
Как обещала - пост об одном из методов, которые я использовала в дипломе, чтобы понять пространственные взаимосвязи между пешеходами, инфраструктурой и музеями. На мой взгляд, сильно недооцененный в России метод при анализе социально0экономических показателей регионов.
Global Moran's индекс (Moran's I)- индекс пространственной автокорреляции. Он показывает насколько расположенные рядом с друг с другом объекты схоже себя ведут или похожи друг на друга по определенному параметру - чем больше схожесть, тем выше значение индекса. Значения индекса измеряются от -1 до 1, где -1 - это шахматная доска ( соседи полностью отличаются друг от друга), а 1 - это российский флаг( идеальное разделение на группы с одинаковыми значениями).
При расчетах индекса ориентируются еще на z-score и pseudo p-value - как и в обычных статистических тестах, они показывают вероятность достичь полученного значения индекса в случае его рандомного распределения между регионами. Подробнее написано здесь: https://mgimond.github.io/Spatial/spatial-autocorrelation.html.
Расчет индекса зависит от того как будут определены соседи - в одном случае это могут быть только объекты имеющие общую границу( метод "ладьи") или общую точку ( метод "королевы") , в другом соседями будут считаться все в рамках заданного расстояния, при этом чем дальше они от анализируемого региона, тем меньше их вес.
Moran's I - индикатор того нужно ли включать пространственные факторы в анализ. Это первый этап перед тем как искать локальные кластеры и "горящие точки" или строить пространственные регрессии.
Индекс обычно используют не для оценки распределения самого показателя, а для оценки распределения остатков модели, которая пытается его объяснить. Инсайт: при оценке социо-демографических показателей регионов, например стоимости жилья или уровня безработицы - Moran's I показывает наличие кластеров ( групп) в распределении или, проще говоря, что соседи важны.
Интуитивно понятный пример : средний доход населения российского региона. Очевидно, что доход жителей Подмосковья или Ленинградской области зависит не только от количества рабочих мест или инвестиций в них, но и от дохода жителей столиц - они служат индикатором столичных зарплат, которые получают многие из жителей областей.
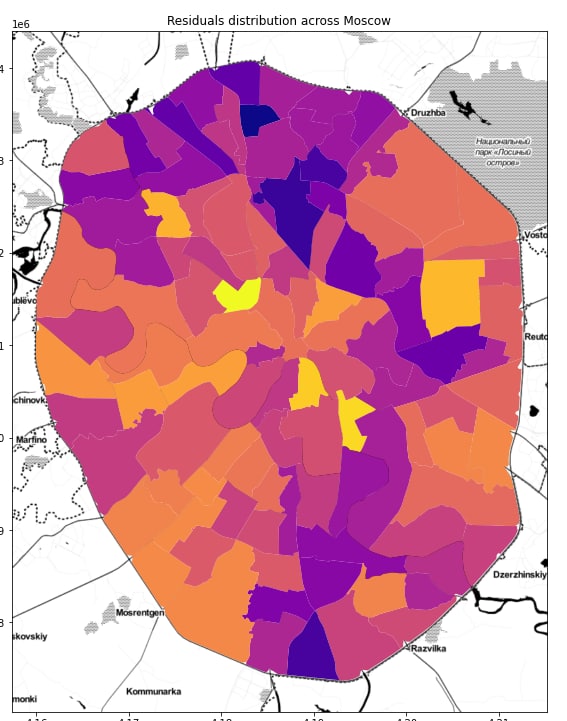
В случае моего диплома, индекс (= 0.42) показал , что количество пешеходов зависит не только от инфраструктуры и транспортной доступности, но и от количества пешеходов в соседних районах. Это совпадает со словами датского урбаниста Jehn Geil ,о том, что "люди привлекают людей на улицы". К слову, с включением пространственных факторов в модель ее точность модели ( R^2) улучшилось с 46% до 86%. Для наглядности прикладываю карту остатков линейной регрессии, прогнозирующей число пешеходов, по районам - пространственная взаимосвязь на лицо.
Инструменты для расчета индекса:
1. Geoda (https://geodacenter.github.io/ ) - программа от "создателя"локальной версии индекса. Мощный инструмент для пространственного анализа экономических показателей, не требующий навыков программирования. Ссылка на серию лекций автора: https://www.youtube.com/channel/UCzvhOfSmJpRsFRF2Pgrv-Wg
2. Инструмент в ArcGIS в разделе Spatial Statistics Tools
3. R - Moran.I из библиотеки ape
4. Python - метод Moran из библиотеки pysal
Global Moran's индекс (Moran's I)- индекс пространственной автокорреляции. Он показывает насколько расположенные рядом с друг с другом объекты схоже себя ведут или похожи друг на друга по определенному параметру - чем больше схожесть, тем выше значение индекса. Значения индекса измеряются от -1 до 1, где -1 - это шахматная доска ( соседи полностью отличаются друг от друга), а 1 - это российский флаг( идеальное разделение на группы с одинаковыми значениями).
При расчетах индекса ориентируются еще на z-score и pseudo p-value - как и в обычных статистических тестах, они показывают вероятность достичь полученного значения индекса в случае его рандомного распределения между регионами. Подробнее написано здесь: https://mgimond.github.io/Spatial/spatial-autocorrelation.html.
Расчет индекса зависит от того как будут определены соседи - в одном случае это могут быть только объекты имеющие общую границу( метод "ладьи") или общую точку ( метод "королевы") , в другом соседями будут считаться все в рамках заданного расстояния, при этом чем дальше они от анализируемого региона, тем меньше их вес.
Moran's I - индикатор того нужно ли включать пространственные факторы в анализ. Это первый этап перед тем как искать локальные кластеры и "горящие точки" или строить пространственные регрессии.
Индекс обычно используют не для оценки распределения самого показателя, а для оценки распределения остатков модели, которая пытается его объяснить. Инсайт: при оценке социо-демографических показателей регионов, например стоимости жилья или уровня безработицы - Moran's I показывает наличие кластеров ( групп) в распределении или, проще говоря, что соседи важны.
