
CamemBERT
New state-of-the-art in French NLU 🇫🇷
CamemBERT is a state-of-the-art language model for French based on the RoBERTa architecture pretrained on the French subcorpus of the newly available multilingual corpus OSCAR.
Project page & examples: https://camembert-model.fr/
#nlp #bert #lm
New state-of-the-art in French NLU 🇫🇷
CamemBERT is a state-of-the-art language model for French based on the RoBERTa architecture pretrained on the French subcorpus of the newly available multilingual corpus OSCAR.
Project page & examples: https://camembert-model.fr/
#nlp #bert #lm
CamemBERT
CamemBERT: a Tasty French Language Model
CamemBERT is a state-of-the-art language model for French based on the RoBERTa architecture.
BodyPix: Real-time Person Segmentation in the Browser with TensorFlow.js
Released BodyPix 2.0 with #multiperson support and improved accuracy (based on ResNet50), a new API, weight quantization, and support for different image sizes with TensorFlow.js
It estimates and renders person and body-part segmentation at 25 fps on a 2018 15-inch MacBook Pro, and 21 fps on an iPhone X.
code: https://github.com/tensorflow/tfjs-models/tree/master/body-pix
demo: https://storage.googleapis.com/tfjs-models/demos/body-pix/index.html
blog: https://blog.tensorflow.org/2019/11/updated-bodypix-2.html
#dl #segmentation
Released BodyPix 2.0 with #multiperson support and improved accuracy (based on ResNet50), a new API, weight quantization, and support for different image sizes with TensorFlow.js
It estimates and renders person and body-part segmentation at 25 fps on a 2018 15-inch MacBook Pro, and 21 fps on an iPhone X.
code: https://github.com/tensorflow/tfjs-models/tree/master/body-pix
demo: https://storage.googleapis.com/tfjs-models/demos/body-pix/index.html
blog: https://blog.tensorflow.org/2019/11/updated-bodypix-2.html
#dl #segmentation
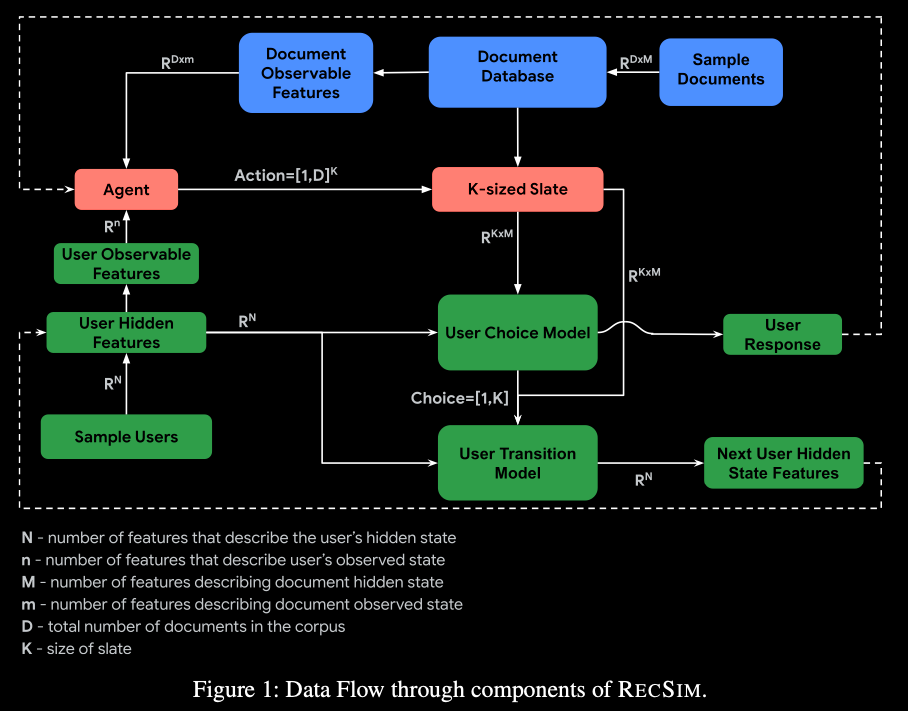
RecSim: A Configurable Simulation Platform for Recommender Systems
It's a configurable platform for authoring simulation environments to facilitate the study of RL algorithms in recommender systems (and CIRs in particular).
RᴇᴄSɪᴍ allows both researchers and practitioners to test the limits of existing RL methods in synthetic recommender settings. RecSim’s aim is to support simulations that mirror specific aspects of user behavior found in real recommender systems and serve as a controlled environment for developing, evaluating and comparing recommender models and algorithms, especially RL systems designed for sequential user-system interaction.
