
PixelPlayer: нейросеть научили раскладывать музыку на партии
PixelPlayer — система, разработанная учеными из Массачусетского технологического института (MIT). Она способна выделять из видеозаписи партии отдельных музыкальных инструментов. Предыдущие разработки по выделению отдельных партий требовали аудиозаписей с ручной разметкой, в то время как PixelPlayer работает с неподготовленным видео.
Разработчики PixelPlayer видят потенциал в изучении синхронизации между зрением и слухом. Поэтому система задействует три алгоритма: для обработки видеоряда, аудиодорожки и для объединения первого со вторым. Необычно, что PixelPlayer определяет звук, относящийся к каждому из сегментов картинки.
На сайте разработки есть интерактивное демо. Там можно понажимать на разные сегменты видео и послушать, как они звучат (или не звучат).
Видео, демонстрирующее возможности PixelPlayer:
https://youtu.be/2eVDLEQlKD0
PixelPlayer — система, разработанная учеными из Массачусетского технологического института (MIT). Она способна выделять из видеозаписи партии отдельных музыкальных инструментов. Предыдущие разработки по выделению отдельных партий требовали аудиозаписей с ручной разметкой, в то время как PixelPlayer работает с неподготовленным видео.
Разработчики PixelPlayer видят потенциал в изучении синхронизации между зрением и слухом. Поэтому система задействует три алгоритма: для обработки видеоряда, аудиодорожки и для объединения первого со вторым. Необычно, что PixelPlayer определяет звук, относящийся к каждому из сегментов картинки.
На сайте разработки есть интерактивное демо. Там можно понажимать на разные сегменты видео и послушать, как они звучат (или не звучат).
Видео, демонстрирующее возможности PixelPlayer:
https://youtu.be/2eVDLEQlKD0
YouTube
Editing Music in Videos Using AI
Paper: https://arxiv.org/abs/1804.03160
More info: http://sound-of-pixels.csail.mit.edu/
http://news.mit.edu/2018/ai-editing-music-videos-pixelplayer-csail-0705
More info: http://sound-of-pixels.csail.mit.edu/
http://news.mit.edu/2018/ai-editing-music-videos-pixelplayer-csail-0705
11 лет назад, 19 февраля 2008 года умер Егор Летов. Даже если вы не знакомы с его песнями, в вашей жизни точно была компания (и не одна!), назойливо распевающая «Все идет по плану», а мозг исправно подсказывает, что после «ооо» следует «моя оборона».
Противоречивые тексты Летова становятся темой научных статей, их орут во дворах, по ним защищают диссертации и пишут на заборе; они остаются современными и сейчас.
В честь годовщины смерти главного поэта русского панка мы подготовили небольшое корпусное исследование по его текстам и визуализировали самые интересные находки.
https://telegra.ph/Novyj-mertvyj-horoshij-vizualizaciya-tekstov-Grazhdanskoj-Oborony-02-19
Противоречивые тексты Летова становятся темой научных статей, их орут во дворах, по ним защищают диссертации и пишут на заборе; они остаются современными и сейчас.
В честь годовщины смерти главного поэта русского панка мы подготовили небольшое корпусное исследование по его текстам и визуализировали самые интересные находки.
https://telegra.ph/Novyj-mertvyj-horoshij-vizualizaciya-tekstov-Grazhdanskoj-Oborony-02-19
Telegraph
Новый, мертвый, хороший: визуализация текстов «Гражданской Обороны»
19 февраля 2008 года умер Егор Летов — и «не было никого, кто бы это опроверг». Даже если вы не знакомы с его песнями, в вашей жизни точно была компания (и не одна!), назойливо распевающая «Все идет по плану», а мозг исправно подсказывает, что после «ооо»…
Нейросеть-композитор учится у Баха, Бетховена и Шопена
Команда из Университета Дьюка создает музыкальные произведения, обучая алгоритмы на сочинениях композиторов-классиков.
Сама идея сочинения музыки автоматическим способом, с минимальным участием человека, имеет долгую историю. Сохранились сведения об игре «Музыкальные кости», существовавшей в XVIII веке. Участники брали небольшие музыкальные фрагменты и комбинировали их в порядке, который указывали брошенные на стол игральные кости. Первым же музыкальным произведением, полностью сочиненным компьютером, является «Illiac Suite» (1955-1956).
С тех пор исследователи опробовали множество вероятностных моделей и обучаемых алгоритмов для автоматизированного создания музыки.
Ученые из Университета Дьюка исследуют возможности использования для создания музыки вероятностных моделей временных рядов (в частности, скрытых марковских моделей и изменяющихся во времени авторегрессионных моделей) для алгоритмического создания музыки в стиле фортепианных произведений эпохи Романтизма.
Сочинения получаются вполне благозвучные. Однако ученые признаются, что пока не смогли «объяснить» машине-композитору законы развития мелодии.
Самый лучший результат выходит, если основывать обучение на музыкальных произведениях, состоящих преимущественно из консонантных интервалов. Таких, как, например, «Ода к радости» Бетховена или Канон Пахельбеля.
В «Яндексе» последовали примеру американских ученых и на днях объявили о созданной с помощью нейросети пьесе для альта с оркестром, которую 24 февраля, на закрытии Зимнего международного фестиваля искусств в Сочи, исполнил оркестр «Новая Россия». Однако искусственный интеллект сгенерировал лишь фортепианные партии, а превратил творение машины в полноценное музыкальное произведение и сделал его оркестровку уже человек — композитор Кузьма Бодров.
