человек.
Для поиска аномалий среди корреспондентов использовался сетевой анализ. Наиболее полезными оказались метрики степень (то есть количество людей, которые получали или отправляли письма данному человеку) и промежуточность (сколько кратчайших путей от узла к узлу проходит через данный узел). О метриках сетевого анализа мы подробно писали тут.
Наиболее интересным для исследователей оказался график, где степень узла ставится в зависимость от его промежуточности. То есть шпионов выдаёт то, что через них курсировала информация от слишком большого числа людей. Среди попавших в список лиц — миссионеры, священники, дипломаты и послы.
https://sysblok.ru/history/shpionazh-i-slezhka-400-let-nazad-i-pochemu-jeto-vazhno-znat-segodnja/
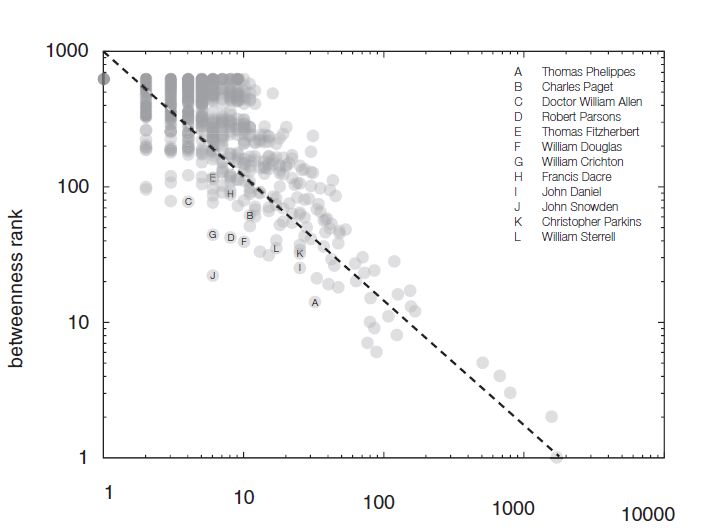{kind=link}
«Особый праздник для бритья»: из чего сделаны поздравления с 23 февраля
В прошлом году мы анализировали поздравления с 8 марта — и подтвердили свои подозрения: «женский» праздник давно превратился из дня борьбы за равные права в день приторных восхищений женственностью и сексистских пожеланий «рожать детей» и «украшать» собой жизнь.
Теперь настала очередь поздравлений с 23 февраля. Стихотворные поздравления с Днем защитника Отечества — не менее одиозный жанр, чем сексистские вирши на 8 марта или слащавые стишки на День святого Валентина. Что можно сказать о пожеланиях на 23 февраля на основе данных и количественного анализа?
Что мы исследовали
Мы собрали тексты с сайта, который выпал первым в выдаче Google по запросу «поздравление с 23 февраля». Коллекция текстов, которую мы исследовали, состоит из 903 поздравлений. Всего в них 39 518 слов — 7 196 уникальных словоформ. Мы решили изучить её традиционным для корпусных исследований способом — посчитали частотности слов.
Мы привели все слова в нашем корпусе к начальной форме. Служебные слова вроде союзов, предлогов, частиц и местоимений мы отфильтровали. Еще убрали некоторые типовые поздравительные слова (поздравлять, желать, день, праздник и т.п.).
Сильный и крепкий защитник: пожелания в цифрах
Дальше мы исследовали частотности для отдельных частей речи. Начали с прилагательных. Как помнят читатели нашего прошлогоднего 8-мартовского исследования, там лидировали прекрасный, нежный и красивый, а слова, характеризующие силу, ум и успех, оказались гораздо ниже.
С поздравлениями на 23 февраля ситуация иная — здесь доминирует именно сила. Прилагательное сильный лидирует с большим отрывом. Также в топ-5 хороший, смелый, любимый и крепкий. Кажется, это неудивительно, учитывая военное происхождение праздника и невытравимую идею разделения полов на «сильный» и «слабый».
В списке частотных глаголов лидер тоже предсказуем — это глагол защищать. За ним с большим отрывом следуют жить, любить, ждать и хранить. В общем, День защитника Отечества — это про защиту и силу, и только потом — про любовь. «Военно-патриотическую» тематику отражают и другие глаголы в этом топе: служить, хранить. Симптоматично появление глагола ждать: идея ожидания человека, призванного на службу/войну, безусловно, одна из стержневых в русской околовоенной лирике («Жди меня», «Темная ночь» и мн. др.) и литературе в целом.