As an open-source platform, RᴇᴄSɪᴍ:
* facilitates research at the intersection of RL and recommender systems
* encourages reproducibility and model-sharing
* aids the recommender-systems practitioner, interested in applying RL to rapidly test and refine models and algorithms in simulation, before incurring the potential cost (e.g., time, user impact) of live experiments
* serves as a resource for academic-industry collaboration through the release of “realistic” stylized models of user behavior without revealing user data or sensitive industry strategies.
blog: https://ai.googleblog.com/2019/11/recsim-configurable-simulation-platform.html
paper: https://arxiv.org/abs/1909.04847
code: https://github.com/google-research/recsim
#rs #rl
It's a configurable platform for authoring simulation environments to facilitate the study of RL algorithms in recommender systems (and CIRs in particular).
RᴇᴄSɪᴍ allows both researchers and practitioners to test the limits of existing RL methods in synthetic recommender settings. RecSim’s aim is to support simulations that mirror specific aspects of user behavior found in real recommender systems and serve as a controlled environment for developing, evaluating and comparing recommender models and algorithms, especially RL systems designed for sequential user-system interaction.
As an open-source platform, RᴇᴄSɪᴍ:
* facilitates research at the intersection of RL and recommender systems
* encourages reproducibility and model-sharing
* aids the recommender-systems practitioner, interested in applying RL to rapidly test and refine models and algorithms in simulation, before incurring the potential cost (e.g., time, user impact) of live experiments
* serves as a resource for academic-industry collaboration through the release of “realistic” stylized models of user behavior without revealing user data or sensitive industry strategies.
blog: https://ai.googleblog.com/2019/11/recsim-configurable-simulation-platform.html
paper: https://arxiv.org/abs/1909.04847
code: https://github.com/google-research/recsim
#rs #rl
{kind=link}
Free book on #PyTorch
Book with all the information required to work with one of the most popular #dl frameworks.
Link: https://twitter.com/PyTorch/status/1197603717144432640?s=20
#book #manual
Book with all the information required to work with one of the most popular #dl frameworks.
Link: https://twitter.com/PyTorch/status/1197603717144432640?s=20
#book #manual
Twitter
PyTorch
To help developers get started with PyTorch, we’re making the 'Deep Learning with PyTorch' book, written by Luca Antiga and Eli Stevens, available for free to the community: https://t.co/KH52NW0Itl
ODS breakfast in Paris! See you this Saturday (tomorrow) at 10:30 at Malongo Café, 50 Rue Saint-André des Arts. We are expecting at least from 7 to 18 people (table overflow might occur).
ODS breakfast in Munich! See you this Saturday (tomorrow) at 11:00 at Mucly & Floyd https://goo.gl/maps/1PFsXqFn23mCYwxi7
Mucki & Floyd - Restaurant, Bar, Café · Ickstattstraße 2, 80469 München, Germany
★★★★★ · Bar
Hello!
We are announcing second but not less historical Munich Data Science #meetup on Dec 5th jointly with BMW Welt
Pls come grab snacks, chill with your peers, discuss #ml magic 🙂
Evgenii +4916091541827
https://www.meetup.com/Munich-Data-Science/events/266659553
We are announcing second but not less historical Munich Data Science #meetup on Dec 5th jointly with BMW Welt
Pls come grab snacks, chill with your peers, discuss #ml magic 🙂
Evgenii +4916091541827
https://www.meetup.com/Munich-Data-Science/events/266659553
Meetup
Login to Meetup | Meetup
Find groups that host online or in person events and meet people in your local community who share your interests.
Momentum Contrast for Unsupervised Visual Representation Learning
The idea represents in one picture there is a new queue mechanism of store features for the batch.
Achieve SOTA on different datasets and architecture.
One of the most popular tasks about unsupervised learning is instance discriminations, which about contrastive loss. We need to feature from different augmentations of the same image to be close to each other and far in other images.
This possible to do with end2end but it will be a big batch size, cause the quality is dependent on the variety of examples inside the batch.
Previous works were founded on memory bank where features previous batches stores and used to negative nonsimilar examples.
The idea in the paper it lets change memory bank in the queue, there will be recent features and it will be two encoders, one of them learning from the batch, the second learning from all queue but with strong momentum.
So the queue is like a crazy big batch. So the best result in different tasks even better than supervised.
via @arsenyinfo
paper: https://arxiv.org/pdf/1911.05722.pdf
#cv #unsupervised
The idea represents in one picture there is a new queue mechanism of store features for the batch.
Achieve SOTA on different datasets and architecture.