Больше примеров и подробности о том, как это работает — здесь.
Команда из Университета Дьюка создает музыкальные произведения, обучая алгоритмы на сочинениях композиторов-классиков.
Сама идея сочинения музыки автоматическим способом, с минимальным участием человека, имеет долгую историю. Сохранились сведения об игре «Музыкальные кости», существовавшей в XVIII веке. Участники брали небольшие музыкальные фрагменты и комбинировали их в порядке, который указывали брошенные на стол игральные кости. Первым же музыкальным произведением, полностью сочиненным компьютером, является «Illiac Suite» (1955-1956).
С тех пор исследователи опробовали множество вероятностных моделей и обучаемых алгоритмов для автоматизированного создания музыки.
Ученые из Университета Дьюка исследуют возможности использования для создания музыки вероятностных моделей временных рядов (в частности, скрытых марковских моделей и изменяющихся во времени авторегрессионных моделей) для алгоритмического создания музыки в стиле фортепианных произведений эпохи Романтизма.
Сочинения получаются вполне благозвучные. Однако ученые признаются, что пока не смогли «объяснить» машине-композитору законы развития мелодии.
Самый лучший результат выходит, если основывать обучение на музыкальных произведениях, состоящих преимущественно из консонантных интервалов. Таких, как, например, «Ода к радости» Бетховена или Канон Пахельбеля.
В «Яндексе» последовали примеру американских ученых и на днях объявили о созданной с помощью нейросети пьесе для альта с оркестром, которую 24 февраля, на закрытии Зимнего международного фестиваля искусств в Сочи, исполнил оркестр «Новая Россия». Однако искусственный интеллект сгенерировал лишь фортепианные партии, а превратил творение машины в полноценное музыкальное произведение и сделал его оркестровку уже человек — композитор Кузьма Бодров.
Больше примеров и подробности о том, как это работает — здесь.
YouTube
Lejaren Hiller - Illiac Suite for String Quartet [1/4]
The Illiac Suite is the first musical composition for traditional instruments that was made through computer by Lejaren Hiller and Leonard Isaacson. More inf...
Проработанная историческая обстановка — одна из причин любви критиков и фанатов к видеоиграм Assassin’s Creed. Действие Assassin’s Creed: Origins происходит в эллинистическом Египте; чтобы точно воссоздать эпоху, разработчики игры из Ubisoft обратились к египтологам.
В ходе совместной работы авторы задумались, насколько долгим и трудоемким до сих пор остается процесс перевода древнеегипетского языка. Так появилась идея проекта The Hieroglyphics Initiative — машинного переводчика египетских иероглифов. И фанаты Assassin’s Creed за одну ночь помогли собрать материал для его обучения!
https://telegra.ph/Kak-gejmery-drevneegipetskoe-pismo-rasshifrovyvali-03-03
В ходе совместной работы авторы задумались, насколько долгим и трудоемким до сих пор остается процесс перевода древнеегипетского языка. Так появилась идея проекта The Hieroglyphics Initiative — машинного переводчика египетских иероглифов. И фанаты Assassin’s Creed за одну ночь помогли собрать материал для его обучения!
https://telegra.ph/Kak-gejmery-drevneegipetskoe-pismo-rasshifrovyvali-03-03
Telegraph
Как геймеры древнеегипетское письмо расшифровывали
Поклонники Assassin’s Creed всегда требовательно относились к целостности игрового мира. Проработанная историческая обстановка — одна из причин любви критиков и фанатов к франшизе. Изучать древнюю историю по играм серии, конечно, не получится, но реалистичные…
Спасение утопающих ученых
Статьи в научных журналах — главный продукт современного ученого. Ежегодно исследователи производят около миллиона публикаций. Навигация в этом огромном информационном потоке остается нерешенной задачей. Одна из ключевых проблем — содержание научных статей трудно индексировать для электронного поиска. Мощным подспорьем здесь могут послужить алгоритмы машинного обучения (ML) и обработка естественного языка (NLP).
Уже сейчас существуют системы поиска, позволяющие находить в огромных массивах данных не просто ключевые слова, а скрытые взаимосвязи, и ранжировать результаты по релевантности. Увы, пока семантический анализ в системах поиска далек от идеального. Использование алгоритмов машинного обучения и NLP позволит улучшить качество поиска научных статей и существенно упростит работу.
Стартапы, внедряющие семантический поиск по научным статьям, уже существуют — например, Semantic Scholar. Многие из них предоставляют сервисы поиска близких по смыслу статей на основе ключевых слов, краткой аннотации (абстракта) или ссылки на документ. Получив их, такой поисковик возвращает близкие или смежные статьи в виде сети.
Близость статей передают через силу (вес) связей в получившейся сети. Так пользователь может увидеть на группы наиболее схожих статей в виде плотных клубков.
Еще научный поисковик может использовать рекомендательную систему, как в Amazon или Netflix. Статьи, которые понравились пользователю А, могут рекомендовать пользователю B, у которого схожие научные предпочтения.
В биомедицине поисковики пытаются искать не только по текстам, но и по изображениям. Однако результаты их анализа всё ещё требуют проверки человеком — алгоритмы компьютерного зрения не дают стопроцентной точности.
