
Distributed Representations of Words and Phrases and their Compositionality
Several extensions to #SkipGram that improve both the quality of the vectors and the training speed
ArXiV: https://arxiv.org/abs/1310.4546
#NLP #oldenough
Several extensions to #SkipGram that improve both the quality of the vectors and the training speed
ArXiV: https://arxiv.org/abs/1310.4546
#NLP #oldenough
arXiv.org
Distributed Representations of Words and Phrases and their Compositionality
The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic...
Real-Time Patch-Based Stylization of Portraits Using Generative Adversarial Network
Face photo stylization from #Snap research team. Rather fast solution with demo available.
Demo: http://facestyle.org/#
Paper: https://dcgi.fel.cvut.cz/home/sykorad/Futschik19-NPAR.pdf
YouTube: https://www.youtube.com/watch?v=G3nwTSd3_XA
#GAN #DL #Styletransfer
Face photo stylization from #Snap research team. Rather fast solution with demo available.
Demo: http://facestyle.org/#
Paper: https://dcgi.fel.cvut.cz/home/sykorad/Futschik19-NPAR.pdf
YouTube: https://www.youtube.com/watch?v=G3nwTSd3_XA
#GAN #DL #Styletransfer
{kind=link}
Speech synthesis from neural decoding of spoken sentences
Researchers tapped the brains of five epilepsy patients who had been implanted with electrodes to map the source of seizures, according to a paper published by #Nature. During a lull in the procedure, they had the patients read English-language texts aloud. They recorded the fluctuating voltage as the brain controlled the muscles involved in speaking. Later, they fed the voltage measurements into a synthesizer.
Nature: https://www.nature.com/articles/s41586-019-1119-1
Paper: https://www.biorxiv.org/content/biorxiv/early/2018/11/29/481267.full.pdf
YouTube: https://www.youtube.com/watch?v=kbX9FLJ6WKw
#DeepDiveWeekly #DL #speech #audiolearning
Researchers tapped the brains of five epilepsy patients who had been implanted with electrodes to map the source of seizures, according to a paper published by #Nature. During a lull in the procedure, they had the patients read English-language texts aloud. They recorded the fluctuating voltage as the brain controlled the muscles involved in speaking. Later, they fed the voltage measurements into a synthesizer.
Nature: https://www.nature.com/articles/s41586-019-1119-1
Paper: https://www.biorxiv.org/content/biorxiv/early/2018/11/29/481267.full.pdf
YouTube: https://www.youtube.com/watch?v=kbX9FLJ6WKw
#DeepDiveWeekly #DL #speech #audiolearning
Nature
Speech synthesis from neural decoding of spoken sentences
Nature - A neural decoder uses kinematic and sound representations encoded in human cortical activity to synthesize audible sentences, which are readily identified and transcribed by listeners.
Unsupervised community detection with modularity-based attention model
Searching for communities on graphs is hard -> no clear loss, discrete labels (usually). What we do: use soft log-liklehood approximation with tricks + GNNs to try to match classical SOTA.
Paper: https://rlgm.github.io/papers/37.pdf
#ICLR2019 #GNN #GraphLearning
Searching for communities on graphs is hard -> no clear loss, discrete labels (usually). What we do: use soft log-liklehood approximation with tricks + GNNs to try to match classical SOTA.
Paper: https://rlgm.github.io/papers/37.pdf
#ICLR2019 #GNN #GraphLearning
👍1
The lottery ticket hypothesis: finding sparse, trainable neural networks
Best paper award at #ICLR2019 main idea: dense, randomly-initialized, networks contain sparse subnetworks that trained in isolation reach test accuracy comparable to the original network. Thus compressing the original network up to 10% its original size.
Paper: https://arxiv.org/pdf/1803.03635.pdf
#nn #research
Best paper award at #ICLR2019 main idea: dense, randomly-initialized, networks contain sparse subnetworks that trained in isolation reach test accuracy comparable to the original network. Thus compressing the original network up to 10% its original size.