Интуитивно понятный пример : средний доход населения российского региона. Очевидно, что доход жителей Подмосковья или Ленинградской области зависит не только от количества рабочих мест или инвестиций в них, но и от дохода жителей столиц - они служат индикатором столичных зарплат, которые получают многие из жителей областей.
В случае моего диплома, индекс (= 0.42) показал , что количество пешеходов зависит не только от инфраструктуры и транспортной доступности, но и от количества пешеходов в соседних районах. Это совпадает со словами датского урбаниста Jehn Geil ,о том, что "люди привлекают людей на улицы". К слову, с включением пространственных факторов в модель ее точность модели ( R^2) улучшилось с 46% до 86%. Для наглядности прикладываю карту остатков линейной регрессии, прогнозирующей число пешеходов, по районам - пространственная взаимосвязь на лицо.
Инструменты для расчета индекса:
1. Geoda (https://geodacenter.github.io/ ) - программа от "создателя"локальной версии индекса. Мощный инструмент для пространственного анализа экономических показателей, не требующий навыков программирования. Ссылка на серию лекций автора: https://www.youtube.com/channel/UCzvhOfSmJpRsFRF2Pgrv-Wg
2. Инструмент в ArcGIS в разделе Spatial Statistics Tools
3. R - Moran.I из библиотеки ape
4. Python - метод Moran из библиотеки pysal
{kind=link}
"Интересный" способ применения AI нашло в этом году правительство Великобритании ( https://rpubs.com/JeniT/ofqual-algorithm) . В августе этого года из-за пандемии правительство отменило школьные выпускные экзамены и вместо этого решило спрогнозировать оценки выпускников с помощью модели.
Модель принимала на вход индивидуальную успеваемость каждого ученика, начиная с начальной школы, прогноз оценок от учителей и нормировала ее на результаты школы за 2017-2019 относительно. Затем для каждой возможной оценки, каждого предмета и каждого ученика модель рассчитывала вероятность получить как минимум такую оценку и выбирала наиболее вероятную. На выходе она давала финальную оценку по каждому предмету и говорила, поступил школьник в желаемый университет или нет.
Интересно, что целью модели было не дать, как можно более точный балл по каждому ученику, а в среднем по школе, региону и стране получить оценку, которая бы не выбивалась из исторической динамики.
Как результат: множество недовольных школьников (https://www.bbc.com/news/education-53787203) с заниженными, по их мнению, баллами - почти 40% оценок модели оказалось ниже выставленных преподавателями. Однако оставить оценки учителей разрешили только в Шотландии, тогда как в остальных частях UK говорили о завышении баллов - средний прогноз учителей оказался на 2.5 пункта ( при максимуме в 7) выше реального прошлогоднего в этих регионах
Какие из этого "опыта можно сделать выводы":
1. В Британии все школы хранят детальную статистику по своим ученикам за последние 12 лет в оцифрованном формате - круто!
2. Модели еще не готовы точно прогнозировать поведение человека, тем более ребенка, тем более в поворотный момент его жизни. Судя по тому что написано в открытых источниках, профиль школьника строился только на основе его оценок и рейтинга, упуская из виду его личные качества, а также возможность прогресса. Может британские дети и отличаются от российских, но не думаю, что настолько, чтобы быть полностью "предсказуемыми" : волнение на экзамене или наоборот, умение собраться, также как и подготовиться "за ночь" никто не отменял
3. Сильная предвзятость в британском мышлении. Ограниченный данными об "успеваемости" школы, алгоритм не мог и не учитывал возможность прогресса учебного заведения за год. То есть создатели просто не рассматривали такую возможность , хотя теоретически, можно было бы считать вероятность такого события, опираясь на косвенные признаки и их связь с прогрессом школ в истории, и взвешивать на него прошлогодний рейтинг
4. Классовость системы: студенты из частных школ априори лучше студентов из общеобразовательных учреждений, школьники Англии из социально-обсепеченных районов лучше своих Шотландских сверстников из неблагоприятных районов
5. Если хочешь способ быстро объяснить ребятам 17-18 лет особенности работы алгоритмов ML, спрогнозируй их выпускные оценки)
Модель принимала на вход индивидуальную успеваемость каждого ученика, начиная с начальной школы, прогноз оценок от учителей и нормировала ее на результаты школы за 2017-2019 относительно. Затем для каждой возможной оценки, каждого предмета и каждого ученика модель рассчитывала вероятность получить как минимум такую оценку и выбирала наиболее вероятную. На выходе она давала финальную оценку по каждому предмету и говорила, поступил школьник в желаемый университет или нет.
Интересно, что целью модели было не дать, как можно более точный балл по каждому ученику, а в среднем по школе, региону и стране получить оценку, которая бы не выбивалась из исторической динамики.
Как результат: множество недовольных школьников (https://www.bbc.com/news/education-53787203) с заниженными, по их мнению, баллами - почти 40% оценок модели оказалось ниже выставленных преподавателями. Однако оставить оценки учителей разрешили только в Шотландии, тогда как в остальных частях UK говорили о завышении баллов - средний прогноз учителей оказался на 2.5 пункта ( при максимуме в 7) выше реального прошлогоднего в этих регионах
Какие из этого "опыта можно сделать выводы":
1. В Британии все школы хранят детальную статистику по своим ученикам за последние 12 лет в оцифрованном формате - круто!
2. Модели еще не готовы точно прогнозировать поведение человека, тем более ребенка, тем более в поворотный момент его жизни. Судя по тому что написано в открытых источниках, профиль школьника строился только на основе его оценок и рейтинга, упуская из виду его личные качества, а также возможность прогресса. Может британские дети и отличаются от российских, но не думаю, что настолько, чтобы быть полностью "предсказуемыми" : волнение на экзамене или наоборот, умение собраться, также как и подготовиться "за ночь" никто не отменял
3. Сильная предвзятость в британском мышлении. Ограниченный данными об "успеваемости" школы, алгоритм не мог и не учитывал возможность прогресса учебного заведения за год. То есть создатели просто не рассматривали такую возможность , хотя теоретически, можно было бы считать вероятность такого события, опираясь на косвенные признаки и их связь с прогрессом школ в истории, и взвешивать на него прошлогодний рейтинг
4. Классовость системы: студенты из частных школ априори лучше студентов из общеобразовательных учреждений, школьники Англии из социально-обсепеченных районов лучше своих Шотландских сверстников из неблагоприятных районов
5. Если хочешь способ быстро объяснить ребятам 17-18 лет особенности работы алгоритмов ML, спрогнозируй их выпускные оценки)
Bbc
Why did the A-level algorithm say no?
