
Forwarded from Находки в опенсорсе
Disappearing-People - Person removal from complex backgrounds over time.
Removing people from complex backgrounds in real time using TensorFlow.js in the web browser using #js
https://github.com/jasonmayes/Real-Time-Person-Removal
Looks awesome!
Removing people from complex backgrounds in real time using TensorFlow.js in the web browser using #js
https://github.com/jasonmayes/Real-Time-Person-Removal
Looks awesome!
conversation Lex Fridman with Andrew Ng
one of the most impactful educators, researchers, innovators, and leaders in the history of artificial intelligence. he has helped educate and inspire millions of people
outline: 1st in AI, early days of online education & DL, teaching on a whiteboard, Pieter Abbeel, deeplearning.ai, landing.ai, AI fund, deeplearning.ai, unsupervised learning, career in DL, PhD, Artificial general intelligence
video-podcast: https://youtu.be/0jspaMLxBig
one of the most impactful educators, researchers, innovators, and leaders in the history of artificial intelligence. he has helped educate and inspire millions of people
outline: 1st in AI, early days of online education & DL, teaching on a whiteboard, Pieter Abbeel, deeplearning.ai, landing.ai, AI fund, deeplearning.ai, unsupervised learning, career in DL, PhD, Artificial general intelligence
video-podcast: https://youtu.be/0jspaMLxBig
YouTube
Andrew Ng: Deep Learning, Education, and Real-World AI | Lex Fridman Podcast #73
Andrew Ng is one of the most impactful educators, researchers, innovators, and leaders in artificial intelligence and technology space in general. He co-founded Coursera and Google Brain, launched deeplearning.ai, Landing.ai, and the AI fund, and was the…
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 6 to 18 people.
What is Trending on Wikipedia? Capturing Trends and Language Biases Across Wikipedia Editions
The authors propose an automatic evaluation and comparison of the browsing behavior of Wikipedia readers that can be applied to any language editions of Wikipedia. Focused on English, French, and Russian languages during the last four months of 2018.
They approach consists of the following steps:
– extraction of a sub-network of trending Wikipedia articles and identification of trends
– extraction of keywords from the summaries of every Wikipedia article in the sub-network and weighting according to their importance
– labeling of the trends with high-level topics using the extracted keywords
paper: https://arxiv.org/abs/2002.06885
github: https://github.com/epfl-lts2/sparkwiki
#nlp #trend #wikipedia
The authors propose an automatic evaluation and comparison of the browsing behavior of Wikipedia readers that can be applied to any language editions of Wikipedia. Focused on English, French, and Russian languages during the last four months of 2018.
They approach consists of the following steps:
– extraction of a sub-network of trending Wikipedia articles and identification of trends
– extraction of keywords from the summaries of every Wikipedia article in the sub-network and weighting according to their importance
– labeling of the trends with high-level topics using the extracted keywords
paper: https://arxiv.org/abs/2002.06885
github: https://github.com/epfl-lts2/sparkwiki
#nlp #trend #wikipedia
{kind=link}
On Identifiability in Transformers
The authors tried to understanding better transformers from identifiability.
They started by proving that attention weights are non-identifiable when the sequence length is longer than the attention head dimension. Thus, infinitely many attention distributions can lead to the same internal representation and model output. They propose effective attention, a method that improves the interpretability of attention weights by projecting out the null space.
Also, showed that tokens remain largely identifiable through a learned linear transformation followed by the nearest neighbor lookup based on cosine similarity. However, input tokens gradually become less identifiable in later layers.
Presented Hidden Token Attribution, a gradient-based method to quantify information mixing. This method is general and can be used to investigate contextual embeddings in self-attention based models.
paper: https://arxiv.org/abs/1908.04211
#nlp #transformer #interpretability #attention #ICLR2020
The authors tried to understanding better transformers from identifiability.
They started by proving that attention weights are non-identifiable when the sequence length is longer than the attention head dimension. Thus, infinitely many attention distributions can lead to the same internal representation and model output. They propose effective attention, a method that improves the interpretability of attention weights by projecting out the null space.
Also, showed that tokens remain largely identifiable through a learned linear transformation followed by the nearest neighbor lookup based on cosine similarity. However, input tokens gradually become less identifiable in later layers.