Ксения Михайлова
Статьи в научных журналах — главный продукт современного ученого. Ежегодно исследователи производят около миллиона публикаций. Навигация в этом огромном информационном потоке остается нерешенной задачей. Одна из ключевых проблем — содержание научных статей трудно индексировать для электронного поиска. Мощным подспорьем здесь могут послужить алгоритмы машинного обучения (ML) и обработка естественного языка (NLP).
Уже сейчас существуют системы поиска, позволяющие находить в огромных массивах данных не просто ключевые слова, а скрытые взаимосвязи, и ранжировать результаты по релевантности. Увы, пока семантический анализ в системах поиска далек от идеального. Использование алгоритмов машинного обучения и NLP позволит улучшить качество поиска научных статей и существенно упростит работу.
Стартапы, внедряющие семантический поиск по научным статьям, уже существуют — например, Semantic Scholar. Многие из них предоставляют сервисы поиска близких по смыслу статей на основе ключевых слов, краткой аннотации (абстракта) или ссылки на документ. Получив их, такой поисковик возвращает близкие или смежные статьи в виде сети.
Близость статей передают через силу (вес) связей в получившейся сети. Так пользователь может увидеть на группы наиболее схожих статей в виде плотных клубков.
Еще научный поисковик может использовать рекомендательную систему, как в Amazon или Netflix. Статьи, которые понравились пользователю А, могут рекомендовать пользователю B, у которого схожие научные предпочтения.
В биомедицине поисковики пытаются искать не только по текстам, но и по изображениям. Однако результаты их анализа всё ещё требуют проверки человеком — алгоритмы компьютерного зрения не дают стопроцентной точности.
Ксения Михайлова
{kind=link}
Большинство из наших читателей наверняка слышали про языковые корпуса: Британский национальный корпус (BNC), Корпус языка Пушкина, Национальный корпус русского языка (НКРЯ) с его подкорпусами — газетным, поэтическим, диалектным, историческим...
Но иногда лингвистам для исследований нужны совершенно нестандартные коллекции текстов, и сегодня мы рассказываем о таких необычных корпусах — от рассказов о грушах до учебников русского языка.
https://telegra.ph/Pomedlennee-ya-zapisyvayu-03-03
Но иногда лингвистам для исследований нужны совершенно нестандартные коллекции текстов, и сегодня мы рассказываем о таких необычных корпусах — от рассказов о грушах до учебников русского языка.
https://telegra.ph/Pomedlennee-ya-zapisyvayu-03-03
Telegraph
Помедленнее, я записываю
Классифицируют ошибки, просят рассказать о грушах, считают частотность матерных слов… порой для исследования лингвистам нужны нестандартные коллекции текстов. Подборка из 5 неординарных корпусов русского языка в вашу лингвистическую копилку. 1. Один речевой…
Как поздравляют российских женщин? Изучаем корпус поздравлений с 8 марта — и генерируем собственные с помощью марковской цепи!
СПОЙЛЕР: в процессе изучения этих текстов у нас взорвались три стереотипометра и еще кое-что полыхнуло.
https://telegra.ph/Smejtes-i-detej-rozhajte-iz-chego-sdelany-pozdravleniya-s-8-marta-03-08
СПОЙЛЕР: в процессе изучения этих текстов у нас взорвались три стереотипометра и еще кое-что полыхнуло.
https://telegra.ph/Smejtes-i-detej-rozhajte-iz-chego-sdelany-pozdravleniya-s-8-marta-03-08
Telegraph
Смейтесь и детей рожайте: из чего сделаны поздравления с 8 марта
Международный день борьбы женщин за свои права превратился в «цветочный день почитания прекрасных дам». Ничего не говорит об этом красноречивее текстов поздравлений: девушкам желают цветов, конфет, «обходительных мужчин», просят «поражать своим совершенством»…
Долгое время лингвистика входила в число классических гуманитарных наук, но все изменилось с появлением работ Фердинанда де Соссюра и его последователей-структуралистов в начале XX в. Именно благодаря ним в 40-50-х гг. лингвистика привлекла внимание математиков и инженеров, что повлекло за собой рождение новой дисциплины — компьютерной лингвистики.
Несмотря на то, что компьютерная лингвистика считается относительно молодой наукой, современному человеку уже сложно представить свою жизнь без существования голосовых помощников, эффективных веб-поисковиков или автоматических переводчиков.
Рассказываем о развитии дружбы лингвистики с точными науками: https://telegra.ph/Kak-lingvistika-stala-blizkoj-podrugoj-matematiki-i-informatiki-03-03
Несмотря на то, что компьютерная лингвистика считается относительно молодой наукой, современному человеку уже сложно представить свою жизнь без существования голосовых помощников, эффективных веб-поисковиков или автоматических переводчиков.
Рассказываем о развитии дружбы лингвистики с точными науками: https://telegra.ph/Kak-lingvistika-stala-blizkoj-podrugoj-matematiki-i-informatiki-03-03
Telegraph
Как лингвистика стала близкой подругой математики и информатики?