What were the factors that really decided the winner and losers for A-level grades?
Продолжая тему важности "соседей".
Недавний пост Дмитрия Прокофьева об агломерациях в России и, в частности в Ленобласти, навел меня на мысль, что за исключением связки Москва-Подмосковье ( а в России, если верить википедии их 17) я ни разу не слышала о том, что регионы обменивались данными для запуска новых проектов. При этом даже в случае столичной агломерации, которая включает Москву и ближайшие ко МКАДу города, их кооперация ограничивается планированием транспортных потоков.
На самом же деле связей намного больше. Специалисты, в целом, рассматривают города как вершины сети, которые соединены с друг с другом разными типами связей, и за счет этого изменения в одном городе приводят к изменению связанных с ним территорий и дальше по цепочке до изменения во всей сети в зависимости наличия и от силы связей ( M.Batty). Чем больше связей существует, тем больше воздействие на сеть.
С данной точки зрения агломерации или metropolitan regions - это кластеры сети, где вершины тесно соединены с центром и иногда между собой.
Европейский комитет называет следующие области взаимодействия между вершинами и центром:
1. Мобильность: дороги и хорошо спланированный общественный транспорт поддерживают ежедневные поездки в центр на работу, учебу, миграцию людей, поездки из центра на природу, на дачу.
2. Экономика: поддержка бизнеса позволяет создавать рыночные отношения между городом и пригородами: вырастая бизнес создает рабочие места в пригородах для удешевления стоимости аренды или из-за потребности в большой площади, например под склад. Плюс появляются торговые отношения, например между сельскохозяйственными производителями и жителями центрального города
3. Возможности для отдыха: создание природных комплексов и развлекательных центров в пригородах, ведет к созданию единых туристических маршрутов, которые могут распределить туристический поток по всей агломерации
4. Экология - создание цепочки "зеленых" объектов(здесь объяснение что это такое ) из пригородов в центр обеспечит более свежий воздух и понижение температуры в урбанизированных районах
5. Использование воды и переработка мусора: "импорт воды" в центр осуществляется из зеленой части агломерации, так как она там чище, а мусор, наоборот, вывозится в пригороды, так как в центре не хватает места для мусоросжигательных заводов.
6. Cоцальные связи - близость проживания позволяет физически чаще видеться с друзьями и родными. Кроме этого, мобильную связь и интернет проще обеспечить для абонентов на небольшой территории, чем прокладывать сети по всей стране. ( Про обратный эффект, что в большом городе мы даже соседей не знаем, почему-то не пишут))
К чему я веду : если создавать агломерации, то нужно думать о том, как обеспечить совместное принятие решение и их оценку: для этого должен быть настроен шеринг данными и смоделирована система, которая будет показывать, как эти решения повлияют на всех членов агломерации.
Недавний пост Дмитрия Прокофьева об агломерациях в России и, в частности в Ленобласти, навел меня на мысль, что за исключением связки Москва-Подмосковье ( а в России, если верить википедии их 17) я ни разу не слышала о том, что регионы обменивались данными для запуска новых проектов. При этом даже в случае столичной агломерации, которая включает Москву и ближайшие ко МКАДу города, их кооперация ограничивается планированием транспортных потоков.
На самом же деле связей намного больше. Специалисты, в целом, рассматривают города как вершины сети, которые соединены с друг с другом разными типами связей, и за счет этого изменения в одном городе приводят к изменению связанных с ним территорий и дальше по цепочке до изменения во всей сети в зависимости наличия и от силы связей ( M.Batty). Чем больше связей существует, тем больше воздействие на сеть.
С данной точки зрения агломерации или metropolitan regions - это кластеры сети, где вершины тесно соединены с центром и иногда между собой.
Европейский комитет называет следующие области взаимодействия между вершинами и центром:
1. Мобильность: дороги и хорошо спланированный общественный транспорт поддерживают ежедневные поездки в центр на работу, учебу, миграцию людей, поездки из центра на природу, на дачу.
2. Экономика: поддержка бизнеса позволяет создавать рыночные отношения между городом и пригородами: вырастая бизнес создает рабочие места в пригородах для удешевления стоимости аренды или из-за потребности в большой площади, например под склад. Плюс появляются торговые отношения, например между сельскохозяйственными производителями и жителями центрального города
3. Возможности для отдыха: создание природных комплексов и развлекательных центров в пригородах, ведет к созданию единых туристических маршрутов, которые могут распределить туристический поток по всей агломерации
4. Экология - создание цепочки "зеленых" объектов(здесь объяснение что это такое ) из пригородов в центр обеспечит более свежий воздух и понижение температуры в урбанизированных районах
5. Использование воды и переработка мусора: "импорт воды" в центр осуществляется из зеленой части агломерации, так как она там чище, а мусор, наоборот, вывозится в пригороды, так как в центре не хватает места для мусоросжигательных заводов.
6. Cоцальные связи - близость проживания позволяет физически чаще видеться с друзьями и родными. Кроме этого, мобильную связь и интернет проще обеспечить для абонентов на небольшой территории, чем прокладывать сети по всей стране. ( Про обратный эффект, что в большом городе мы даже соседей не знаем, почему-то не пишут))
К чему я веду : если создавать агломерации, то нужно думать о том, как обеспечить совместное принятие решение и их оценку: для этого должен быть настроен шеринг данными и смоделирована система, которая будет показывать, как эти решения повлияют на всех членов агломерации.
