
Machine Learning for Everyone.
The best general intro post about Machine Learning, covering everything you need to know not to get overxcited about SkyNet and to get general understanding of all #ML / #AI hype. You can surely save this post into «Saved messages» and forward it to your friends to make them familiar with the subject
Link: https://vas3k.com/blog/machine_learning/
#entrylevel #novice #general
The best general intro post about Machine Learning, covering everything you need to know not to get overxcited about SkyNet and to get general understanding of all #ML / #AI hype. You can surely save this post into «Saved messages» and forward it to your friends to make them familiar with the subject
Link: https://vas3k.com/blog/machine_learning/
#entrylevel #novice #general
Vas3K
None
How to read any scientific paper
Reading any paper is hard. And let's admit, it takes time and cognitive resources. Sometimes it may take hours to understand 1 page. If you are constantly skipping or have no clue at all on how to read scientific paper, there is a guide from TNW.
Link: https://thenextweb.com/basics/2019/06/14/how-to-read-a-scientific-research-paper/
#general
Reading any paper is hard. And let's admit, it takes time and cognitive resources. Sometimes it may take hours to understand 1 page. If you are constantly skipping or have no clue at all on how to read scientific paper, there is a guide from TNW.
Link: https://thenextweb.com/basics/2019/06/14/how-to-read-a-scientific-research-paper/
#general
The Next Web
How to read a scientific research paper
Welcome to TNW Basics, a collection of tips, guides, and advice on how to easily get the most out of your gadgets, apps, and other stuff. One of the most important skills any discerning media consumer can have is the ability to comprehend a scientific research…
Using AI to generate recipes from food images
Facebook developed image 2 recipe architecture.
Link: https://ai.facebook.com/blog/inverse-cooking/
Paper: https://research.fb.com/publications/inverse-cooking-recipe-generation-from-food-images/
Code: https://github.com/facebookresearch/inversecooking
#CV #DL
Facebook developed image 2 recipe architecture.
Link: https://ai.facebook.com/blog/inverse-cooking/
Paper: https://research.fb.com/publications/inverse-cooking-recipe-generation-from-food-images/
Code: https://github.com/facebookresearch/inversecooking
#CV #DL
{kind=link}
ODS breakfast in Paris! See you this Saturday at 10:30 at Malongo Café, 50 Rue Saint-André des Arts.
You are kindly welcome to submit any news / content you would like to share through the bot, whose message been forwarded above. If you want to increase probability of content being posted, please do follow the structure we use in our channel, providing title, short description and hashtags for the post.
A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruction
This paper receive best paper award at #CVPR2019.
Main idea: seeing around the corner at non-line-of-sight (NLOS) objects by using Fermat paths, which is a new theory of how NLOS photons follow specific geometric paths.
Link: http://imaging.cs.cmu.edu/fermat_paths/assets/cvpr2019.pdf
This paper receive best paper award at #CVPR2019.
Main idea: seeing around the corner at non-line-of-sight (NLOS) objects by using Fermat paths, which is a new theory of how NLOS photons follow specific geometric paths.
Link: http://imaging.cs.cmu.edu/fermat_paths/assets/cvpr2019.pdf
{kind=link}
Accelerating MRI reconstruction via active acquisition
Researchers from #Facebook AI propose a new approach to MRI reconstruction that restores a high fidelity image from partially observed measurements in less time and with fewer errors.
Link: https://ai.facebook.com/blog/accelerating-mri-reconstruction/
Paper link: https://research.fb.com/publications/reducing-uncertainty-in-undersampled-mri-reconstruction-with-active-acquisition/
#CV #DL #CVPR2019 #healthcare #MRI #biolearning
Researchers from #Facebook AI propose a new approach to MRI reconstruction that restores a high fidelity image from partially observed measurements in less time and with fewer errors.
Link: https://ai.facebook.com/blog/accelerating-mri-reconstruction/
Paper link: https://research.fb.com/publications/reducing-uncertainty-in-undersampled-mri-reconstruction-with-active-acquisition/
#CV #DL #CVPR2019 #healthcare #MRI #biolearning
{kind=link}
Ranking Items With Star Ratings and How Not To Sort By Average Rating
Two absolute must read articles for proper sorting handling. Sorting items with just an average score is wrong and there is some good classic statistics explanation why.