Presented Hidden Token Attribution, a gradient-based method to quantify information mixing. This method is general and can be used to investigate contextual embeddings in self-attention based models.
paper: https://arxiv.org/abs/1908.04211
#nlp #transformer #interpretability #attention #ICLR2020
{kind=link}
A Deep Learning Approach to Antibiotic Discovery
A new antibiotic was found using DL, claimed to be effective against several bacteria resistant to existing antibiotics on mice in the lab.
The problem with finding good antibiotics is potential molecule space is prohibitively large to test all possible molecules in the lab. They train a model that receives the molecule as a graph and tries to predict how effective it is against E. coli.
For every edge, they run single-layer NN receiving activations and features of input node and edge features, and producing new activations for the edge. Activations of the node = sum of all incoming edge activations. Overall activations vector for molecule = sum of all nodes.
Finally, there's a 2-layer NN receiving overall vector for the molecule + some standard handcrafted features with a binary classification output, trained end-to-end on 2.3K molecules. Then, they predict on the dataset of 6K molecules being in different stages of the investigation.
They looked at the top 51 predictions and manually ranked them by not being similar to the training dataset, being far in the investigation stage and scoring low on the external toxicity model. The top pick is what they called Halicin and tested in the lab.
article (only pdf): https://www.cell.com/cell/pdf/S0092-8674(20)30102-1.pdf
ps
thx @Sim0nsays for his cool abstract from the twitter
#medicine #molecule #antibiotic #dl #graph
A new antibiotic was found using DL, claimed to be effective against several bacteria resistant to existing antibiotics on mice in the lab.
The problem with finding good antibiotics is potential molecule space is prohibitively large to test all possible molecules in the lab. They train a model that receives the molecule as a graph and tries to predict how effective it is against E. coli.
For every edge, they run single-layer NN receiving activations and features of input node and edge features, and producing new activations for the edge. Activations of the node = sum of all incoming edge activations. Overall activations vector for molecule = sum of all nodes.
Finally, there's a 2-layer NN receiving overall vector for the molecule + some standard handcrafted features with a binary classification output, trained end-to-end on 2.3K molecules. Then, they predict on the dataset of 6K molecules being in different stages of the investigation.
They looked at the top 51 predictions and manually ranked them by not being similar to the training dataset, being far in the investigation stage and scoring low on the external toxicity model. The top pick is what they called Halicin and tested in the lab.
article (only pdf): https://www.cell.com/cell/pdf/S0092-8674(20)30102-1.pdf
ps
thx @Sim0nsays for his cool abstract from the twitter
#medicine #molecule #antibiotic #dl #graph
{kind=link}
Forwarded from Graph Machine Learning
Fresh picks from ArXiv
More ICML and KDD submissions and large body on mathematical graph theory 📖
ICML
Reinforcement Learning Enhanced Quantum-inspired Algorithm for Combinatorial Optimization
Neural Networks on Random Graphs
Embedding Graph Auto-Encoder with Joint Clustering via Adjacency Sharing
Adaptive Graph Auto-Encoder for General Data Clustering
Computationally Tractable Riemannian Manifolds for Graph Embeddings
Set2Graph: Learning Graphs From Sets
Node Masking: Making Graph Neural Networks Generalize and Scale Better
Deep Graph Mapper: Seeing Graphs through the Neural Lens
Learning Dynamic Knowledge Graphs to Generalize on Text-Based Games by Microsoft and group of William L. Hamilton
Learning to Simulate Complex Physics with Graph Networks by Deepmind + group of Jure Leskovec
KDD
Self-Enhanced GNN: Improving Graph Neural Networks UsingModel Outputs
Graph4Code: A Machine Interpretable Knowledge Graph for Code
Localized Flow-Based Clustering in Hypergraphs by group of Jon Kleinberg
WWW
Beyond Clicks: Modeling Multi-Relational Item Graph for Session-Based Target Behavior Prediction
Graph Theory
Building large k-cores from sparse graphs
Distributed graph problems through an automata-theoretic lens
Computing the k Densest Subgraphs of a Graph
Seeing Far vs. Seeing Wide: Volume Complexity of Local Graph Problems
Planar graphs have bounded queue-number
Review
Graph Embedding on Biomedical Networks: Methods, Applications, and Evaluations