Системные преобразования Лингвистика — это наука, которая изучает устную и письменную формы человеческого языка, его структуру, элементы, его связь с другими науками. Современная лингвистика имеет два подхода к изучению: синхронический и диахронический. Изначально…
Сторителлинг — исскусство рассказывать истории — существует уже не одно тысячелетие. Как оно трансформировалрсь в век цифровых технологий? Каким образом вписать статистику в увлекательный сюжет? Какую роль в data-сторителлинге играет визуализация? Об этом — наша сегодняшняя статья.
https://telegra.ph/Data-storitelling-dannye-govoryat-sami-za-sebya-12-23
https://telegra.ph/Data-storitelling-dannye-govoryat-sami-za-sebya-12-23
Telegraph
Data-сторителлинг: данные говорят сами за себя
Сторителлинг — это рассказ качественных, запоминающихся историй. В сторителлинге нет ничего нового — люди рассказывают истории с древности. Для улучшения восприятия человеческий мозг кодирует все окружающие объекты в образы, поэтому мы так хорошо и запоминаем…
Исследователи из Стэнфордского университета решили проверить, как выглядят эмоции из литературных произведений, если их перенести на карту города, и провели количественный анализ английских романов XVIII и XIX века, события которых происходят в Лондоне.
Знакомим вас с нарративной географией и рассказываем, какие технологии использовались в исследовании, в какой части Лондона герои счастливее и как это меняется со временем.
https://telegra.ph/Strah-i-schaste-v-Londone-geografiya-ehmocij-03-11
Знакомим вас с нарративной географией и рассказываем, какие технологии использовались в исследовании, в какой части Лондона герои счастливее и как это меняется со временем.
https://telegra.ph/Strah-i-schaste-v-Londone-geografiya-ehmocij-03-11
Telegraph
Страх и счастье в Лондоне: география эмоций
Как связать географию и эмоции Исследователи Райан Хэйзер, Франко Моретти и Эрик Штайнер из Стэнфордского университета решили проверить, как выглядят эмоции из литературных произведений, если их перенести на карту города. Был проведен количественный анализ…
Как лайки влияют на наш мозг
Лайки появились совсем недавно, но уже стали неотъемлемой чертой общения в сети. Раньше психологи, антропологи и социологи пытались разобраться в сути явления с помощью опросов или других косвенных методов. Сегодня ученые получили возможность заглянуть прямо в мозг — как он воспринимает лайки, как видоизменяются и адаптируются сформировавшиеся в течение долгого времени механизмы к новому феномену социальной жизни.
Функциональная магнитно-резонансная томография (фМРТ) позволяет с высоким пространственным разрешением оценить активность разных участков головного мозга во время выполнения разных дел, в том числе в процессе общения. Сложно вести светскую беседу, находясь внутри МРТ-сканнера, но при изучении коммуникации в социальных сетях сегодня можно обойтись и без собеседника.
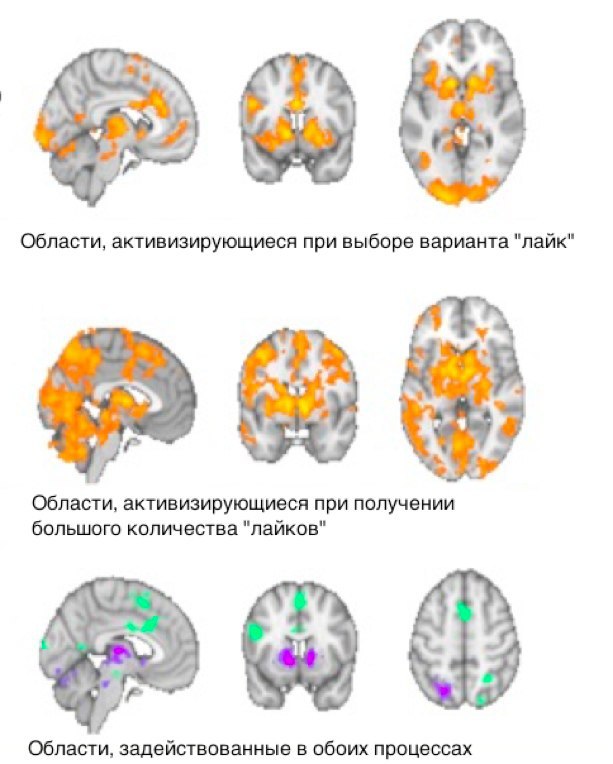
В ходе эксперимента 58 участникам предъявлялись фотографии из Инстаграма: собственные снимки и фото других участников. После просмотра каждой фотографии можно было нажатием кнопки обозначить лайк или просто переключиться на новую фотографию. Все это время регистрировалась активность мозга. Далее участникам предъявлялись их собственные фотографии из соцсетей с уже проставленными лайками от других людей.
Так исследователи выделили зоны мозга, активирующиеся только в тех случаях, когда человек лайкал фотографию, и области, активность которых проявляется при просмотре собственной фотографии с большим количеством лайков.
После наложения картинок исследователи выделили области мозга, задействованные в обоих случаях:
На сегодня в мозге человека достаточно хорошо изучена система «вознаграждения» (reward system) — в первую очередь в ходе экспериментов в сфере нейроэкономики. В таких экспериментах обычно моделируются ситуации с выигрышем или потерей денежных средств и регистрируется активность мозга в случае удачи.