One of the most popular tasks about unsupervised learning is instance discriminations, which about contrastive loss. We need to feature from different augmentations of the same image to be close to each other and far in other images.
This possible to do with end2end but it will be a big batch size, cause the quality is dependent on the variety of examples inside the batch.
Previous works were founded on memory bank where features previous batches stores and used to negative nonsimilar examples.
The idea in the paper it lets change memory bank in the queue, there will be recent features and it will be two encoders, one of them learning from the batch, the second learning from all queue but with strong momentum.
So the queue is like a crazy big batch. So the best result in different tasks even better than supervised.
via @arsenyinfo
paper: https://arxiv.org/pdf/1911.05722.pdf
#cv #unsupervised
{kind=link}
Forwarded from Spark in me (Alexander)
Streamlit vs. viola vs. panel vs. dash vs. bokeh server
TLDR - make scientific web-apps via python only w/o any web-programming (i.e. django, tornado).
Dash
- Mostly for BI
- Also a paid product
- Looks like the new Tableau
- Serving and out-of-the-box scaling options
Bokeh server
- Mostly plotting (very flexible, unlimited capabilities)
- High entry cost, though bokeh is kind of easy to use
- Also should scale well
Panel
- A bokeh server wrapper with a lot of capabilities for geo + templates
Streamlit
- The nicest looking app for interactive ML apps (maybe even annotation)
- Has pre-built styles and grid
- Limited only to its pre-built widgets
- Built on tornado with a very specific data model incompatible with the majority of available widgets
- Supposed to scale well - built on top of tornado
Viola
- If it runs in a notebook - it will run in viola
- Just turns a notebook into a server
- The app with the most promise for DS / ML
- Scales kind of meh - you need to run a jupyter kernel for each user - also takes some time to spin up a kernel
- Fully benefits from a rich ecosystem of jupyter / python / widgets
- In theory has customizable grid and CSS, but does not come pre-built with this => higher barrier to entry
Also most of these apps have no authentication buil-in.
More details:
- A nice summary here;
- A very detailed pros and cons summary of Streamlit + Viola. Also a very in-depth detailed discussion;
- Also awesome streamlit boilerplate is awesome;
#data_science
TLDR - make scientific web-apps via python only w/o any web-programming (i.e. django, tornado).
Dash
- Mostly for BI
- Also a paid product
- Looks like the new Tableau
- Serving and out-of-the-box scaling options
Bokeh server
- Mostly plotting (very flexible, unlimited capabilities)
- High entry cost, though bokeh is kind of easy to use
- Also should scale well
Panel
- A bokeh server wrapper with a lot of capabilities for geo + templates
Streamlit
- The nicest looking app for interactive ML apps (maybe even annotation)
- Has pre-built styles and grid
- Limited only to its pre-built widgets
- Built on tornado with a very specific data model incompatible with the majority of available widgets
- Supposed to scale well - built on top of tornado
Viola
- If it runs in a notebook - it will run in viola
- Just turns a notebook into a server
- The app with the most promise for DS / ML
- Scales kind of meh - you need to run a jupyter kernel for each user - also takes some time to spin up a kernel
- Fully benefits from a rich ecosystem of jupyter / python / widgets
- In theory has customizable grid and CSS, but does not come pre-built with this => higher barrier to entry
Also most of these apps have no authentication buil-in.
More details:
- A nice summary here;
- A very detailed pros and cons summary of Streamlit + Viola. Also a very in-depth detailed discussion;
- Also awesome streamlit boilerplate is awesome;
#data_science
Medium
Jupyter Dashboarding — some thoughts on Voila, Panel and Dash
There are three main players in the Python dashboarding space, let’s discuss.
This media is not supported in your browser
VIEW IN TELEGRAM
You can now build and run ML pipelines in an interactive Colab notebook using TensorFlow Extended (TFX)!
Develop in a notebook and then export to a production-ready ML pipeline.
Link to try: https://goo.gle/TFXnotebook
Develop in a notebook and then export to a production-ready ML pipeline.