More ICML and KDD submissions and large body on mathematical graph theory 📖
ICML
Reinforcement Learning Enhanced Quantum-inspired Algorithm for Combinatorial Optimization
Neural Networks on Random Graphs
Embedding Graph Auto-Encoder with Joint Clustering via Adjacency Sharing
Adaptive Graph Auto-Encoder for General Data Clustering
Computationally Tractable Riemannian Manifolds for Graph Embeddings
Set2Graph: Learning Graphs From Sets
Node Masking: Making Graph Neural Networks Generalize and Scale Better
Deep Graph Mapper: Seeing Graphs through the Neural Lens
Learning Dynamic Knowledge Graphs to Generalize on Text-Based Games by Microsoft and group of William L. Hamilton
Learning to Simulate Complex Physics with Graph Networks by Deepmind + group of Jure Leskovec
KDD
Self-Enhanced GNN: Improving Graph Neural Networks UsingModel Outputs
Graph4Code: A Machine Interpretable Knowledge Graph for Code
Localized Flow-Based Clustering in Hypergraphs by group of Jon Kleinberg
WWW
Beyond Clicks: Modeling Multi-Relational Item Graph for Session-Based Target Behavior Prediction
Graph Theory
Building large k-cores from sparse graphs
Distributed graph problems through an automata-theoretic lens
Computing the k Densest Subgraphs of a Graph
Seeing Far vs. Seeing Wide: Volume Complexity of Local Graph Problems
Planar graphs have bounded queue-number
Review
Graph Embedding on Biomedical Networks: Methods, Applications, and Evaluations
Popular example of application AI to fashion
Ai can be used for chair design. Some generative models can definately be used in the fashion industry.
Link: https://qz.com/1770508/an-emerging-japanese-startup-is-mining-tradition-to-create-a-more-sustainable-fashion-future/
#aiapplication #generativedesign #meta
Ai can be used for chair design. Some generative models can definately be used in the fashion industry.
Link: https://qz.com/1770508/an-emerging-japanese-startup-is-mining-tradition-to-create-a-more-sustainable-fashion-future/
#aiapplication #generativedesign #meta
Extending relational query processing with ML inference
In some way, it may sound like something strange, but in a close view, it is a brilliant idea in our opinion.
Microsoft develops SQL DB with an inference ML model inside them. So you can do SQL query with a model like usual query alongside good optimization and runtimes as part of the builtin functionality of SQL engine. Data scientists develop an ML model with a pipeline and just put it inside the database. A stored model with the pipeline can then be invoked a bit like a stored procedure by issuing SQL commands.
So:
0. A statement adds the source code for the model pipeline (Python in the example) to the database.
1. At some later point, a SQL query is issued which a model and then uses the function to generate a prediction from the model given some input data (which is itself, of course, the result of a query).
2. The combined model and query undergo static analysis to produce an intermediate representation (IR) of the prediction computation as a DAG.
3. A cross-optimizer then looks for opportunities to optimize the data operator parts of the query given the ML model, and vice-versa (e.g., pruning).
4. A runtime code generator creates a SQL query incorporating all of these optimizations.
5. An extended version of SQL Server, with an integrated ONNX Runtime engine, executes the query.
Neural network translation optimizations replace classical ML operators and data features with NN that can be executed directly in e.g. ONNX Runtime, PyTorch, or TensorFlow.
paper (.pdf): http://cidrdb.org/cidr2020/papers/p24-karanasos-cidr20.pdf
blogpost: https://blog.acolyer.org/2020/02/21/extending-relational-query-processing/
software: https://azure.microsoft.com/en-gb/services/sql-database-edge/
#ml #db #sql
In some way, it may sound like something strange, but in a close view, it is a brilliant idea in our opinion.
Microsoft develops SQL DB with an inference ML model inside them. So you can do SQL query with a model like usual query alongside good optimization and runtimes as part of the builtin functionality of SQL engine. Data scientists develop an ML model with a pipeline and just put it inside the database. A stored model with the pipeline can then be invoked a bit like a stored procedure by issuing SQL commands.
So:
0. A statement adds the source code for the model pipeline (Python in the example) to the database.
1. At some later point, a SQL query is issued which a model and then uses the function to generate a prediction from the model given some input data (which is itself, of course, the result of a query).