Так же существует пул исследований, посвященных изучению эмоционального отклика в мозге человека в момент возникновения положительных эмоций в ходе общения с другими людьми. Одно из важнейших отличий в этих двух ситуациях: «исчисляемость» реакции в случае с деньгами, возможность выделить отдельные «кванты». В ходе общения гораздо сложнее выделить какой-то единый эквивалент и лайки как раз позволяют это сделать.
Исследователи сравнили активность мозга в эксперименте с результатами предыдущих исследований и оказалось, что задействованы обе системы.
Получается, наш мозг вполне всерьез воспринимает лайки. Это помогает объяснить, почему мы постоянно обновляем страницы социальных сетей и смотрим, как изменяется заветное число под фотографией или постом.
Ирина Зябрева
Лайки появились совсем недавно, но уже стали неотъемлемой чертой общения в сети. Раньше психологи, антропологи и социологи пытались разобраться в сути явления с помощью опросов или других косвенных методов. Сегодня ученые получили возможность заглянуть прямо в мозг — как он воспринимает лайки, как видоизменяются и адаптируются сформировавшиеся в течение долгого времени механизмы к новому феномену социальной жизни.
Функциональная магнитно-резонансная томография (фМРТ) позволяет с высоким пространственным разрешением оценить активность разных участков головного мозга во время выполнения разных дел, в том числе в процессе общения. Сложно вести светскую беседу, находясь внутри МРТ-сканнера, но при изучении коммуникации в социальных сетях сегодня можно обойтись и без собеседника.
В ходе эксперимента 58 участникам предъявлялись фотографии из Инстаграма: собственные снимки и фото других участников. После просмотра каждой фотографии можно было нажатием кнопки обозначить лайк или просто переключиться на новую фотографию. Все это время регистрировалась активность мозга. Далее участникам предъявлялись их собственные фотографии из соцсетей с уже проставленными лайками от других людей.
Так исследователи выделили зоны мозга, активирующиеся только в тех случаях, когда человек лайкал фотографию, и области, активность которых проявляется при просмотре собственной фотографии с большим количеством лайков.
После наложения картинок исследователи выделили области мозга, задействованные в обоих случаях:
На сегодня в мозге человека достаточно хорошо изучена система «вознаграждения» (reward system) — в первую очередь в ходе экспериментов в сфере нейроэкономики. В таких экспериментах обычно моделируются ситуации с выигрышем или потерей денежных средств и регистрируется активность мозга в случае удачи.
Так же существует пул исследований, посвященных изучению эмоционального отклика в мозге человека в момент возникновения положительных эмоций в ходе общения с другими людьми. Одно из важнейших отличий в этих двух ситуациях: «исчисляемость» реакции в случае с деньгами, возможность выделить отдельные «кванты». В ходе общения гораздо сложнее выделить какой-то единый эквивалент и лайки как раз позволяют это сделать.
Исследователи сравнили активность мозга в эксперименте с результатами предыдущих исследований и оказалось, что задействованы обе системы.
Получается, наш мозг вполне всерьез воспринимает лайки. Это помогает объяснить, почему мы постоянно обновляем страницы социальных сетей и смотрим, как изменяется заветное число под фотографией или постом.
Ирина Зябрева
{kind=link}
Мы перешли к системе, в которой компьютеры все меньше контролируются человеком. Вместо того чтобы вручную писать алгоритмы, управляющие поведением компьютера, мы часто просим машину написать свои собственные инструкции — на основе имеющегося опыта и некоторой модели проблемы, которую нужно решить. Это называется машинным обучением.
Гуманитарии могут внести вклад в этот образовательный проект, потому что они уже знакомы с одной из главных задач машинного обучения — поиском закономерностей в изменчивом человеческом поведении.
Гуманитарные науки несут в себе разумный скептицизм и критическое отношение к количественным данным и подходам.
Однако скептицизм — не единственное, что могут предложить гуманитарии. Они могут показать, что проблема не в только машинном обучении или алгоритмах, но в самом сложной и непредсказуемой сущности человека, культуры и общества. Сотрудничая с технарями и вдумчиво анализируя количественные модели, гуманитарные исследователи могут действительно приблизить людей к пониманию того, как функционируют сложные механизмы культуры.
https://telegra.ph/Zachem-nuzhny-gumanitarii-v-ehpohu-mashinnogo-obucheniya-03-28
Гуманитарии могут внести вклад в этот образовательный проект, потому что они уже знакомы с одной из главных задач машинного обучения — поиском закономерностей в изменчивом человеческом поведении.
Гуманитарные науки несут в себе разумный скептицизм и критическое отношение к количественным данным и подходам.
Однако скептицизм — не единственное, что могут предложить гуманитарии. Они могут показать, что проблема не в только машинном обучении или алгоритмах, но в самом сложной и непредсказуемой сущности человека, культуры и общества. Сотрудничая с технарями и вдумчиво анализируя количественные модели, гуманитарные исследователи могут действительно приблизить людей к пониманию того, как функционируют сложные механизмы культуры.
https://telegra.ph/Zachem-nuzhny-gumanitarii-v-ehpohu-mashinnogo-obucheniya-03-28
Telegraph
Зачем нужны гуманитарии в эпоху машинного обучения?
