
Prescribed Generative Adversarial Networks
Adding noise to the generator's output prevent common model collapse in GANs, and also allows to approximate log-likelihood evaluation.
#GAN
Link: https://arxiv.org/abs/1910.04302
Adding noise to the generator's output prevent common model collapse in GANs, and also allows to approximate log-likelihood evaluation.
#GAN
Link: https://arxiv.org/abs/1910.04302
{kind=link}
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
It's the method for pre-training seq2seq models by de-noising text.
BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text.
They evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token.
BART matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, Q&A, and summarization tasks, with gains of up to 6 ROUGE.
Paper: https://arxiv.org/abs/1910.13461
#nlp #bert
It's the method for pre-training seq2seq models by de-noising text.
BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text.
They evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token.
BART matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, Q&A, and summarization tasks, with gains of up to 6 ROUGE.
Paper: https://arxiv.org/abs/1910.13461
#nlp #bert
{kind=link}
Function-Space Distributions over Kernels
With a function-space approach to kernel learning helps to incorporate interpretable inductive biases, manage uncertainty, and discover rich representations of data.
ArXiV: https://arxiv.org/abs/1910.13565
#gaussianprocess #NeurIPS #NeurIPS2019 #FKL #kernellearning
With a function-space approach to kernel learning helps to incorporate interpretable inductive biases, manage uncertainty, and discover rich representations of data.
ArXiV: https://arxiv.org/abs/1910.13565
#gaussianprocess #NeurIPS #NeurIPS2019 #FKL #kernellearning
{kind=link}
Forwarded from Spark in me (Alexander)
The current state of "DIY" ML hardware
(i.e. that you can actually assemble and maintain and use in a small team)
Wanted to write a large post, but decided to just a TLDR.
In case you need a super-computer / cluster / devbox with 4 - 16 GPUs.
The bad
- Nvidia DGX and similar - 3-5x overpriced (sic!)
- Cloud providers (Amazon) - 2-3x overpriced
The ugly
- Supermicro GPU server solutions. This server hardware is a bit overpriced, but its biggest problem is old processor sockets
- Custom shop buit machines (with water) - very nice, but (except for water) you just pay US$5 - 10 - 15k for work you can do yourself in one day
- 2 CPU professional level motherboards - very cool, but powerful Intel Xeons are also very overpriced
The good
- Powerful AMD processor with 12-32 cores + top tier motherboard. This will support 4 GPUs on x8 speed and have a 10 Gb/s ethernet port
- Just add more servers with 10 Gb/s connection and probably later connect them into a ring ... cheap / powerful / easy to maintain
More democratization soon?
Probably the following technologies will untie our hands
- Single slot GPUs - Zotac clearly thought about it, maybe it will become mainstream in the professional market
- PCIE 4.0 => enough speed for ML even on cheaper motherboards
- New motherboards for AMD processors => maybe more PCIE slots will become normal
- Intel optane persistent memory => slow and expensive now, maybe RAM / SSD will merge (imagine having 2 TB of cheap RAM on your box)
Good chat in ODS on same topic.
#hardware
(i.e. that you can actually assemble and maintain and use in a small team)
Wanted to write a large post, but decided to just a TLDR.
In case you need a super-computer / cluster / devbox with 4 - 16 GPUs.
The bad
- Nvidia DGX and similar - 3-5x overpriced (sic!)
- Cloud providers (Amazon) - 2-3x overpriced
The ugly
- Supermicro GPU server solutions. This server hardware is a bit overpriced, but its biggest problem is old processor sockets
- Custom shop buit machines (with water) - very nice, but (except for water) you just pay US$5 - 10 - 15k for work you can do yourself in one day
- 2 CPU professional level motherboards - very cool, but powerful Intel Xeons are also very overpriced
The good
- Powerful AMD processor with 12-32 cores + top tier motherboard. This will support 4 GPUs on x8 speed and have a 10 Gb/s ethernet port
- Just add more servers with 10 Gb/s connection and probably later connect them into a ring ... cheap / powerful / easy to maintain
More democratization soon?