Telegram
Деньги и песец
В продолжение идеи о том, что для города человеческие потоки и активности важнее инфраструктуры (ну, здесь, скорее, как «софт» и «железо» для компьютера, инфраструктура важна, но без «софта», «без людей» работать ничего не будет).
В Санкт-Петербурге региональный…
В Санкт-Петербурге региональный…
#urbanreflections
В связи с недавней новостью об утечке данных пациентов в Москве, возникли следующие мысли.
Общий уровень осведомленности об информационной безопасности в России очень низкий - у нас этому не учат. Лично я, несмотря на техническое образование, впервые столкнулась с этой темой, только придя в Сбер, когда получила требование пройти серию тестов на кибербезопасность. Проходят их все сотрудники без исключения: независимо от того анализируешь ли ты данные или обслуживаешь клиентов в отделении. Получается в России научить людей «безопасной» работе с данными - это сугубо ответственность работодателя – государство в целом не парится.
В мире не так: умение защитить данные повсеместно становится таким же важным, как умение писать, и поэтому власти отвечают за то, чтобы каждый, понимал, что такое кибербезопасность. У многих, в том числе и образцовых для Москвы Сингапуре , Дубае и Гонконге есть стратегии кибербезопасности, а где-то, как в Лондоне, кибербезопасность включена в стратегию Умного города.
Процитирую:
Дубаи: «наша первая цель: повысить знание населения о важности кибербезопасности и гарантировать, что они осознают всю опасность киберугроз»;
Сингапур: «кибербезопасность - это командная работа и каждый должен сыграть свою роль. Правительство возьмет на себя инициативы по усилению позиции Сингапура в области кибербезопасности, и нам понадобится помощь каждого для получения долгосрочных выгод для киберэкосистемы»;
Гонконг: «Поскольку информационная безопасность - это дело каждого, департаменты должны постоянно повышать осведомленность об информационной безопасности во всех организациях и организовывать обучение, чтобы гарантировать, что все связанные стороны понимают риски, соблюдают правила и требования безопасности и соответствуют передовым методам обеспечения безопасности».
У Москвы нет такой стратегии, а ответственность смещена с лидеров города на ДИТ и дальше на it-специалистов подразделений.
Про кибербезопасность упоминает стратегия «Умного города 2030», но к ней есть вопросы.
1. Ни слова про обучение. Цель «Повышение эффективности противодействия киберугрозам» скорее про технологии, чем про развитие компетенций, а ведь именно они стали причиной недавней "утечки". На мой взгляд это должно быть частью раздела «Образование»
2. К выше названной цели есть показатель «доля органов, использующих стандарты безопасного информационного взаимодействия». Становится страшно: какое тогда взаимодействие сейчас? Правильно ли я понимаю, что, например, к 2030 году, департамент образования должен обеспечить безопасность, а вот здравоохранения только в следующем 10-летии?
Конечно, у города как работодателя есть документы для чиновников. В случае Москвы - это методологические рекомендации от 2019 года. С одной стороны он включает в себя все, что требует закон: здесь и ознакомление сотрудников с требованиями обработки персданных (ПДн), и определение ответственного за безопасность данных, и соответствие фактического использования ПДн заявленным целям, и контроль защищенности.
С другой стороны, погружаясь в документ, видно, что - это сплошная формальность. Вопросов много:
1. Почему согласно приложению 7 к Методологии к ПДн, с которыми работают госорганы, относятся только данные из кадровой и бухгалтерской системы? То есть информация о москвичах за персданные у чиновников в принципе не считается?
2. Почему для департамента здравоохранения, работающего с наиболее "чувствительными" данными нет отдельных правил?
3. Как учитывается специфика работы госорганов? Документ как будто списан с частной компании, даже слово "Организация" осталось
4. Где можно увидеть, как именно будет гарантировано знание основ защиты данных сотрудниками и как технически предполагается информацию защищать? По факту идет просто переписывание 152-ФЗ без деталей
Чтобы понять насколько ситуация нехорошая, представьте, что вы забираетесь на Эверест, не пройдя обучение и не имея предварительной подготовки, при этом ваша страховка рассчитана для занятий на скалодроме. Много ли у вас шансов достичь вершины?
В связи с недавней новостью об утечке данных пациентов в Москве, возникли следующие мысли.
Общий уровень осведомленности об информационной безопасности в России очень низкий - у нас этому не учат. Лично я, несмотря на техническое образование, впервые столкнулась с этой темой, только придя в Сбер, когда получила требование пройти серию тестов на кибербезопасность. Проходят их все сотрудники без исключения: независимо от того анализируешь ли ты данные или обслуживаешь клиентов в отделении. Получается в России научить людей «безопасной» работе с данными - это сугубо ответственность работодателя – государство в целом не парится.
В мире не так: умение защитить данные повсеместно становится таким же важным, как умение писать, и поэтому власти отвечают за то, чтобы каждый, понимал, что такое кибербезопасность. У многих, в том числе и образцовых для Москвы Сингапуре , Дубае и Гонконге есть стратегии кибербезопасности, а где-то, как в Лондоне, кибербезопасность включена в стратегию Умного города.
Процитирую:
Дубаи: «наша первая цель: повысить знание населения о важности кибербезопасности и гарантировать, что они осознают всю опасность киберугроз»;
Сингапур: «кибербезопасность - это командная работа и каждый должен сыграть свою роль. Правительство возьмет на себя инициативы по усилению позиции Сингапура в области кибербезопасности, и нам понадобится помощь каждого для получения долгосрочных выгод для киберэкосистемы»;
Гонконг: «Поскольку информационная безопасность - это дело каждого, департаменты должны постоянно повышать осведомленность об информационной безопасности во всех организациях и организовывать обучение, чтобы гарантировать, что все связанные стороны понимают риски, соблюдают правила и требования безопасности и соответствуют передовым методам обеспечения безопасности».
У Москвы нет такой стратегии, а ответственность смещена с лидеров города на ДИТ и дальше на it-специалистов подразделений.
Про кибербезопасность упоминает стратегия «Умного города 2030», но к ней есть вопросы.