Paper: https://arxiv.org/pdf/1803.03635.pdf
#nn #research
Modeling Price with Regularized Linear Model & #XGBoost
Great example of applicable research for #production #ML.
Link: https://www.kdnuggets.com/2019/05/modeling-price-regularized-linear-model-xgboost.html
#novice #entrylevel
Great example of applicable research for #production #ML.
Link: https://www.kdnuggets.com/2019/05/modeling-price-regularized-linear-model-xgboost.html
#novice #entrylevel
{kind=link}
Forwarded from Hacker News
The Feynman Lectures on Physics now free (Score: 100+ in 17 hours)
Link: https://readhacker.news/s/43fFn
Comments: https://readhacker.news/c/43fFn
Link: https://readhacker.news/s/43fFn
Comments: https://readhacker.news/c/43fFn
🐣 Conversational AI building tutorial, open-source code & demo!
Building a SOTA Conversational AI with transfer learning & OpenAI GPT models
Code/pretrained model from NeurIPS 2018 ConvAI2 competition model, SOTA on automatic track
Detailed Tutorial w. code
Tutorial: https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313
Demo: http://convai.huggingface.co
Code: https://github.com/huggingface/transfer-learning-conv-ai
#tutorial #novice
Building a SOTA Conversational AI with transfer learning & OpenAI GPT models
Code/pretrained model from NeurIPS 2018 ConvAI2 competition model, SOTA on automatic track
Detailed Tutorial w. code
Tutorial: https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313
Demo: http://convai.huggingface.co
Code: https://github.com/huggingface/transfer-learning-conv-ai
#tutorial #novice
Forwarded from Karim Iskakov - канал (karfly_bot)
This media is not supported in your browser
VIEW IN TELEGRAM
"I'm very proud to share our first paper Learnable Triangulation of Human Pose. We smashed previous state of the art (by ~2.5x) in multi-view 3D human pose estimation. Like, share, cite!"
🔎 saic-violet.github.io/learnable-triangulation
🔎 arxiv.org/abs/1905.05754
📉 @loss_function_porn
🔎 saic-violet.github.io/learnable-triangulation
🔎 arxiv.org/abs/1905.05754
📉 @loss_function_porn
End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography
Researchers from #GoogleAi and #Stanford published work today in #Nature that shows great potential to use machine learning to help catch more lung cancer cases earlier and increase survival likelihood.
Link: http://go.nature.com/2LSMaAz
#LungCancer #Cancer #biolearning #healthcare #DL #CV
Researchers from #GoogleAi and #Stanford published work today in #Nature that shows great potential to use machine learning to help catch more lung cancer cases earlier and increase survival likelihood.
Link: http://go.nature.com/2LSMaAz
#LungCancer #Cancer #biolearning #healthcare #DL #CV
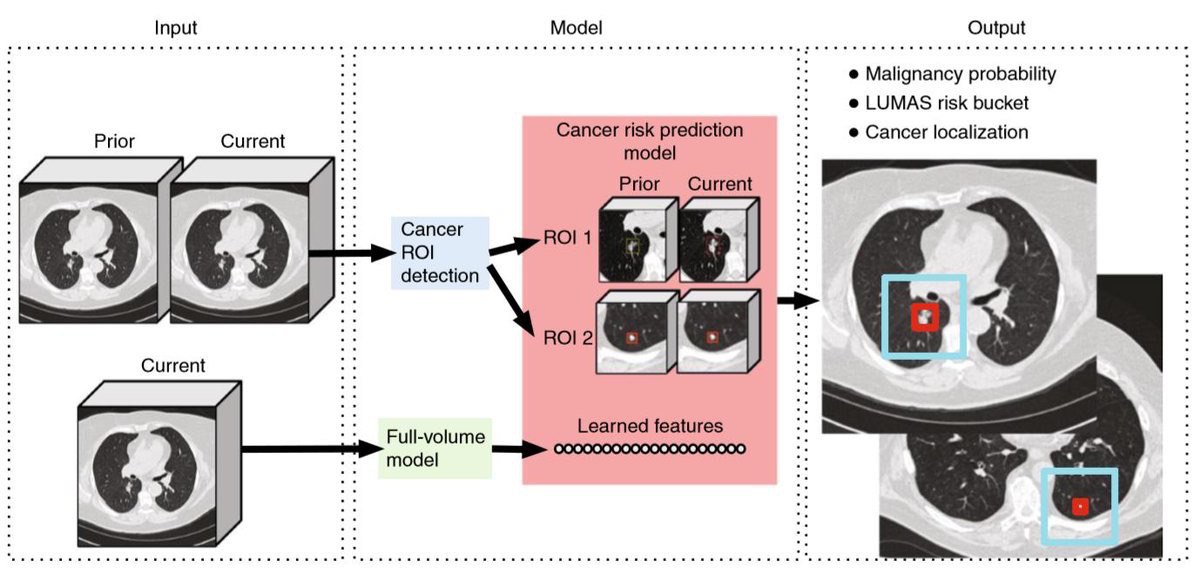{kind=link}
New deep learning framework from Facebook