Probably the following technologies will untie our hands
- Single slot GPUs - Zotac clearly thought about it, maybe it will become mainstream in the professional market
- PCIE 4.0 => enough speed for ML even on cheaper motherboards
- New motherboards for AMD processors => maybe more PCIE slots will become normal
- Intel optane persistent memory => slow and expensive now, maybe RAM / SSD will merge (imagine having 2 TB of cheap RAM on your box)
Good chat in ODS on same topic.
#hardware
AnandTech
ZOTAC’s GeForce RTX 2080 Ti ArcticStorm: A Single-Slot Water Cooled GeForce RTX 2080 Ti
Ultra-high-end graphics cards these days all seem to either come with a very large triple fan cooler, or more exotically, a hybrid cooling system based around a large heatsink with fans and a liquid cooling block. Naturally, these cards use two or more slots…
Forwarded from Spark in me (Alexander)
Open STT v1.0 release
Finally we released open STT v1.0 =)
Highlights
- 20 000 hours of annotated data
- 2 new large and diverse domains
- 12k speakers (to be released soon)
- Overall quality improvement
- See below posts and releases for more details
How can I help?
- Share our dataset
- Share / publish your dataset - the more domains the better
- Upvote on habr
- Upvote on TDS (when released)
- We have an Open Collective page for donations
Links
- Open STT https://github.com/snakers4/open_stt
- Release https://github.com/snakers4/open_stt/releases
- Open TTS https://github.com/snakers4/open_tts
- Habr https://habr.com/ru/post/474462/
- Towards Data Science (coming soon)
- Bloghttps://spark-in.me/post/open-stt-release-v10
- Open collective https://opencollective.com/open_stt (edited)
Finally we released open STT v1.0 =)
Highlights
- 20 000 hours of annotated data
- 2 new large and diverse domains
- 12k speakers (to be released soon)
- Overall quality improvement
- See below posts and releases for more details
+---------------+------+--------+------+
| Domain | Utts | Hours | GB |
+---------------+------+--------+------+
| Radio | 8,3М | 11,996 | 1367 |
+---------------+------+--------+------+
| Public Speech | 1,7M | 2,709 | 301 |
+---------------+------+--------+------+
| Youtube | 2,6М | 2,117 | 346 |
+---------------+------+--------+------+
| Books | 1,3М | 1,632 | 180 |
+---------------+------+--------+------+
| Calls | 695K | 819 | 91 |
+---------------+------+--------+------+
| Other | 1.9M | 835 | 95 |
