
Fast Segment Anything
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
{kind=link}
❤16👍6🔥3
Multilingual End to End Entity Linking
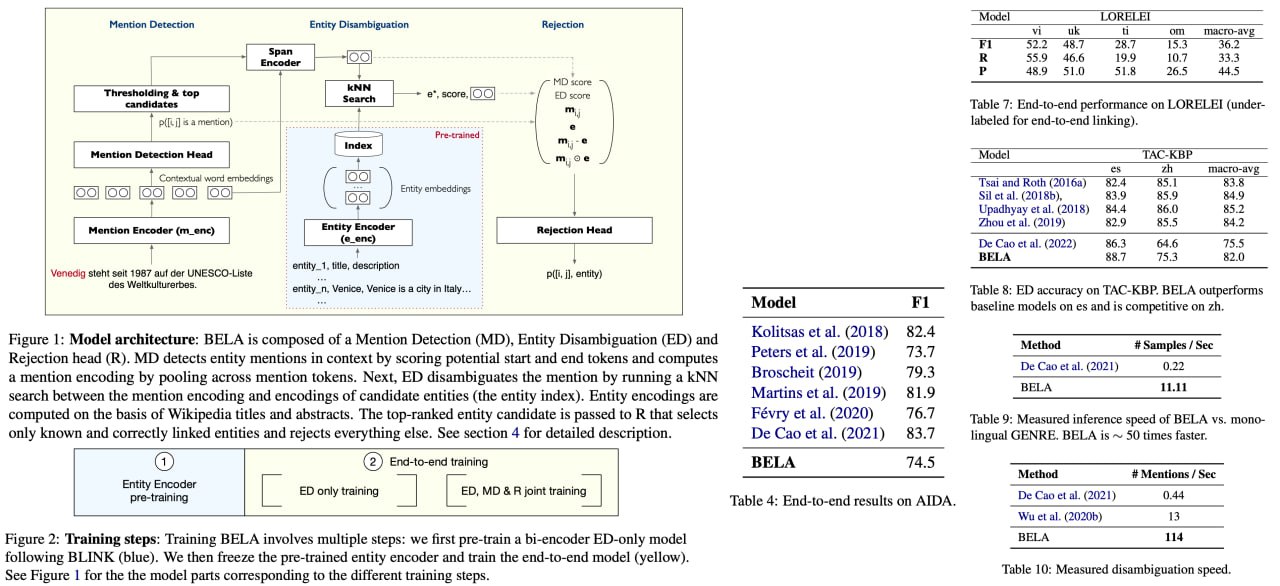
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
{kind=link}
👍13❤4🆒3🔥2🥰1🤔1