1. Ни слова про обучение. Цель «Повышение эффективности противодействия киберугрозам» скорее про технологии, чем про развитие компетенций, а ведь именно они стали причиной недавней "утечки". На мой взгляд это должно быть частью раздела «Образование»
2. К выше названной цели есть показатель «доля органов, использующих стандарты безопасного информационного взаимодействия». Становится страшно: какое тогда взаимодействие сейчас? Правильно ли я понимаю, что, например, к 2030 году, департамент образования должен обеспечить безопасность, а вот здравоохранения только в следующем 10-летии?
Конечно, у города как работодателя есть документы для чиновников. В случае Москвы - это методологические рекомендации от 2019 года. С одной стороны он включает в себя все, что требует закон: здесь и ознакомление сотрудников с требованиями обработки персданных (ПДн), и определение ответственного за безопасность данных, и соответствие фактического использования ПДн заявленным целям, и контроль защищенности.
С другой стороны, погружаясь в документ, видно, что - это сплошная формальность. Вопросов много:
1. Почему согласно приложению 7 к Методологии к ПДн, с которыми работают госорганы, относятся только данные из кадровой и бухгалтерской системы? То есть информация о москвичах за персданные у чиновников в принципе не считается?
2. Почему для департамента здравоохранения, работающего с наиболее "чувствительными" данными нет отдельных правил?
3. Как учитывается специфика работы госорганов? Документ как будто списан с частной компании, даже слово "Организация" осталось
4. Где можно увидеть, как именно будет гарантировано знание основ защиты данных сотрудниками и как технически предполагается информацию защищать? По факту идет просто переписывание 152-ФЗ без деталей
Чтобы понять насколько ситуация нехорошая, представьте, что вы забираетесь на Эверест, не пройдя обучение и не имея предварительной подготовки, при этом ваша страховка рассчитана для занятий на скалодроме. Много ли у вас шансов достичь вершины?
ТАСС
Власти Москвы подтвердили утечку персональных данных москвичей, переболевших COVID-19
В настоящее время проводится проверка
#geotools
Еще один повод обратить внимание на мощный и понятный пользователю инструмент для пространственного анализа. Единственный язык, который нужно хоть чуть-чуть знать, чтобы работать с ним - это английский. Ссылка : https://geodacenter.github.io
Еще один повод обратить внимание на мощный и понятный пользователю инструмент для пространственного анализа. Единственный язык, который нужно хоть чуть-чуть знать, чтобы работать с ним - это английский. Ссылка : https://geodacenter.github.io
Forwarded from Egor Kotov
возвращаясь к разговору о пространственных моделях - сегодня вышла GeoDa 1.8 - GUI open source для работы с пространственной автокорреляцией, пространственными моделями, кластеризацией и др. в РФ меньше 1000 пользователей. Рекомендую обратить внимание. Все, что она может - можно накодить в R/Pyhon/Julia, но при первом знакомстве с концептами это отличный помощник + интерактивные карты и графики в GeoDa можно заменить только очень долгим кодингом собственных дэшбордов
Forwarded from Egor Kotov
This media is not supported in your browser
VIEW IN TELEGRAM
Так как в этом году жизнь в городах диктовалась пандемией, то в финальный посте я собрала на мой взгляд основные изменения, с которыми столкнулись города в борьбе с ней
1. Усилилось взаимодействие между городскими властями, бизнесом и академией: первые формировали запрос, вторые давали данные ( преимущественно данные о перемещениях), третьи делали аналитику и формировали рекомендации. Например, в этой статье financial times совместная работа University College London и компании Kup показала, что люди больше не могут сидеть дома и властям необходимо начинать разумно снижать ограничения.
2. Пространственные модели стали чаще использоваться для анализа. Помимо классических SIR и SEIR применяли agent-based modelling - подход, позволяющий учитывать помимо пространственно-временных особенностей еще индивидуальные характеристики агентов – например, возраст, хронические заболевания или число контактов. Примеры: https://www.nature.com/articles/s41591-020-1001-6 ( Франция), https://www.medrxiv.org/content/10.1101/2020.07.05.20146977v1 (США)
3 С помощью графики журналистам удалось объяснить людям, почему необходимо соблюдать локдаун. Пример WashingtonPost
4. Необходимость в открытых данных стала более очевидной и вместе с этим выросло число источников ( жаль только, что коснулось это преимущественно тех стран, кто уже с ними работал).
Ресурсы:
https://data.world/datasets/covid-19 – статистика некоторых стран в разрезе городов по перемещениям людей и числу заболевших https://wiki.unece.org/display/DSOCIOT/Data+Sources+on+Coronavirus+impact+on+transport – основные цифры по использованию транспорта в период локдауна по странам
5. Острее стал вопрос приватности персональных данных в связи с необходимостью трекинга распространения вируса. Что выбрать : сохранение тайны личных данных, но при этом невысокой эффективности отслеживания контактов заболевших, как в Европе , либо нарушение права на приватность ради гарантии , что люди сидят дома, как, например, в Южной Корее и Эквадоре
6. Многие страны разработали мобильные приложения для сбора статистики. Решения : GPS-трекинг, определение соседних устройств по Bluetooth, чекин по qr-коду в общественных местах. Полный список решений по странам здесь
7. Стали больше говорить о городе шаговой доступности ( в 15-минутах от дома есть все необходимые сервисы) и увеличилось число исследований оценки качества текущей инфраструктуры для пешеходов:
рекомендации
анализ перепланировочных инициатив
оценка текущей ширины тротуаров в Лондоне
Суммирая, кажется, что год оказался положительным для развития работы с данными в городах и еще острее показал существующие проблемы "smart cities", такие как слабая защищенность персональных данных и недостаточная связанность между источниками особенно разных стейкхолдеров, не позволяющая быстро получить картину целиком.
Надеюсь Новый год учтет ошибки предыдущего, а прогрессивные исследования будут посвящены не только пандемии)
1. Усилилось взаимодействие между городскими властями, бизнесом и академией: первые формировали запрос, вторые давали данные ( преимущественно данные о перемещениях), третьи делали аналитику и формировали рекомендации. Например, в этой статье financial times совместная работа University College London и компании Kup показала, что люди больше не могут сидеть дома и властям необходимо начинать разумно снижать ограничения.