В наше время нелегко быть сознательным гражданином. Нам говорят, что нужно быть осторожными с поисковыми системами, но и недоверие к медиа тоже может сделать нас легкой добычей для пропаганды. Дональд Трамп, например, объявляет любую критику в свой адрес…
Наблюдать за появлением нового языка в XXI веке — редкая возможность, и у нас она есть! В октябре 2011 года Apple добавила emoji как международную клавиатуру. С тех пор цифровой язык развился настолько, что сейчас половина комментариев и хэштегов в Instagram содержат эмодзи.
А если у смайликов есть своя клавиатура, значит это фактически новый искусственный язык, и, применяя методы машинного обучения и обработки естественного языка, можно понаблюдать за его семантикой и обнаружить любопытные скрытые закономерности. 😎💻💡
https://telegra.ph/CHto-v-smajlike-tebe-moem-03-30
А если у смайликов есть своя клавиатура, значит это фактически новый искусственный язык, и, применяя методы машинного обучения и обработки естественного языка, можно понаблюдать за его семантикой и обнаружить любопытные скрытые закономерности. 😎💻💡
https://telegra.ph/CHto-v-smajlike-tebe-moem-03-30
Telegraph
Что в смайлике тебе моем?
Наблюдать за появлением нового языка в двадцать первом веке — редкая возможность, и у нас она есть! В октябре 2011 года Apple добавила emoji как международную клавиатуру. С тех пор цифровой язык развился настолько, что сейчас половина комментариев и хэштегов…
«Системный Блокъ» запускает новую рубрику — интервью с учеными! Мы будем общаться с деятелями науки, искусства и культуры о роли цифровых и точных методов в их областях.
Наше первое интервью — с лингвистом и популяризатором науки Александром Пиперски.
https://sysblok.ru/interviews/cifra-na-sluzhbe-u-filologa/
Наше первое интервью — с лингвистом и популяризатором науки Александром Пиперски.
https://sysblok.ru/interviews/cifra-na-sluzhbe-u-filologa/
Системный Блокъ
Цифра на службе у филолога - Системный Блокъ
“Гумилёва считали?”: лингвист и популяризатор Александр Пиперски рассказывает, как открыл для себя количественные методы, что из этого получилось и зачем они нужны филологу-исследователю
В честь Дня космонавтики рассказываем о прекрасном образце data-сторителлинга — арт-проекте «Мы верим в космос».
https://telegra.ph/Prosto-kosmos-04-12
https://telegra.ph/Prosto-kosmos-04-12
Telegraph
Просто космос!
58 лет назад 12 апреля человек впервые полетел в космос. Но помимо этого события в истории изучения внеземного пространства много важных достижений — от первого искусственного спутника до орбитальной обсерватории, от посадки на Луну до фотоснимков Плутона.…
Первого мая режиссер и волшебник Уэс Андерсон отметил пятидесятилетний юбилей. Узнать фильм Уэса Андерсона несложно: идеально симметричные кадры, теплая палитра, удивительные детали, странные костюмы… Не кино, а иллюстрированная книга — даже главы есть. Этот «кукольный» сеттинг позволяет без страха поднимать болезненные вопросы: о семейных проблемах, поиске места в жизни, одиночестве, смерти.
К юбилею режиссера мы перечитали фильмографию Уэса Андерсона и cделали визуализацию субтитров полнометражных лент. Так, как ее сделал бы Уэс, конечно!
https://sysblok.ru/visual/o-chem-govorjat-geroi-filmov-ujesa-andersona/
К юбилею режиссера мы перечитали фильмографию Уэса Андерсона и cделали визуализацию субтитров полнометражных лент. Так, как ее сделал бы Уэс, конечно!
https://sysblok.ru/visual/o-chem-govorjat-geroi-filmov-ujesa-andersona/
Системный Блокъ
О чем говорят герои фильмов Уэса Андерсона? - Системный Блокъ
Первого мая режиссер и волшебник Уэс Андерсон отмечает пятидесятилетний юбилей. Перечитываем его фильмографию и делаем визуализацию. Так, как ее сделал бы Уэс, конечно!
Всю весну кипит битва вокруг статьи The Computational Case against Computational Literary Studies. ⚡️⚡️⚡️ Автор статьи всерьез замахнулась на «закрытие» цифровой филологии как научного направления. Отдельно в этой статье досталось исследователям гендера в литературе ♀♂📚. Мол компьютерные литературоведы так любят гендер только потому, что он дает им легкое и однозначное разделение на две понятные категории, которые потом можно статистически сравнивать.
Нам кажется, что автор передергивает. Цифровые исследования репрезентации мужчин и женщин в художественных текстах — не дань моде или удобству. Они могут дать объективные сведения не только о том, как устроена литература, но и о том, как в культуре отражены гендерные стереотипы и общественные процессы. А главное — как это все эволюционирует и куда движется.
Пример такого исследования — работа о трансформации гендера в англоязычной литературе от Теда Андервуда, Дэвида Баммана и Сабрины Ли. На материале 104 тысяч книг они показывают, например, как изображение гендера становится все менее стереотипным в описаниях: в XIX веке алгоритмы машинного обучения легко справляются с разбиением персонажей на мужчин и женщин по связанным с ними прилагательным, в первой половине XX века это удается хуже, а ближе к 2000 годам — полный провал.
С другой стороны, доля внимания, которые уделяют авторы (особенно авторы-мужчины!) женским персонажам, по-прежнему несправедливо мала. Даже в XXI веке — что-то около 30%.