Pythia is a deep learning framework that supports multitasking in the vision and language domain. Built on our open-source #PyTorch framework, the modular, plug-and-play design enables researchers to quickly build, reproduce, and benchmark AI models. #Pythia is designed for vision and language tasks, such as answering questions related to visual data and automatically generating image captions.
Link: https://code.fb.com/ai-research/pythia/
GitHub: https://github.com/facebookresearch/pythia
#Facebook #FacebookAI #DL #CV #multimodal
Pythia is a deep learning framework that supports multitasking in the vision and language domain. Built on our open-source #PyTorch framework, the modular, plug-and-play design enables researchers to quickly build, reproduce, and benchmark AI models. #Pythia is designed for vision and language tasks, such as answering questions related to visual data and automatically generating image captions.
Link: https://code.fb.com/ai-research/pythia/
GitHub: https://github.com/facebookresearch/pythia
#Facebook #FacebookAI #DL #CV #multimodal
Engineering at Meta
Releasing Pythia for vision and language multimodal AI models
Pythia is a new open source deep learning framework that enables researchers to quickly build, reproduce, and benchmark AI models.
Parisian Open Data Science branch is growing!
Come to have a coffee with a fellow Data Scientists. We speak English, Russian or French. This Saturday, 25th of May, at 10h30 at Malongo Cafe, 50 Rue Saint-André des Arts.
Come to have a coffee with a fellow Data Scientists. We speak English, Russian or French. This Saturday, 25th of May, at 10h30 at Malongo Cafe, 50 Rue Saint-André des Arts.
Parallel Neural Text-to-Speech
#Baidu Research team has reached a new milestone in text-to-speech (#TTS) with the release of the first fully parallel neural TTS system. It generates speech from text with a single feed-forward pass, which brings ~17.5X speed-up over previous autoregressive models.
Link: https://arxiv.org/pdf/1905.08459.pdf
#Baidu Research team has reached a new milestone in text-to-speech (#TTS) with the release of the first fully parallel neural TTS system. It generates speech from text with a single feed-forward pass, which brings ~17.5X speed-up over previous autoregressive models.
Link: https://arxiv.org/pdf/1905.08459.pdf
Head animation from single shot by #SamsungAI team
Samsung researchers have released a model that can generate faces in new poses from just a single image/frame (for each of face, pose). Done by building a well-trained landmark model in advance & one-shotting from that, using keypoints, adaptive instance norms and GANs. Model performs no 3D face modelling!
ArXiV: https://arxiv.org/abs/1905.08233v1
Youtube: https://www.youtube.com/watch?v=p1b5aiTrGzY
#GAN #CV #DL
Samsung researchers have released a model that can generate faces in new poses from just a single image/frame (for each of face, pose). Done by building a well-trained landmark model in advance & one-shotting from that, using keypoints, adaptive instance norms and GANs. Model performs no 3D face modelling!
