
В рубрике интересных продуктов для работы с данными:
- MissionKontrol [1] админская панель для управления данными в базах данных MySQL и Postgres․ Создаёт NoCode интерфейс поверх таблиц и распространяется с открытым кодом
- Query.me [2] построитель запросов к СУБД с элементами коллаборации и в стиле а-ля Notebook. Облачный и платный
- Atlas [3] утилита командной строки для описания схем баз данных и организации их миграции. Написана на Go, с открытым кодом, поддерживает основные open-source СУБД, не поддерживает NoSQL. Хорошо документирована
- Sandman2 [4] автоматический генератор API на основе SQL СУБД
- Dragonfly [5] более производительная замена Redis. С открытым кодом
Ссылки:
[1] https://www.missionkontrol.io
[2] https://query.me/
[3] https://atlasgo.io/
[4] https://github.com/jeffknupp/sandman2
[5] https://github.com/dragonflydb/dragonfly
#opensource #datatools
- MissionKontrol [1] админская панель для управления данными в базах данных MySQL и Postgres․ Создаёт NoCode интерфейс поверх таблиц и распространяется с открытым кодом
- Query.me [2] построитель запросов к СУБД с элементами коллаборации и в стиле а-ля Notebook. Облачный и платный
- Atlas [3] утилита командной строки для описания схем баз данных и организации их миграции. Написана на Go, с открытым кодом, поддерживает основные open-source СУБД, не поддерживает NoSQL. Хорошо документирована
- Sandman2 [4] автоматический генератор API на основе SQL СУБД
- Dragonfly [5] более производительная замена Redis. С открытым кодом
Ссылки:
[1] https://www.missionkontrol.io
[2] https://query.me/
[3] https://atlasgo.io/
[4] https://github.com/jeffknupp/sandman2
[5] https://github.com/dragonflydb/dragonfly
#opensource #datatools
MissionKontrol
MissionKontrol - A Modern Admin Panel For Successful Teams
Build a fully self-hosted admin panel to manage your app's data in minutes that your team will love. Language agnostic. No coding required.
О противодействии коррупции с помощью открытых данных. У Open Data Charter не так давно появился интерактивный инструмент подготовки программ противодействия коррупции [1] через публикацию данных.
К России он малоприменим в ближайшей исторической перспективе, поскольку содержит отсылки к проектам финансируемым "нежелательными организациями" и к Open Government Partnership.
Но стоит обратить внимание что противодействие коррупции в мире сейчас - это доступность машиночитаемых данных о контрактах, имуществе, декларациях, бюджетах, добывающих отраслях и ещё много что.
Ссылки:
[1] https://fightcorruption.opendatacharter.net/
#opendata #opengov
К России он малоприменим в ближайшей исторической перспективе, поскольку содержит отсылки к проектам финансируемым "нежелательными организациями" и к Open Government Partnership.
Но стоит обратить внимание что противодействие коррупции в мире сейчас - это доступность машиночитаемых данных о контрактах, имуществе, декларациях, бюджетах, добывающих отраслях и ещё много что.
Ссылки:
[1] https://fightcorruption.opendatacharter.net/
#opendata #opengov
fightcorruption.opendatacharter.net
Open Data Anti Corruption
Anticorruption Open Data
В качестве регулярного напоминания кто я, зачем и о чём пишу, особенно для недавно подписавшихся.
Я возглавляю АНО "Инфокультура" (@infoculture), создаю общественные проекты и продукты на открытых данных и для их популяризации такие как Национальный цифровой архив (@ruarxive), а также развиваю коммерческие продукты на данных такие как APICrafter и DataCrafter и возглавляю небольшую ИТ компанию для создания дата-продуктов подобных этим. До этого 2 года я вел проект Госрасходы (spending.gov.ru) в Счетной палате РФ, а сейчас его ведёт моя коллега Ольга, канал @ahminfin.
Я пишу заметки в блоге на английском на Medium, на них также можно подписаться. Также веду рассылку на Substack на русском языке и реже пишу в свой блог на личном сайте begtin.tech.
Кроме всего прочего я регулярно читаю лекции госслужащим, общественным организациям, в просветительском или образовательном формате. Сейчас реже поскольку всё более концентрируюсь на разработке ИТ продуктов, но как минимум 5-6 лекций в год, до пандемии было до 20.
Этот телеграм канал @begtin я создавал, в первую очередь, как записную книжку, для личных публичных заметок. Читаю что-то, думаю о чём и рассуждаю вслух здесь. Реже я здесь же публикую какую-либо аналитику связанную с одним из наших проектов или моими хобби.
Поэтому подписываясь будьте готовы что здесь будет много публикаций про данные, инструменты работы с ними, госполитику в этой области, цифровую архивацию и тому подобное
#channel #topics #overview
Я возглавляю АНО "Инфокультура" (@infoculture), создаю общественные проекты и продукты на открытых данных и для их популяризации такие как Национальный цифровой архив (@ruarxive), а также развиваю коммерческие продукты на данных такие как APICrafter и DataCrafter и возглавляю небольшую ИТ компанию для создания дата-продуктов подобных этим. До этого 2 года я вел проект Госрасходы (spending.gov.ru) в Счетной палате РФ, а сейчас его ведёт моя коллега Ольга, канал @ahminfin.
Я пишу заметки в блоге на английском на Medium, на них также можно подписаться. Также веду рассылку на Substack на русском языке и реже пишу в свой блог на личном сайте begtin.tech.
Кроме всего прочего я регулярно читаю лекции госслужащим, общественным организациям, в просветительском или образовательном формате. Сейчас реже поскольку всё более концентрируюсь на разработке ИТ продуктов, но как минимум 5-6 лекций в год, до пандемии было до 20.
