
Really interesting talk at MLconfSF by Franziska Bell on how #Uber uses NLP for customer experience. Most of what was described are recent advances in their COTA platform.
Link: https://eng.uber.com/cota/
Link: https://eng.uber.com/cota/
{kind=link}
DeepMasterPrints: Generating MasterPrints for Dictionary Attacks via Latent Variable Evolution
Using GANs to generate MasterFingerPrints that unlock 22-78% phones sensors (dep. on security level of sensor). It doesn't get much more "adversarial" than that.
This work can be potentially used to create fingerprint which can be used to match 22-78% of fingerprints in the wild, creating Skeleton key, fitting any security system, including home alarm or phone lock.
ArXiV: https://arxiv.org/pdf/1705.07386.pdf
#GAN #security #fingerprint
Using GANs to generate MasterFingerPrints that unlock 22-78% phones sensors (dep. on security level of sensor). It doesn't get much more "adversarial" than that.
This work can be potentially used to create fingerprint which can be used to match 22-78% of fingerprints in the wild, creating Skeleton key, fitting any security system, including home alarm or phone lock.
ArXiV: https://arxiv.org/pdf/1705.07386.pdf
#GAN #security #fingerprint
{kind=link}
Sptoify announced its new Data Science Challenge
Spotify Sequential Skip Prediction Challenge is a part of #WSDM Cup 2019. The dataset comprises 130M Spotify listening sessions, and the task is to predict if a track is skipped. The challenge is live today, and runs until Jan 4.
Link: https://www.crowdai.org/challenges/spotify-sequential-skip-prediction-challenge
#kaggle #CompetitiveDataScience #Spotify
Spotify Sequential Skip Prediction Challenge is a part of #WSDM Cup 2019. The dataset comprises 130M Spotify listening sessions, and the task is to predict if a track is skipped. The challenge is live today, and runs until Jan 4.
Link: https://www.crowdai.org/challenges/spotify-sequential-skip-prediction-challenge
#kaggle #CompetitiveDataScience #Spotify
ImageNet/ResNet-50 Training speed dramatically (6.6 min -> 224 sec) reduced
ResNet-50 on ImageNet now (allegedly) down to 224sec (3.7min) using 2176 V100s. Increasing batch size schedule, LARS, 5 epoch LR warmup, synch BN without mov avg. (mixed) fp16 training. "2D-Torus" all-reduce on NCCL2, with NVLink2 & 2 IB EDR interconnect.
1.28M images over 90 epochs with 68K batches, so the entire optimization is ~1700 updates to converge.
ArXiV: https://arxiv.org/abs/1811.05233
#ImageNet #ResNet
ResNet-50 on ImageNet now (allegedly) down to 224sec (3.7min) using 2176 V100s. Increasing batch size schedule, LARS, 5 epoch LR warmup, synch BN without mov avg. (mixed) fp16 training. "2D-Torus" all-reduce on NCCL2, with NVLink2 & 2 IB EDR interconnect.
1.28M images over 90 epochs with 68K batches, so the entire optimization is ~1700 updates to converge.
ArXiV: https://arxiv.org/abs/1811.05233
#ImageNet #ResNet
New open source suite of ODE solvers in PyTorch
Everything happens on the GPU and is differentiable. Now you can use ODEs in your deep learning models.
Github: https://github.com/rtqichen/torchdiffeq
Everything happens on the GPU and is differentiable. Now you can use ODEs in your deep learning models.
Github: https://github.com/rtqichen/torchdiffeq
GitHub
GitHub - rtqichen/torchdiffeq: Differentiable ODE solvers with full GPU support and O(1)-memory backpropagation.
Differentiable ODE solvers with full GPU support and O(1)-memory backpropagation. - rtqichen/torchdiffeq
Gradient Descent Provably Optimizes Over-parameterized Neural Networks
Paper shows that the loss of two-layer neural networks can be optimized to zero in polynomial time using gradient descent.
ArXiV: https://arxiv.org/pdf/1810.02054.pdf
#nn #dl
Paper shows that the loss of two-layer neural networks can be optimized to zero in polynomial time using gradient descent.
ArXiV: https://arxiv.org/pdf/1810.02054.pdf
#nn #dl
And the same for #ResNet, #RNN and feed-forward #nn without residual connections.
Gradient Descent Finds Global Minima of Deep Neural Networks
ArXiV: https://arxiv.org/pdf/1811.03804.pdf
On the Convergence Rate of Training Recurrent Neural Networks
ArXiV: https://arxiv.org/pdf/1810.12065.pdf
A Convergence Theory for Deep Learning via Over-Parameterization
ArXiV: https://arxiv.org/pdf/1811.03962.pdf
#dl
Gradient Descent Finds Global Minima of Deep Neural Networks
ArXiV: https://arxiv.org/pdf/1811.03804.pdf
On the Convergence Rate of Training Recurrent Neural Networks
ArXiV: https://arxiv.org/pdf/1810.12065.pdf
A Convergence Theory for Deep Learning via Over-Parameterization
ArXiV: https://arxiv.org/pdf/1811.03962.pdf
#dl
All the statistical distributions and how they relate to each other!