Подробности по ссылке:
https://sysblok.ru/philology/gendernye-trudnosti-anglijskoj-literatury/
Нам кажется, что автор передергивает. Цифровые исследования репрезентации мужчин и женщин в художественных текстах — не дань моде или удобству. Они могут дать объективные сведения не только о том, как устроена литература, но и о том, как в культуре отражены гендерные стереотипы и общественные процессы. А главное — как это все эволюционирует и куда движется.
Пример такого исследования — работа о трансформации гендера в англоязычной литературе от Теда Андервуда, Дэвида Баммана и Сабрины Ли. На материале 104 тысяч книг они показывают, например, как изображение гендера становится все менее стереотипным в описаниях: в XIX веке алгоритмы машинного обучения легко справляются с разбиением персонажей на мужчин и женщин по связанным с ними прилагательным, в первой половине XX века это удается хуже, а ближе к 2000 годам — полный провал.
С другой стороны, доля внимания, которые уделяют авторы (особенно авторы-мужчины!) женским персонажам, по-прежнему несправедливо мала. Даже в XXI веке — что-то около 30%.
Подробности по ссылке:
https://sysblok.ru/philology/gendernye-trudnosti-anglijskoj-literatury/
Системный Блокъ
Гендерные трудности английской литературы - Системный Блокъ
За двести пятьдесят лет положение женщин в обществе изменилось, и эти изменения затронули не только реальную жизнь, но и книжное пространство. Как изменялось место женщины в литературе как автора и персонажа? Возможно ли определить пол героя по его описанию?…
Вчера умер Сергей Доренко — ведущий, «телекиллер» и толстый тролль. В 1999 году Доренко помог вывести Путина в президенты, поливая грязью Лужкова и Примакова. А в 2000-м неожиданно сыграл в камикадзе, разнеся в пух и прах самого Путина прямо в прайм-тайме Первого канала — за катастрофу «Курска».
Доренко — противоречивая фигура в истории российской журналистики. Он часто менял убеждения и, кажется, никогда не был на 100% серьезен. Но в одном Доренко не откажешь: это был человек смелый до безбашенности. Умел переть напролом и рубить сплеча, не подстилая соломки — и этим отличался от 95% журналистов России. Смерть ему тоже досталась под стать характеру: разрыв аорты за рулем мотоцикла. Настоящий «Беспечный ездок» русских медиа.
А мы решили еще раз вспомнить знаковые эфиры Сергея Доренко — те самые, которые принесли ему противоречивую славу телекиллера. Для этого мы взяли расшифровки программ и визуализировали их в виде облаков частотностей слов.
Вот репортаж про Примакова и его тазобедренный сустав, где самое частотное слово — «операция». Этим выпуском Доренко уничтожил одного из политических тяжеловесов 90-х. До выпуска Примаков выглядел весомым кандидатом в преемники Ельцина. После — беспомощным и бесперспективным стариком, этаким Брежневым 3.0.
Вот выпуск про Лужкова, его жену Елену Батурину, ее братьев и фирму Мабетекс. Пятно на репутации «старика Батурина» с тех пор так и не отмылось, не позволив ему мечтать о чем-то большем, чем кресло московского мэра.
Ну и, наконец, выпуск про гибель подлодки «Курск». Ключевые слова катастрофы: «Лодка», «Экипаж», «Курск» — и те, кого призвал за нее к ответу Доренко: «президент», «власть», «путин». Власть и Путин журналиста не простили — это был его последний телеэфир на федеральном ТВ.
И, конечно, фоном идет российская история рубежа 90-х — 2000-х. Скандал вокруг Скуратова, убийства и Чечня, Чечня, Чечня…
Доренко — противоречивая фигура в истории российской журналистики. Он часто менял убеждения и, кажется, никогда не был на 100% серьезен. Но в одном Доренко не откажешь: это был человек смелый до безбашенности. Умел переть напролом и рубить сплеча, не подстилая соломки — и этим отличался от 95% журналистов России. Смерть ему тоже досталась под стать характеру: разрыв аорты за рулем мотоцикла. Настоящий «Беспечный ездок» русских медиа.
А мы решили еще раз вспомнить знаковые эфиры Сергея Доренко — те самые, которые принесли ему противоречивую славу телекиллера. Для этого мы взяли расшифровки программ и визуализировали их в виде облаков частотностей слов.
Вот репортаж про Примакова и его тазобедренный сустав, где самое частотное слово — «операция». Этим выпуском Доренко уничтожил одного из политических тяжеловесов 90-х. До выпуска Примаков выглядел весомым кандидатом в преемники Ельцина. После — беспомощным и бесперспективным стариком, этаким Брежневым 3.0.
Вот выпуск про Лужкова, его жену Елену Батурину, ее братьев и фирму Мабетекс. Пятно на репутации «старика Батурина» с тех пор так и не отмылось, не позволив ему мечтать о чем-то большем, чем кресло московского мэра.
Ну и, наконец, выпуск про гибель подлодки «Курск». Ключевые слова катастрофы: «Лодка», «Экипаж», «Курск» — и те, кого призвал за нее к ответу Доренко: «президент», «власть», «путин». Власть и Путин журналиста не простили — это был его последний телеэфир на федеральном ТВ.