+---------------+------+--------+------+
How can I help?
- Share our dataset
- Share / publish your dataset - the more domains the better
- Upvote on habr
- Upvote on TDS (when released)
- We have an Open Collective page for donations
Links
- Open STT https://github.com/snakers4/open_stt
- Release https://github.com/snakers4/open_stt/releases
- Open TTS https://github.com/snakers4/open_tts
- Habr https://habr.com/ru/post/474462/
- Towards Data Science (coming soon)
- Bloghttps://spark-in.me/post/open-stt-release-v10
- Open collective https://opencollective.com/open_stt (edited)
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
🔥OpenAI realesed the 1.5billion parameter GPT-2 model
Post: https://openai.com/blog/gpt-2-1-5b-release/
GPT-2 output detection model: https://github.com/openai/gpt-2-output-dataset/tree/master/detector
Research from partners on potential malicious uses: https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
#NLU #GPT2 #OpenAI #NLP
Post: https://openai.com/blog/gpt-2-1-5b-release/
GPT-2 output detection model: https://github.com/openai/gpt-2-output-dataset/tree/master/detector
Research from partners on potential malicious uses: https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
#NLU #GPT2 #OpenAI #NLP
Openai
GPT-2: 1.5B release
As the final model release of GPT-2’s staged release, we’re releasing the largest version (1.5B parameters) of GPT-2 along with code and model weights to facilitate detection of outputs of GPT-2 models. While there have been larger language models released…
👍1
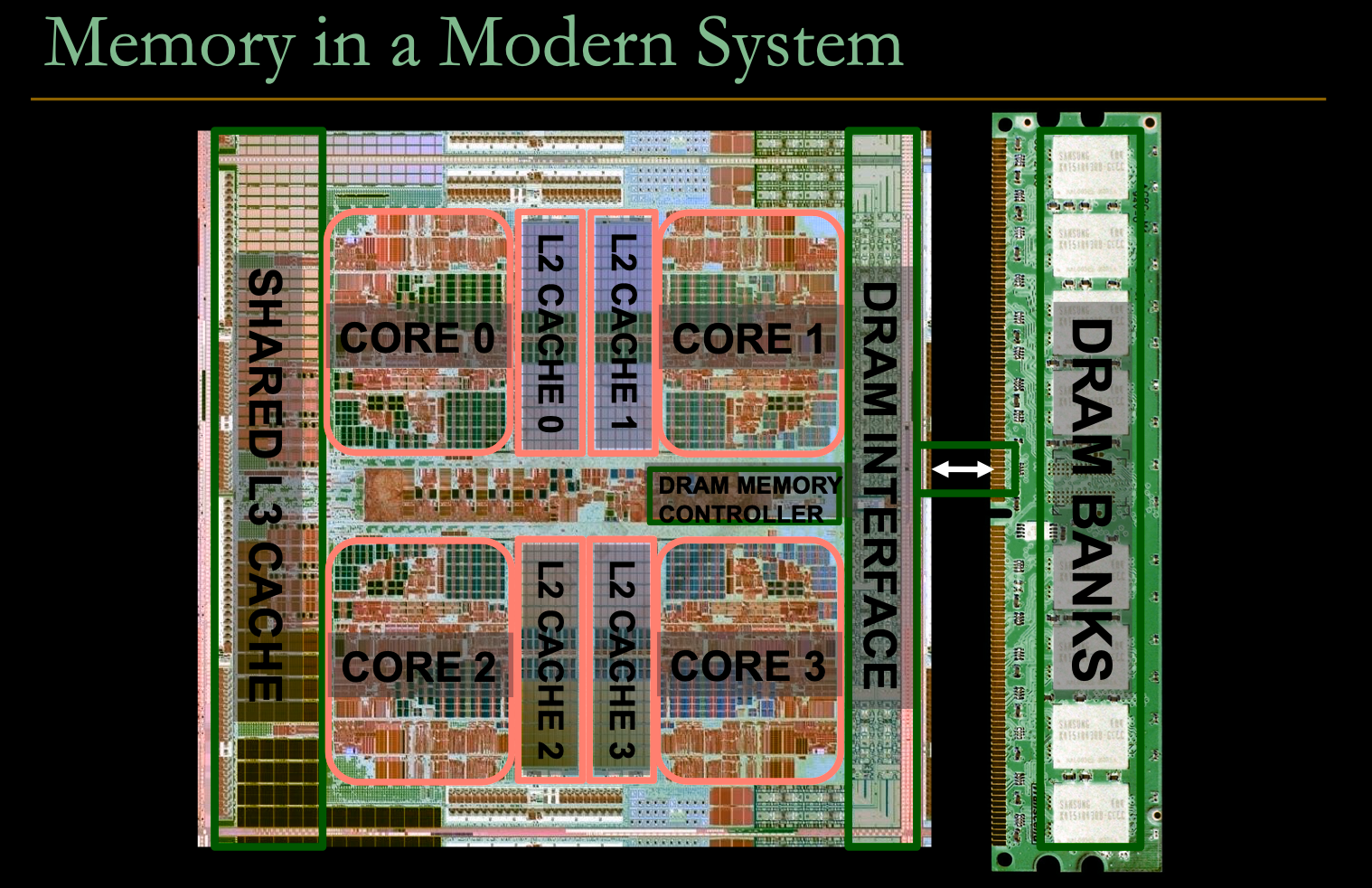
Lectures on computer architecture
Videos and slides about computer architecture by Professor Onur Mutlu
Channel: https://www.youtube.com/channel/UCIwQ8uOeRFgOEvBLYc3kc3g/featured
Professor: https://people.inf.ethz.ch/omutlu/
#hardware #lectures
Videos and slides about computer architecture by Professor Onur Mutlu
Channel: https://www.youtube.com/channel/UCIwQ8uOeRFgOEvBLYc3kc3g/featured
Professor: https://people.inf.ethz.ch/omutlu/
#hardware #lectures
{kind=link}
ODS breakfast in Paris! See you this Saturday (9th of November) at 10:30 at Malongo Café, 50 Rue Saint-André des Arts.
Generalization through Memorization: Nearest Neighbor Language Models
Introduced kNN-LMs, which extend LMs with nearest neighbor search in embedding space, achieving a new SOTA perplexity on Wikitext-103, without additional training!
