
Что такое race condition?
Состояние гонки (англ. race condition), также конкуренция — ошибка проектирования многопоточной системы или приложения, при которой работа системы или приложения зависит от того, в каком порядке выполняются части кода. Своё название ошибка получила от похожей ошибки проектирования электронных схем (см. Гонки сигналов).
Термин состояние гонки относится к инженерному жаргону и появился вследствие неаккуратного дословного перевода английского эквивалента. В более строгой академической среде принято использовать термин неопределённость параллелизма.
Из-за своей конструкции детектор гонки может обнаруживать условия гонки только тогда, когда они фактически вызываются запуском кода, что означает, что важно запускать двоичные файлы с поддержкой детектора гонки при реалистичных рабочих нагрузках. Однако двоичные файлы с поддержкой детектора гонки могут в десять раз больше использовать процессор и память, поэтому нецелесообразно постоянно включать детектор гонки. Одним из выходов из этой дилеммы является запуск некоторых тестов с включенным детектором гонки. Нагрузочные тесты и интеграционные тесты являются хорошими кандидатами, так как они имеют тенденцию использовать конкурентные части кода. Другой подход, использующий производственные рабочие нагрузки, заключается в развертывании одного экземпляра с включенным детектором гонки в пуле работающих серверов.
Подробнее
@golang_interview
Состояние гонки (англ. race condition), также конкуренция — ошибка проектирования многопоточной системы или приложения, при которой работа системы или приложения зависит от того, в каком порядке выполняются части кода. Своё название ошибка получила от похожей ошибки проектирования электронных схем (см. Гонки сигналов).
Термин состояние гонки относится к инженерному жаргону и появился вследствие неаккуратного дословного перевода английского эквивалента. В более строгой академической среде принято использовать термин неопределённость параллелизма.
Из-за своей конструкции детектор гонки может обнаруживать условия гонки только тогда, когда они фактически вызываются запуском кода, что означает, что важно запускать двоичные файлы с поддержкой детектора гонки при реалистичных рабочих нагрузках. Однако двоичные файлы с поддержкой детектора гонки могут в десять раз больше использовать процессор и память, поэтому нецелесообразно постоянно включать детектор гонки. Одним из выходов из этой дилеммы является запуск некоторых тестов с включенным детектором гонки. Нагрузочные тесты и интеграционные тесты являются хорошими кандидатами, так как они имеют тенденцию использовать конкурентные части кода. Другой подход, использующий производственные рабочие нагрузки, заключается в развертывании одного экземпляра с включенным детектором гонки в пуле работающих серверов.
Подробнее
@golang_interview
👍12👎5🔥3
Какие проблемы решает Service Discovery?
Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
Как это выглядит? На классическом примере в вебе – это фронтенд, который принимает запрос пользователя. Дальше выполняет маршрутизацию его на backend. На данном примере – это load-balancer балансирует на два backend.
На картиннке мы видим, что мы запускаем третий экземпляр приложения. Соответственно, когда приложение запускается, оно производит регистрацию в Service Discovery. Service Discovery уведомляет load-balancer. Load-balancer меняет свой конфиг автоматически и уже новый backend подключается в работу. Таким образом могут добавляться backend, либо, наоборот, исключаться из работы.
@golang_interview
Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
Как это выглядит? На классическом примере в вебе – это фронтенд, который принимает запрос пользователя. Дальше выполняет маршрутизацию его на backend. На данном примере – это load-balancer балансирует на два backend.
На картиннке мы видим, что мы запускаем третий экземпляр приложения. Соответственно, когда приложение запускается, оно производит регистрацию в Service Discovery. Service Discovery уведомляет load-balancer. Load-balancer меняет свой конфиг автоматически и уже новый backend подключается в работу. Таким образом могут добавляться backend, либо, наоборот, исключаться из работы.
@golang_interview
👍14🔥2🥰1
Что такое lvalues и rvalues в Go ?
Ответ:
В Go есть два типа выражений:
lvalue − выражение, которое ссылается на какой-то явный участок памяти называется “lvalue” (“Locator value“), при этом выражение может находится с любой стороны от оператора присваивания.
rvalue − термин r-value (“Raw value“?) применяется к данным, которые хранятся в каком-то участке памяти.
Переменные являются l-values, и могут указываться с левой стороны (тем не менее – не “left-value“, а “locator value“). Числовые литералы, в свою очередь, являются r-values, и не могут быть присвоены к чему-либо, и не должны быть указаны с левой стороны от оператора присваивания.
Т.е. следующее выражение будет корректным:
x = 20.0
Тогда как следующее вызовет ошибку компилятора:
10 = 20
#junior
@golang_interview
Ответ:
В Go есть два типа выражений:
lvalue − выражение, которое ссылается на какой-то явный участок памяти называется “lvalue” (“Locator value“), при этом выражение может находится с любой стороны от оператора присваивания.
rvalue − термин r-value (“Raw value“?) применяется к данным, которые хранятся в каком-то участке памяти.