Link to try: https://goo.gle/TFXnotebook
VizSeq: A Visual Analysis Toolkit for Text Generation Tasks
it's a visual analysis toolkit for {text, image, audio, video}-to-text generation system evaluation, dataset analysis, and benchmark hosting.
supports multimodal sources and multiple text references, providing visualization in Jupyter notebook or a web app interface.
also, it can be used locally or deployed onto public servers for centralized data hosting and benchmarking; covers most common n-gram based metrics accelerated with multiprocessing and also provides the latest embedding-based metrics such as BERTScore
Paper: https://arxiv.org/abs/1909.05424
Code: https://github.com/facebookresearch/vizseq
#computation #language #emnlp2019
it's a visual analysis toolkit for {text, image, audio, video}-to-text generation system evaluation, dataset analysis, and benchmark hosting.
supports multimodal sources and multiple text references, providing visualization in Jupyter notebook or a web app interface.
also, it can be used locally or deployed onto public servers for centralized data hosting and benchmarking; covers most common n-gram based metrics accelerated with multiprocessing and also provides the latest embedding-based metrics such as BERTScore
Paper: https://arxiv.org/abs/1909.05424
Code: https://github.com/facebookresearch/vizseq
#computation #language #emnlp2019
{kind=link}
A Visual Guide to Using BERT for the First Time
A new blog post and notebook by Jay Alammar to get you started with using a pre-trained BERT model for the first time. It uses huggingface libs for sentence embedding and scikitLearn for classification
blog: https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time
#nlp #bert
A new blog post and notebook by Jay Alammar to get you started with using a pre-trained BERT model for the first time. It uses huggingface libs for sentence embedding and scikitLearn for classification
blog: https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time
#nlp #bert
{kind=link}
DeepFovea: Using deep learning for foveated reconstruction in AR/VR
DeepFovea is a network for a foveated rendering that allows reconstructing a plausible periphery with a small amount of pixels.
The reconstruction is done by finding the closest matching video to this sparse input stream of pixels on the learned manifold of natural videos.
The generator model is a U-Net with recurrent decoder blocks.
Use multiple losses to make the reconstruction plausible: adversarial loss, LPIPS loss to improve the reconstruction of the spatial details, optical flow loss to reduce the peripheral flicker.
BUT training code and weights coming soon.
blog: https://ai.facebook.com/blog/deepfovea-using-deep-learning-for-foveated-reconstruction-in-ar-vr/
code: https://github.com/facebookresearch/DeepFovea
#dl #gan
DeepFovea is a network for a foveated rendering that allows reconstructing a plausible periphery with a small amount of pixels.
The reconstruction is done by finding the closest matching video to this sparse input stream of pixels on the learned manifold of natural videos.
The generator model is a U-Net with recurrent decoder blocks.
Use multiple losses to make the reconstruction plausible: adversarial loss, LPIPS loss to improve the reconstruction of the spatial details, optical flow loss to reduce the peripheral flicker.
BUT training code and weights coming soon.
blog: https://ai.facebook.com/blog/deepfovea-using-deep-learning-for-foveated-reconstruction-in-ar-vr/
code: https://github.com/facebookresearch/DeepFovea
#dl #gan
Altair version 3.3 released! http://altair-viz.github.io
Enhancements:
* Add inheritance structure to low-level schema classes
* Add
* Support Python 3.8
* Add
* Add data generator interface:
* Support geographic data sources via
Enhancements:
* Add inheritance structure to low-level schema classes
* Add
html renderer which works across frontends* Support Python 3.8
* Add
:G shorthand for geojson type* Add data generator interface:
alt.sequence, alt.graticule, alt.sphere()* Support geographic data sources via
__geo_interface__{kind=link}
ODS breakfast in Paris! 🇫🇷 See you this Saturday at 10:30 at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 7 to 14 people
All the vector algebra you need for understanding neural networks
Article contains great explanations and description of matrix calculus you need to know and understand to really grok neural networks.
Link: https://explained.ai/matrix-calculus/index.html
#WhereToStart #entrylevel #novice #base #DL #nn
Article contains great explanations and description of matrix calculus you need to know and understand to really grok neural networks.
Link: https://explained.ai/matrix-calculus/index.html
#WhereToStart #entrylevel #novice #base #DL #nn
explained.ai
The Matrix Calculus You Need For Deep Learning
Most of us last saw calculus in school, but derivatives are a critical part of machine learning, particularly deep neural networks, which are trained by optimizing a loss function. This article is an attempt to explain all the matrix calculus you need in…
Hello!
Gentle reminder in regards of second but not less historical Munich Data Science #meetup on Dec 5th jointly with BMW Welt. 160 RSVPed already, don’t miss opportunity
Evgenii +4916091541827
https://www.meetup.com/Munich-Data-Science/events/266659553
Gentle reminder in regards of second but not less historical Munich Data Science #meetup on Dec 5th jointly with BMW Welt. 160 RSVPed already, don’t miss opportunity
Evgenii +4916091541827
https://www.meetup.com/Munich-Data-Science/events/266659553
Meetup
Login to Meetup | Meetup
Find groups that host online or in person events and meet people in your local community who share your interests.