И, конечно, фоном идет российская история рубежа 90-х — 2000-х. Скандал вокруг Скуратова, убийства и Чечня, Чечня, Чечня…
{kind=link}
Как оцифровать азулежу? Цифровая карта португальских изразцов
В солнечной и жаркой Португалии на стенах домов, дворцов, церквей и, в общем-то, почти чего угодно вы встретите не только штукатурку и бетон, но и национальное достояние каждого португальца — изразцы азулежу. Техника росписи маленьких керамических квадратиков была изначально принесена на Пиренейский полуостров во времена арабских завоеваний и осталась здесь на долгие годы. Пика распространенности азулежу достигли с началом массового промышленного производства в середине XIX века. Плитки перестали быть предметом роскоши, и ими начали украшать фасады домов.
Проект Mapping Our Tiles ставит своей целью собрать и классифицировать как можно больше (желательно, все) рисунки таких азулежу, а также места, где они встречаются. Дело в том, что большинство изразцов, украшающих церкви и дворцы, уже описаны и изучены искусствоведами и учеными, а домами обычных граждан никто не занимался.
На страничке проекта все предельно просто — вы можете выбрать любой понравившийся вам рисунок и посмотреть на карте, в каких городах добровольцы проекта заметили такой изразец — или его вариацию.
Авторы Mapping Out Tiles приглашают всех и каждого помочь им с наполнением базы, прислав фотографию какого-либо рисунка и адрес, где его можно найти. Это можно сделать как по почте, так и просто поставив хэштег в Инстаграме. Так что оказавшись в Португалии, берите в руки телефон и используйте Инстаграм с пользой! А пока можно просто насладиться красотой португальского изразца — Mapping Our Tiles
Нелли Бурцева
В солнечной и жаркой Португалии на стенах домов, дворцов, церквей и, в общем-то, почти чего угодно вы встретите не только штукатурку и бетон, но и национальное достояние каждого португальца — изразцы азулежу. Техника росписи маленьких керамических квадратиков была изначально принесена на Пиренейский полуостров во времена арабских завоеваний и осталась здесь на долгие годы. Пика распространенности азулежу достигли с началом массового промышленного производства в середине XIX века. Плитки перестали быть предметом роскоши, и ими начали украшать фасады домов.
Проект Mapping Our Tiles ставит своей целью собрать и классифицировать как можно больше (желательно, все) рисунки таких азулежу, а также места, где они встречаются. Дело в том, что большинство изразцов, украшающих церкви и дворцы, уже описаны и изучены искусствоведами и учеными, а домами обычных граждан никто не занимался.
На страничке проекта все предельно просто — вы можете выбрать любой понравившийся вам рисунок и посмотреть на карте, в каких городах добровольцы проекта заметили такой изразец — или его вариацию.
Авторы Mapping Out Tiles приглашают всех и каждого помочь им с наполнением базы, прислав фотографию какого-либо рисунка и адрес, где его можно найти. Это можно сделать как по почте, так и просто поставив хэштег в Инстаграме. Так что оказавшись в Португалии, берите в руки телефон и используйте Инстаграм с пользой! А пока можно просто насладиться красотой португальского изразца — Mapping Our Tiles
Нелли Бурцева
{kind=link}
Как машинный перевод оценивает… машина?
Оценивать машинный перевод — сложно. Для такой оценки человек должен сопоставить адекватность, точность и естественность перевода, а это занимает много времени (недели и даже месяцы) и стоит довольно дорого. Для разработчиков систем МП это проблема — ведь им нужно ежедневно отслеживать изменения в системе и очень быстро отсеивать неудачные решения.
Так как же оценить качество перевода автоматически? Гипотеза такова: чем ближе МП к профессиональному человеческому, тем он лучше. В 2002 году команда из Научно-исследовательского центра IBM имени Томаса Дж. Уотсона создала собственную метрику точности — BLEU (BiLingual Evaluation Understudy), основная идея которой заключается в подсчете совпадений N-граммов в оцениваемом и эталонном переводах. Качество машинного перевода постепенно приближается к качеству перевода, выполненного человеком, и BLEU - маленький шаг для исследователей, но огромный скачок для всех переводчиков.
https://sysblok.ru/nlp/kak-mashinnyj-perevod-ocenivaet-mashina/
Оценивать машинный перевод — сложно. Для такой оценки человек должен сопоставить адекватность, точность и естественность перевода, а это занимает много времени (недели и даже месяцы) и стоит довольно дорого. Для разработчиков систем МП это проблема — ведь им нужно ежедневно отслеживать изменения в системе и очень быстро отсеивать неудачные решения.
Так как же оценить качество перевода автоматически? Гипотеза такова: чем ближе МП к профессиональному человеческому, тем он лучше. В 2002 году команда из Научно-исследовательского центра IBM имени Томаса Дж. Уотсона создала собственную метрику точности — BLEU (BiLingual Evaluation Understudy), основная идея которой заключается в подсчете совпадений N-граммов в оцениваемом и эталонном переводах. Качество машинного перевода постепенно приближается к качеству перевода, выполненного человеком, и BLEU - маленький шаг для исследователей, но огромный скачок для всех переводчиков.
https://sysblok.ru/nlp/kak-mashinnyj-perevod-ocenivaet-mashina/
Системный Блокъ
Как машинный перевод оценивает… машина? - Системный Блокъ
Если качество машинного перевода проверяет человек, то это долго и дорого. А если нужно быстро и дёшево?