2. The combined model and query undergo static analysis to produce an intermediate representation (IR) of the prediction computation as a DAG.
3. A cross-optimizer then looks for opportunities to optimize the data operator parts of the query given the ML model, and vice-versa (e.g., pruning).
4. A runtime code generator creates a SQL query incorporating all of these optimizations.
5. An extended version of SQL Server, with an integrated ONNX Runtime engine, executes the query.
Neural network translation optimizations replace classical ML operators and data features with NN that can be executed directly in e.g. ONNX Runtime, PyTorch, or TensorFlow.
paper (.pdf): http://cidrdb.org/cidr2020/papers/p24-karanasos-cidr20.pdf
blogpost: https://blog.acolyer.org/2020/02/21/extending-relational-query-processing/
software: https://azure.microsoft.com/en-gb/services/sql-database-edge/
#ml #db #sql
{kind=link}
How climate change, air pollution, and provider shortages are making things worse for allergy-sufferers
Analytical research (including #interactive maps) of connection of air pollution to allergy reactions in the U.S.
Link: https://medium.com/ro-co/how-climate-change-air-pollution-and-provider-shortages-are-making-things-worse-for-90e0f8d4a36b
#eda #explorative #healthcare #medical
Analytical research (including #interactive maps) of connection of air pollution to allergy reactions in the U.S.
Link: https://medium.com/ro-co/how-climate-change-air-pollution-and-provider-shortages-are-making-things-worse-for-90e0f8d4a36b
#eda #explorative #healthcare #medical
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 6 to 18 people.
ODS dinner in Munich! See you this Friday at 20:00 at
Opatija Easy im Tal
Hochbrückenstraße 3, 80331 München
089 268353
https://goo.gl/maps/iNMcNmzmvKbcxnqk7
Table is booked for Evgenii/Eugene/Ivgenii - try your best to identify :)
Opatija Easy im Tal
Hochbrückenstraße 3, 80331 München
089 268353
https://goo.gl/maps/iNMcNmzmvKbcxnqk7
Table is booked for Evgenii/Eugene/Ivgenii - try your best to identify :)
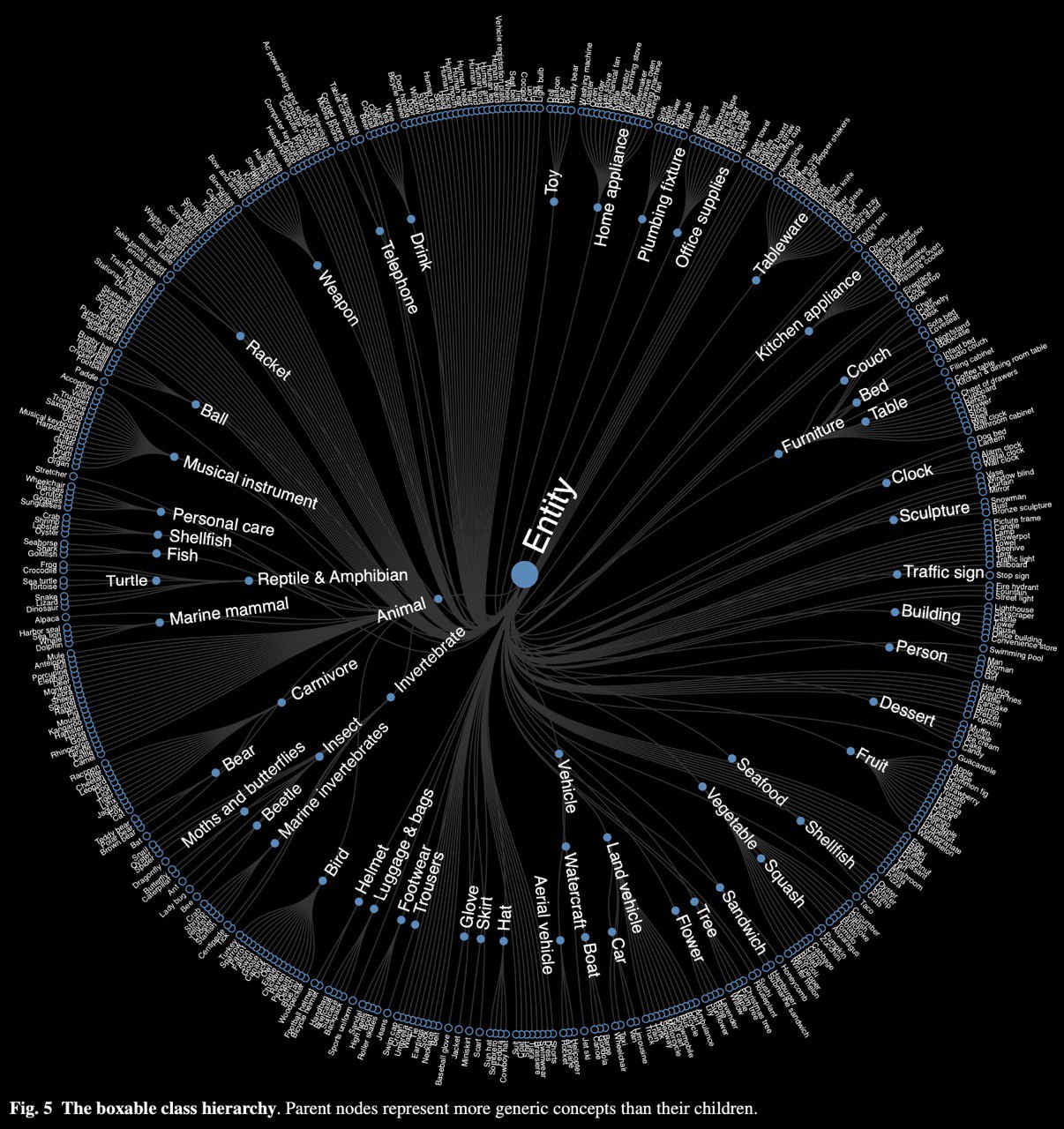
The Open Images Dataset V4 by GoogleAI
#GoogleAI present #OpenImagesV4, a #dataset of 9.2M images with unified annotations for:
– image #classification
– object #detection
– visual relationship detection
30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes
paper: https://arxiv.org/abs/1811.00982v2
#GoogleAI present #OpenImagesV4, a #dataset of 9.2M images with unified annotations for:
– image #classification
– object #detection
– visual relationship detection