Переменные являются l-values, и могут указываться с левой стороны (тем не менее – не “left-value“, а “locator value“). Числовые литералы, в свою очередь, являются r-values, и не могут быть присвоены к чему-либо, и не должны быть указаны с левой стороны от оператора присваивания.
Т.е. следующее выражение будет корректным:
x = 20.0
Тогда как следующее вызовет ошибку компилятора:
10 = 20
#junior
@golang_interview
👍17🔥6👎4❤1
Как выполняется мониторинг Docker в производственных окружениях?
Для мониторинга есть инструменты Docker stats и Docker events. С их помощью можно получить отчеты по важной статистике. Если запустить stats с некоторым идентификатором контейнера, он вернет использование оперативной памяти и процессорного времени в контейнере. Это схоже с использованием команды top. С другой стороны есть events, показывающая список активностей в процессе работы сервиса Docker. Вот некоторые из них: подключение к консоли контейнера, commit, переименование, удаление и т.п., а также есть возможность фильтрации нужных событий.
Шпаргалка с командами Docker
#middle
@golang_interview
Для мониторинга есть инструменты Docker stats и Docker events. С их помощью можно получить отчеты по важной статистике. Если запустить stats с некоторым идентификатором контейнера, он вернет использование оперативной памяти и процессорного времени в контейнере. Это схоже с использованием команды top. С другой стороны есть events, показывающая список активностей в процессе работы сервиса Docker. Вот некоторые из них: подключение к консоли контейнера, commit, переименование, удаление и т.п., а также есть возможность фильтрации нужных событий.
Шпаргалка с командами Docker
#middle
@golang_interview
👍11🔥4❤2
Расскажите об использование оператора switch в Go
Ответ
Базовый switch с default кейсом
Оператор switch запускает первый case (кейс), равный выражению условия.
Кейсы оцениваются сверху вниз, останавливаясь, когда кейс подходит.
Если ни один кейс не совпадает и есть default кейс, выполняются его утверждения.
switch time.Now().Weekday() {
case time.Saturday:
fmt.Println("Сегодня суббота.")
case time.Sunday:
fmt.Println("Сегодня воскресенье.")
default:
fmt.Println("Сегодня будничный день.")
}
В отличие от C и Java, выражения case не обязательно должны быть константами.
Пять паттернов использования операторов switch
#junior
@golang_interview
Ответ
Базовый switch с default кейсом
Оператор switch запускает первый case (кейс), равный выражению условия.
Кейсы оцениваются сверху вниз, останавливаясь, когда кейс подходит.
Если ни один кейс не совпадает и есть default кейс, выполняются его утверждения.
switch time.Now().Weekday() {
case time.Saturday:
fmt.Println("Сегодня суббота.")
case time.Sunday:
fmt.Println("Сегодня воскресенье.")
default:
fmt.Println("Сегодня будничный день.")
}
В отличие от C и Java, выражения case не обязательно должны быть константами.
Пять паттернов использования операторов switch
#junior
@golang_interview
👍11🔥4👎3❤1
✒️ Мои собеседования (Golang developer)
Привет, меня зовут Олег, я разработчик со стажем почти 10 лет.
Разработкой начал заниматься ещё со старшей школы, изучал C/C++ (очень пригодилось при написании скриптов в injection для ультимы онлайн). Профессионально начал работать разработчиком приблизительно с 2014, основной язык до 2020 года был C# с примесью C++. Сначала разрабатывал и поддерживал некоторые проекты в банковской сфере, потом резко поменял предметную область и ушёл писать софт для автоматизации работы одного строительного девелопера. На начальных этапах это было огромное легаси на C# от бывшего архитектора, решившего стать программистом, с кучей багов и неочевидных решений, пришлось много переписывать.
Со временем появились задачи, которые не были привязаны к языку и технологиям в принципе (изначально писал, по сути, плагины к CAD-приложениям), и я попробовал Golang, а вместе с ним и микросервисы, NoSQL, gRPC и прочие модные штуки. Побывал в шкуре админа-девопса, так как новые сервисы я запускал и поддерживал сам.
➡️ Читать дальше
@golang_interview
Привет, меня зовут Олег, я разработчик со стажем почти 10 лет.
Разработкой начал заниматься ещё со старшей школы, изучал C/C++ (очень пригодилось при написании скриптов в injection для ультимы онлайн). Профессионально начал работать разработчиком приблизительно с 2014, основной язык до 2020 года был C# с примесью C++. Сначала разрабатывал и поддерживал некоторые проекты в банковской сфере, потом резко поменял предметную область и ушёл писать софт для автоматизации работы одного строительного девелопера. На начальных этапах это было огромное легаси на C# от бывшего архитектора, решившего стать программистом, с кучей багов и неочевидных решений, пришлось много переписывать.