Also show that kNN-LM can efficiently scale up LMs to larger training sets and allows for effective domain adaptation, by simply varying the nearest neighbor datastore without further training. It seems to be helpful in predicting long tail patterns, such as factual knowledge!
code available soon
Paper: https://arxiv.org/abs/1911.00172
#nlp #generalization #kNN
Introduced kNN-LMs, which extend LMs with nearest neighbor search in embedding space, achieving a new SOTA perplexity on Wikitext-103, without additional training!
Also show that kNN-LM can efficiently scale up LMs to larger training sets and allows for effective domain adaptation, by simply varying the nearest neighbor datastore without further training. It seems to be helpful in predicting long tail patterns, such as factual knowledge!
code available soon
Paper: https://arxiv.org/abs/1911.00172
#nlp #generalization #kNN
{kind=link}
Data science Munich dinner at Nov 8 Fri 20:00, table booked by name Eugen. 12 persons
Wirtshaus Valley´s
Aberlestraße 52, 81371 München
089 76775151
https://maps.app.goo.gl/XyrWcx15LBmMzGZV9
Wirtshaus Valley´s
Aberlestraße 52, 81371 München
089 76775151
https://maps.app.goo.gl/XyrWcx15LBmMzGZV9
Wirtshaus Valley´s · Aberlestraße 52, 81371 München, Germany
★★★★★ · German restaurant
Separate voice from music
Spleeter is the Deezer source separation library with pretrained models written in Python and uses Tensorflow. It makes it easy to train source separation model (assuming you have a dataset of isolated sources), and provides already trained state of the art model for performing various flavor of separation:
* vocals (singing voice) / accompaniment separation (2 stems)
* vocals / drums / bass / other separation (4 stems)
* vocals / drums / bass / piano / other separation (5 stems)
Spleeter is also very fast as it can perform separation of audio files to 4 stems 100x faster than real-time when run on a GPU
blog: https://deezer.io/releasing-spleeter-deezer-r-d-source-separation-engine-2b88985e797e
paper: http://archives.ismir.net/ismir2019/latebreaking/000036.pdf
github: https://github.com/deezer/spleeter
#voice #music #tf
Spleeter is the Deezer source separation library with pretrained models written in Python and uses Tensorflow. It makes it easy to train source separation model (assuming you have a dataset of isolated sources), and provides already trained state of the art model for performing various flavor of separation:
* vocals (singing voice) / accompaniment separation (2 stems)
* vocals / drums / bass / other separation (4 stems)
* vocals / drums / bass / piano / other separation (5 stems)
Spleeter is also very fast as it can perform separation of audio files to 4 stems 100x faster than real-time when run on a GPU
blog: https://deezer.io/releasing-spleeter-deezer-r-d-source-separation-engine-2b88985e797e
paper: http://archives.ismir.net/ismir2019/latebreaking/000036.pdf
github: https://github.com/deezer/spleeter
#voice #music #tf
{kind=link}
Revealing the Dark Secrets of BERT
This work interpretation of self-attention.
Using a subset of GLUE tasks and a set of handcrafted features-of-interest, they proposed the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
The findings suggest that there is a limited set of attention patterns that are repeated across different heads, indicating the overall model overparametrization.
Also, show that manually disabling attention in certain heads leads to a performance improvement over the regular fine-tuned BERT models.
paper: https://arxiv.org/abs/1908.08593
#nlp #bert
This work interpretation of self-attention.
Using a subset of GLUE tasks and a set of handcrafted features-of-interest, they proposed the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
The findings suggest that there is a limited set of attention patterns that are repeated across different heads, indicating the overall model overparametrization.
