
Are Pre-trained Convolutions Better than Pre-trained Transformers?
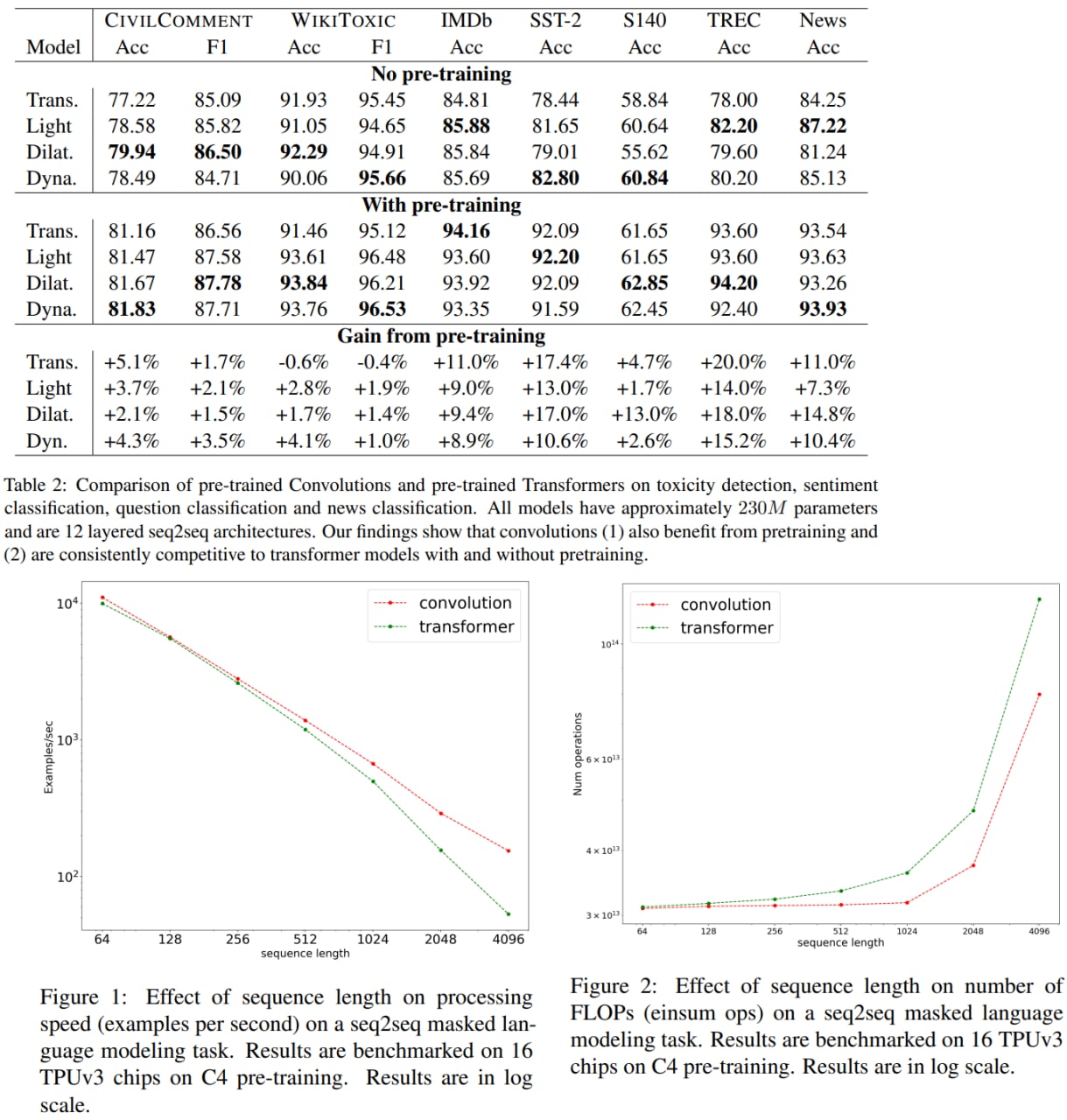
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
{kind=link}
InceptionNeXt: When Inception Meets ConvNeXt
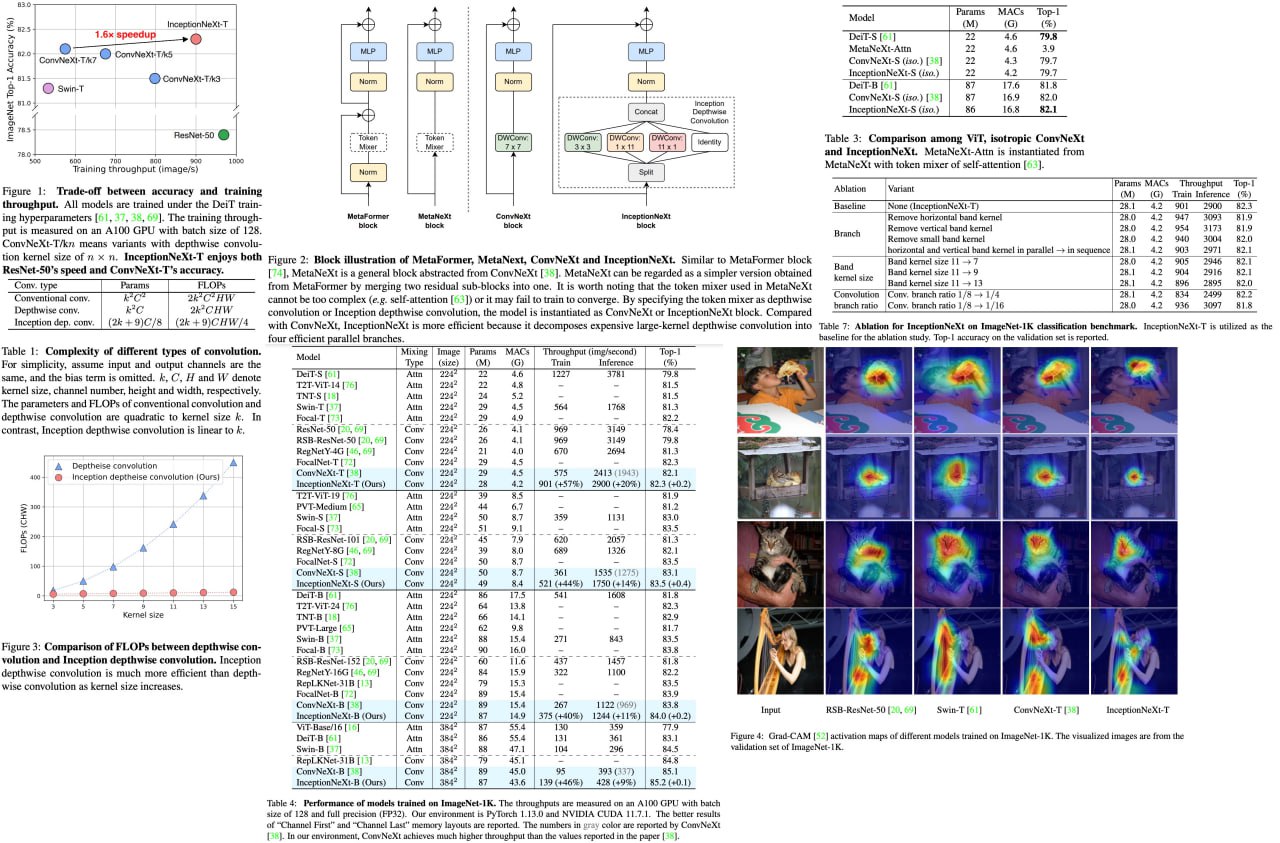
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
{kind=link}
👍6