Со временем появились задачи, которые не были привязаны к языку и технологиям в принципе (изначально писал, по сути, плагины к CAD-приложениям), и я попробовал Golang, а вместе с ним и микросервисы, NoSQL, gRPC и прочие модные штуки. Побывал в шкуре админа-девопса, так как новые сервисы я запускал и поддерживал сам.
➡️ Читать дальше
@golang_interview
👍15👎3🔥3🥰1
Что такое пространства имен в Docker?
Ответ
Пространства имен Docker — это технология обеспечения изолированных рабочих пространств, известная как контейнер. Как только контейнер запускается, создается набор пространств имен для этого контейнера. Они обеспечивают уровень изоляции для контейнеров, поскольку каждый контейнер работает в отдельном пространстве имен, с ограничением доступа к другим пространствам.
@golang_interview
Ответ
Пространства имен Docker — это технология обеспечения изолированных рабочих пространств, известная как контейнер. Как только контейнер запускается, создается набор пространств имен для этого контейнера. Они обеспечивают уровень изоляции для контейнеров, поскольку каждый контейнер работает в отдельном пространстве имен, с ограничением доступа к другим пространствам.
@golang_interview
👍11🔥2❤1
Что такое затененные (shadowed) переменные в Golang?
Переменная является затеняющей, если ее имя совпадает с именем переменной, определенной во вмещающем блоке. При наличии затеняющей переменной вы не можете получить доступ к затененной переменной.
Запустив код на картинке, вы получите следующие результаты:
5 20
10
Переменная x затеняется внутри оператора if, несмотря на наличие определения переменной x во внешнем блоке. Это объясняется тем, что оператор := заново использует переменные, объявляемые в текущем блоке. Поэтому при применении оператора := следует убедиться в том, что слева от него не указаны переменные, объявленные во внешней области видимости, если у вас нет намерения их затенить.
Также нужно проследить за тем, чтобы не был затенен импорт пакета.
@golang_interview
Переменная является затеняющей, если ее имя совпадает с именем переменной, определенной во вмещающем блоке. При наличии затеняющей переменной вы не можете получить доступ к затененной переменной.
Запустив код на картинке, вы получите следующие результаты:
5 20
10
Переменная x затеняется внутри оператора if, несмотря на наличие определения переменной x во внешнем блоке. Это объясняется тем, что оператор := заново использует переменные, объявляемые в текущем блоке. Поэтому при применении оператора := следует убедиться в том, что слева от него не указаны переменные, объявленные во внешней области видимости, если у вас нет намерения их затенить.
Также нужно проследить за тем, чтобы не был затенен импорт пакета.
@golang_interview
👍20🔥6👎2🥰1
Расскажите о GOPATH и GOROOT
Ответ
Переменная среды $GOPATH перечисляет места, где Go ищет рабочие пространства Go.
По умолчанию Go использует в качестве GOPATH расположение $HOME/go, где $HOME — корневой каталог учетной записи пользователя нашего компьютера. Для изменения этой настройки следует изменить переменную среды $GOPATH.
Дополнительную информацию по настройке переменной $GOPATH можно найти в документации по Go.
$GOPATH — это не $GOROOT
Переменная $GOROOT определяет расположение кода Go, компилятора и инструментов, а не нашего исходного кода. Переменная $GOROOT обычно имеет значение вида /usr/local/go. Переменная $GOPATH обычно имеет значение вида $HOME/go.
Хотя явно задавать переменную $GOROOT больше не нужно, она все еще упоминается в старых материалах.
Теперь поговорим о структуре рабочего пространства Go.
Анатомия рабочего пространства Go
Внутри рабочего пространства Go или GOPATH содержится три каталога: bin, pkg и src. Каждый из этих каталогов имеет особое значение для цепочки инструментов Go.
.
├── bin
├── pkg
└── src
└── github.com/foo/bar
└── bar.go
Давайте посмотрим на каждый из этих каталогов.
Каталог $GOPATH/bin — это место, где Go размещает двоичные файлы, компилируемые go install. Операционная система использует переменную среды $PATH для поиска двоичных приложений, которые могут выполняться без полного пути. Рекомендуется добавить этот каталог в глобальную переменную $PATH.
Например, если мы не добавим $GOPATH/bin в $PATH для выполнения программы, нам нужно будет выполнять запуск следующим образом:
$GOPATH/bin/myapp
При добавлении $GOPATH/bin в $PATH мы можем вызвать программу примерно так:
myapp
Каталог $GOPATH/pkg используется Go для хранения предварительно скомпилированных объектных файлов для ускорения последующей компиляции программ. Большинству разработчиков этот каталог не потребуется. Если у вас возникнут проблемы при компиляции, вы можете спокойно удалить этот каталог, и Go воссоздаст его.
В каталоге src должны находиться все наши файлы .go или исходный код. Их не следует путать с исходным кодом, который используют инструменты Go, и который находится в каталоге $GOROOT. При написании приложений, пакетов и библиотек Go мы помещаем эти файлы в каталог $GOPATH/src/path/to/code.