2. Пространственные модели стали чаще использоваться для анализа. Помимо классических SIR и SEIR применяли agent-based modelling - подход, позволяющий учитывать помимо пространственно-временных особенностей еще индивидуальные характеристики агентов – например, возраст, хронические заболевания или число контактов. Примеры: https://www.nature.com/articles/s41591-020-1001-6 ( Франция), https://www.medrxiv.org/content/10.1101/2020.07.05.20146977v1 (США)
3 С помощью графики журналистам удалось объяснить людям, почему необходимо соблюдать локдаун. Пример WashingtonPost
4. Необходимость в открытых данных стала более очевидной и вместе с этим выросло число источников ( жаль только, что коснулось это преимущественно тех стран, кто уже с ними работал).
Ресурсы:
https://data.world/datasets/covid-19 – статистика некоторых стран в разрезе городов по перемещениям людей и числу заболевших https://wiki.unece.org/display/DSOCIOT/Data+Sources+on+Coronavirus+impact+on+transport – основные цифры по использованию транспорта в период локдауна по странам
5. Острее стал вопрос приватности персональных данных в связи с необходимостью трекинга распространения вируса. Что выбрать : сохранение тайны личных данных, но при этом невысокой эффективности отслеживания контактов заболевших, как в Европе , либо нарушение права на приватность ради гарантии , что люди сидят дома, как, например, в Южной Корее и Эквадоре
6. Многие страны разработали мобильные приложения для сбора статистики. Решения : GPS-трекинг, определение соседних устройств по Bluetooth, чекин по qr-коду в общественных местах. Полный список решений по странам здесь
7. Стали больше говорить о городе шаговой доступности ( в 15-минутах от дома есть все необходимые сервисы) и увеличилось число исследований оценки качества текущей инфраструктуры для пешеходов:
рекомендации
анализ перепланировочных инициатив
оценка текущей ширины тротуаров в Лондоне
Суммирая, кажется, что год оказался положительным для развития работы с данными в городах и еще острее показал существующие проблемы "smart cities", такие как слабая защищенность персональных данных и недостаточная связанность между источниками особенно разных стейкхолдеров, не позволяющая быстро получить картину целиком.
Надеюсь Новый год учтет ошибки предыдущего, а прогрессивные исследования будут посвящены не только пандемии)
Ft
Subscribe to read | Financial Times
News, analysis and comment from the Financial Times, the worldʼs leading global business publication
Forwarded from Медуза — LIVE
Департамент информационных технологий Москвы потратит 185 миллионов рублей на создание подробной и персонализированной базы данных о каждом жителе города.
Среди данных будут, в частности, номера паспортов, СНИЛС, ИНН, полиса ОМС, карты «Тройка», сведения о фактическом месте жительства, родственниках, транспорте и месте работы
https://mdza.io/sTpZgV9qS3k
Среди данных будут, в частности, номера паспортов, СНИЛС, ИНН, полиса ОМС, карты «Тройка», сведения о фактическом месте жительства, родственниках, транспорте и месте работы
https://mdza.io/sTpZgV9qS3k
Meduza
Мэрия Москвы усилит сбор данных о горожанах. Теперь она хочет знать реальные доходы людей и оценки детей в школах
Департамент информационных технологий Москвы решил создать за 185 миллионов рублей подробную и персонализированную базу данных о каждом жителе города, пишет «Коммерсант».
Forwarded from Ivan Begtin (Ivan Begtin)
В догонку про геоданные и их доступность, Максим Дубинин из NextGIS поделился статистикой их проекта [1] облачного, не государственного, сервиса российского происхождения и международной аудиторией:
- 2.1 млн скачиваний клиента для QGIS, 0.7 за последний год
- 1800+ сервисов
- 1000 авторов сервисов из 50 стран.
Максим был одним из основателей ГИС Лаборатории [2], одного их первых сообществ по открытым геоданным в России. А NextGIS - это пример коммерческого проекта на открытых данных и с открытым кодом для общественной пользы.
Ссылки:
[1] https://www.facebook.com/maxim.dubinin/posts/10111830597349957
[2] https://gis-lab.info/
#opendata #tech #opensource
- 2.1 млн скачиваний клиента для QGIS, 0.7 за последний год
- 1800+ сервисов
- 1000 авторов сервисов из 50 стран.
Максим был одним из основателей ГИС Лаборатории [2], одного их первых сообществ по открытым геоданным в России. А NextGIS - это пример коммерческого проекта на открытых данных и с открытым кодом для общественной пользы.
Ссылки:
[1] https://www.facebook.com/maxim.dubinin/posts/10111830597349957
[2] https://gis-lab.info/
#opendata #tech #opensource
Facebook
Log in to Facebook
Log in to Facebook to start sharing and connecting with your friends, family and people you know.
#urbanreflections
И снова карательная функция Умного города Москвы в действии. Интересно, почему у московского правительства лучше всего получается та деятельность, которой даже в Стратегии нет? Это очень грустно, что власти забывают, что главная цель технологий Умного города - облегчать жизнь горожан, а не усложнять ее. Кажется, что лучше тогда совсем без технологий..
Какие выводы можно сделать из последних новостей кроме того, что мой друг и просто хороший человек, Камиль, получил 10 суток ни за что и что под горячую руку полиции может попасть каждый.
1. В очередной раз можно убедиться, что алгоритм идентификации личности с видеоизображений у правительства Москвы настроен хорошо, даже отлично. В огромной толпе с высокой вероятностью идентифицировать человека среднего роста и не особо выделяющейся внешности ни так-то просто.
2. Очевидно, для заданного массива ФИО ( в данном случае это лица идентифицированные на видео с камер) существует возможность автоматической сцепки не только с базой данных паспортов, как минимум прописанных в Москве, но и с информацией из поисковика и соц.сетей. Иначе сложно поверить, что полиция вручную забивает в поисковик 20 тыс человек.