Link: https://www.evanmiller.org/ranking-items-with-star-ratings.html
Link2: https://www.evanmiller.org/how-not-to-sort-by-average-rating.html
#Statistics #rating #scoring #ranking
Two absolute must read articles for proper sorting handling. Sorting items with just an average score is wrong and there is some good classic statistics explanation why.
Link: https://www.evanmiller.org/ranking-items-with-star-ratings.html
Link2: https://www.evanmiller.org/how-not-to-sort-by-average-rating.html
#Statistics #rating #scoring #ranking
www.evanmiller.org
How Not To Sort By Average Rating
Users are rating items on your website. How do you know what the highest-rated items are?
Intro to Pythia — Visual Question Answering framework from Facebook
Pythia works in terms of #VQA by taking input picture and question and providing the answer to the latter in terms of picture semantics.
Link: https://link.medium.com/dknDKSuVqX
Previously: https://yangx.top/opendatascience/812
#DL #facebook #pythia #VQA #opensource
Pythia works in terms of #VQA by taking input picture and question and providing the answer to the latter in terms of picture semantics.
Link: https://link.medium.com/dknDKSuVqX
Previously: https://yangx.top/opendatascience/812
#DL #facebook #pythia #VQA #opensource
Medium
Pythia (Facebook)— Greek god doing Deep learning
“Artificial Intelligence” in 2019 has been exciting, Can it be more exciting than this? Guess what I found an answer for it and the answer…
Introducing MASS – A pre-training method that outperforms BERT and GPT in sequence to sequence language generation tasks
Researchers from Microsoft Research Asia have introduced MASS—a new pre-training method that claimed to achieve better results than BERT and GPT.
Link: https://www.microsoft.com/en-us/research/blog/introducing-mass-a-pre-training-method-that-outperforms-bert-and-gpt-in-sequence-to-sequence-language-generation-tasks/
#nlp #microsoft
Researchers from Microsoft Research Asia have introduced MASS—a new pre-training method that claimed to achieve better results than BERT and GPT.
Link: https://www.microsoft.com/en-us/research/blog/introducing-mass-a-pre-training-method-that-outperforms-bert-and-gpt-in-sequence-to-sequence-language-generation-tasks/
#nlp #microsoft
Microsoft Research
Introducing MASS – A pre-training method that outperforms BERT and GPT in sequence to sequence language generation tasks
Pre-training is a hot topic in NLP research and models like BERT and GPT have definitely delivered exciting breakthroughs. The challenge is in upping our game in finer sequence to sequence based language generation tasks. Enter MASS. Click the link in our…
Neural network to undress people on photo
App / web service is released to uncover naked body under the clothes. Works better on swimsuits pictures. Currently website is overloaded and down, updates on the matter are on twitter.
Team's twitter: https://twitter.com/deepnudeapp
Vice article: https://www.vice.com/en_us/article/kzm59x/deepnude-app-creates-fake-nudes-of-any-woman
Website: http://deepnude.com
#HypeNN #DL #CV #nudes
App / web service is released to uncover naked body under the clothes. Works better on swimsuits pictures. Currently website is overloaded and down, updates on the matter are on twitter.
Team's twitter: https://twitter.com/deepnudeapp
Vice article: https://www.vice.com/en_us/article/kzm59x/deepnude-app-creates-fake-nudes-of-any-woman
Website: http://deepnude.com
#HypeNN #DL #CV #nudes
{kind=link}
ODS breakfast in Paris! See you this Saturday at 10:30 at Malongo Café, 50 Rue Saint-André des Arts.
Communauté francaise de Machine Learning / Data science - dscientist
Bonjour,
Il existe des communautés anglaises, russes de Machine Learning. En France, il y a de quelques petites communauté (basée sur la localisation ou le domaine spécifique) mais pas une communauté globale. Aujourd'hui dscientist.slack.com est né et permet de regrouper les personnes francophones s'intéressants à ces domaines. L'objectif principal est le partage d'expériences, de connaissances et une veille commune sur l'IA et le ML.