Этот телеграм канал @begtin я создавал, в первую очередь, как записную книжку, для личных публичных заметок. Читаю что-то, думаю о чём и рассуждаю вслух здесь. Реже я здесь же публикую какую-либо аналитику связанную с одним из наших проектов или моими хобби.
Поэтому подписываясь будьте готовы что здесь будет много публикаций про данные, инструменты работы с ними, госполитику в этой области, цифровую архивацию и тому подобное
#channel #topics #overview
АНО "Информационная культура"
Проекты
Свежий апдейт по проекту metacrafter.
Обновился реестр семантических типов данных metacrafter-registry [1], теперь там появился раздел инструментов [2] со списком, пока, из 9 инструментов и того какие семантические типы данных они поддерживают.
Список неполный потому что есть инструменты вроде Microsoft Presidio [3] которые по факту поддерживают ещё и многие типы данных которые пока в этот реестр не входят, но их систематизация хотя бы начата. Каждый инструмент описывается в виде yaml файла с описанием, например, yaml файл metacrafter'а.
Сейчас metacrafter с базовыми правилами распознает 48 семантических типов данных [4], а как веб сервис поддерживает 118 семантических типов [5].
На самом деле, конечно, если говорить про ширину охвата, то можно упростить распознавание сведя все численные типы к одному семантическому типу. Например, так сделано в Google Data Studio, а можно наоборот усложинить добавив множество градаций и подтипов. Как это сделано в Metabase где есть отдельные типы данных "Creation Date", "Updated Date" и тд.
Ссылки:
[1] https://registry.apicrafter.io/
[2] https://registry.apicrafter.io/tool
[3] https://registry.apicrafter.io/tool/presidio
[4] https://github.com/apicrafter/metacrafter-registry/blob/main/data/tools/detectors/metacrafter.yaml
[5] https://github.com/apicrafter/metacrafter-registry/tree/main/data/tools
[4] https://registry.apicrafter.io/tool/metacrafter
[5] https://registry.apicrafter.io/tool/metacrafterpro
#opensource #datatools #apicrafter #metadata #pii
Обновился реестр семантических типов данных metacrafter-registry [1], теперь там появился раздел инструментов [2] со списком, пока, из 9 инструментов и того какие семантические типы данных они поддерживают.
Список неполный потому что есть инструменты вроде Microsoft Presidio [3] которые по факту поддерживают ещё и многие типы данных которые пока в этот реестр не входят, но их систематизация хотя бы начата. Каждый инструмент описывается в виде yaml файла с описанием, например, yaml файл metacrafter'а.
Сейчас metacrafter с базовыми правилами распознает 48 семантических типов данных [4], а как веб сервис поддерживает 118 семантических типов [5].
На самом деле, конечно, если говорить про ширину охвата, то можно упростить распознавание сведя все численные типы к одному семантическому типу. Например, так сделано в Google Data Studio, а можно наоборот усложинить добавив множество градаций и подтипов. Как это сделано в Metabase где есть отдельные типы данных "Creation Date", "Updated Date" и тд.
Ссылки:
[1] https://registry.apicrafter.io/
[2] https://registry.apicrafter.io/tool
[3] https://registry.apicrafter.io/tool/presidio
[4] https://github.com/apicrafter/metacrafter-registry/blob/main/data/tools/detectors/metacrafter.yaml
[5] https://github.com/apicrafter/metacrafter-registry/tree/main/data/tools
[4] https://registry.apicrafter.io/tool/metacrafter
[5] https://registry.apicrafter.io/tool/metacrafterpro
#opensource #datatools #apicrafter #metadata #pii
GitHub
metacrafter-registry/metacrafter.yaml at main · apicrafter/metacrafter-registry