@golang_interview
Ответ
Переменная среды $GOPATH перечисляет места, где Go ищет рабочие пространства Go.
По умолчанию Go использует в качестве GOPATH расположение $HOME/go, где $HOME — корневой каталог учетной записи пользователя нашего компьютера. Для изменения этой настройки следует изменить переменную среды $GOPATH.
Дополнительную информацию по настройке переменной $GOPATH можно найти в документации по Go.
$GOPATH — это не $GOROOT
Переменная $GOROOT определяет расположение кода Go, компилятора и инструментов, а не нашего исходного кода. Переменная $GOROOT обычно имеет значение вида /usr/local/go. Переменная $GOPATH обычно имеет значение вида $HOME/go.
Хотя явно задавать переменную $GOROOT больше не нужно, она все еще упоминается в старых материалах.
Теперь поговорим о структуре рабочего пространства Go.
Анатомия рабочего пространства Go
Внутри рабочего пространства Go или GOPATH содержится три каталога: bin, pkg и src. Каждый из этих каталогов имеет особое значение для цепочки инструментов Go.
.
├── bin
├── pkg
└── src
└── github.com/foo/bar
└── bar.go
Давайте посмотрим на каждый из этих каталогов.
Каталог $GOPATH/bin — это место, где Go размещает двоичные файлы, компилируемые go install. Операционная система использует переменную среды $PATH для поиска двоичных приложений, которые могут выполняться без полного пути. Рекомендуется добавить этот каталог в глобальную переменную $PATH.
Например, если мы не добавим $GOPATH/bin в $PATH для выполнения программы, нам нужно будет выполнять запуск следующим образом:
$GOPATH/bin/myapp
При добавлении $GOPATH/bin в $PATH мы можем вызвать программу примерно так:
myapp
Каталог $GOPATH/pkg используется Go для хранения предварительно скомпилированных объектных файлов для ускорения последующей компиляции программ. Большинству разработчиков этот каталог не потребуется. Если у вас возникнут проблемы при компиляции, вы можете спокойно удалить этот каталог, и Go воссоздаст его.
В каталоге src должны находиться все наши файлы .go или исходный код. Их не следует путать с исходным кодом, который используют инструменты Go, и который находится в каталоге $GOROOT. При написании приложений, пакетов и библиотек Go мы помещаем эти файлы в каталог $GOPATH/src/path/to/code.
@golang_interview
👍22🔥6❤3
Опишите все возможные состояния контейнера Docker
Ответ
Created — контейнер создан, но не активен.
Restarting — контейнер в процессе перезапуска.
Running — контейнер работает.
Paused — контейнер приостановлен.
Exited — контейнер закончил свою работу.
Dead — контейнер, который сервис попытался остановить, но не смог.
@golang_interview
Ответ
Created — контейнер создан, но не активен.
Restarting — контейнер в процессе перезапуска.
Running — контейнер работает.
Paused — контейнер приостановлен.
Exited — контейнер закончил свою работу.
Dead — контейнер, который сервис попытался остановить, но не смог.
@golang_interview
👍19🔥4❤3👎2🥰1
Загрузка из «плохого» API большого количества данных и их синхронизация с табличкой в БД (например, Postgres). Считаем, что на входе мы скачиваем JSON-массив из N (>100k) объектов (dict) заданной структуры (primary key поле + некоторое количество строковых полей). Считаем, что нам надо раз в некоторое время запускать функцию, которая создаст записи, которые есть в JSON, но их нет в базе, а далее обновит строковые поля там, где что-то поменялось, и пометить удаленными записи, которых нет в JSON, но они все еще есть в базе.
Решение
Есть 3 простых решения. Первое — просто перебрать записи из JSON, выбирая из базы записи по одной по pk, но тогда мы получим N запросов в базу, что может приводить к неконтролируемой пиковой нагрузке. Второе — выбрать из базы полностью таблицу и сравнить 2 массива, что будет работать, скорее всего, быстрее других вариантов, но будет максимально неэффективно по памяти (упрощаем решение задачи выделением дополнительных ресурсов, но, опять же, есть вероятность, что из-за неожиданно большого объема данных памяти может не хватить и выполнение таска прервется). Компромиссный вариант по производительности, нагрузке на базу и памяти — проходить циклом по JSON (или записям базы, но там есть нюансы) бачами по 100-1000 шт., накапливая обработанные id. Это сократит количество запросов на 2-3 порядка, не потребует загрузки в память всех текущих данных, но при этом будет всё ещё достаточно быстро. Также тут можно обсудить варианты реализации чисто средствами базы (временные таблицы, bulk upsert-ы и т.д.)