Source: http://www.math.wm.edu/~leemis/2008amstat.pdf
#distributions #visualization #cheatsheet #statistics
Source: http://www.math.wm.edu/~leemis/2008amstat.pdf
#distributions #visualization #cheatsheet #statistics
Dynamic relationship visualization project
Two kill two birds with one stone, we should also share this #visualization tool.
http://distributome.org/tools.html
#statistics #distributions
Two kill two birds with one stone, we should also share this #visualization tool.
http://distributome.org/tools.html
#statistics #distributions
www.distributome.org
Distributome Tools Carousel
Probability and Statistics Distributions Resource - Distributome
{kind=link}
A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks
HMTL is a Hierarchical Multi-Task Learning model which combines a set of four carefully selected semantic tasks. The model achieves state-of-the-art results on Named Entity Recognition, Entity Mention Detection and Relation Extraction. Using SentEval, we show that as we move from the bottom to the top layers of the model, the model tend to learn more complex semantic representation.
ArXiV: https://arxiv.org/abs/1811.06031
Github: https://github.com/huggingface/hmtl
#SOTA #NLP #MultiTask
HMTL is a Hierarchical Multi-Task Learning model which combines a set of four carefully selected semantic tasks. The model achieves state-of-the-art results on Named Entity Recognition, Entity Mention Detection and Relation Extraction. Using SentEval, we show that as we move from the bottom to the top layers of the model, the model tend to learn more complex semantic representation.
ArXiV: https://arxiv.org/abs/1811.06031
Github: https://github.com/huggingface/hmtl
#SOTA #NLP #MultiTask
GitHub
GitHub - huggingface/hmtl: 🌊HMTL: Hierarchical Multi-Task Learning - A State-of-the-Art neural network model for several NLP tasks…
🌊HMTL: Hierarchical Multi-Task Learning - A State-of-the-Art neural network model for several NLP tasks based on PyTorch and AllenNLP - huggingface/hmtl
This media is not supported in your browser
VIEW IN TELEGRAM
California wildfire #visualization
How weather conditions during California's fire season have evolved over time.
How weather conditions during California's fire season have evolved over time.
Nice paper from the #GoogleAI team, grading prostate cancer in prostatectomy specimens.
The model outperforms humans on the silver standard labels (panel of experts), but there is no clear winner for outcome prediction in the K-M plot/c-index.
«the mean accuracy among 29 general pathologists was 0.61. The DLS achieved an... accuracy of 0.70 (p=0.002) and trended towards better patient risk stratification»
Post: https://ai.googleblog.com/2018/11/improved-grading-of-prostate-cancer.html
ArXiV: https://arxiv.org/abs/1811.06497
#DL #medical #cancer
The model outperforms humans on the silver standard labels (panel of experts), but there is no clear winner for outcome prediction in the K-M plot/c-index.
«the mean accuracy among 29 general pathologists was 0.61. The DLS achieved an... accuracy of 0.70 (p=0.002) and trended towards better patient risk stratification»
Post: https://ai.googleblog.com/2018/11/improved-grading-of-prostate-cancer.html
ArXiV: https://arxiv.org/abs/1811.06497
#DL #medical #cancer
Googleblog
Improved Grading of Prostate Cancer Using Deep Learning
Difference between machine learning and AI:
If it is written in Python, it's probably machine learning
If it is written in PowerPoint, it's probably AI
If it is written in Python, it's probably machine learning
If it is written in PowerPoint, it's probably AI
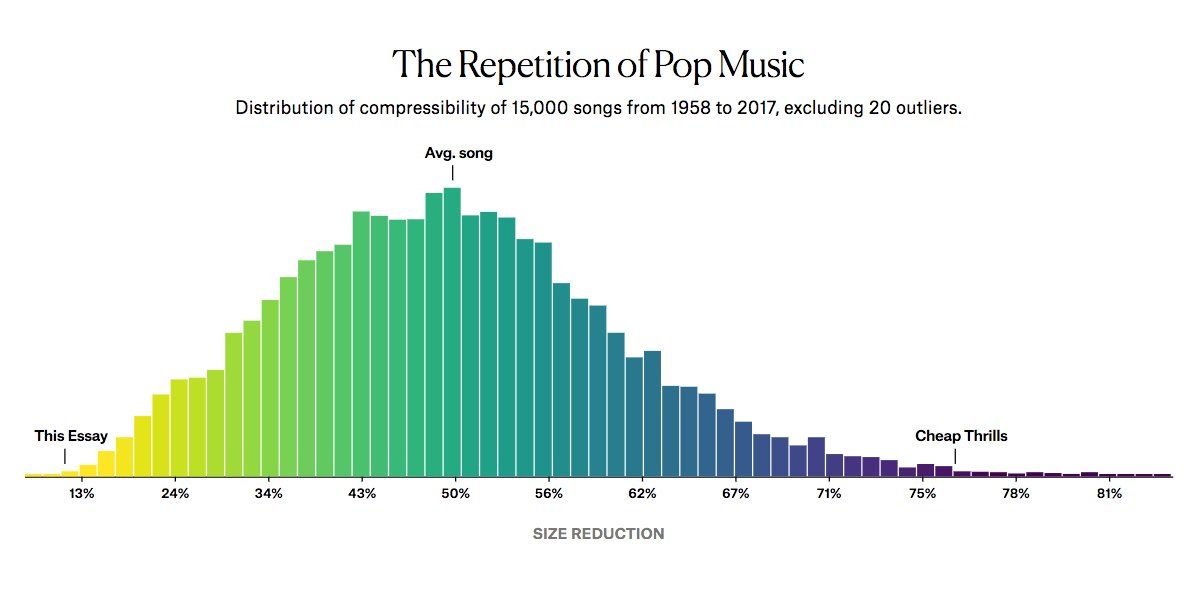
Are Pop Lyrics Getting More Repetitive?