Registry of metadata identifier entities like UUID, GUID, person fullname, address and so on. Linked with other sources - metacrafter-registry/metacrafter.yaml at main · apicrafter/metacrafter-regi...
Forwarded from Малоизвестное интересное
Скатывание вниз по эскалатору, идущему вверх.
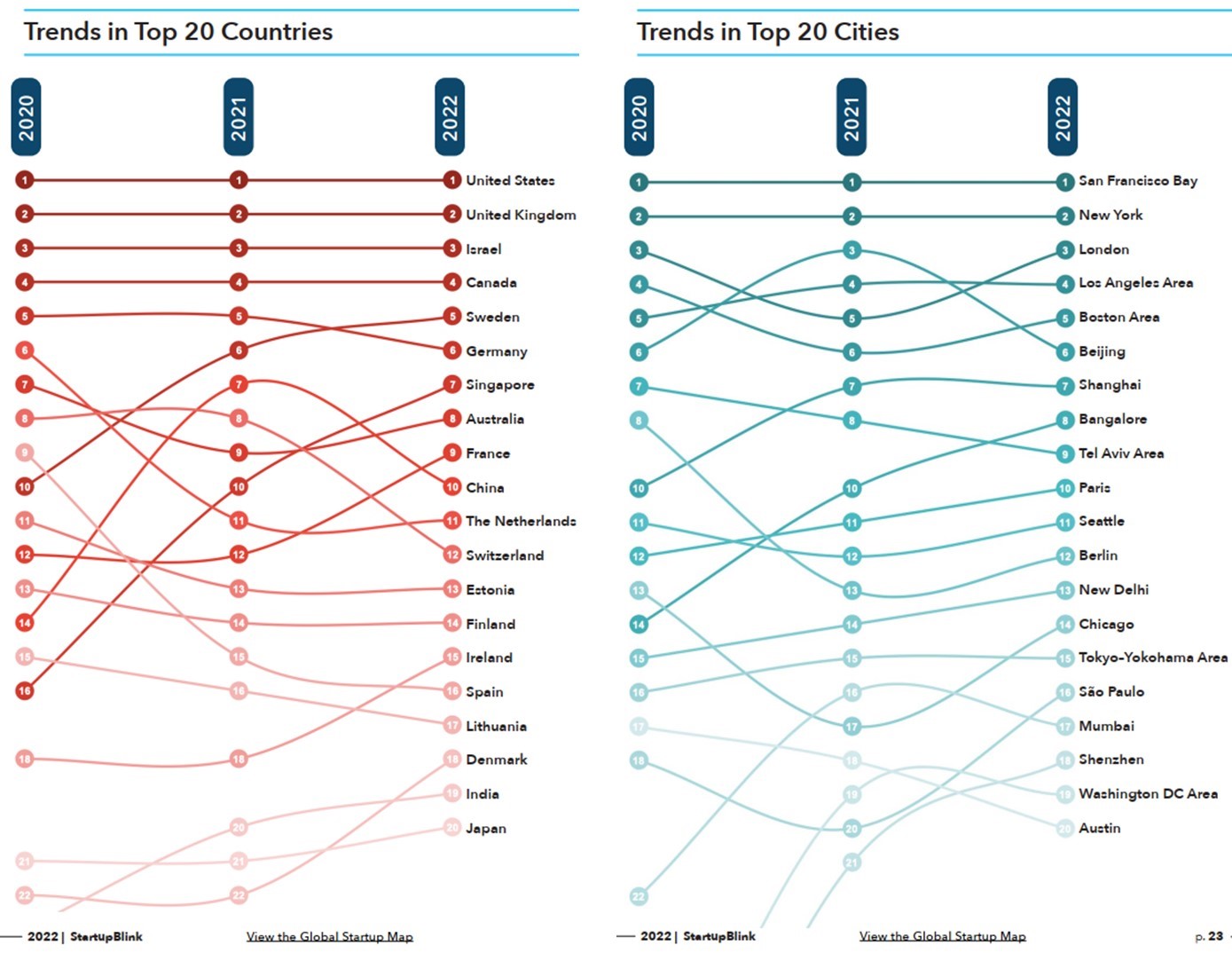
Падение позиций России в глобальной экосистеме стартапов.
Динамика состояния экосистемы стартапов – один из лучших показателей технологического будущего страны.
И если хотите уже сегодня понять, каким может стать это будущее, не пропустите новый 400 страничный отчет о состоянии глобальной экосистемы стартапов в 2022 году.
Отчет содержит рейтинги (интегральные и покомпонентные) ста лучших стран-экосистем и тысячи лучших городов-хабов, обзоры по регионам и индустриям с анализом текущего состояния и динамики за последние годы.
Смотреть на показатели России жутко и больно. А ведь еще год назад все было, хоть и не великолепно, но вполне прилично.
Теперь же, в сравнении с 2021, стремительное падение всех индексов:
• - 12 позиций по интегральному индексу
• -20 позиций у Москвы по индексу городов-хабов
• - 38 позиций у Санкт-Петербурга
• у остальных городов-хабов просто кошмар: -127 позиций у Казани, -177 у Томска, -189 у Новосибирска и т.д.
У Украины, по понятным причинам, ситуация еще хуже (-16 по интегральному, -45 у Киева, -348 у Одессы).
А мир едет себе дальше.
Группа лучших цветет и пахнет (ТОР 20 стран и городов см. на приложенных диаграммах.
• Лидеры (США, Великобритания, Израиль, Сан-Франциско, Нью-Йорк) держат позиции, как вкопанные.
• Китай и Пекин болтает, но Шанхай уже круче Бангалора
Группа преследователей рвётся вперед (Ангола +18, Исландия +14, Норвегия и Индонезия +7, Австрия +5).
Отчет здесь: https://www.startupblink.com/
#Стартапы
Падение позиций России в глобальной экосистеме стартапов.
Динамика состояния экосистемы стартапов – один из лучших показателей технологического будущего страны.
И если хотите уже сегодня понять, каким может стать это будущее, не пропустите новый 400 страничный отчет о состоянии глобальной экосистемы стартапов в 2022 году.
Отчет содержит рейтинги (интегральные и покомпонентные) ста лучших стран-экосистем и тысячи лучших городов-хабов, обзоры по регионам и индустриям с анализом текущего состояния и динамики за последние годы.
Смотреть на показатели России жутко и больно. А ведь еще год назад все было, хоть и не великолепно, но вполне прилично.
Теперь же, в сравнении с 2021, стремительное падение всех индексов:
• - 12 позиций по интегральному индексу
• -20 позиций у Москвы по индексу городов-хабов
• - 38 позиций у Санкт-Петербурга
• у остальных городов-хабов просто кошмар: -127 позиций у Казани, -177 у Томска, -189 у Новосибирска и т.д.
У Украины, по понятным причинам, ситуация еще хуже (-16 по интегральному, -45 у Киева, -348 у Одессы).
А мир едет себе дальше.
Группа лучших цветет и пахнет (ТОР 20 стран и городов см. на приложенных диаграммах.
• Лидеры (США, Великобритания, Израиль, Сан-Франциско, Нью-Йорк) держат позиции, как вкопанные.
• Китай и Пекин болтает, но Шанхай уже круче Бангалора
Группа преследователей рвётся вперед (Ангола +18, Исландия +14, Норвегия и Индонезия +7, Австрия +5).
Отчет здесь: https://www.startupblink.com/
#Стартапы
{kind=link}
В рубрике полезных инструментов по работе с данными сервис My MLOps Stack [1] позволяет собрать собственный стек технологий для Machine Learning выбрав инструменты под определенные задачи. К инструментам есть пояснения, их категоризация и целевое назначение. Также сильный акцент на open-source инструменты, без упоминания больших платформ. Но как один из инструментов моделирования технологического стека весьма полезный инструмент.