@golang_interview
Решение
Есть 3 простых решения. Первое — просто перебрать записи из JSON, выбирая из базы записи по одной по pk, но тогда мы получим N запросов в базу, что может приводить к неконтролируемой пиковой нагрузке. Второе — выбрать из базы полностью таблицу и сравнить 2 массива, что будет работать, скорее всего, быстрее других вариантов, но будет максимально неэффективно по памяти (упрощаем решение задачи выделением дополнительных ресурсов, но, опять же, есть вероятность, что из-за неожиданно большого объема данных памяти может не хватить и выполнение таска прервется). Компромиссный вариант по производительности, нагрузке на базу и памяти — проходить циклом по JSON (или записям базы, но там есть нюансы) бачами по 100-1000 шт., накапливая обработанные id. Это сократит количество запросов на 2-3 порядка, не потребует загрузки в память всех текущих данных, но при этом будет всё ещё достаточно быстро. Также тут можно обсудить варианты реализации чисто средствами базы (временные таблицы, bulk upsert-ы и т.д.)
@golang_interview
👍11🔥3❤1
Возможен ли запуск нескольких копий одного и того же compose файла на одном и том же сервере? Как именно?
Ответ
Это можно сделать с помощью docker-compose, использующего файл YAML для настройки сервисов приложения. После его создания вы можете в одну команду создать и запустить все сервисы. Для того, чтобы начать им пользоваться:
Задайте окружение приложения в Dockerfile, так что оно сможет быть реплицировано везде
Определите все сервисы вашего приложения в файле docker-compose.yml
Запустите docker-compose up для создания и запуска приложения целиком
➡️ Подробнее
@golang_interview
Ответ
Это можно сделать с помощью docker-compose, использующего файл YAML для настройки сервисов приложения. После его создания вы можете в одну команду создать и запустить все сервисы. Для того, чтобы начать им пользоваться:
Задайте окружение приложения в Dockerfile, так что оно сможет быть реплицировано везде
Определите все сервисы вашего приложения в файле docker-compose.yml
Запустите docker-compose up для создания и запуска приложения целиком
➡️ Подробнее
@golang_interview
👎23👍3❤1
🔥 Полезная подборка каналов
🦫 Golang
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@Golang_google - go для разработчиков
@golangtests - тесты и задачи GO
@golangl - чат Golang
@GolangJobsit - вакансии и работа GO
@golang_jobsgo - чат вакансий
@golang_books - книги Golang
@golang_speak - обсуждение задач Go
🦾 Machine learning
@ai_machinelearning_big_data – все о машинном обучении
@data_analysis_ml – все о анализе данных.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседования Data Science
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@neural – все о нейронных сетях
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
🐍 Python
@pythonl – python для датасаентиста
@pro_python_code – python на русском
@python_job_interview – подготовка к Python собеседованию
@python_testit тесты на python
@pythonlbooks - книги Python
@Django_pythonl django
@python_djangojobs - работа Python
🐧 Linux
@inux_kal - чат kali linux
@inuxkalii - linux kali
@linux_read - книги linux
👷♂️ IT работа
@hr_itwork - ит-ваканнсии
🔋 SQL
@sqlhub - базы данных
@chat_sql - базы данных чат
🤡It memes
@memes_prog - ит-мемы
💡 Javascript / front
@javascriptv - javascript изучение
@about_javascript - javascript продвинутый
@JavaScript_testit -тесты JS
@htmlcssjavas - web
@hashdev - web разработка
⚙️ Rust
@rust_code - язык программирования rust
@rust_chats - чат rust
#️⃣ c# c++
@csharp_ci - c# c++кодинг
@csharp_cplus чат
☕️ Java
@javatg - Java для програмистов
@javachats Java чат
@java_library - книги Java
@android_its Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
🦫 Golang
@golang_interview - вопросы и ответы с собеседований по Go. Для всех уровней разработчиков.
@Golang_google - go для разработчиков
@golangtests - тесты и задачи GO
@golangl - чат Golang
@GolangJobsit - вакансии и работа GO
@golang_jobsgo - чат вакансий
@golang_books - книги Golang
@golang_speak - обсуждение задач Go
🦾 Machine learning
@ai_machinelearning_big_data – все о машинном обучении
@data_analysis_ml – все о анализе данных.
@machinelearning_ru – машинное обучении на русском от новичка до профессионала.
