
Напишите код для перестановки всех символов строки.
Реализуйте функцию perm(), которая принимает слайс или строку и выводит все возможные комбинации символов. Пишите свой вариант ответа в комментариях.
Ответ
@golang_interview
Реализуйте функцию perm(), которая принимает слайс или строку и выводит все возможные комбинации символов. Пишите свой вариант ответа в комментариях.
Ответ
package main
import "fmt"
// Perm calls f with each permutation of a.
func Perm(a []rune, f func([]rune)) {
perm(a, f, 0)
}
// Permute the values at index i to len(a)-1.
func perm(a []rune, f func([]rune), i int) {
if i > len(a) {
f(a)
return
}
perm(a, f, i+1)
for j := i + 1; j < len(a); j++ {
a[i], a[j] = a[j], a[i]
perm(a, f, i+1)
a[i], a[j] = a[j], a[i]
}
}
func main() {
Perm([]rune("abc"), func(a []rune) {
fmt.Println(string(a))
})
}
@golang_interview
👍11👎2
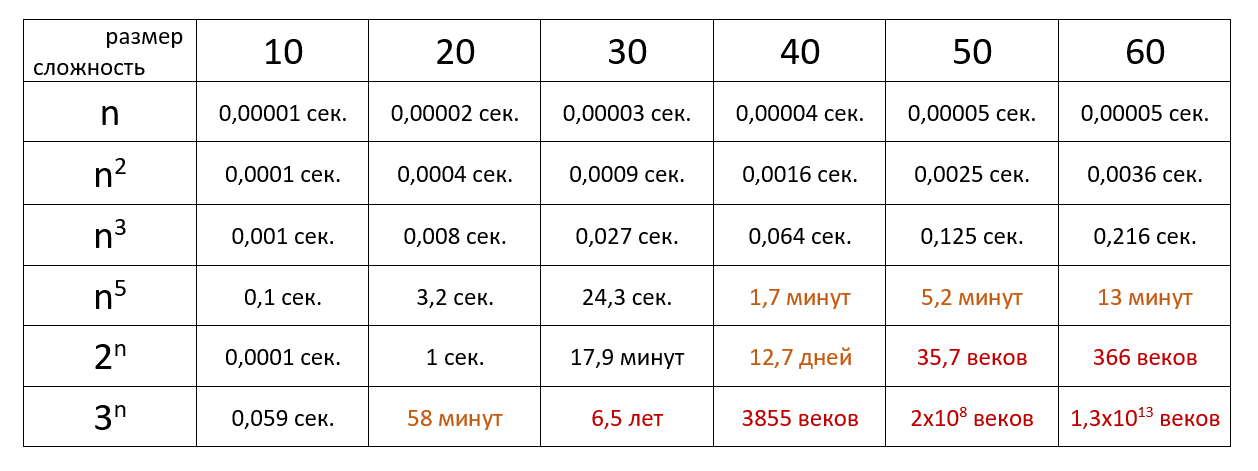
Что такое временная сложность алгоритма (time complexity)
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n. Тогда говорят, что временная сложность этого алгоритма равна О(n3), т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n).
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n, т. е. n2.
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1). Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
@golang_interview
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n. Тогда говорят, что временная сложность этого алгоритма равна О(n3), т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n).
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n, т. е. n2.
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1). Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
@golang_interview
{kind=link}
👍18
Напишите код, чтобы поменять местами значения двух переменных без использования временной переменной
Ответ
Реализуйте функцию swap(), которая меняет местами значения двух переменных без использования третьей переменной.
Хотя это может быть сложно на других языках, Go делает это легко.
Мы можем просто написать утверждение b, a = a, b, на какие данные ссылается переменная, не связываясь ни с одним из значений.
Пишите свои варианты в комменнтариях
@golang_interview
Ответ
Реализуйте функцию swap(), которая меняет местами значения двух переменных без использования третьей переменной.
Хотя это может быть сложно на других языках, Go делает это легко.
Мы можем просто написать утверждение b, a = a, b, на какие данные ссылается переменная, не связываясь ни с одним из значений.
package main
import "fmt"
func main() {
fmt.Println(swap())
}
func swap() []int {
a, b := 15, 10
b, a = a, b
return []int{a, b}
}Пишите свои варианты в комменнтариях
@golang_interview
👍14👎11😢5
Расскажите о командах systemd для управления Docker
Ответ
Для запуска Docker многие дистрибутивы Linux используют systemd. Для запуска сервисов используется команда systemctl. Если ее нет, следует использовать команду service.