Ссылки:
[1] https://mymlops.com/
#datatools #moderndatastack #mlops
Ссылки:
[1] https://mymlops.com/
#datatools #moderndatastack #mlops
UPDATE: О том же в англоязычной заметке в блоге на Medium
К вопросу о рынке инструментов работы с данными, могу сказать что за вот уже долгое наблюдение за тем как они развиваются, всё ещё явным образом есть дефицит инструментов 3-х типов с пересекающимися категориями
- data wrangling
- data quality (observation)
- data enrichment
Data wrangling
Это одна из многими нелюбимых, но актуальных тем, по очистке и подготовке данных. Особенность в что делают это обычно, или с командной строки, или в СУБД, а из удобных интерактивных инструментов только и есть открытый и бесплатный OpenRefine [1] или очень дорогие инструменты вроде Trifacta [2].
У OpenRefine очень серьёзные ограничения по объёму данных, но он весьма популярен в дата-журналистике и дата-аналитике (не дата-инженерии).
Так вот таких инструментов дефицит, бесплатных и коммерческих за небольшие-средние понятные деньги. А самое главное с меньшими ограничениями чем у OpenRefine. По моим ощущениям что если такой инструмент построить на современной колоночной или быстрой in-memory базе данных, вроде Tarantool или Clickhouse или одного из похожих движков, то можно создать очень востребованный продукт. Только надо вложить немало усилий в пользовательский интерфейс.
О дефиците инструментов по качеству и обогащению данных я ещё напишу в следующих постах.
Ссылки:
[1] https://openrefine.org
[2] https://www.trifacta.com
#datatools #datawrangling
К вопросу о рынке инструментов работы с данными, могу сказать что за вот уже долгое наблюдение за тем как они развиваются, всё ещё явным образом есть дефицит инструментов 3-х типов с пересекающимися категориями
- data wrangling
- data quality (observation)
- data enrichment
Data wrangling
Это одна из многими нелюбимых, но актуальных тем, по очистке и подготовке данных. Особенность в что делают это обычно, или с командной строки, или в СУБД, а из удобных интерактивных инструментов только и есть открытый и бесплатный OpenRefine [1] или очень дорогие инструменты вроде Trifacta [2].
У OpenRefine очень серьёзные ограничения по объёму данных, но он весьма популярен в дата-журналистике и дата-аналитике (не дата-инженерии).
Так вот таких инструментов дефицит, бесплатных и коммерческих за небольшие-средние понятные деньги. А самое главное с меньшими ограничениями чем у OpenRefine. По моим ощущениям что если такой инструмент построить на современной колоночной или быстрой in-memory базе данных, вроде Tarantool или Clickhouse или одного из похожих движков, то можно создать очень востребованный продукт. Только надо вложить немало усилий в пользовательский интерфейс.
О дефиците инструментов по качеству и обогащению данных я ещё напишу в следующих постах.
Ссылки:
[1] https://openrefine.org
[2] https://www.trifacta.com
#datatools #datawrangling
Тут российское пр-во пишет в телеграм канале [1] про сервис ФАС России по подаче жалоб на СМС рекламу [2] где обещают блокировать рекламу за 72 часа после обращения.
Я прочитав это долго думал как написать про это без матерных слов, отсылки к разного рода сексуальным девиациям и возрастным болезнями вызванные последствиями ковида. И видите, не написал и сдержался!
Так вот, в мире есть большая отрасль мобильных приложений которые помогают блокировать спамеров. Они есть у Яндекса, Касперского, есть приложения вроде Труколлера и Намбастера и десятков других которые помогают блокировать спамеров автоматически или очень автоматизировано. И мгновенно! Ими пользуются, несмотря на огромную брешь в приватности, именно потому что спамеры всех порядком достали, а официальная борьба с ними - это для очень особых людей любящих российскую бюрократию. Их немного, таких людей.
Может ли государство использовать современные методы? Да, может. И даже не нарушая приватность пользователей самостоятельно, а договорившись или отрегулировав отрасль блокировки спам звонков об автоматической передаче сведений в ФАС России, пусть пользователь сам отмечает галочкой когда он на такое согласен и хочет сделать спамерам больно. И автоматизацией расследований на основе собираемых больших данных.
Сложно ли это? Нет, это не грёбанная магия. Это очень простая регуляторная модель концепцию которой можно написать за один день, а реализовать за месяц. Есть ли другие эффективные методы? Да, есть, только работать придётся.
Так, внимание вопрос, почему этого не происходит?
Может быть потому что хвалёная цифровая трансформация в наших госорганах давно провалена, а пр-во в этом боится открыто признаться и через такие публикации нам как-бы издалека на это намекает?
Ребята, намёк понят 😉, полностью согласен, цифровая трансформация ФАС провалилась. Спасибо что в очередной раз об этом напомнили.
Ссылки:
[1] https://yangx.top/government_rus/3419
[2] https://fas.gov.ru/pages/zhaloby-sms
#russia #regulation #spammers #fas #admarket
Я прочитав это долго думал как написать про это без матерных слов, отсылки к разного рода сексуальным девиациям и возрастным болезнями вызванные последствиями ковида. И видите, не написал и сдержался!
Так вот, в мире есть большая отрасль мобильных приложений которые помогают блокировать спамеров. Они есть у Яндекса, Касперского, есть приложения вроде Труколлера и Намбастера и десятков других которые помогают блокировать спамеров автоматически или очень автоматизировано. И мгновенно! Ими пользуются, несмотря на огромную брешь в приватности, именно потому что спамеры всех порядком достали, а официальная борьба с ними - это для очень особых людей любящих российскую бюрократию. Их немного, таких людей.
Может ли государство использовать современные методы? Да, может. И даже не нарушая приватность пользователей самостоятельно, а договорившись или отрегулировав отрасль блокировки спам звонков об автоматической передаче сведений в ФАС России, пусть пользователь сам отмечает галочкой когда он на такое согласен и хочет сделать спамерам больно. И автоматизацией расследований на основе собираемых больших данных.