Si vous êtes intéressé(e), rejoignez cette communauté via le lien ci-dessous.
Link: https://docs.google.com/forms/d/1g7v9MpzhgXgDUyAtLDU5MSh78DDaBhGYJgFV1Ys46EU
Bonjour,
Il existe des communautés anglaises, russes de Machine Learning. En France, il y a de quelques petites communauté (basée sur la localisation ou le domaine spécifique) mais pas une communauté globale. Aujourd'hui dscientist.slack.com est né et permet de regrouper les personnes francophones s'intéressants à ces domaines. L'objectif principal est le partage d'expériences, de connaissances et une veille commune sur l'IA et le ML.
Si vous êtes intéressé(e), rejoignez cette communauté via le lien ci-dessous.
Link: https://docs.google.com/forms/d/1g7v9MpzhgXgDUyAtLDU5MSh78DDaBhGYJgFV1Ys46EU
Google Docs
Inscription au slack dscientist francophone
New free Deep Learning course from #FastAI
This course shows how to build a state of the art deep learning model from scratch.
FastAI’s mission is to make neural nets uncool again by teaching as many people from as many backgrounds as possible.
Link: https://www.fast.ai/2019/06/28/course-p2v3/
#MOOC #DL #freecourse
This course shows how to build a state of the art deep learning model from scratch.
FastAI’s mission is to make neural nets uncool again by teaching as many people from as many backgrounds as possible.
Link: https://www.fast.ai/2019/06/28/course-p2v3/
#MOOC #DL #freecourse
Google announced the updated YouTube-8M dataset
Updated set now includes a subset with verified 5-s segment level labels, along with the 3rd Large-Scale Video Understanding Challenge and Workshop at #ICCV19.
Link: https://ai.googleblog.com/2019/06/announcing-youtube-8m-segments-dataset.html
#Google #YouTube #CV #DL #Video #dataset
Updated set now includes a subset with verified 5-s segment level labels, along with the 3rd Large-Scale Video Understanding Challenge and Workshop at #ICCV19.
Link: https://ai.googleblog.com/2019/06/announcing-youtube-8m-segments-dataset.html
#Google #YouTube #CV #DL #Video #dataset
{kind=link}
ML system used to create complex and accurate simulation of the universe
The speed and accuracy of the project, called the Deep Density Displacement Model, or #D3M for short, wasn't the biggest surprise to the researchers. The real shock was that D3M could accurately simulate how the universe would look if certain parameters were tweaked — such as how much of the cosmos is dark matter — even though the model had never received any training data where those parameters varied.
Link: https://phys.org/news/2019-06-ai-universe-sim-fast-accurateand.html
#Physics #DL #simulation
The speed and accuracy of the project, called the Deep Density Displacement Model, or #D3M for short, wasn't the biggest surprise to the researchers. The real shock was that D3M could accurately simulate how the universe would look if certain parameters were tweaked — such as how much of the cosmos is dark matter — even though the model had never received any training data where those parameters varied.
Link: https://phys.org/news/2019-06-ai-universe-sim-fast-accurateand.html
#Physics #DL #simulation
phys.org
The first AI universe sim is fast and accurate—and its creators don't know how it works
For the first time, astrophysicists have used artificial intelligence techniques to generate complex 3-D simulations of the universe. The results are so fast, accurate and robust that even the creators ...
💣New open-source recommender system from Facebook.
Facebook is open-sourcing DLRM — a state-of-the-art deep learning recommendation model to help AI researchers and the systems and hardware community develop new, more efficient ways to work with categorical data.
Link: https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep-learning-recommendation-model/
Github: https://github.com/facebookresearch/dlrm
ArXiV: https://arxiv.org/abs/1906.03109
#Facebook #DLRM #recommender #DL #PyTorch #Caffe
Facebook is open-sourcing DLRM — a state-of-the-art deep learning recommendation model to help AI researchers and the systems and hardware community develop new, more efficient ways to work with categorical data.