Чтобы добавить сервис в автозагрузку, либо убрать его:
Для проверки параметров запуска сервиса и их изменения:
Просмотра связанных с сервисом журналов:
Опишите процесс масштабирования контейнеров Docker
Контейнеры могут быть масштабированы с использованием команды docker-compose scale. Процесс масштабирования такой:
Масштабируем контейнер и запускаем n экземпляров:
В вышеприведенном примере имя сервиса задается в файле docker-compose-run-srvr.yml, а также запускается n копий контейнеров, где n — любое целое положительное число.
После масштабирования контейнера для проверки можно использовать такую команду:
@golang_interview
Ответ
Для запуска Docker многие дистрибутивы Linux используют systemd. Для запуска сервисов используется команда systemctl. Если ее нет, следует использовать команду service.
$ sudo systemctl start docker
$ sudo service docker startЧтобы добавить сервис в автозагрузку, либо убрать его:
$ sudo systemctl enable docker
$ sudo systemctl disable dockerДля проверки параметров запуска сервиса и их изменения:
$ sudo systemctl edit dockerПросмотра связанных с сервисом журналов:
$ journalctl -u dockerОпишите процесс масштабирования контейнеров Docker
Контейнеры могут быть масштабированы с использованием команды docker-compose scale. Процесс масштабирования такой:
Масштабируем контейнер и запускаем n экземпляров:
$ docker-compose --file docker-compose-run-srvr.yml scale <service_name>=<n>В вышеприведенном примере имя сервиса задается в файле docker-compose-run-srvr.yml, а также запускается n копий контейнеров, где n — любое целое положительное число.
После масштабирования контейнера для проверки можно использовать такую команду:
$ docker ps -a@golang_interview
👍18😁4❤1🔥1
Есть ли особенности поведения при передаче map и slice в функцию?
Ответ
Передача slice и map может заставить усомниться в том, что они передаются в функцию по значению. Однако здесь так же происходит копирование. Структуры slice и map (уточнение: в случае map копируется не сама структура, а указатель структуру hmap, подробнее о том, что такое hmap можно прочитать в первой статье) копируются, однако в самих структурах содержатся ссылки на области памяти, благодаря которым создается эффект передачи по ссылке.
Вывод
Вывод
@golang_interview
Ответ
Передача slice и map может заставить усомниться в том, что они передаются в функцию по значению. Однако здесь так же происходит копирование. Структуры slice и map (уточнение: в случае map копируется не сама структура, а указатель структуру hmap, подробнее о том, что такое hmap можно прочитать в первой статье) копируются, однако в самих структурах содержатся ссылки на области памяти, благодаря которым создается эффект передачи по ссылке.
func main() {
slice := []int{1, 2, 3, 4, 5}
fmt.Println(slice)
fmt.Printf("%p\n", &slice)
changeZeroElem(slice)
fmt.Println(slice)
}
func changeZeroElem(slice []int) {
fmt.Printf("%p\n", &slice)
slice[0] = 99
}
Вывод
[1 2 3 4 5]
0xc0000ac018
0xc0000ac048
[99 2 3 4 5]func main() {
store := map[string]int{"first": 1, "second": 2}
fmt.Println(store)
fmt.Printf("%p\n", &store)
changeMapElem(store)
fmt.Println(store)
}
func changeMapElem(store map[string]int) {
fmt.Printf("%p\n", &store)
store["first"] = 99
}
Вывод
map[first:1 second:2]
0xc0000b2018
0xc0000b2028
map[first:99 second:2]@golang_interview
👍18👎2❤1🔥1
Каковы отличия context.WithCancel, context.WithDeadline, context.WithTimeout?
- context.WithCancel(parent Context) (ctx Context, cancel CancelFunc) создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Общепринятой практикой является работать с функцией отмены там, где она получена, не передавая ее глубже.
- context.WithDeadline(parent Context, d time.Time) (ctx Context, cancel CancelFunc) создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Контекст автоматически отменится в переданное, как входной параметр функции, время.
- context.WithTimeout(parent Context, timeout time.Duration) (ctx Context, cancel CancelFunc) создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Контекст автоматически отменится через интервал времени, переданный, как входной параметр функции.
@golang_interview
- context.WithCancel(parent Context) (ctx Context, cancel CancelFunc) создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Общепринятой практикой является работать с функцией отмены там, где она получена, не передавая ее глубже.
- context.WithDeadline(parent Context, d time.Time) (ctx Context, cancel CancelFunc) создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Контекст автоматически отменится в переданное, как входной параметр функции, время.