Сложно ли это? Нет, это не грёбанная магия. Это очень простая регуляторная модель концепцию которой можно написать за один день, а реализовать за месяц. Есть ли другие эффективные методы? Да, есть, только работать придётся.
Так, внимание вопрос, почему этого не происходит?
Может быть потому что хвалёная цифровая трансформация в наших госорганах давно провалена, а пр-во в этом боится открыто признаться и через такие публикации нам как-бы издалека на это намекает?
Ребята, намёк понят 😉, полностью согласен, цифровая трансформация ФАС провалилась. Спасибо что в очередной раз об этом напомнили.
Ссылки:
[1] https://yangx.top/government_rus/3419
[2] https://fas.gov.ru/pages/zhaloby-sms
#russia #regulation #spammers #fas #admarket
Telegram
Правительство России
📲Как пожаловаться на спам-рекламу?
ФАС и операторы связи разработали сервис для подачи жалобы на спам-рекламу. Он поможет оперативно блокировать нежелательную рекламу, которая поступает без согласия на ее получение.
💻Заполнить анкету можно на сайте ФАС.…
ФАС и операторы связи разработали сервис для подачи жалобы на спам-рекламу. Он поможет оперативно блокировать нежелательную рекламу, которая поступает без согласия на ее получение.
💻Заполнить анкету можно на сайте ФАС.…
В качестве небольшого оффтопика, для тех кто не знает, я в свободное время иногда пишу едкие стихи на разные около гос и цифровые темы, в канале @ministryofpoems. Читателей у него немного, о том что я его веду также знают немногие, но вот он есть и его можно читать.
P.S. Конечно же, все совпадения там случайны, и, конечно же, все образы выдуманы.
P.S. Конечно же, все совпадения там случайны, и, конечно же, все образы выдуманы.
Forwarded from ministryofpoems
Государство развивает проект поддержки тюремно-приходских инновационных предприятий
И проводит для этого серию национальных мероприятий
Министерство развития тюремных акселераторов
Ищет новых менторов и кураторов
Направляйте ваши рекомендации
Через сайт Министерства внутренней дискриминации
В разделе "Клевета, доносы и ренегаты"
Расскажите какие они кандидаты
Обеспечим им гарантированное трудоустройство
Полезное в нашем мироустройстве
За хорошую рекомендацию положена награда
И такая что каждому её надо!
Много баллов в государственном приложении лояльности
Будут полезны Вам до крайности
Можно ими закрыть месяц отсидки
Или получить какие-нибудь скидки
И проводит для этого серию национальных мероприятий
Министерство развития тюремных акселераторов
Ищет новых менторов и кураторов
Направляйте ваши рекомендации
Через сайт Министерства внутренней дискриминации
В разделе "Клевета, доносы и ренегаты"
Расскажите какие они кандидаты
Обеспечим им гарантированное трудоустройство
Полезное в нашем мироустройстве
За хорошую рекомендацию положена награда
И такая что каждому её надо!
Много баллов в государственном приложении лояльности
Будут полезны Вам до крайности
Можно ими закрыть месяц отсидки
Или получить какие-нибудь скидки
В рубрике интересных продуктов на данных, Directus [1]. Ещё пару лет продвинутая безголовая CMS (headless CMS) конкурирующая с GraphCMS, Strapi и тому подобными CMS решениями и продуктами.
Сейчас позиционируют себя как modern data platform, продукт по превращению SQL баз данных в API и No-code app. Смена бизнес модели довольно существенная, не берусь предсказать насколько новый рынок будет больше, но само изменения существенное.
Как я понимаю произошло оно после того как они привлекли первые венчурные деньги в $1M в июле 2021 г.
Ссылки:
[1] https://directus.io/
#data #dataplatforms #startups
Сейчас позиционируют себя как modern data platform, продукт по превращению SQL баз данных в API и No-code app. Смена бизнес модели довольно существенная, не берусь предсказать насколько новый рынок будет больше, но само изменения существенное.
Как я понимаю произошло оно после того как они привлекли первые венчурные деньги в $1M в июле 2021 г.
Ссылки:
[1] https://directus.io/
#data #dataplatforms #startups
directus.io
The Headless CMS + Backend for Every Custom Build
Built for developers who need more than just a CMS. Manage complex content structures, handle digital assets, and control user permissions – all through an intuitive Studio.
В рубрике как это устроено у них, портал открытых данных Франции data.gouv.fr [1]
Включает более 40 тысяч наборов данных, в основном в форматах CSV, JSON и форматах геоданных GML, GeoJSON, Shape
Создан и поддерживается Etalab, подразделением их межминистерского управления по цифре. Работает на платформе udata [3] каталоге данных созданном специально под этот портал.
Важные особенности:
- большой раздел примеров использования данных [4] более 3000 примеров
- данные публикуют не только госорганы [5] но и предприятия и НКО
Ссылки:
[1] https://data.gouv.fr
[2] https://etalab.gouv.fr
[3] https://github.com/etalab/udata
[4] https://www.data.gouv.fr/fr/reuses/
[5] https://www.data.gouv.fr/fr/organizations/izivia/
#opendata #france #bestpractices
Включает более 40 тысяч наборов данных, в основном в форматах CSV, JSON и форматах геоданных GML, GeoJSON, Shape
Создан и поддерживается Etalab, подразделением их межминистерского управления по цифре. Работает на платформе udata [3] каталоге данных созданном специально под этот портал.