«Воевать за монитором желаю счастья»
Мы решили посмотреть, возможно ли получить по-настоящему душевные пожелания на такой коллекции слов, и сгенерировали свой текст на основе исходных данных. Для генерации мы использовали самый простой способ — цепи Маркова.
Из результатов генерации мы собрали свою подборку поздравлений с 23 февраля. Ведь, в конце концов, люди ищут «оригинальные» поздравления — а что может быть оригинальнее, чем текст, синтезированный только что на наших глазах? Вот несколько примеров:
Поздравляю тебя через край.
Будь отважным героем для успеха, любви и взаимной любви.
Воевать за монитором, желаю счастья.
Пусть ВБР будет полна любовью!
В феврале особый праздник для бритья,
Февральский ветер лишь преследует тебя.
Познакомиться с остальными результатами генерации, изучить графики частотностей слов, а также посмотреть на любопытные примеры народной поздравительной поэзии вы можете по ссылке:
https://sysblok.ru/society/eshhe-muzhchinestee-byt-iz-chego-sdelany-pozdravlenija-s-23-fevralja/
В прошлом году мы анализировали поздравления с 8 марта — и подтвердили свои подозрения: «женский» праздник давно превратился из дня борьбы за равные права в день приторных восхищений женственностью и сексистских пожеланий «рожать детей» и «украшать» собой жизнь.
Теперь настала очередь поздравлений с 23 февраля. Стихотворные поздравления с Днем защитника Отечества — не менее одиозный жанр, чем сексистские вирши на 8 марта или слащавые стишки на День святого Валентина. Что можно сказать о пожеланиях на 23 февраля на основе данных и количественного анализа?
Что мы исследовали
Мы собрали тексты с сайта, который выпал первым в выдаче Google по запросу «поздравление с 23 февраля». Коллекция текстов, которую мы исследовали, состоит из 903 поздравлений. Всего в них 39 518 слов — 7 196 уникальных словоформ. Мы решили изучить её традиционным для корпусных исследований способом — посчитали частотности слов.
Мы привели все слова в нашем корпусе к начальной форме. Служебные слова вроде союзов, предлогов, частиц и местоимений мы отфильтровали. Еще убрали некоторые типовые поздравительные слова (поздравлять, желать, день, праздник и т.п.).
Сильный и крепкий защитник: пожелания в цифрах
Дальше мы исследовали частотности для отдельных частей речи. Начали с прилагательных. Как помнят читатели нашего прошлогоднего 8-мартовского исследования, там лидировали прекрасный, нежный и красивый, а слова, характеризующие силу, ум и успех, оказались гораздо ниже.
С поздравлениями на 23 февраля ситуация иная — здесь доминирует именно сила. Прилагательное сильный лидирует с большим отрывом. Также в топ-5 хороший, смелый, любимый и крепкий. Кажется, это неудивительно, учитывая военное происхождение праздника и невытравимую идею разделения полов на «сильный» и «слабый».
В списке частотных глаголов лидер тоже предсказуем — это глагол защищать. За ним с большим отрывом следуют жить, любить, ждать и хранить. В общем, День защитника Отечества — это про защиту и силу, и только потом — про любовь. «Военно-патриотическую» тематику отражают и другие глаголы в этом топе: служить, хранить. Симптоматично появление глагола ждать: идея ожидания человека, призванного на службу/войну, безусловно, одна из стержневых в русской околовоенной лирике («Жди меня», «Темная ночь» и мн. др.) и литературе в целом.
«Воевать за монитором желаю счастья»
Мы решили посмотреть, возможно ли получить по-настоящему душевные пожелания на такой коллекции слов, и сгенерировали свой текст на основе исходных данных. Для генерации мы использовали самый простой способ — цепи Маркова.
Из результатов генерации мы собрали свою подборку поздравлений с 23 февраля. Ведь, в конце концов, люди ищут «оригинальные» поздравления — а что может быть оригинальнее, чем текст, синтезированный только что на наших глазах? Вот несколько примеров:
Поздравляю тебя через край.
Будь отважным героем для успеха, любви и взаимной любви.
Воевать за монитором, желаю счастья.
Пусть ВБР будет полна любовью!
В феврале особый праздник для бритья,
Февральский ветер лишь преследует тебя.