- context.WithTimeout(parent Context, timeout time.Duration) (ctx Context, cancel CancelFunc) создает контекст производный от родительского, также возвращает функцию отмены, с помощью которой этот контекст можно закрыть. Контекст автоматически отменится через интервал времени, переданный, как входной параметр функции.
@golang_interview
👍17🔥3❤1
В равной ли степени горутины делят между собой процессорное время?
Ответ
Существует 2 типа многозадачности:
кооперативная - передачей управления процессы занимаются самостоятельно;
вытесняющая многозадачность - планировщик дает отработать процессам равное время, после чего перещелкивает контекст.
С версии Go 1.14 планировщик с кооперативного стал асинхронно вытесняющим. Сделано это было по причине долго отрабатывающих горутин, надолго занимающих процессорное время и не дающих доступа до него другим горутинам. Теперь когда горутина отрабатывает больше 10 м/с Go будет пытаться переключить контекст для выполнения следующей горутины. Казалось бы вот он ответ. Но не все так просто... Части кооперативного поведения до сих пор присутствуют, к примеру перед вытеснением горутины необходимо выполнить проверку куска кода на атомарность, с точки зрения garbage collector. Операция вытеснения может настичь горутину в любом месте, в зависимости от состояния данных, сборщик мусора может отработать совсем не так как ожидалось. Так как Go живой язык, в который постоянно вносятся изменения, реализация и тонкости в разных версиях могут отличаться. Настоятельно советую обновлять свои знания по этой теме по мере релизов Go.
@golang_interview
Ответ
Существует 2 типа многозадачности:
кооперативная - передачей управления процессы занимаются самостоятельно;
вытесняющая многозадачность - планировщик дает отработать процессам равное время, после чего перещелкивает контекст.
С версии Go 1.14 планировщик с кооперативного стал асинхронно вытесняющим. Сделано это было по причине долго отрабатывающих горутин, надолго занимающих процессорное время и не дающих доступа до него другим горутинам. Теперь когда горутина отрабатывает больше 10 м/с Go будет пытаться переключить контекст для выполнения следующей горутины. Казалось бы вот он ответ. Но не все так просто... Части кооперативного поведения до сих пор присутствуют, к примеру перед вытеснением горутины необходимо выполнить проверку куска кода на атомарность, с точки зрения garbage collector. Операция вытеснения может настичь горутину в любом месте, в зависимости от состояния данных, сборщик мусора может отработать совсем не так как ожидалось. Так как Go живой язык, в который постоянно вносятся изменения, реализация и тонкости в разных версиях могут отличаться. Настоятельно советую обновлять свои знания по этой теме по мере релизов Go.
@golang_interview
👍30🔥3❤1
🔥 Полезнейшая Подборка каналов
👣 Golang
@Golang_google - go для разработчиков
@golangtests - тесты и задачи GO
@golangl - чат Golang
@GolangJobsit - вакансии и работа GO
@golang_jobsgo - чат вакансий
@golang_books - книги Golang
@golang_speak - обсуждение задач Go
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
🖥 Python
@pro_python_code – погружение в python
@python_job_interview – подготовка к Python собеседованию
@python_testit тесты на python
@pythonlbooks - книги Python
@Django_pythonl django
@python_djangojobs - работа Python
@python_django_work
🖥 Machine learning
@ai_machinelearning_big_data – все о машинном обучении
@data_analysis_ml – все о анализе данных.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседования Data Science
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@neural – все о нейронных сетях
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
@Machinelearning_Jobs
🖥 Java
@javatg - Java для програмистов
@javachats Java чат
@java_library - книги Java
@android_its Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
🖥 Javascript / front
@javascriptv - javascript изучение
@about_javascript - javascript продвинутый
@JavaScript_testit -тесты JS
@htmlcssjavas - web
@hashdev - web разработка
🖥 Linux
@linux_kal - чат kali linux
@linuxkalii - linux kali
@linux_read - книги linux
👷♂️ IT работа
@hr_itwork - ит-ваканнсии
🖥 SQL
@sqlhub - базы данных
@chat_sql - базы данных чат
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - язык программирования rust
@rust_chats - чат rust
#️⃣ c# c++
@csharp_ci - c# c++кодинг
@csharp_cplus чат
📓 Книги
@programming_books_it
@datascienceiot
@pythonlbooks
@golang_books
@frontendbooksit
@progersit
@linux_read
@java_library
@frontendbooksit
📢 English for coders
@english_forprogrammers - Английский для программистов
🖥 Github
@github_code
@Golang_google - go для разработчиков