Важные особенности:
- большой раздел примеров использования данных [4] более 3000 примеров
- данные публикуют не только госорганы [5] но и предприятия и НКО
Ссылки:
[1] https://data.gouv.fr
[2] https://etalab.gouv.fr
[3] https://github.com/etalab/udata
[4] https://www.data.gouv.fr/fr/reuses/
[5] https://www.data.gouv.fr/fr/organizations/izivia/
#opendata #france #bestpractices
Варианты типов продуктов и новомодных понятий и подходов с ними связанных.
Таблица в черновом виде, но по ней можно увидеть типы продуктов: CMS, ETP, ETL/ELT, CRM, CDP и колонки Headless, Reverse, Serverless и Streaming.
Можно обратить внимание что:
- Headless ETL это скорее будет маркетинговым термином и так почти все ETL предполагают несколько вариантов работы и в жизни такое сочетание не используется, хотя и существует как явление
- reverse CMS, ERP и CDP пока не встречались
- Serverless популярно для всего кроме Serverless CDP, таких продуктов пока нет
- Streaming применимо к ETL/ELT, но не для других.
Каких типов продуктов и каких подходов нехватает на картинке?
#headless #serverless #reverse #streaming
Таблица в черновом виде, но по ней можно увидеть типы продуктов: CMS, ETP, ETL/ELT, CRM, CDP и колонки Headless, Reverse, Serverless и Streaming.
Можно обратить внимание что:
- Headless ETL это скорее будет маркетинговым термином и так почти все ETL предполагают несколько вариантов работы и в жизни такое сочетание не используется, хотя и существует как явление
- reverse CMS, ERP и CDP пока не встречались
- Serverless популярно для всего кроме Serverless CDP, таких продуктов пока нет
- Streaming применимо к ETL/ELT, но не для других.
Каких типов продуктов и каких подходов нехватает на картинке?
#headless #serverless #reverse #streaming
В рубрике интересных проектов на открытых данных, малоизвестная поисковая система по наборам данных Auctus [1] созданная в Visualization, Imaging, and Data Analysis lab (VIDA) Университета Нью Йорка
В отличие от Google Dataset Search (GDS) эта поисковая система выгружает данные, анализирует их состав, дает возможности расширенного поиска и дополнительно визуализирует данные на карте, таблицей и графиками. Охват меньше чем у GDS, зато подача результата качественно лучше.
У проекта открытый код и хорошая документация [2], а также авторы написали научную статью о его создании [3].
Лично я давно хочу сделать похожую штуку, может быть с меньшим акцентом на визуализацию и с большим на обнаружение данных. В том числе включив поиск по семантическим типам данных. А Auctus хороший пример того что такой проект возможен разумными силами.
Ссылки:
[1] https://auctus.vida-nyu.org
[2] https://gitlab.com/ViDA-NYU/auctus/auctus
[3] https://arxiv.org/abs/2102.05716
#opendata #data #datasearch
В отличие от Google Dataset Search (GDS) эта поисковая система выгружает данные, анализирует их состав, дает возможности расширенного поиска и дополнительно визуализирует данные на карте, таблицей и графиками. Охват меньше чем у GDS, зато подача результата качественно лучше.
У проекта открытый код и хорошая документация [2], а также авторы написали научную статью о его создании [3].
Лично я давно хочу сделать похожую штуку, может быть с меньшим акцентом на визуализацию и с большим на обнаружение данных. В том числе включив поиск по семантическим типам данных. А Auctus хороший пример того что такой проект возможен разумными силами.
Ссылки:
[1] https://auctus.vida-nyu.org
[2] https://gitlab.com/ViDA-NYU/auctus/auctus
[3] https://arxiv.org/abs/2102.05716
#opendata #data #datasearch
Это, конечно, плохая новость для остатков ИТ сектора в России. Яндекса одна из немногих полноценных больших технологических компаний в России и с глобальными амбициями.
Forwarded from РБК. Новости. Главное
⚡️Аркадий Волож покидает совет директоров и пост генерального директора группы компаний «Яндекс».
Это решение принято после того, как против него ввел санкции Евросоюз.
«Я считаю решение комиссии нелогичным. Однако пока действуют санкции, я не буду давать никаких указаний и рекомендаций трасту относительно голосования, решения продолжит принимать совет директоров. Это защитит интересы компании и всех наших акционеров. При этом я продолжу помогать компании и ее команде», — прокомментировал санкции и свой уход Аркадий Волож.
Это решение принято после того, как против него ввел санкции Евросоюз.
«Я считаю решение комиссии нелогичным. Однако пока действуют санкции, я не буду давать никаких указаний и рекомендаций трасту относительно голосования, решения продолжит принимать совет директоров. Это защитит интересы компании и всех наших акционеров. При этом я продолжу помогать компании и ее команде», — прокомментировал санкции и свой уход Аркадий Волож.
В рубрике интересных проектов на данных Data-Driven Discovery of Models (D3M) [1], большой проект DARPA, военного ведомства США финансирующего инновационные проекты.
Проект посвящён автоматизации data science и предсказанием применения моделей данных. А главная идея в улучшении понимания предметных областей для для исследователей данных.
Они упоминают там 3 платформы в этом направлении:
- Einblick [2] система совместного исследования данных и моделирования предсказаний на их основе
- TwoRavens [3] система для моделирования предметных областей через данные и моделирования данных в этих областях
- Distil [4] система для специалистов предметных областей исследовать данные в разных формах
Фактически D3M это экосистема внутри которой финансируются многие проекты. Например, Auctus, поисковик по данным о которым я недавно писал [5] и Datamart [6] проект по анализу наборов данных с сопоставлением их с Wikidata.
А также множество проектов по направлению AutoML, помогающим автоматизировать работу отраслевых экспертов и отделяющих машинное обучение от самих специалистов по машинному обучению. Через типовые модели, через создание базы примитивов для этих моделей и многое другое.