3.Далее, по всей видимости, в столичной полиции используют алгоритмы анализа текста, которые определяют окраску сообщений и выделяют ключевые слова ( иначе как понять к кому из 20000 человек "идти в гости"). И они явно нуждаются в доработке, потому что только машина в текстах Камиля ( он автор канала Высокая порта - @sublimeporte) может увидеть угрозу, выделив такие ключевые слова как "война", "бунт", "низвержение правительства" и т.д. - человек же сразу поймет, что речь идет об исторических событиях 16-17 веков, так как Камиль -историк, а не политик).
4. В который раз можно говорить о нарушении закона о персональных данных, потому что цели, для которых камеры ставились не совпадают с целями, для которых их фактически используют. Автоматическое сопоставление с базой преступников + их идентификация и распознавание каждого жителя Москвы - очень разные вещи...
И снова карательная функция Умного города Москвы в действии. Интересно, почему у московского правительства лучше всего получается та деятельность, которой даже в Стратегии нет? Это очень грустно, что власти забывают, что главная цель технологий Умного города - облегчать жизнь горожан, а не усложнять ее. Кажется, что лучше тогда совсем без технологий..
Какие выводы можно сделать из последних новостей кроме того, что мой друг и просто хороший человек, Камиль, получил 10 суток ни за что и что под горячую руку полиции может попасть каждый.
1. В очередной раз можно убедиться, что алгоритм идентификации личности с видеоизображений у правительства Москвы настроен хорошо, даже отлично. В огромной толпе с высокой вероятностью идентифицировать человека среднего роста и не особо выделяющейся внешности ни так-то просто.
2. Очевидно, для заданного массива ФИО ( в данном случае это лица идентифицированные на видео с камер) существует возможность автоматической сцепки не только с базой данных паспортов, как минимум прописанных в Москве, но и с информацией из поисковика и соц.сетей. Иначе сложно поверить, что полиция вручную забивает в поисковик 20 тыс человек.
3.Далее, по всей видимости, в столичной полиции используют алгоритмы анализа текста, которые определяют окраску сообщений и выделяют ключевые слова ( иначе как понять к кому из 20000 человек "идти в гости"). И они явно нуждаются в доработке, потому что только машина в текстах Камиля ( он автор канала Высокая порта - @sublimeporte) может увидеть угрозу, выделив такие ключевые слова как "война", "бунт", "низвержение правительства" и т.д. - человек же сразу поймет, что речь идет об исторических событиях 16-17 веков, так как Камиль -историк, а не политик).
4. В который раз можно говорить о нарушении закона о персональных данных, потому что цели, для которых камеры ставились не совпадают с целями, для которых их фактически используют. Автоматическое сопоставление с базой преступников + их идентификация и распознавание каждого жителя Москвы - очень разные вещи...
#spatialmodels
На днях увидела интересную работу(https://ieeexplore.ieee.org/document/8406847), где довольно простым способом авторы автоматически выделяли функциональные зоны в городе. Имея под рукой данные по инфраструктуре Москвы с data,mos.ru захотела повторить подобный эксперимент.
Алгоритм следующий:
1. Выгружаются списки POIs для каждой локации, все слова нормализуются и удаляются "стоп-слова". На первый раз взяла только данные магазинов .
2. Вычисляется матрица tf-idf (https://ru.wikipedia.org/wiki/TF-IDF). Пример на python здесь
3. С помощью алгоритма кластеризации ( для пробы взяла k-means) локации делятся на кластеры
4. Для каждого кластера составляются облака слов, показывающие самые частые словосочетания
5. Кластеры отображают на карте разными цветами
.Заранее скажу, что это пробная попытка, цель которой - увидеть насколько хорошо можно выделять зоны в Москве ( в пределах МКАД), не погружаясь в детальный анализ и обработку "грязных" данных.
Хотя, безусловно, это может быть первым шагом в задачах не соответствия инфраструктуры потребностям жителей, например, в обнаружении, так называемых, "food deserts" - мест без продуктовых магазинов в шаговой доступности. Также для бизнеса - это быстрый способ оценить уровень конкуренции в определенном районе.
Результаты анализа:
- Карта с кластерами сформированными на основе наименований магазинов. Единица оценки - гексагон системы H3 радиусом 174 метра.
- Облака слов, позволяющие понять специфику каждого кластера из магазинов- показывают 100 самых частых слов в списке POIs.
Выводы:
1. Территория делится на 4 кластера - это оптимальное число, определенное "методом локтя"
2. Порядка 8% территории ( кластер №1) не покрыты никакими магазинами. Большая часть это парковые зоны, однако есть и жилые районы.
3. Центр города и, похоже, торговые центры- ( кластер №0) зона высокого разнообразия магазинов. Нет одного ярко выделенного сегмента
4. 50% территории приходится на жилые районы. Из них на 32% ( кластер №2) преобладают продуктовые магазины, и на остальных 20% ( кластер №3) магазины одежды. Причем кластер 2 распределен равномерно, то участки, относящиеся к кластеру №3 представляют собой островки.
Потенциальное улучшение : добавление данных о других POIs, использование других типов кластеризации, например, иерархической, разделение центральных зон и жилых за счет добавления координат и флага центральности района в модель кластеризации.
Я пока не стала добавлять новые данные по инфраструктуре, но мне стало интересно наложить получившиеся кластеры на кластеры, построенные на интересах людей в городе, рассчитанных компанией Locomizer. Что получилось - следующий пост + с меня ссылка на Github с кодом проекта
На днях увидела интересную работу(https://ieeexplore.ieee.org/document/8406847), где довольно простым способом авторы автоматически выделяли функциональные зоны в городе. Имея под рукой данные по инфраструктуре Москвы с data,mos.ru захотела повторить подобный эксперимент.
Алгоритм следующий:
1. Выгружаются списки POIs для каждой локации, все слова нормализуются и удаляются "стоп-слова". На первый раз взяла только данные магазинов .