Познакомиться с остальными результатами генерации, изучить графики частотностей слов, а также посмотреть на любопытные примеры народной поздравительной поэзии вы можете по ссылке:
https://sysblok.ru/society/eshhe-muzhchinestee-byt-iz-chego-sdelany-pozdravlenija-s-23-fevralja/
{kind=link}
Берлинале-2020 глазами российских и американских критиков
#arts #visualisation
29 февраля завершился 70-й Берлинский кинофестиваль. Программа вышла разнообразная — здесь и вызвавший этические споры в Берлине «Дау. Наташа», и новое переложение культового немецкого романа «Берлин, Александерплац» из 1920-х в контекст современной Европы, и многое другое. Иранская лента об ужасах тоталитарного режима «Зла не существует» получила в этом году главный приз — Золотого Медведя.
Вместе с журналом «Искусство Кино» @kinoartru «Системный Блокъ» подготовил инфографику с оценками фильмов конкурсной программы фестиваля. Мы использовали оценки российских критиков, собранные на сайте Искусства Кино, и Tomatometer — совокупный рейтинг сайта Rotten Tomatoes, составленный на основе отзывов американских критиков. Российские критики оценивали ленты по пятибалльной шкале, далее считалась средняя оценка для каждого фильма. Tomatometer представлен в виде оценки по стобалльной шкале, поэтому мы перевели её в пятибалльную шкалу для более удобного сравнения: например, у фильма «Первая корова» Tomatometer равен 91 из 100, т.е. (91/100) * 5 = 4,6 из 5.
Интересно, что российские критики оценили фильм-победитель Берлинале довольно сдержанно — на 3 балла. Американские критики и вовсе не уделяют ему должного внимания — рейтинг для этого фильма пока не доступен, как и ещё для пяти фильмов-участников (он становится видимым только после того, как ленту оценят хотя бы 5 экспертов).
Наибольший разрыв между оценками российских и американских критиков наблюдается у фильма «Чужак» («The Intruder») — средняя оценка российских кинокритиков составила всего 2,2 балла, в то время как рейтинг их американских коллег составил 3,8 балла (75 из 100). А вот оценка фильма «DAU. Наташа» Ильи Хржановского от российских критиков оказалась на полбалла выше, чем оценка американских — и это наибольший разрыв в обратную сторону.
Данные
1. Оценки фильмов, данные российскими критиками
2. Рейтинг фильмов с сайта Rotten Tomatoes
#arts #visualisation
29 февраля завершился 70-й Берлинский кинофестиваль. Программа вышла разнообразная — здесь и вызвавший этические споры в Берлине «Дау. Наташа», и новое переложение культового немецкого романа «Берлин, Александерплац» из 1920-х в контекст современной Европы, и многое другое. Иранская лента об ужасах тоталитарного режима «Зла не существует» получила в этом году главный приз — Золотого Медведя.
Вместе с журналом «Искусство Кино» @kinoartru «Системный Блокъ» подготовил инфографику с оценками фильмов конкурсной программы фестиваля. Мы использовали оценки российских критиков, собранные на сайте Искусства Кино, и Tomatometer — совокупный рейтинг сайта Rotten Tomatoes, составленный на основе отзывов американских критиков. Российские критики оценивали ленты по пятибалльной шкале, далее считалась средняя оценка для каждого фильма. Tomatometer представлен в виде оценки по стобалльной шкале, поэтому мы перевели её в пятибалльную шкалу для более удобного сравнения: например, у фильма «Первая корова» Tomatometer равен 91 из 100, т.е. (91/100) * 5 = 4,6 из 5.
Интересно, что российские критики оценили фильм-победитель Берлинале довольно сдержанно — на 3 балла. Американские критики и вовсе не уделяют ему должного внимания — рейтинг для этого фильма пока не доступен, как и ещё для пяти фильмов-участников (он становится видимым только после того, как ленту оценят хотя бы 5 экспертов).
Наибольший разрыв между оценками российских и американских критиков наблюдается у фильма «Чужак» («The Intruder») — средняя оценка российских кинокритиков составила всего 2,2 балла, в то время как рейтинг их американских коллег составил 3,8 балла (75 из 100). А вот оценка фильма «DAU. Наташа» Ильи Хржановского от российских критиков оказалась на полбалла выше, чем оценка американских — и это наибольший разрыв в обратную сторону.
Данные
1. Оценки фильмов, данные российскими критиками
2. Рейтинг фильмов с сайта Rotten Tomatoes
{kind=link}