@machinelearning_interview – подготовка к собеседования Data Science
@datascienceiot – бесплатные книги Machine learning
@ArtificialIntelligencedl – канал о искусственном интеллекте
@neural – все о нейронных сетях
@machinee_learning – чат о машинном обучении
@datascienceml_jobs - работа ds, ml
🐍 Python
@pythonl – python для датасаентиста
@pro_python_code – python на русском
@python_job_interview – подготовка к Python собеседованию
@python_testit тесты на python
@pythonlbooks - книги Python
@Django_pythonl django
@python_djangojobs - работа Python
🐧 Linux
@inux_kal - чат kali linux
@inuxkalii - linux kali
@linux_read - книги linux
👷♂️ IT работа
@hr_itwork - ит-ваканнсии
🔋 SQL
@sqlhub - базы данных
@chat_sql - базы данных чат
🤡It memes
@memes_prog - ит-мемы
💡 Javascript / front
@javascriptv - javascript изучение
@about_javascript - javascript продвинутый
@JavaScript_testit -тесты JS
@htmlcssjavas - web
@hashdev - web разработка
⚙️ Rust
@rust_code - язык программирования rust
@rust_chats - чат rust
#️⃣ c# c++
@csharp_ci - c# c++кодинг
@csharp_cplus чат
☕️ Java
@javatg - Java для програмистов
@javachats Java чат
@java_library - книги Java
@android_its Android разработка
@java_quizes - тесты Java
@Java_workit - работа Java
@progersit - шпаргалки ит
👍9🔥3😁1
Как работает goscheduler ?
Ответ
В основу работы этого планировщика положено исследование Роберта Блюмфо и Чарлза Лисерсена под названием, - “Планирование многопоточных приложений на основе захвата работы”.
Давайте посмотрим на некоторые моменты, описанные в этом документе.
Планирование выполнения это чрезвычайно сложный процесс. С точки зрения операционной системы минимальный блок выполнения — это поток. ОС не может регулировать количество потоков, создаваемых пользователем. Если пользователь хочет, то вот вам фотошоп с лайтрумом и спотифаем работают вместе, создавая армию в 1000 потоков. А если пользователь хочет, то вот вам сервер на линуксе, в котором после старта запускается и мирно спят 150 потоков, не нагружая процессор.
ОС должна распределить эти потоки по процессорам. А так как процессоров у нас обычно меньше, чем потоков, то приходится эти потоки запускать на определённое время, после чего снимать и запускать другие потоки.
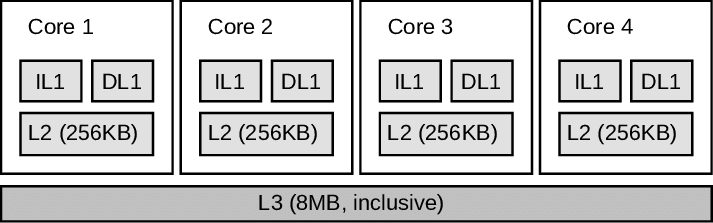
А если вы посмотрите на то, как устроен кеш любого процессора, то поймёте, что проблема может быть более глубокой. Вот, например, изображение того, как выглядят кеши моего процессора (картинка).
Данные, прочитанные из памяти, при исполнении программы будут помещаться в кеш процессора. Поэтому, когда операционная система решает, что определённый поток наигрался на процессоре, и ему пора пойти отдохнуть, работы предстоит немало. Вам нужно не только изменить инструкции, выполняемые процессором, но и переписать кеши.
А кеш у нас не один. Их на каждое ядро — четыре разных штуки. IL and DL это кеши инструкций и данных первого уровня. Дальше на ядре есть кеш второго уровня, и все ядра вместе делят кеш третьего уровня. Если вам очень хочется разобраться в работе кеша в i7, то рекомендую обратиться к официальной документации Интел. Это документ в 50 мегабайт и более чем в 5000 страниц. Информация о работе с кешем находится по всему документу. А если вам хочется почитать что-то за кружкой кофе с утра, то есть вот эта статья, где всё объясняется более понятным языком и намного более компактно.
При работе с кешем задержки будут становиться всё более и более серьёзными. Если верить Process Explorer, то в данный, ненагруженный, момент, моя ОС переключает контекст примерно 20,000 раз в секунду. А при запуске нашей программы-убиваки переключение контекста подскакивает до 700,000 раз в секунду.
Соответственно, операционная система, работая совместно с процессором, должна решить, как правильно выполнить все эти переключения контекста. Переключение контекста выполнения означает дополнительную нагрузку на процессор. А отсутствие переключения означает, что ваш медиаплеер будет лагать и выдавать музыку кусками, поскольку он не будет выполняться достаточно часто.
Для того чтобы выяснить, когда надо производить операцию переключения контекста, ОС использует планировщик задач. Если вы хотите окунуться в мир планировки задач в ОС Windows, то я рекомендую посмотреть на эту замечательную главу из книги Windows Internals, 5th edition (не самое последнее издание, но это есть в открытом доступе в интернете).
Исходя из этих данных, мы знаем, что Windows использует упреждающий планировщик задач, основанный на приоритетах. В зависимости от текущей конфигурации системы выделяются определённые кванты времени. Промежутки времени, в которые происходит выполнение процесса. Каждый процесс выполняется только в течение этого кванта времени, после этого снимается с процессора и заменяется другим процессом, в зависимости от приоритета.
Кстати, в зависимости от этого же приоритета, процесс может даже и не закончит свой квант, ввиду наличия процесса с большим приоритетом.