2. Вычисляется матрица tf-idf (https://ru.wikipedia.org/wiki/TF-IDF). Пример на python здесь
3. С помощью алгоритма кластеризации ( для пробы взяла k-means) локации делятся на кластеры
4. Для каждого кластера составляются облака слов, показывающие самые частые словосочетания
5. Кластеры отображают на карте разными цветами
.Заранее скажу, что это пробная попытка, цель которой - увидеть насколько хорошо можно выделять зоны в Москве ( в пределах МКАД), не погружаясь в детальный анализ и обработку "грязных" данных.
Хотя, безусловно, это может быть первым шагом в задачах не соответствия инфраструктуры потребностям жителей, например, в обнаружении, так называемых, "food deserts" - мест без продуктовых магазинов в шаговой доступности. Также для бизнеса - это быстрый способ оценить уровень конкуренции в определенном районе.
Результаты анализа:
- Карта с кластерами сформированными на основе наименований магазинов. Единица оценки - гексагон системы H3 радиусом 174 метра.
- Облака слов, позволяющие понять специфику каждого кластера из магазинов- показывают 100 самых частых слов в списке POIs.
Выводы:
1. Территория делится на 4 кластера - это оптимальное число, определенное "методом локтя"
2. Порядка 8% территории ( кластер №1) не покрыты никакими магазинами. Большая часть это парковые зоны, однако есть и жилые районы.
3. Центр города и, похоже, торговые центры- ( кластер №0) зона высокого разнообразия магазинов. Нет одного ярко выделенного сегмента
4. 50% территории приходится на жилые районы. Из них на 32% ( кластер №2) преобладают продуктовые магазины, и на остальных 20% ( кластер №3) магазины одежды. Причем кластер 2 распределен равномерно, то участки, относящиеся к кластеру №3 представляют собой островки.
Потенциальное улучшение : добавление данных о других POIs, использование других типов кластеризации, например, иерархической, разделение центральных зон и жилых за счет добавления координат и флага центральности района в модель кластеризации.
Я пока не стала добавлять новые данные по инфраструктуре, но мне стало интересно наложить получившиеся кластеры на кластеры, построенные на интересах людей в городе, рассчитанных компанией Locomizer. Что получилось - следующий пост + с меня ссылка на Github с кодом проекта
Для тех, кто интересуется data science и анализом данных рекомендую подписаться следующие каналы, авторы - мои коллеги из Сбербанка, люди, знающие про большие данные не понаслышке) :
@start_ds Роман (@RAVasiliev) делится полезными материалами для подготовки к собеседованиям в ДС
@dataviznews Никита (@nikitarokotyan) рассказывает о визуализации данных
@botka_chronics Алексей (@shpacman) о математике в ДС
@moir_x Мария ( @izomeraz4 ) дата инжениринг , математика , ДС
@data_events Николай (@NikolayKrupiy) держит в курсе ДС (и других data-тематических) событий в Москве и онлайне
@sv9t_channel Святослав ( @IggiSv9t) : лучший канал в тг по ДС, графам , визуализациям
Места общего сбора : @sberloga и @sberlogajobs
@start_ds Роман (@RAVasiliev) делится полезными материалами для подготовки к собеседованиям в ДС
@dataviznews Никита (@nikitarokotyan) рассказывает о визуализации данных
@botka_chronics Алексей (@shpacman) о математике в ДС
@moir_x Мария ( @izomeraz4 ) дата инжениринг , математика , ДС
@data_events Николай (@NikolayKrupiy) держит в курсе ДС (и других data-тематических) событий в Москве и онлайне
@sv9t_channel Святослав ( @IggiSv9t) : лучший канал в тг по ДС, графам , визуализациям
Места общего сбора : @sberloga и @sberlogajobs
Для тех, кто хотел бы освоить ГИС — в рамках Дистанционной программы Высшей школы урбанистики им. А.А.Высоковского пройдёт онлайн-курс «Геоинформационные методы анализа городских данных». Егор Котов приглашает на онлайн-презентацию курса 11 февраля в онлайне:
https://urban.hse.ru/announcements/440588837.html
https://urban.hse.ru/announcements/440588837.html
urban.hse.ru
Презентация ДПО «Геоинформационные методы анализа городских данных»
Forwarded from Канал Алексея Радченко
Сегодня еще один проект нашего студента - Артема Панкина
Он подготовил карты, где мы изучали плотность жилья и насколько плотность влияет на пасспоток. Основная гипотеза заключалась в поиске мест, где число пассажиров на остановке значительно превосходит число жителей вокруг. А значит требуется дополнительный анализ и усиление работы транспорта. Часто такие полигоны лежат рядом с метро или другими точками притяжения, но чаще есть другой источник спроса, про который перевозчик и комитеты по транспорту не знают.
Отношение числа пассажиров к числу жителей:
https://studio.unfolded.ai/public/daae3cad-087a-425e-a752-ad4950ed0782
Плотность населения:
https://studio.unfolded.ai/public/6f13c7b1-4a20-4adf-aea5-12fa4b241a9f
Питер в целом очень интересный для геоанализа: большое число открытых данных и масштаб города с одной стороны, огромные проблемы и потенциал развития наземного транспорта с другой. Даже невооруженным взглядом видны огромные районы высокой плотности, вообще не покрытые автобусами. Странно.
Он подготовил карты, где мы изучали плотность жилья и насколько плотность влияет на пасспоток. Основная гипотеза заключалась в поиске мест, где число пассажиров на остановке значительно превосходит число жителей вокруг. А значит требуется дополнительный анализ и усиление работы транспорта. Часто такие полигоны лежат рядом с метро или другими точками притяжения, но чаще есть другой источник спроса, про который перевозчик и комитеты по транспорту не знают.
Отношение числа пассажиров к числу жителей:
https://studio.unfolded.ai/public/daae3cad-087a-425e-a752-ad4950ed0782
Плотность населения:
https://studio.unfolded.ai/public/6f13c7b1-4a20-4adf-aea5-12fa4b241a9f
Питер в целом очень интересный для геоанализа: большое число открытых данных и масштаб города с одной стороны, огромные проблемы и потенциал развития наземного транспорта с другой. Даже невооруженным взглядом видны огромные районы высокой плотности, вообще не покрытые автобусами. Странно.