Там много очень разных интересных идей, причём в сторону технологически продвинутых nocode/low-code инструментов внутри которых могут быть сложные алгоритмы работы с данными. Фактически это путь по значительному усилению отраслевых аналитиков в областях экономики, геополитики, промышленности и тд и для того чтобы они самостоятельно могли бы работать с большими данными.
Ссылки:
[1] https://datadrivendiscovery.org/
[2] https://www.einblick.ai/
[3] http://2ra.vn/
[4] https://d3m.uncharted.software/
[5] https://yangx.top/begtin/3922
[6] https://datadrivendiscovery.org/augmentation/
#data #research #datascience #datadiscovery #ml
Проект посвящён автоматизации data science и предсказанием применения моделей данных. А главная идея в улучшении понимания предметных областей для для исследователей данных.
Они упоминают там 3 платформы в этом направлении:
- Einblick [2] система совместного исследования данных и моделирования предсказаний на их основе
- TwoRavens [3] система для моделирования предметных областей через данные и моделирования данных в этих областях
- Distil [4] система для специалистов предметных областей исследовать данные в разных формах
Фактически D3M это экосистема внутри которой финансируются многие проекты. Например, Auctus, поисковик по данным о которым я недавно писал [5] и Datamart [6] проект по анализу наборов данных с сопоставлением их с Wikidata.
А также множество проектов по направлению AutoML, помогающим автоматизировать работу отраслевых экспертов и отделяющих машинное обучение от самих специалистов по машинному обучению. Через типовые модели, через создание базы примитивов для этих моделей и многое другое.
Там много очень разных интересных идей, причём в сторону технологически продвинутых nocode/low-code инструментов внутри которых могут быть сложные алгоритмы работы с данными. Фактически это путь по значительному усилению отраслевых аналитиков в областях экономики, геополитики, промышленности и тд и для того чтобы они самостоятельно могли бы работать с большими данными.
Ссылки:
[1] https://datadrivendiscovery.org/
[2] https://www.einblick.ai/
[3] http://2ra.vn/
[4] https://d3m.uncharted.software/
[5] https://yangx.top/begtin/3922
[6] https://datadrivendiscovery.org/augmentation/
#data #research #datascience #datadiscovery #ml
На vc.ru статья [1] про инициативу конкретного человека по сбору списка сотрудников компании NTechLab и, по сути, применения к ним культуры отмены. Для тех кто не знает, NTechLab - это российская компания разработчик технологии распознавания по лицам. Технологии мирового уровня по многим измерениям, оценкам и практике применения.
Лично я, мягко говоря, против культуры отмены. Персонифицированные бойкоты слишком похожи на самосуд, даже при плохой правоохранительной системе, они, в основном, создают поддерживают атмосферу общего ожесточения.
Но сейчас хочу сказать не об этом. В технологических компаниях очень многие и слишком часто забывают про то что многие технологии имеют двойное назначение. В каких-то областях это давно знают, есть ограничения таких как Вассенаарских соглашения [2], иногда спорно применяемых к технологиям сильного шифрования, но тем не менее.
Так вот дело в том что во многих технологиях уже невозможно говорить о благих намерениях или говорить о непонимании того как Ваша технология будет применяться на практике. Разработчики безусловно отвечают за применение их технологии и должны уметь отвечать на вопросы:
1. Можно ли с помощью технологии нарушать права граждан?
2. Можно ли с помощью технологии усилить нарушение прав граждан?
3. Какие меры разработчик предпринимает чтобы снизить последствия такого применения?
и ещё многие другие.
Технологии распознавания лиц, силуэтов, походки, или технологии глубокого перехвата трафика и ещё многие безусловно относятся как таким технологиям двойного назначения.
И везде где возможно в мире внедрению таких технологий препятствуют общественные организации, политики, учёные и отдельные активисты.
Есть много примеров такого сопротивления. Сотрудники Гугл активно протестовали против разработки ПО для военных. Соцсети под давлением общественного мнения заблокировали ПО Geofeedia использовавшееся для мониторинга протестов полицейскими в США, а в отношении компании NetSweeper продающей ПО для фильтрации интернета было полномасштабное расследование [3] со стороны НКО Citizenlab в 2018 году.
Меры общественного сопротивления таким технологиям в мире включали: общественные кампании, публикации в СМИ, призывы правительствам стран проводить расследования, протесты при внедрении таких систем, письма сотрудникам с призывом увольняться и многое другое.
Но нигде не было призывов составлять списки всех сотрудников компании и применять к ним культуру отмены (читаем правильно - применять санкции и устраивать самосуд).
При том что я лично понимаю насколько все легальные меры воздействия на подобные компании в России и ряде других стран сейчас ограничены, но очень важно помнить что покраска мира в черно-белый цвет очень редко достигает своих целей.
Для меня всё это выглядит как часть очень неприятного для мира изменения - радикализация инженеров. Главное отличие профессионального инженера в способности нанести гораздо больший вред окружающему обществу при желании. Технологии, в принципе, за последние годы в направлении усиления малых команд и одиночек. Ни один террорист-смертник не мог ранее нанести столько вреда как очень мотивированный инженер сейчас. Возможно пользы тоже, но вред первичен.
Возвращаясь к ситуации с NTechLab. Методы культуры отмены против сотрудников которые сейчас против них применяют, безусловно, мне не нравятся, но и компания безусловно пошла по пути когда их технологии специально заточены под технологии массовой слежки.
Вопрос лишь кто может оказаться следующим на рынке нарушения приватности?
Ссылки:
[1] https://vc.ru/services/435936-programmist-opublikoval-spisok-sotrudnikov-ntechlab-on-obvinyaet-ih-v-pomoshchi-silovikam-v-arestah-posle-mitingov
[2] https://ru.wikipedia.org/wiki/Вассенаарские_соглашения
[3] https://citizenlab.ca/2018/04/planet-netsweeper/
#privacy #security #biometrics #facerecognition
Лично я, мягко говоря, против культуры отмены. Персонифицированные бойкоты слишком похожи на самосуд, даже при плохой правоохранительной системе, они, в основном, создают поддерживают атмосферу общего ожесточения.