Also, show that manually disabling attention in certain heads leads to a performance improvement over the regular fine-tuned BERT models.
paper: https://arxiv.org/abs/1908.08593
#nlp #bert
{kind=link}
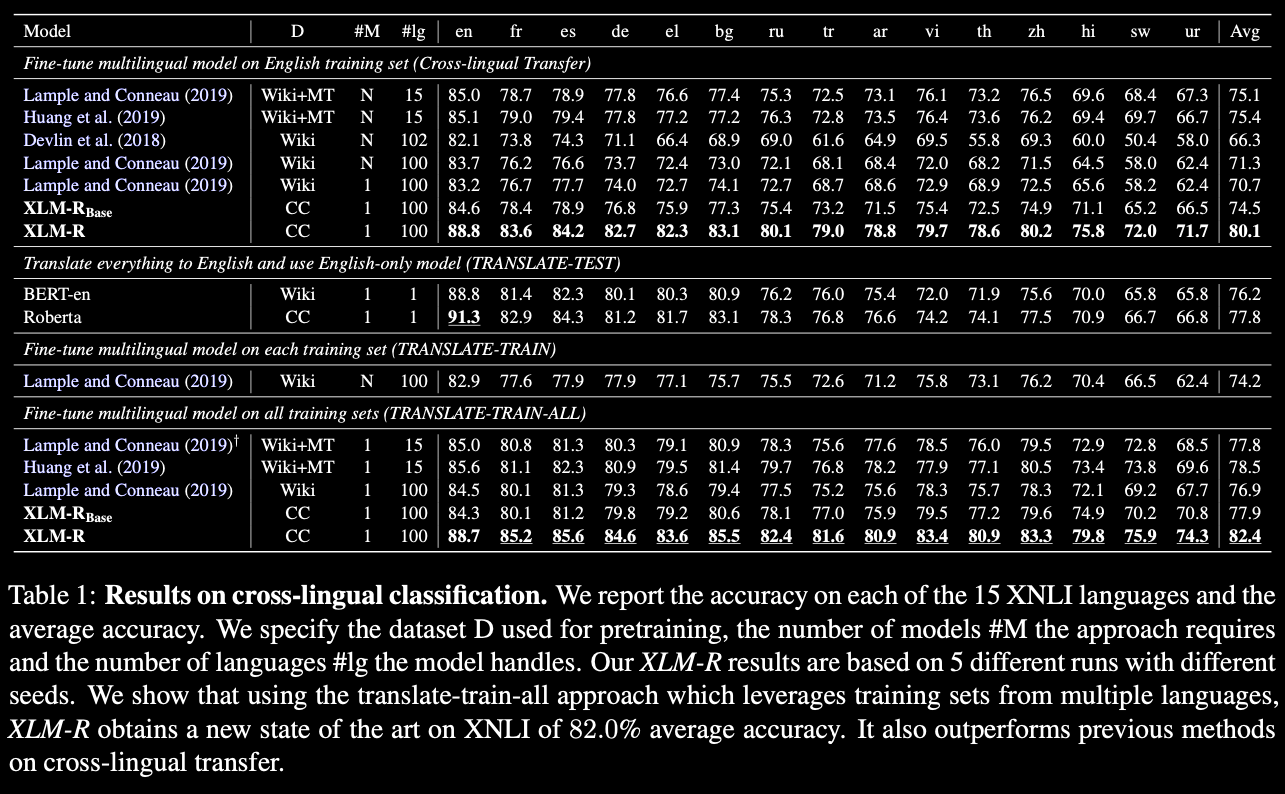
Unsupervised Cross-lingual Representation Learning at Scale
They release XLM-R, a Transformer MLM trained in 100 langs on 2.5 TB of text data! Which obtains state-of-the-art performance on cross-lingual classification, sequence labeling and question answering.
Introduced a comprehensive analysis of the capacity and limits of unsupervised multilingual masked language modeling at scale.
XLM-R especially outperforms mBERT and XLM-100 on low-resource languages, for which CommonCrawl data enables representation learning: +13.7% and +9.3% for Urdu, +21.6% and +13.8% accuracy for Swahili on XNLI.
Soon on transformers by huggingface repo & at tf.hub
paper: https://arxiv.org/abs/1911.02116
code: https://github.com/pytorch/fairseq/tree/master/examples/xlmr
#nlp #bert #xlu #transformer
They release XLM-R, a Transformer MLM trained in 100 langs on 2.5 TB of text data! Which obtains state-of-the-art performance on cross-lingual classification, sequence labeling and question answering.
Introduced a comprehensive analysis of the capacity and limits of unsupervised multilingual masked language modeling at scale.
XLM-R especially outperforms mBERT and XLM-100 on low-resource languages, for which CommonCrawl data enables representation learning: +13.7% and +9.3% for Urdu, +21.6% and +13.8% accuracy for Swahili on XNLI.