Well-written article on pop music analysis. Is the repetitiveness in songs rising? Does it influence song popularity?
Article contains well-designed and illustrated research.
Link: https://pudding.cool/2017/05/song-repetition/
#popularDS #researh #statistics #vizualization
Well-written article on pop music analysis. Is the repetitiveness in songs rising? Does it influence song popularity?
Article contains well-designed and illustrated research.
Link: https://pudding.cool/2017/05/song-repetition/
#popularDS #researh #statistics #vizualization
{kind=link}
Measuring the Effects of Data Parallelism on Neural Network Training
Important paper from Google on large batch optimization. They do impressively careful experiments measuring iterations needed to achieve target validation error at various batch sizes. The main "surprise" is the lack of surprises.
There is rather long and throughtful twitter thread about the paper.
Twitter thread: https://twitter.com/RogerGrosse/status/1066392375570894849
ArXiV: https://arxiv.org/abs/1811.03600
Telegra.ph for instant view: https://telegra.ph/Roger-Grosses-thread-on-Measuring-the-Effects-of-Data-Parallelism-on-Neural-Network-Training-11-24
Important paper from Google on large batch optimization. They do impressively careful experiments measuring iterations needed to achieve target validation error at various batch sizes. The main "surprise" is the lack of surprises.
There is rather long and throughtful twitter thread about the paper.
Twitter thread: https://twitter.com/RogerGrosse/status/1066392375570894849
ArXiV: https://arxiv.org/abs/1811.03600
Telegra.ph for instant view: https://telegra.ph/Roger-Grosses-thread-on-Measuring-the-Effects-of-Data-Parallelism-on-Neural-Network-Training-11-24
{kind=link}
🎓 Free «Advanced Deep Learning and Reinforcement Learning» course.
#DeepMind researchers have released video recordings of lectures from «Advanced Deep Learning and Reinforcement Learning» a course on deep RL taught at #UCL earlier this year.
YouTube Playlist: https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs
#course #video #RL #DL
#DeepMind researchers have released video recordings of lectures from «Advanced Deep Learning and Reinforcement Learning» a course on deep RL taught at #UCL earlier this year.
YouTube Playlist: https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs
#course #video #RL #DL
Beard length A/B testing on #Tinder
https://appsciencing.wordpress.com/2018/11/19/beard-studies/
#abtest #statistics #practicalML
https://appsciencing.wordpress.com/2018/11/19/beard-studies/
#abtest #statistics #practicalML
Application Science
How Do You Test Out A New Look? Dating Apps!
People have described a dystopian future where machines control your dating life by presenting you with images of single women and convincing you that feeding the machines will lead to a life (or a…
🎓Amazon have released its Free Machine Learning #course.
Course consits of 30+ digital ML classes totaling 45+ hours, aiming for improving skills of different roles: from Data Platform Engineer to Business Decision Maker.
Link: https://aws.amazon.com/ru/training/learning-paths/machine-learning/
#Amazon #ML #MOOC
Course consits of 30+ digital ML classes totaling 45+ hours, aiming for improving skills of different roles: from Data Platform Engineer to Business Decision Maker.
Link: https://aws.amazon.com/ru/training/learning-paths/machine-learning/
#Amazon #ML #MOOC
Amazon
Машинное обучение и искусственный интеллект – Цифровое и аудиторное обучение AWS
Развивайте навыки по работе с технологиями машинного обучения с помощью онлайн-курсов, аудиторных занятий и программ сертификации, предназначенных для специализированных ролей в области машинного обучения. Подробнее