@golangtests - тесты и задачи GO
@golangl - чат Golang
@GolangJobsit - вакансии и работа GO
@golang_jobsgo - чат вакансий
@golang_books - книги Golang
@golang_speak - обсуждение задач Go
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@pro_python_code – погружение в python
@python_job_interview – подготовка к Python собеседованию
@python_testit тесты на python
@pythonlbooks - книги Python
@Django_pythonl django
@python_djangojobs - работа Python
@python_django_work
@ai_machinelearning_big_data – все о машинном обучении
@data_analysis_ml – все о анализе данных.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседования Data Science
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@neural – все о нейронных сетях
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
@Machinelearning_Jobs
@javatg - Java для програмистов
@javachats Java чат
@java_library - книги Java
@android_its Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
@javascriptv - javascript изучение
@about_javascript - javascript продвинутый
@JavaScript_testit -тесты JS
@htmlcssjavas - web
@hashdev - web разработка
@linux_kal - чат kali linux
@linuxkalii - linux kali
@linux_read - книги linux
👷♂️ IT работа
@hr_itwork - ит-ваканнсии
@sqlhub - базы данных
@chat_sql - базы данных чат
🤡It memes
@memes_prog - ит-мемы
⚙️ Rust
@rust_code - язык программирования rust
@rust_chats - чат rust
#️⃣ c# c++
@csharp_ci - c# c++кодинг
@csharp_cplus чат
📓 Книги
@programming_books_it
@datascienceiot
@pythonlbooks
@golang_books
@frontendbooksit
@progersit
@linux_read
@java_library
@frontendbooksit
@english_forprogrammers - Английский для программистов
@github_code
Please open Telegram to view this post
VIEW IN TELEGRAM
👍6❤2🔥2
Что такое буферизированный и небуферизированный channel?
Ответ
channel делятся на два типа по наличию/отсутствию буфера. Соответственно в первом случае поле dataqsiz будет равно размеру переданного буфера (3), а поле buf будет ссылкой на этот буфер. Во втором случае поле dataqsiz будет равно 0, а поле buf будет nil. Отсюда возникает различное поведение этих типов channel при операциях с ними. Об этом мы поговорим ниже.
@golang_interview
Ответ
channel делятся на два типа по наличию/отсутствию буфера. Соответственно в первом случае поле dataqsiz будет равно размеру переданного буфера (3), а поле buf будет ссылкой на этот буфер. Во втором случае поле dataqsiz будет равно 0, а поле buf будет nil. Отсюда возникает различное поведение этих типов channel при операциях с ними. Об этом мы поговорим ниже.
chanBuf := make(chan bool, 3)
chanIsNotBuf := make(chan bool)@golang_interview
🥴9🤡6👍5👎3❤1🔥1
Ответ
Если размышлять глобально, то таких способа 3:
- завершение main функции и main горутины;
- прослушивание всеми горутинами channel, при закрытии channel отправляется значение по умолчанию всем слушателям, при получении сигнала все горутины делают return;
- завязать все горутины на переданный в них context.
@golang_interview
Please open Telegram to view this post
VIEW IN TELEGRAM
👍9❤1🥰1
На этот вопрос, ожидается ответ, не сколько весят все вместе взятые поля в структуре g объекта горутины. Интервьюера интересуют минимальный и максимальный размер стэка горутины. Минимальный (начальный) размер стэка составляет 2 КБ. Максимальный размер стэка горутины зависит от архитектуры системы и равен 1 ГБ для 64-разрядной архитектуры, 250 МБ для 32-разрядной архитектуры.
// The minimum size of stack used by Go code
_StackMin = 2048
// Max stack size is 1 GB on 64-bit, 250 MB on 32-bit.
// Using decimal instead of binary GB and MB because
// they look nicer in the stack overflow failure message.
if sys.PtrSize == 8 {
maxstacksize = 1000000000
} else {
maxstacksize = 250000000
}
@golang_interview
Please open Telegram to view this post
VIEW IN TELEGRAM
👍20🔥4❤1
Что такое wait group?
Ответ
sync.WaitGroup - это реализация счетчика, который можно инкрементировать и декрементировать, и самое главное остановить выполнение куска кода до того момента, пока значение счетчика не будет равно 0.
Вывод
@golang_interview
Ответ
sync.WaitGroup - это реализация счетчика, который можно инкрементировать и декрементировать, и самое главное остановить выполнение куска кода до того момента, пока значение счетчика не будет равно 0.
func main() {
wg := sync.WaitGroup{}
wg.Add(1)
go gorutinePrint(&wg)
wg.Wait()
fmt.Println("hello from main")
}
func gorutinePrint(wg *sync.WaitGroup) {
// без использования WaitGroup нет гарантий, что будет выведено
fmt.Println("hello from goroutine")
wg.Done()
}Вывод
hello from goroutine
hello from main@golang_interview
👍13🔥4❤2
Для чего используется atomic?