Link: https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep-learning-recommendation-model/
Github: https://github.com/facebookresearch/dlrm
ArXiV: https://arxiv.org/abs/1906.03109
#Facebook #DLRM #recommender #DL #PyTorch #Caffe
👍1
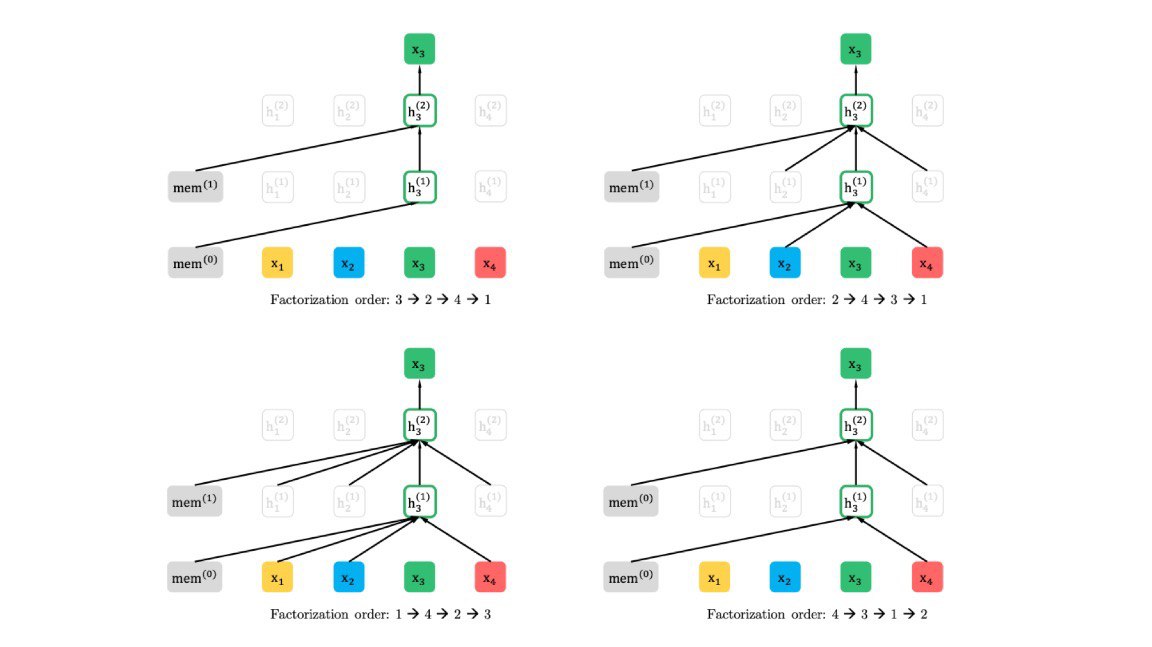
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Researchers at Google Brain and Carnegie Mellon introduce #XLNet, a pre-training algorithm for natural language processing systems. It helps NLP models (in this case, based on Transformer-XL) achieve state-of-the-art results in 18 diverse language-understanding tasks including question answering and sentiment analysis.
Article: https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335
ArXiV: https://arxiv.org/pdf/1906.08237.pdf
#Google #GoogleBrain #CMU #NLP #SOTA #DL
Researchers at Google Brain and Carnegie Mellon introduce #XLNet, a pre-training algorithm for natural language processing systems. It helps NLP models (in this case, based on Transformer-XL) achieve state-of-the-art results in 18 diverse language-understanding tasks including question answering and sentiment analysis.
Article: https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335
ArXiV: https://arxiv.org/pdf/1906.08237.pdf
#Google #GoogleBrain #CMU #NLP #SOTA #DL
{kind=link}
0.2 release of PyTorchPipe
Library for multi-modal deep learning pipelines, in a modular fashion for GPU and CPU.
Link: https://github.com/IBM/pytorchpipe
#IBM #PyTorch
Library for multi-modal deep learning pipelines, in a modular fashion for GPU and CPU.
Link: https://github.com/IBM/pytorchpipe
#IBM #PyTorch
GitHub
GitHub - IBM/pytorchpipe: PyTorchPipe (PTP) is a component-oriented framework for rapid prototyping and training of computational…
PyTorchPipe (PTP) is a component-oriented framework for rapid prototyping and training of computational pipelines combining vision and language - GitHub - IBM/pytorchpipe: PyTorchPipe (PTP) is a co...