ArXiV: https://arxiv.org/abs/1905.08233v1
Youtube: https://www.youtube.com/watch?v=p1b5aiTrGzY
#GAN #CV #DL
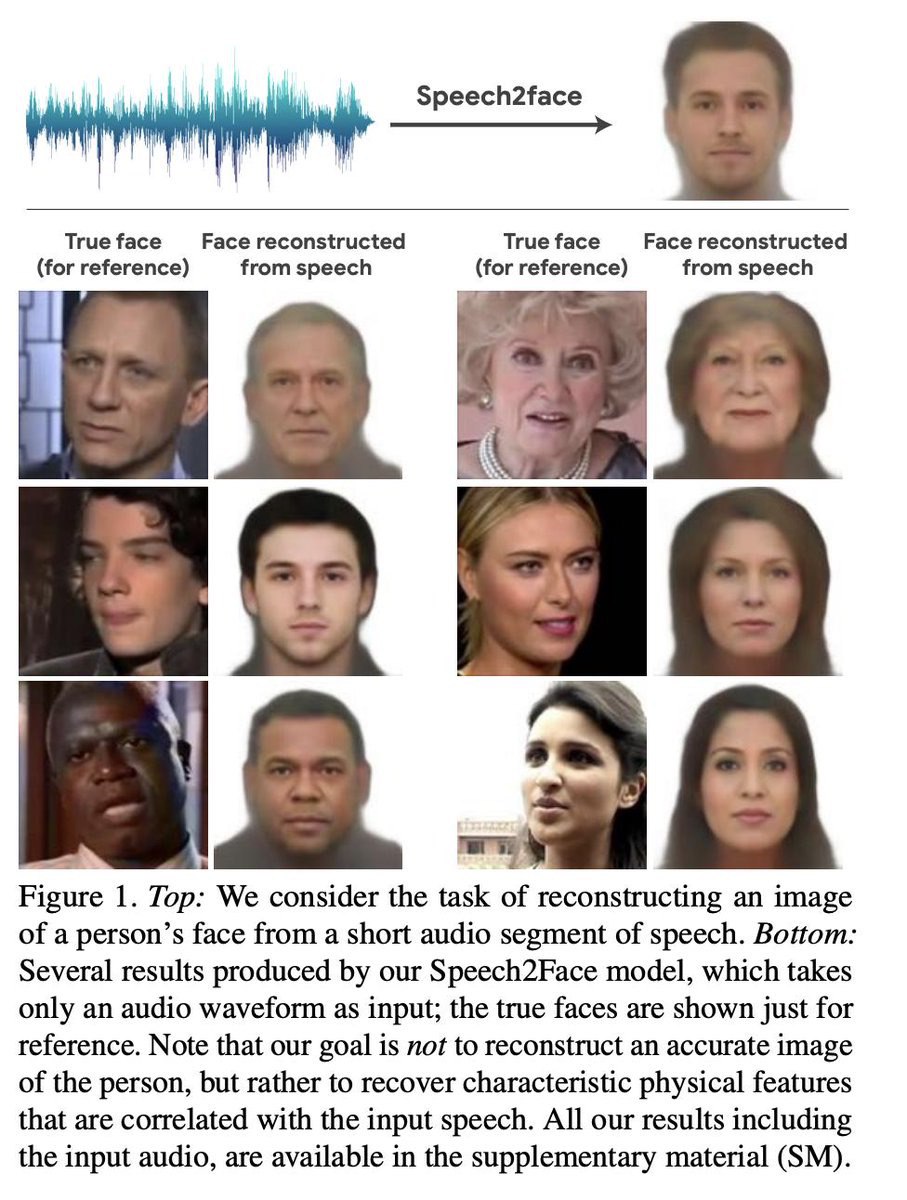
Recovering person appereance from person’s speech
As the result of the research, much resembling facial image of a person reconstructed from short audio recording of that person speaking.