Soon on transformers by huggingface repo & at tf.hub
paper: https://arxiv.org/abs/1911.02116
code: https://github.com/pytorch/fairseq/tree/master/examples/xlmr
#nlp #bert #xlu #transformer
{kind=link}
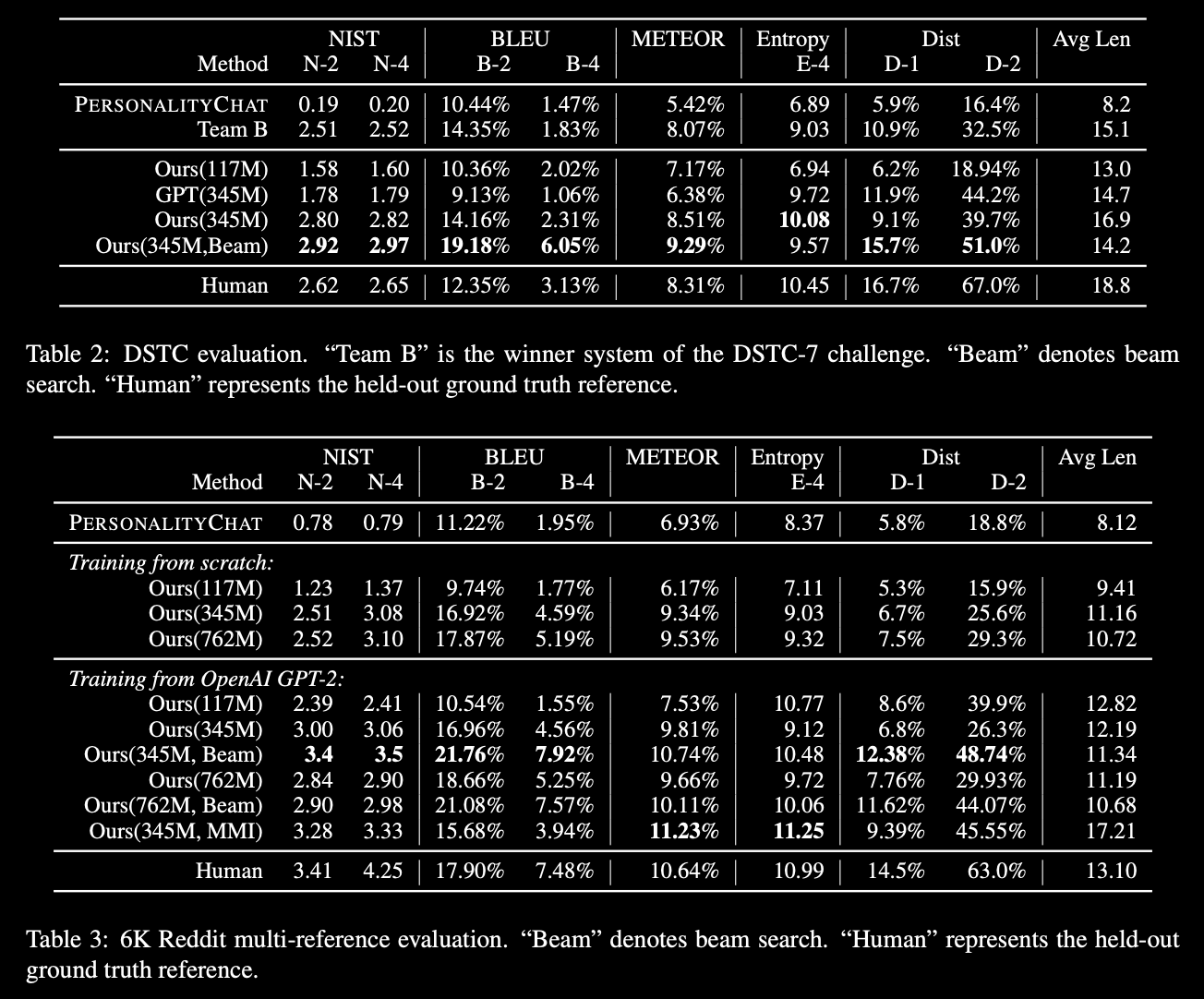
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
tl;dr: GPT2 + Dialogue data = DialoGPT
trained on Reddit comments from 2005 through 2017 (not a very big dataset, about 2Gb)
Paper: https://arxiv.org/abs/1911.00536
Code: https://github.com/microsoft/DialoGPT
Blog: https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/
#nlp #gpt2 #dialog
tl;dr: GPT2 + Dialogue data = DialoGPT
trained on Reddit comments from 2005 through 2017 (not a very big dataset, about 2Gb)
Paper: https://arxiv.org/abs/1911.00536
Code: https://github.com/microsoft/DialoGPT
Blog: https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/
#nlp #gpt2 #dialog
{kind=link}
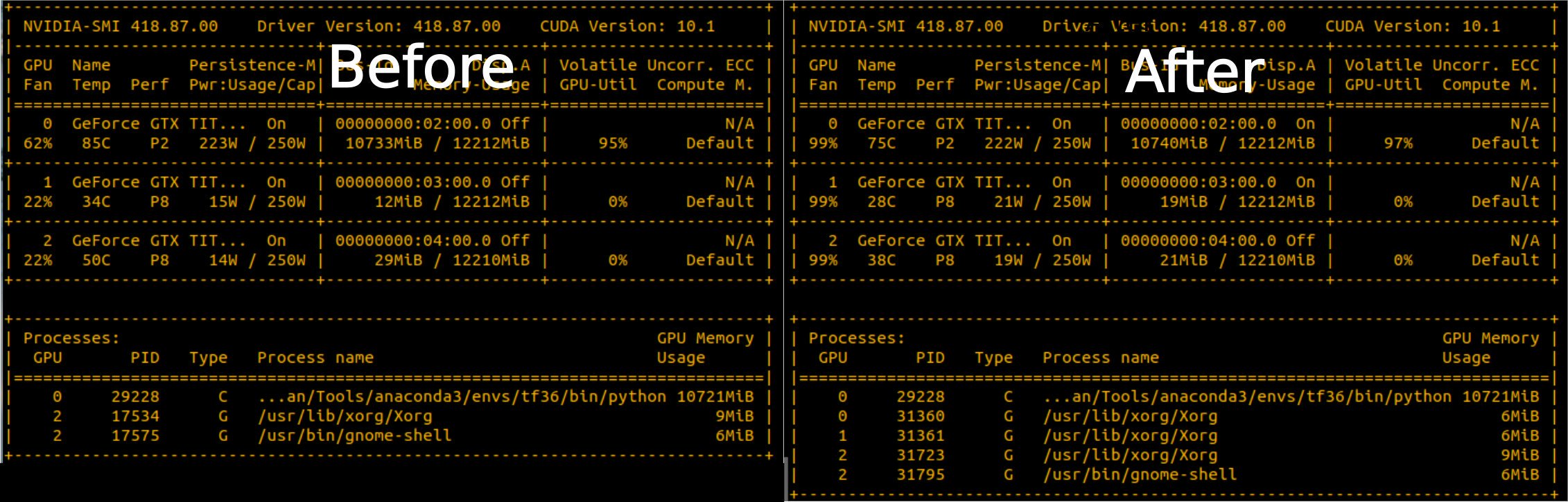
GPU cooling tool
This script lets you set a custom GPU fan curve on a headless Linux server.
If you want to install multiple GPUs in a single machine, you have to use blower-style GPUs else the hot exhaust builds up in your case. Blower-style GPUs can get very loud, so to avoid annoying customers nvidia artificially limits their fans to ~50% duty. At 50% duty and a heavy workload, blower-style GPUs will hot up to 85C or so and throttle themselves.
Now if you're on Windows nvidia happily lets you override that limit by setting a custom fan curve. If you're on Linux though you need to use nvidia-settings, which - as of Sept 2019 - requires a display attached to each GPU you want to set the fan for. This is a pain to set up, as is checking the GPU temp every few seconds and adjusting the fan speed.
This script does all that for you.
Code: https://github.com/andyljones/coolgpus
#hardware #gpu
This script lets you set a custom GPU fan curve on a headless Linux server.
If you want to install multiple GPUs in a single machine, you have to use blower-style GPUs else the hot exhaust builds up in your case. Blower-style GPUs can get very loud, so to avoid annoying customers nvidia artificially limits their fans to ~50% duty. At 50% duty and a heavy workload, blower-style GPUs will hot up to 85C or so and throttle themselves.