@golang_interview
Ответ
В основу работы этого планировщика положено исследование Роберта Блюмфо и Чарлза Лисерсена под названием, - “Планирование многопоточных приложений на основе захвата работы”.
Давайте посмотрим на некоторые моменты, описанные в этом документе.
Планирование выполнения это чрезвычайно сложный процесс. С точки зрения операционной системы минимальный блок выполнения — это поток. ОС не может регулировать количество потоков, создаваемых пользователем. Если пользователь хочет, то вот вам фотошоп с лайтрумом и спотифаем работают вместе, создавая армию в 1000 потоков. А если пользователь хочет, то вот вам сервер на линуксе, в котором после старта запускается и мирно спят 150 потоков, не нагружая процессор.
ОС должна распределить эти потоки по процессорам. А так как процессоров у нас обычно меньше, чем потоков, то приходится эти потоки запускать на определённое время, после чего снимать и запускать другие потоки.
А если вы посмотрите на то, как устроен кеш любого процессора, то поймёте, что проблема может быть более глубокой. Вот, например, изображение того, как выглядят кеши моего процессора (картинка).
Данные, прочитанные из памяти, при исполнении программы будут помещаться в кеш процессора. Поэтому, когда операционная система решает, что определённый поток наигрался на процессоре, и ему пора пойти отдохнуть, работы предстоит немало. Вам нужно не только изменить инструкции, выполняемые процессором, но и переписать кеши.
А кеш у нас не один. Их на каждое ядро — четыре разных штуки. IL and DL это кеши инструкций и данных первого уровня. Дальше на ядре есть кеш второго уровня, и все ядра вместе делят кеш третьего уровня. Если вам очень хочется разобраться в работе кеша в i7, то рекомендую обратиться к официальной документации Интел. Это документ в 50 мегабайт и более чем в 5000 страниц. Информация о работе с кешем находится по всему документу. А если вам хочется почитать что-то за кружкой кофе с утра, то есть вот эта статья, где всё объясняется более понятным языком и намного более компактно.
При работе с кешем задержки будут становиться всё более и более серьёзными. Если верить Process Explorer, то в данный, ненагруженный, момент, моя ОС переключает контекст примерно 20,000 раз в секунду. А при запуске нашей программы-убиваки переключение контекста подскакивает до 700,000 раз в секунду.
Соответственно, операционная система, работая совместно с процессором, должна решить, как правильно выполнить все эти переключения контекста. Переключение контекста выполнения означает дополнительную нагрузку на процессор. А отсутствие переключения означает, что ваш медиаплеер будет лагать и выдавать музыку кусками, поскольку он не будет выполняться достаточно часто.
Для того чтобы выяснить, когда надо производить операцию переключения контекста, ОС использует планировщик задач. Если вы хотите окунуться в мир планировки задач в ОС Windows, то я рекомендую посмотреть на эту замечательную главу из книги Windows Internals, 5th edition (не самое последнее издание, но это есть в открытом доступе в интернете).
Исходя из этих данных, мы знаем, что Windows использует упреждающий планировщик задач, основанный на приоритетах. В зависимости от текущей конфигурации системы выделяются определённые кванты времени. Промежутки времени, в которые происходит выполнение процесса. Каждый процесс выполняется только в течение этого кванта времени, после этого снимается с процессора и заменяется другим процессом, в зависимости от приоритета.
Кстати, в зависимости от этого же приоритета, процесс может даже и не закончит свой квант, ввиду наличия процесса с большим приоритетом.
@golang_interview
{kind=link}
👎17👍8❤1👏1
Напишите код для перестановки всех символов строки.
Реализуйте функцию perm(), которая принимает слайс или строку и выводит все возможные комбинации символов. Пишите свой вариант ответа в комментариях.
Ответ
@golang_interview
Реализуйте функцию perm(), которая принимает слайс или строку и выводит все возможные комбинации символов. Пишите свой вариант ответа в комментариях.
Ответ
package main
import "fmt"
// Perm calls f with each permutation of a.
func Perm(a []rune, f func([]rune)) {
perm(a, f, 0)
}
// Permute the values at index i to len(a)-1.
func perm(a []rune, f func([]rune), i int) {
if i > len(a) {
f(a)
return
}
perm(a, f, i+1)
for j := i + 1; j < len(a); j++ {
a[i], a[j] = a[j], a[i]
perm(a, f, i+1)
a[i], a[j] = a[j], a[i]
}
}
func main() {
Perm([]rune("abc"), func(a []rune) {
fmt.Println(string(a))
})
}
@golang_interview
👍11👎2
Что такое временная сложность алгоритма (time complexity)
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n. Тогда говорят, что временная сложность этого алгоритма равна О(n3), т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n).
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n, т. е. n2.