30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes
paper: https://arxiv.org/abs/1811.00982v2
{kind=link}
Albumentation – fast & flexible image augmentations
Image Augmentations is a powerful technique to improve model robustness and performance. There are many image augmentations libraries on the market: torchvision, imgaug, DALI, Augmentor, SOLT, etc.
In all of them, authors focussed on variety at the cost of speed, or the speed at the cost of flexibility.
Requirements for augmentations:
* Variety: they want to have a large set of standard and exotic augmentation for image classification, segmentation, and detection in one place.
* Performance: transforms should be as fast as possible.
* Flexibility: it should be easy to add new transforms or new types of transforms.
* Conciseness: all complexity of implementation should be hidden behind the API.
To date
The library was adopted by academics, Kaggle, and other communities.
ODS: #tool_albumentations
Link: https://albumentations.ai/
Github: https://github.com/albumentations-team/albumentations
Paper: https://www.mdpi.com/2078-2489/11/2/125
P.S. Following trend setup by #Catalyst team, we provide extensive description of project with the help of its creators.
#guestpost #augmentation #CV #DL #imageprocessing #ods #objectdetection #imageclassification #tool
Image Augmentations is a powerful technique to improve model robustness and performance. There are many image augmentations libraries on the market: torchvision, imgaug, DALI, Augmentor, SOLT, etc.
In all of them, authors focussed on variety at the cost of speed, or the speed at the cost of flexibility.
Requirements for augmentations:
* Variety: they want to have a large set of standard and exotic augmentation for image classification, segmentation, and detection in one place.
* Performance: transforms should be as fast as possible.
* Flexibility: it should be easy to add new transforms or new types of transforms.
* Conciseness: all complexity of implementation should be hidden behind the API.
Albumentations were born out of necessity. The authors were actively participating in various Deep Learning competitions. To get to the top they needed something better than what was already available. All of them, independently, started working on more powerful augmentation pipelines. Later they merged their efforts and released the code in the form of the library.To date
Albumentations has more than 70 transforms and supports image classification, #segmentation, object and keypoint detection tasks.The library was adopted by academics, Kaggle, and other communities.