Now if you're on Windows nvidia happily lets you override that limit by setting a custom fan curve. If you're on Linux though you need to use nvidia-settings, which - as of Sept 2019 - requires a display attached to each GPU you want to set the fan for. This is a pain to set up, as is checking the GPU temp every few seconds and adjusting the fan speed.
This script does all that for you.
Code: https://github.com/andyljones/coolgpus
#hardware #gpu
{kind=link}
BPE-Dropout: Simple and Effective Subword Regularization
The dominant approach to subword segmentation is Byte Pair Encoding (BPE), which keeps the most frequent words intact while splitting the rare ones into multiple tokens.
And while multiple segmentations are possible even with the same vocabulary, BPE splits words into unique sequences; this may prevent a model from better learning the compositionality of words and being robust to segmentation errors.
In this paper introduced BPE-dropout – simple and effective subword regularization method based on and compatible with conventional BPE.
It stochastically corrupts the segmentation procedure of BPE, which leads to producing multiple segmentations within the same fixed BPE framework.
Using BPE-dropout during training and the standard BPE during inference improves translation quality up to 3 BLEU compared to BPE and up to 0.9 BLEU compared to the previous subword regularization.
Paper: https://arxiv.org/abs/1910.13267
Code: https://github.com/rsennrich/subword-nmt
#nlp #bpe
The dominant approach to subword segmentation is Byte Pair Encoding (BPE), which keeps the most frequent words intact while splitting the rare ones into multiple tokens.
And while multiple segmentations are possible even with the same vocabulary, BPE splits words into unique sequences; this may prevent a model from better learning the compositionality of words and being robust to segmentation errors.
In this paper introduced BPE-dropout – simple and effective subword regularization method based on and compatible with conventional BPE.
It stochastically corrupts the segmentation procedure of BPE, which leads to producing multiple segmentations within the same fixed BPE framework.
Using BPE-dropout during training and the standard BPE during inference improves translation quality up to 3 BLEU compared to BPE and up to 0.9 BLEU compared to the previous subword regularization.
Paper: https://arxiv.org/abs/1910.13267
Code: https://github.com/rsennrich/subword-nmt
#nlp #bpe
{kind=link}
Neural network reconstructs human thoughts from brain waves
in real time
MIPT (top Russian university) researchers published results on mind-reading technology.
Link: https://techxplore.com/news/2019-10-neural-network-reconstructs-human-thoughts.html
Video: https://www.youtube.com/watch?v=nf-P3b2AnZw
#Neuroscience #thoughts2pic #BCI #neuralink #MIPT
in real time
MIPT (top Russian university) researchers published results on mind-reading technology.
Link: https://techxplore.com/news/2019-10-neural-network-reconstructs-human-thoughts.html
Video: https://www.youtube.com/watch?v=nf-P3b2AnZw
#Neuroscience #thoughts2pic #BCI #neuralink #MIPT
YouTube
Нейросети научили "читать мысли" в режиме реального времени
https://www.biorxiv.org/content/10.1101/787101v2
В рамках проекта "Ассистивные нейротехнологии" NeuroNet НТИ сотрудники ГК "Нейроботикс" и МФТИ обучили нейросети воссоздавать изображения по электрической активности мозга, ранее такие эксперименты никем не…
В рамках проекта "Ассистивные нейротехнологии" NeuroNet НТИ сотрудники ГК "Нейроботикс" и МФТИ обучили нейросети воссоздавать изображения по электрической активности мозга, ранее такие эксперименты никем не…
Using AI to Understand What Causes Diseases
An overview on applying data science in healthcare
Poster: https://info.gnshealthcare.com/hubfs/Publications_2019/ESMO_GI_Final_Poster_Printed_PD_20.pdf
Link: https://hbr.org/2019/11/using-ai-to-understand-what-causes-diseases
#meta #biolearning #dl #medical #healthcare
An overview on applying data science in healthcare
Poster: https://info.gnshealthcare.com/hubfs/Publications_2019/ESMO_GI_Final_Poster_Printed_PD_20.pdf
Link: https://hbr.org/2019/11/using-ai-to-understand-what-causes-diseases
#meta #biolearning #dl #medical #healthcare