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1). Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
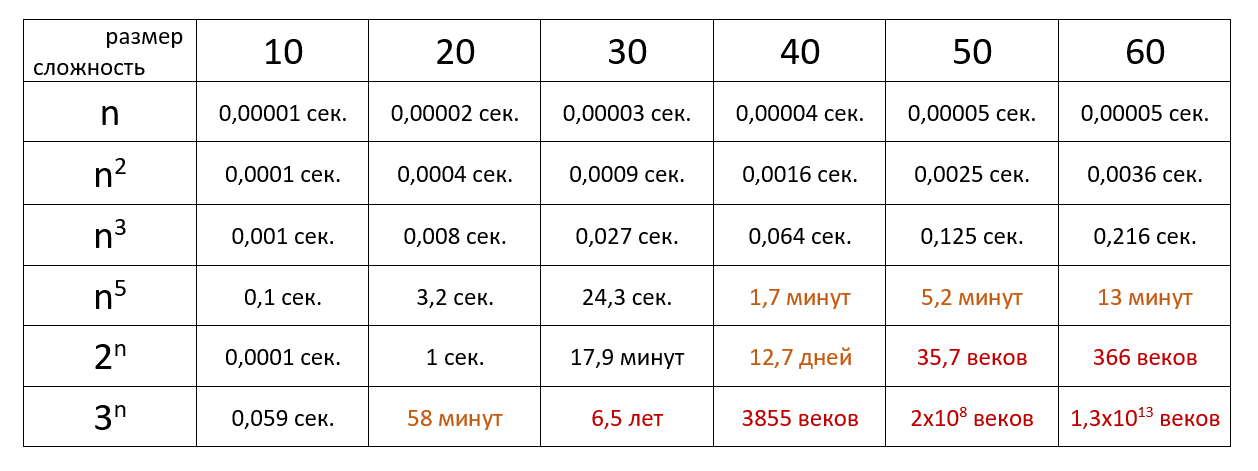
Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
@golang_interview
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n. Тогда говорят, что временная сложность этого алгоритма равна О(n3), т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n).
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n, т. е. n2.
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1). Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
@golang_interview
{kind=link}
👍18
Напишите код, чтобы поменять местами значения двух переменных без использования временной переменной
Ответ
Реализуйте функцию swap(), которая меняет местами значения двух переменных без использования третьей переменной.
Хотя это может быть сложно на других языках, Go делает это легко.
Мы можем просто написать утверждение b, a = a, b, на какие данные ссылается переменная, не связываясь ни с одним из значений.
Пишите свои варианты в комменнтариях
@golang_interview
Ответ
Реализуйте функцию swap(), которая меняет местами значения двух переменных без использования третьей переменной.
Хотя это может быть сложно на других языках, Go делает это легко.
Мы можем просто написать утверждение b, a = a, b, на какие данные ссылается переменная, не связываясь ни с одним из значений.
package main
import "fmt"
func main() {
fmt.Println(swap())
}
func swap() []int {
a, b := 15, 10
b, a = a, b
return []int{a, b}
}Пишите свои варианты в комменнтариях
@golang_interview
👍14👎11😢5
Расскажите о командах systemd для управления Docker
Ответ
Для запуска Docker многие дистрибутивы Linux используют systemd. Для запуска сервисов используется команда systemctl. Если ее нет, следует использовать команду service.
Чтобы добавить сервис в автозагрузку, либо убрать его:
Для проверки параметров запуска сервиса и их изменения:
Просмотра связанных с сервисом журналов:
Опишите процесс масштабирования контейнеров Docker
Контейнеры могут быть масштабированы с использованием команды docker-compose scale. Процесс масштабирования такой:
Масштабируем контейнер и запускаем n экземпляров:
В вышеприведенном примере имя сервиса задается в файле docker-compose-run-srvr.yml, а также запускается n копий контейнеров, где n — любое целое положительное число.
После масштабирования контейнера для проверки можно использовать такую команду:
@golang_interview
Ответ
Для запуска Docker многие дистрибутивы Linux используют systemd. Для запуска сервисов используется команда systemctl. Если ее нет, следует использовать команду service.
$ sudo systemctl start docker
$ sudo service docker startЧтобы добавить сервис в автозагрузку, либо убрать его:
$ sudo systemctl enable docker
$ sudo systemctl disable dockerДля проверки параметров запуска сервиса и их изменения:
$ sudo systemctl edit dockerПросмотра связанных с сервисом журналов:
$ journalctl -u dockerОпишите процесс масштабирования контейнеров Docker
Контейнеры могут быть масштабированы с использованием команды docker-compose scale. Процесс масштабирования такой:
Масштабируем контейнер и запускаем n экземпляров:
$ docker-compose --file docker-compose-run-srvr.yml scale <service_name>=<n>В вышеприведенном примере имя сервиса задается в файле docker-compose-run-srvr.yml, а также запускается n копий контейнеров, где n — любое целое положительное число.
После масштабирования контейнера для проверки можно использовать такую команду:
$ docker ps -a@golang_interview
👍18😁4❤1🔥1