Ответ
Вывод
@golang_interview
Ответ
atomic - предоставляет набор атомарных функций, реализованных на аппаратном уровне. Это позволяет избегать гонки данных без блокировок. Вместе с этим, с помощью atomic в отличие от mutex можно делать только простые вещи, к примеру инкрементировать различные счетчики. Немного пояснений про атомарность: функция будет атомарной, если она завершается в один шаг по отношению ко всем другим потокам, которые имеют доступ к обрабатываемой памяти.func main() {
var (
counter uint64
wg sync.WaitGroup
)
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
for c := 0; c < 1000; c++ {
atomic.AddUint64(&counter, 1)
}
wg.Done()
}()
}
wg.Wait()
fmt.Println("counter:", counter)
}Вывод
counter: 10000@golang_interview
👍19🤡2❤1🔥1
Ответ
Это можно сделать через
runtime.GOMAXPROCS(). Важно понимать, что при выставлении количества логических процессоров больше, чем есть у вас в системе, вы рискуете получить определенные проблемы с производительностью. Чтобы избежать этого можно задать runtime.GOMAXPROCS(runtime.NumCPU()), runtime.NumCPU() - количество логических процессоров.@golang_interview
Please open Telegram to view this post
VIEW IN TELEGRAM
👍14❤1🔥1😁1
Как принудительно переключить контекст?
Ответ
Переключение контекста вручную осуществляется с помощью функции
@golang_interview
Ответ
Переключение контекста вручную осуществляется с помощью функции
runtime.Goshed().@golang_interview
👍12🔥3❤1
Ответ
wait group;
mutex;
atomic;
sync map;
channel.@golang_interview
Please open Telegram to view this post
VIEW IN TELEGRAM
👍18❤4🔥2😁1😱1🤡1
Для чего используется sync map?
Ответ
Простой ответ на этот вопрос: достаточно частый кейс использования в Go mutex, который защищает данные в map. sync.Map можно рассматривать как map+RWMutex обертку. Но на деле этот ответ не совсем правильный, так как sync.Map решает одну довольно конкретную проблему cache contention. Что же это такое? При использовании sync.RWMutex в случае блокировки на чтение каждая горутина должна обновить поле readerCount, что происходит атомарно. Довольно обще процесс выглядит так:
- ядро процессора обновляет счетчик;
- ядро процессора сбрасывает кэш для этого адреса для всех других ядер;
- ядро процессора объявляет, что только оно знает действующее значение для обрабатываемого адреса;
- следующее ядро процессора вычитывает значение из кэша предыдущего;
- процесс повторяется. Так вот, когда несколько ядер хотят обновить readerCount, образуется очередь. И операция, которую мы считали константной, становится линейной относительно количества ядер. Именно решая эту проблему и ввели sync.Map. sync.Map рекомендуется применять именно на многопроцессорных системах.
@golang_interview
Ответ
Простой ответ на этот вопрос: достаточно частый кейс использования в Go mutex, который защищает данные в map. sync.Map можно рассматривать как map+RWMutex обертку. Но на деле этот ответ не совсем правильный, так как sync.Map решает одну довольно конкретную проблему cache contention. Что же это такое? При использовании sync.RWMutex в случае блокировки на чтение каждая горутина должна обновить поле readerCount, что происходит атомарно. Довольно обще процесс выглядит так:
- ядро процессора обновляет счетчик;
- ядро процессора сбрасывает кэш для этого адреса для всех других ядер;
- ядро процессора объявляет, что только оно знает действующее значение для обрабатываемого адреса;
- следующее ядро процессора вычитывает значение из кэша предыдущего;
- процесс повторяется. Так вот, когда несколько ядер хотят обновить readerCount, образуется очередь. И операция, которую мы считали константной, становится линейной относительно количества ядер. Именно решая эту проблему и ввели sync.Map. sync.Map рекомендуется применять именно на многопроцессорных системах.
// Lock locks rw for writing.
// If the lock is already locked for reading or writing,
// Lock blocks until the lock is available.
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
rw.w.Lock()
// Announce to readers there is a pending writer.
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}@golang_interview
👍26🔥9❤2👎2
Если размер стэка горутины превышен (к примеру запустили бесконечную рекурсию), то приложение упадет с fatal error.
runtime: goroutine stack exceeds 1000000000-byte limit
fatal error: stack overflow@golang_interview
Please open Telegram to view this post
VIEW IN TELEGRAM
👍16🔥6❤2