ODS: #tool_albumentations
Link: https://albumentations.ai/
Github: https://github.com/albumentations-team/albumentations
Paper: https://www.mdpi.com/2078-2489/11/2/125
P.S. Following trend setup by #Catalyst team, we provide extensive description of project with the help of its creators.
#guestpost #augmentation #CV #DL #imageprocessing #ods #objectdetection #imageclassification #tool
GitHub
GitHub - albumentations-team/albumentations: Fast and flexible image augmentation library. Paper about the library: https://www.mdpi.com/2078…
Fast and flexible image augmentation library. Paper about the library: https://www.mdpi.com/2078-2489/11/2/125 - albumentations-team/albumentations
Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
tl;dr:
- 11 billion parameters
- encoder-decoder models generally outperformed “decoder-only” language models
- fill-in-the-blank-style denoising objectives worked best;
- the most important factor was the computational cost;
- training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
- multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task
The model can be fine-tuned on smaller labeled datasets, often resulting in (far) better performance than training on the labeled data alone.
Present a large-scale empirical survey to determine which transfer learning techniques work best and apply these insights at scale to create a new model that we call the T5. Also, introduce a new open-source pre-training dataset, called the Colossal Clean Crawled Corpus (C4).
The T5 model, pre-trained on C4, achieves SOTA results on many NLP benchmarks while being flexible enough to be fine-tuned to a variety of important downstream tasks.
blog post: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
paper: https://arxiv.org/abs/1910.10683
github (with pre-trained models): https://github.com/google-research/text-to-text-transfer-transformer
colab notebook: https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb
#nlp #transformer #t5
tl;dr:
- 11 billion parameters
- encoder-decoder models generally outperformed “decoder-only” language models
- fill-in-the-blank-style denoising objectives worked best;
- the most important factor was the computational cost;
- training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
- multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task
The model can be fine-tuned on smaller labeled datasets, often resulting in (far) better performance than training on the labeled data alone.
Present a large-scale empirical survey to determine which transfer learning techniques work best and apply these insights at scale to create a new model that we call the T5. Also, introduce a new open-source pre-training dataset, called the Colossal Clean Crawled Corpus (C4).
The T5 model, pre-trained on C4, achieves SOTA results on many NLP benchmarks while being flexible enough to be fine-tuned to a variety of important downstream tasks.
blog post: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
paper: https://arxiv.org/abs/1910.10683
github (with pre-trained models): https://github.com/google-research/text-to-text-transfer-transformer
colab notebook: https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb
#nlp #transformer #t5
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 4 to 16 people.
🔥AI Meme Generator: This Meme Does Not Exist
Imgflip created an “AI meme generator”. Meme captions are generated by neural network.
Link: https://imgflip.com/ai-meme
#NLP #NLU #meme #generation #imgflip
Imgflip created an “AI meme generator”. Meme captions are generated by neural network.
Link: https://imgflip.com/ai-meme
#NLP #NLU #meme #generation #imgflip
{kind=link}
#DeepPavlov & #transformers
and now at 🤗 you can also use the next models:
-
-
-
-
-
-
page: https://huggingface.co/DeepPavlov
colab tutorial: here
and now at 🤗 you can also use the next models:
-
DeepPavlov/bert-base-bg-cs-pl-ru-cased-
DeepPavlov/bert-base-cased-conversational-
DeepPavlov/bert-base-multilingual-cased-sentence-
DeepPavlov/rubert-base-cased-conversational-
DeepPavlov/rubert-base-cased-sentence-
DeepPavlov/rubert-base-casedpage: https://huggingface.co/DeepPavlov
colab tutorial: here
{kind=link}
👍1
Data Science interview questions list
List, compiled from medium article and peer-provided contributions.
Github (questions and answers): https://github.com/alexeygrigorev/data-science-interviews/blob/master/theory.md
#interview #questions #meta
List, compiled from medium article and peer-provided contributions.
Github (questions and answers): https://github.com/alexeygrigorev/data-science-interviews/blob/master/theory.md
#interview #questions #meta
GitHub
data-science-interviews/theory.md at master · alexeygrigorev/data-science-interviews
Data science interview questions and answers. Contribute to alexeygrigorev/data-science-interviews development by creating an account on GitHub.