Но сейчас хочу сказать не об этом. В технологических компаниях очень многие и слишком часто забывают про то что многие технологии имеют двойное назначение. В каких-то областях это давно знают, есть ограничения таких как Вассенаарских соглашения [2], иногда спорно применяемых к технологиям сильного шифрования, но тем не менее.
Так вот дело в том что во многих технологиях уже невозможно говорить о благих намерениях или говорить о непонимании того как Ваша технология будет применяться на практике. Разработчики безусловно отвечают за применение их технологии и должны уметь отвечать на вопросы:
1. Можно ли с помощью технологии нарушать права граждан?
2. Можно ли с помощью технологии усилить нарушение прав граждан?
3. Какие меры разработчик предпринимает чтобы снизить последствия такого применения?
и ещё многие другие.
Технологии распознавания лиц, силуэтов, походки, или технологии глубокого перехвата трафика и ещё многие безусловно относятся как таким технологиям двойного назначения.
И везде где возможно в мире внедрению таких технологий препятствуют общественные организации, политики, учёные и отдельные активисты.
Есть много примеров такого сопротивления. Сотрудники Гугл активно протестовали против разработки ПО для военных. Соцсети под давлением общественного мнения заблокировали ПО Geofeedia использовавшееся для мониторинга протестов полицейскими в США, а в отношении компании NetSweeper продающей ПО для фильтрации интернета было полномасштабное расследование [3] со стороны НКО Citizenlab в 2018 году.
Меры общественного сопротивления таким технологиям в мире включали: общественные кампании, публикации в СМИ, призывы правительствам стран проводить расследования, протесты при внедрении таких систем, письма сотрудникам с призывом увольняться и многое другое.
Но нигде не было призывов составлять списки всех сотрудников компании и применять к ним культуру отмены (читаем правильно - применять санкции и устраивать самосуд).
При том что я лично понимаю насколько все легальные меры воздействия на подобные компании в России и ряде других стран сейчас ограничены, но очень важно помнить что покраска мира в черно-белый цвет очень редко достигает своих целей.
Для меня всё это выглядит как часть очень неприятного для мира изменения - радикализация инженеров. Главное отличие профессионального инженера в способности нанести гораздо больший вред окружающему обществу при желании. Технологии, в принципе, за последние годы в направлении усиления малых команд и одиночек. Ни один террорист-смертник не мог ранее нанести столько вреда как очень мотивированный инженер сейчас. Возможно пользы тоже, но вред первичен.
Возвращаясь к ситуации с NTechLab. Методы культуры отмены против сотрудников которые сейчас против них применяют, безусловно, мне не нравятся, но и компания безусловно пошла по пути когда их технологии специально заточены под технологии массовой слежки.
Вопрос лишь кто может оказаться следующим на рынке нарушения приватности?
Ссылки:
[1] https://vc.ru/services/435936-programmist-opublikoval-spisok-sotrudnikov-ntechlab-on-obvinyaet-ih-v-pomoshchi-silovikam-v-arestah-posle-mitingov
[2] https://ru.wikipedia.org/wiki/Вассенаарские_соглашения
[3] https://citizenlab.ca/2018/04/planet-netsweeper/
#privacy #security #biometrics #facerecognition
vc.ru
Программист опубликовал список сотрудников NtechLab — он обвиняет их в помощи силовикам в арестах после митингов — Сервисы на vc.ru
Компания разрабатывает систему распознавания лиц по камерам и делится доступом к ней, например, с МВД и другими органами.
Что думате по поводу попыток применения культуры отмены к сотрудникам NTechLab и другим подобным компаниям?
Anonymous Poll
28%
Это, безусловно, неприемлимо ни в каком виде
18%
Это, безусловно, необходимо потому что они знали куда шли
18%
Это допустимо только после того как все другие способы воздействия не работают
15%
Это приемлимо только к компании, но не к людям
6%
Это бесполезно потому что неэффективно
14%
Мнения не имею, хочу посмотреть ответы
На сервисе BGPView созданном компанией SecurityTrails исчезли все сведения о подсетях и автономных системах относящимся к России.
На странице страны [1] теперь список отсутствует, хотя он есть для других стран: Бразилии, Польши и др. [2] [3]
С чем это связано непонятно. Может быть чтобы мешать украинским хакерам находить российские подсети, может быть чтобы мешать российским безопасникам знать как фильтровать трафик с не-российских подсетей. Но факт остаётся фактом, именно российские подсети там теперь отсутствуют.
Ссылки:
[1] https://bgpview.io/reports/countries/RU
[2] https://bgpview.io/reports/countries/BR
[3] https://bgpview.io/reports/countries/PL
#opendata #security #infrastructure #telecom
На странице страны [1] теперь список отсутствует, хотя он есть для других стран: Бразилии, Польши и др. [2] [3]
С чем это связано непонятно. Может быть чтобы мешать украинским хакерам находить российские подсети, может быть чтобы мешать российским безопасникам знать как фильтровать трафик с не-российских подсетей. Но факт остаётся фактом, именно российские подсети там теперь отсутствуют.
Ссылки:
[1] https://bgpview.io/reports/countries/RU
[2] https://bgpview.io/reports/countries/BR
[3] https://bgpview.io/reports/countries/PL
#opendata #security #infrastructure #telecom
bgpview.io
Russian Federation (RU) ASN Summary - List of Russian Federation IP Addresses - BGPView
Russian Federation (RU) full list of IP allocations last updated in November 2024. Russian Federation BGP network data map.