ArXiV: https://arxiv.org/pdf/1905.09773v1.pdf
#speech #audiolearning #CV #DL #face
As the result of the research, much resembling facial image of a person reconstructed from short audio recording of that person speaking.
ArXiV: https://arxiv.org/pdf/1905.09773v1.pdf
#speech #audiolearning #CV #DL #face
{kind=link}
🇮🇹If by any chance you are in Venice for week or two and would like to meet and talk about Data Science and have some caffe normale, pm @malev.
Set of animated Artificial Intelligence cheatsheets covering Stanford's CS 221 class:
Reflex-based: http://stanford.io/2EqNPHy
States-based: http://stanford.io/2wh4F7u
Variables-based: http://stanford.io/2HAiAfh
Logic-based: http://stanford.io/2M7taia
GitHub: https://github.com/afshinea/stanford-cs-221-artificial-intelligence
#cheatsheet #Stanford
Reflex-based: http://stanford.io/2EqNPHy
States-based: http://stanford.io/2wh4F7u
Variables-based: http://stanford.io/2HAiAfh
Logic-based: http://stanford.io/2M7taia
GitHub: https://github.com/afshinea/stanford-cs-221-artificial-intelligence
#cheatsheet #Stanford
MetroTwitter - What Twitter reveals about the differences between cities and the monoculture of the Bay Area
Researcher collected 96K bios + 180M tweets from Twitters users in 13 major cities and visualized the differences between these cities:
- How people describe themselves
- What they talk about
- Popular emojis
- Most unique city
Code and data are open-sourced.
Website: https://huyenchip.com/2019/05/28/metrotwitter.html
GitHub: https://github.com/chiphuyen/MetroTwitter
#openresearch
Researcher collected 96K bios + 180M tweets from Twitters users in 13 major cities and visualized the differences between these cities:
- How people describe themselves
- What they talk about
- Popular emojis
- Most unique city
Code and data are open-sourced.
Website: https://huyenchip.com/2019/05/28/metrotwitter.html
GitHub: https://github.com/chiphuyen/MetroTwitter
#openresearch
Huyenchip
MetroTwitter - What Twitter reveals about the differences between cities and the monoculture of the Bay Area
Disclaimer:
Small $ 60 camera for #CV tasks
JeVois — video sensor + quad-core CPU + USB video + serial port, all in a tiny, self-contained package size of a small coin.
YouTube: https://www.youtube.com/watch?v=7cTfOckkGlE
Project site: http://jevois.org
Link for shop: https://www.jevoisinc.com
#deeplearning #hardware #tensorflow
JeVois — video sensor + quad-core CPU + USB video + serial port, all in a tiny, self-contained package size of a small coin.
YouTube: https://www.youtube.com/watch?v=7cTfOckkGlE
Project site: http://jevois.org
Link for shop: https://www.jevoisinc.com
#deeplearning #hardware #tensorflow
YouTube
JeVois smart machine vision camera: kickstarter video
Open-source quad-core camera effortlessly adds powerful machine vision to all your PC/Arduino/Raspberry Pi projects.
http://jevois.org
Open-source machine vision finally ready for prime-time in all your projects!
JeVois = video sensor + quad-core CPU…
http://jevois.org
Open-source machine vision finally ready for prime-time in all your projects!
JeVois = video sensor + quad-core CPU…
Panel: A high-level app and dashboarding solution for the PyData ecosystem.
New framework for handling python dashboards.
Link: https://medium.com/@philipp.jfr/panel-announcement-2107c2b15f52
#vizualization #panel #metrics #dashboard #python
New framework for handling python dashboards.
Link: https://medium.com/@philipp.jfr/panel-announcement-2107c2b15f52
#vizualization #panel #metrics #dashboard #python
Medium
Panel
A high-level app and dashboarding solution for the PyData ecosystem.